前后两天,Databricks发布了DBRX,AI21发布了Jamba,都是开放权重的MoE模型。像极了去年的某一段时间,闭源模型纷纷推出后,开源模型开始轮番上阵表演。
准确的说,这一次的开源模型爆发,应该是从去年十二月Mixtral 8X7B的MoE模型开始的。DBRX和Jamba应该也是充分借鉴了Mixtral模型,一个很直接的证据就是DBRX使用了3072块H100进行训练,预训练加精挑,加红队测试,等等时间加起来差不多是三个多月。Jamba的情况应该也是差不多的。
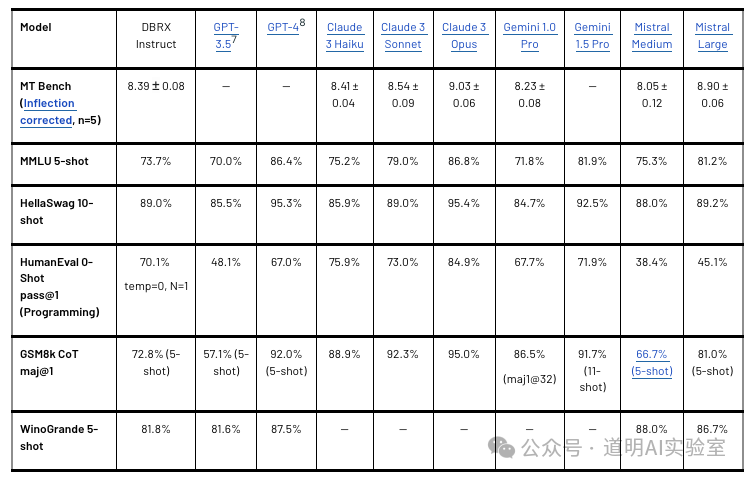
从评分看,DBRX即使与闭源模型相比,表现也很优异,超越GPT-3.5的水平,与Gemini 1.0 Pro差不多在一个水平线上。
相比其他开源模型,DBRX的表现就显然要更好一些。
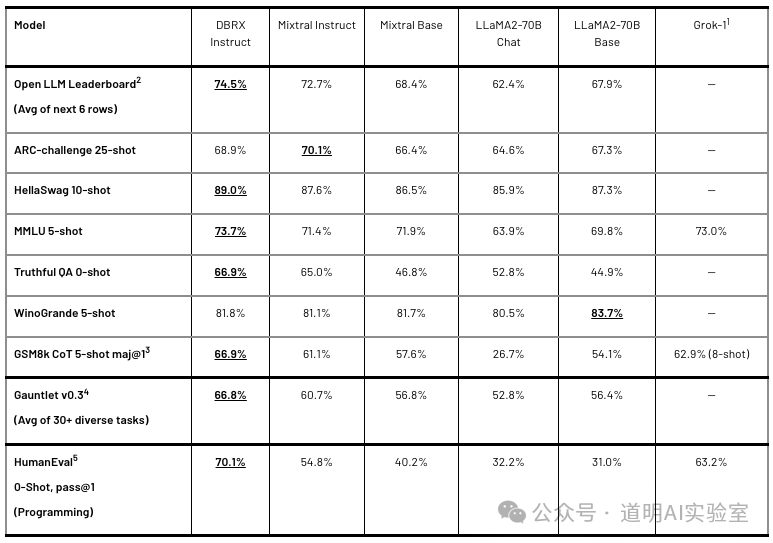
相比之下,Jamba要稍微差一点,不过,拿来跑分的DBRX是一个132B(1320亿,其中active的参数是36B)参数的模型,而Jamba是一个52B参数(active的是12B)的模型,规模差了三倍。虽然都充分借鉴了mixtral模型,但是能力提升之外,还有许多新的看点。
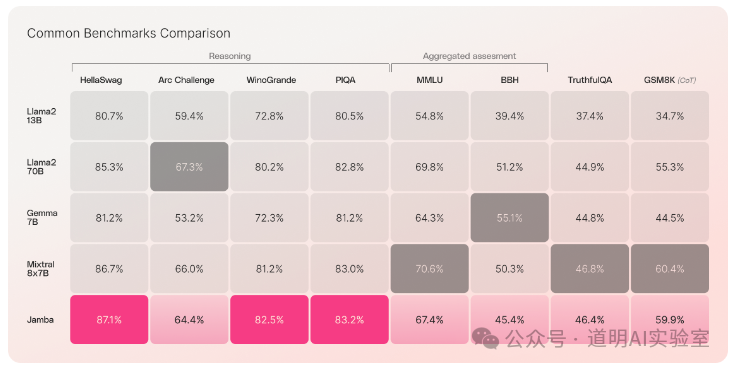
1、MoE成为主流,GPT-4是MoE的,Gemini 1.5 Pro是MoE的,这段时间火爆的国产模型Kimi Chat也是MoE的,当然,今天的主角DBRX和Jamba也是MoE的,质量提升其实都挺明显的。当然,MoE还有个好处是同样参数规模下,训练算力要求会显著的低。
2、DBRX和Jamba都在长上下文和RAG上下了功夫。
DBRX训练时支持最长32K的上下文,Jamba是第一个可以用于生产环境的Mamba架构模型,最长能够支持256K上下文。
Jamba没有专门公布长上下文测试结果,DBRX则是显著超越GPT-3.5的。但是从技术报告的细节看,我初步感觉能力应该是不如Kimi的。不过这个需要我有时间本地部署完两个模型后再进行详细比较。
但是,毫无疑问,对于语言大模型而言,长上下文就是最基础最重要的能力。
3、两个模型都非常强调推理性能。
这一点,Jamba显然更强势一些,首先,在长上下文场景下,每秒钟输出的token数量是Mixtral 8X7B模型的三倍(两个模型参数量几乎一致);
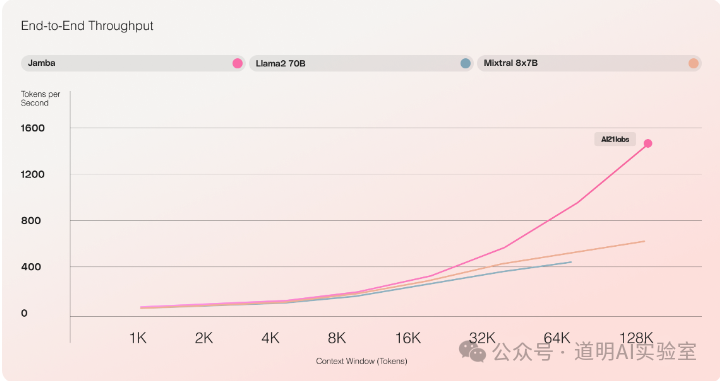
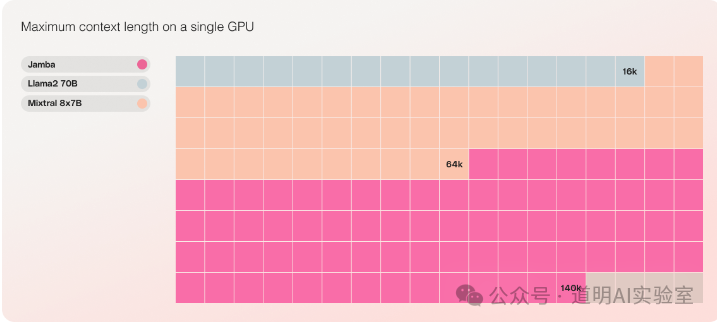
其次,Jamba是可以用一张GPU(应该是指H100 80GB)就推理140K上下文的模型,Mixtral只能支持到64K,LLaMA2-70B只能支持到16K。LLaMMa-3真的得赶快出了。
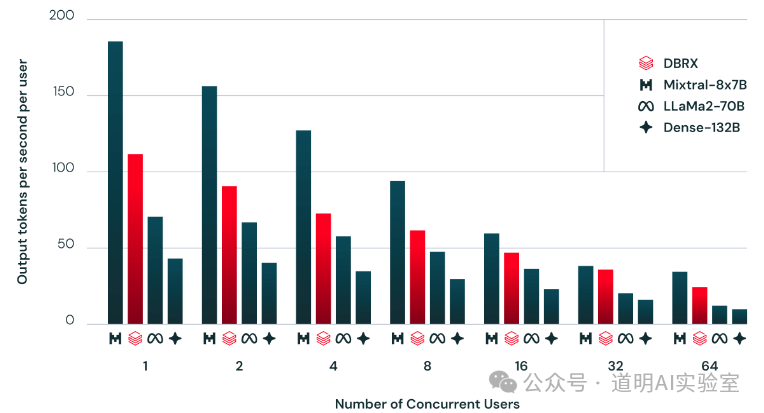
DBRX给出了不同的比较,在高并发时(64个并发用户),DBRX输出能力差不多是LLaMa2-70B的两倍,而相比只有三分之一参数量的Mixtral,差距则并不大。
4、MoE、长上下文、推理性能之外,为什么这两家要推出这样的开放模型(开放权重,Jamba是Apache2.0协议,通常理解的无商业使用限制的开源,DBRX用了Databricks自己的开放协议,我看了商业条款,是如果一个月活跃用户超过7亿,就需要额外申请许可)?
Databricks在之前就是一家头部的数据及AI类SaaS服务提供商,从SaaS转向MaaS(模型即服务),商业模式其实很通。Databricks完全可以给中小企业客户或者个人提供完整的基于自己开源模型的云端私有化部署及运维方案。模型不收钱,但是基础设施和配套服务可以收费。DBRX的推出,至少确保databricks在这一轮变革中不会被快速淘汰,甚至,这个模型的表现,让我相信,databricks还有可能受益。
AI21作为文本生成领域的头部MaaS公司,开源模型同样可以进一步稳固基本盘的同时拓展其他的云服务机会。当然,相对于过去几年较多使用databricks技术栈方案的经验而言,我对AI21的了解程度非常有限,但是有一点我还是比较确定的,海外市场,在用户对SaaS接受度和付费意愿已经很高的背景下,转向MaaS的路径很通畅。相比之下,国内,就会是完全不同的情境。
5、关于推理。
毫无疑问,无论是闭源模型,还是开源模型,AI已经进入了推理需求大爆发的阶段。部署门槛(生态)、推理性能、推理成本是最重要的三个方面。
最近,无论是Stability AI还是Databricks都发表了推理方面的一些结论,一致的结论都是:Intel的Gaudi2是性价比最好的推理卡,一方面确实是Gaudi2推理性能超过A100,甚至有些场景下超过H100,另一方面因为Gaudi2等待时间很短,Intel提供的云服务价格也比较便宜。
所以,在云端推理市场,看起来Intel甚至AMD都具备一定的吸引力。Stability AI和Databricks这类具备非常强技术实力的公司,搞定不同硬件环境下的推理完全不在话下,但如果就是中小企业自身的推理需求呢?显然,英伟达的生态带来的更低的技术门槛和更有弹性的应用场景(中小企业可能技术环境变化会很快,CUDA生态不仅仅是用来推大语言模型,还可以更灵活的切换到其他使用场景),吸引力依然还是最大的。
当然,对于推理市场,国内国外其实是完全不同的。海外市场,B端用户对云服务接受度非常高,业务落地是首要考量,所以往往会选择SaaS服务商的一整套解决方案,这一点在开源(或者闭源模型私有化)模型部署上,会体现的更加明显。基础云服务商(AWS、Azure、Google Cloud这些)对不同硬件的采购量都比较大,本身也提供完整的技术栈SaaS方案,结合类似于Databricks的SaaS企业,对用户而言,硬件的绑定度并不强,都是云端一键部署,推理是用英伟达,还是用Intel或者AMD,使用成本甚至可能成为决策的唯一要素。
而在国内的环境下,用户即使选择云服务,也是裸服务器更多,SaaS的采购比例相对海外显著较低。硬件架构和生态支持反而成为重要的考虑因素,当然,如果机房租赁费用和电费合适的话,自己买卡还是更好的选择。如今的GPU几乎可以算作硬通货,甚至可能比房子还保值。
这样看来,联想最近暗示的AMD MI300出货量超预期,和很多渠道公开表示的H20订货量超预期,都有足够的合理性。
其实,推理还有很多选择,比如热炒的AIPC,甚至手机,其他边缘设备,跟着场景,一点点来吧。至少上半年剩下的这两三个月,应该还是看大模型推理。