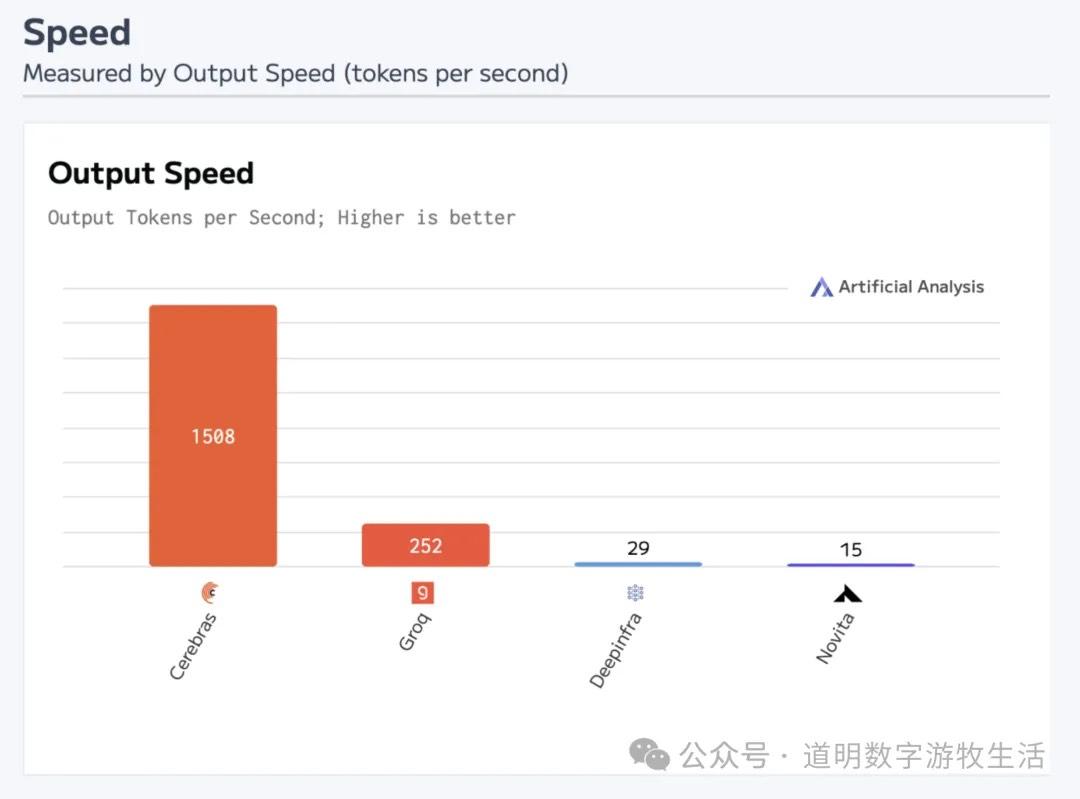
随着Groq和Cerebras相继公布支持DeepSeek-R1,并且给出了不出意外的推理速度“天花板”数值后,技术层面上,DeepSeek引起的短期冲击波基本结束了。
然而,因为科技与资本市场的绑定过深,心理层面的余震看起来却远未消停:
1、对算力和英伟达是利空吗?因为看起来根本不需要这么多卡;
2、既然看起来“壁垒”不那么高,那么大公司这么多资本开支做训练还有意义吗?
回答这些问题真的挺难的,线条太多,就容易逻辑混乱。
其实,这一轮DeepSeek引起巨大冲击波的根本原因是:表面看,OpenAI模型已经超过半年没有显性的巨大进步了(尽管我们知道,前沿模型其实在变得越来越好用),而o1和o3其实还都只是重要路径上的尝试,都没到“ChatGPT时刻”。
假设,OpenAI、Google或者Anthropic中的一家或几家在较短的时间(三个月?)里发布轻松将各种benchmark提高十分以上的下一代模型,即使成本是现在的十倍,可能市场都不会觉得“模型届拼多多”会有多了不起。
无论从哪个层面看,毫无疑问,2024年下半年以来,模型的进步速度是明显落后于之前的预期曲线的。主因当然是OpenAI作为实质上的“初创草台班子”,不稳定性显而易见,但是重要的次因也有英伟达Blackwell集群落地过程中遇到的一系列技术问题。
所以由英伟达为代表的“算力”来背市场质疑的锅,并没有多过分:“大集群20-30倍训练和推理算力提升,4倍能源效率提升”的期货,其实已经持续了快一年了。
回击质疑的方式,只能是,更好的模型。班上“学霸”帮助的同学,期末考试分数比自己高,学霸除了参加更高级别的比赛证明自己,也没更好的办法了。
那么,第二个问题就来了:既然“通向下一代”还有很大的不确定性,或者说即使达到了,也可能很快被人赶上,那么巨大的资本开支是否还应该持续?
微软和Meta的业绩说明会上给出了清晰的回答:继续!
为什么?
因为“更多的数据,更大的算力”是确定性最强或者说唯一能看清楚的道路:过去几十年里或者说自计算机发明以来,每一次算法的创新都来源于“硬件的瓶颈”,但创新算法的scaling law又会在最短时间里吃掉所有的硬件提升,前一个例子是大数据。
尽管竞争者越来越多,但看起来在一两年里,市场依然会消化掉几乎所有“最好的算力”。在算力领域,核心矛盾不是“需不需要”,而是从发布会的“纸面算力”到真正落地的“真实算力”之间的时间差。如果这个时间差接近硬件公司roadmap上的代际升级时间(一个摩尔周期?),那需求就会消失整整一代。
以上,才是真正需要关注的问题。其实,也是“聪明的市场”过去半年多里隐含的最大逻辑。
这是算力的全部与资本开支的一半的问题。
资本开支的另一半问题是:变现能力。
过去两年里似乎证明了一件事情:纯粹卖大语言模型是不可能挣钱的。
卖大语言模型的实质是卖模型压缩过的数据(“蒸馏”这件事情事实上谁都在干,最后除了行政上的“使用限制”,没有太好的解决方案的)。“独家数据”可以卖高价,“你有我有全都有”的数据就是一文不值。
从产品角度而言,一定是将这些数据附着到能够“开辟场景”的载体上,这是我一开始就看好AI硬件和端侧的原因,也是我一直不太看好微软的原因。微软过去的成功是Wintel联盟的成功,然后是基于Windows垄断地位带来Office的垄断地位,进而依靠“企业办公数字化”带来Azure云上的地位。2023年后在大企业压缩资本开支时Azure云依然保持高增长的原因也很简单,对OpenAI的垄断。
“遥遥领先”的软件和体验可以创造场景,打造生态垄断,然后打开更多变现场景。越是急迫增加资本开始的玩家,越是代表“依靠技术革新破局”的强烈愿望,“赌”的也越大。虽然成功率并不高,但是成功的收益足够大,巨大的“期望收益”就可以支撑巨大的故事。
如果碰到市场开始下调“期望收益”,故事就会更好玩一点。然而,从过去大半年里看,这些“基本面”的因素发生了重大变化了吗?对未来也会产生巨大变化吗?其实,都没有。只不过总是需要时不时的“泼一盆冷水”平息一下过高的体温。
DeepSeek的出现更像是那盆“冷水”。没有它,也会有别人,比如说“命不太好的”QWen、MiniMax和Kimi……
如果看benchmark,国产模型都飞起了,我相信技术层面差距也不大,毕竟即使在海外,使用QWen2进行本地部署的也大有人在。这是技术外溢和数据外溢结果的正常体现,也是我从23年开始就一直说差距差不多就是六个月时间的原因。
如前所述,所谓的大语言模型,本质上就是个“数据压缩器”,OpenAI的生意不是卖模型,而是卖数据。数据一定是越卖越便宜的,公开卖的数据也一定是无法保密的。
其实,OpenAI当然很清楚这个问题,但是如果时间倒退回两年前,他们的可选项似乎也不多。而且,在巨量资本从四面八方砸来的场面下,尽快“闭源”创造收入,而不是“开源”牢固基本盘,估计是任何人都会做出的选项。
那么,回到模型本身,大概就聚焦到两个解决方案:压缩更多的数据;让模型产生个性化记忆(我一直不愿意称之为“智能”)。
前者,是寻找更多更海量的“新数据”,比如图像、视频、声音、空间信息;后者,是让模型和场景结合,能够与更多的场景数据“融合”。
前者,是“预训练”依然在准备的部分,至少Sora的进度表明,数据量需求是比预期的更大,而不是更小。
后者,是“后训练”强化学习真正想要解决的问题,是o1、o3这类思考模型的终极目标,只是是不是可以通过o1、o3这类方式达到,还不太清楚。
从“解压缩”层面看,多模态或者“物理世界”对数据还原的要求非常高,卖家秀wow的sora,在买家秀不断翻车,大概就证明了这点:为什么相对简单聚焦的场景看起来就不错,大场面的场景看起来就漏洞百出?
本质上,那些漏洞百出的地方都是因为“数据不够,随机来凑”的结果。
假期期间,我尝试通过下面的例子来说明这个问题。
所以,如果我们依然是“唯物主义”的,那么,数据就还是通向所谓AGI的最重要的基础之一。
那么,另一个问题,个性化记忆(或者我不愿意叫的“智能”)在哪里?在每一个使用场景里。
在窄应用里,这个出现过,就是一直在说的从AlphaGo到AlphaZero的进化过程。前者是把足够多的棋谱进行压缩,对弈过程就是通过计算还原(“穷尽”)各种场景的过程;后者通过深度强化学习(建立在深度神经网络上的强化学习)在“对弈”中训练自己,通过一次次对弈结果的“奖励”强化记忆,最终将下棋变成某种程度上的“条件反射”。
因为围棋的场景非常聚焦,“奖励”很容易设定,所以这种方式不仅理论上可行,而且实际上也成功了。如今AlphaZero存在的更大价值不是证明AI超过人类(围棋领域无需证明了),而是更多作为棋手辅助训练的最强大教练了。“AI让人变得更好,同时不危害人”,这个目标至少在类似的窄领域里实现了。
但是,回到“AGI”,问题就复杂得太多了。虽然深度强化学习理论上依然可行,但是实际上,先不说通用场景极海量的问题,即使同一个问题在不同场景,对于不同人而言,答案都是不同的,“奖励”的设定根本不可能千篇一律。
这是类似于空间智能和具身智能从现阶段或者稍早阶段开始重要性快速提升的最重要原因。也是OpenAI尝试o1和o3这条道路的重要原因。
然而,回到类似于o1和o3的思考模型这个问题上来。我至今都觉得这条路看起来很模糊,一是这依然是一个“对每个人都一样”的云端模型模式,二是,显然,用于训练的“奖励数据”依然少的可怜。
我相信,OpenAI一定是花了很多时间和成本进行o1和o3的训练的,但是,怎么看,所谓的“思考模型”,都像是一个大型的“提示词模型”:训练的过程或许就是如何更好的将用户的“大白话”翻译成让“GPT-4o”输出更好结果的提示词。
我也相信,一个真正具备“思考能力”的强化学习后的模型,被“蒸馏”的难度是非常大的。但是“提示词模型”本质上就还是个数据压缩器,只不过卖的是所谓“思考数据”而已。然而,就目前而言,这个“提示词模型”实际的数据量远小于“大语言模型”,解压缩的成本可能也会低很多。
我还相信,如果给予o1/o3足够多的“奖励”数据,“思考者模型”可能会“涌现出”思考能力。但是,这些数据从哪里来?尤其是个性化的“奖励”数据?
答案或许很聚焦:ChatGPT“助手”功能发布后:OpenAI与Agent之间差一个硬件。
PS:碍于篇幅和各种原因,本篇在一些问题上还留了些“尾巴”。