在开始今天的更新之前,必须承认:网络环境正在对我的工作效率产生巨大的影响。所以,好模型很重要,带宽很重要,token速度很重要,工具间的连通很重要……
积压了一批要写的,一个个来吧,先讲最新的,或许是最重要的,Jensen在CES上的演讲。我没有熬夜看直播,所以体会不到几年前那种很激动很兴奋的感觉了,不知道是因为没看直播的原因,还是,确实有些“审美疲劳”了。
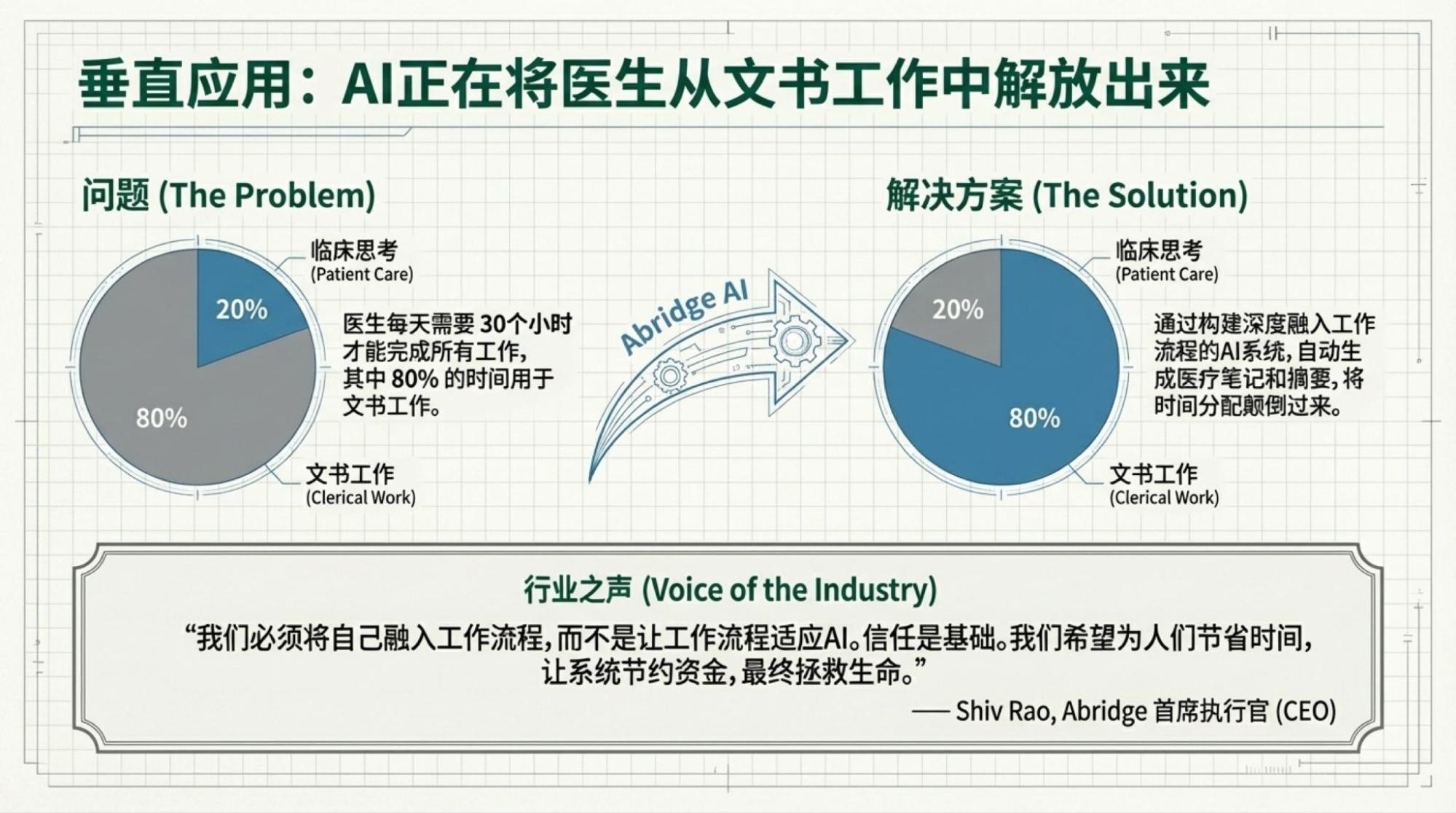
没关系,这不是很重要,重要的只有两个:一个是或许跟很多人的“钱袋子”密切相关的Rubin,一个其实是讲起来很酷炫但实际上离很多人还很远的那些“未来”(实际上医疗AI确实是可以有东西的,尤其是最近一段时间因为各种原因高频度切身体会了不同的国内医疗机构的“工作流”后,感触真的是“立刻”出来的,也算积压的内容吧)。
详细的展示,总结,已经不太适合我干了,交给NotebookLM就可以了:直接给实况的视频链接,就可以出东西,尽管我的目的就是给自己看,不过作为一个对外的产品,表现也很好了。所以,按照这段时间的固有操作,会贴在后面。
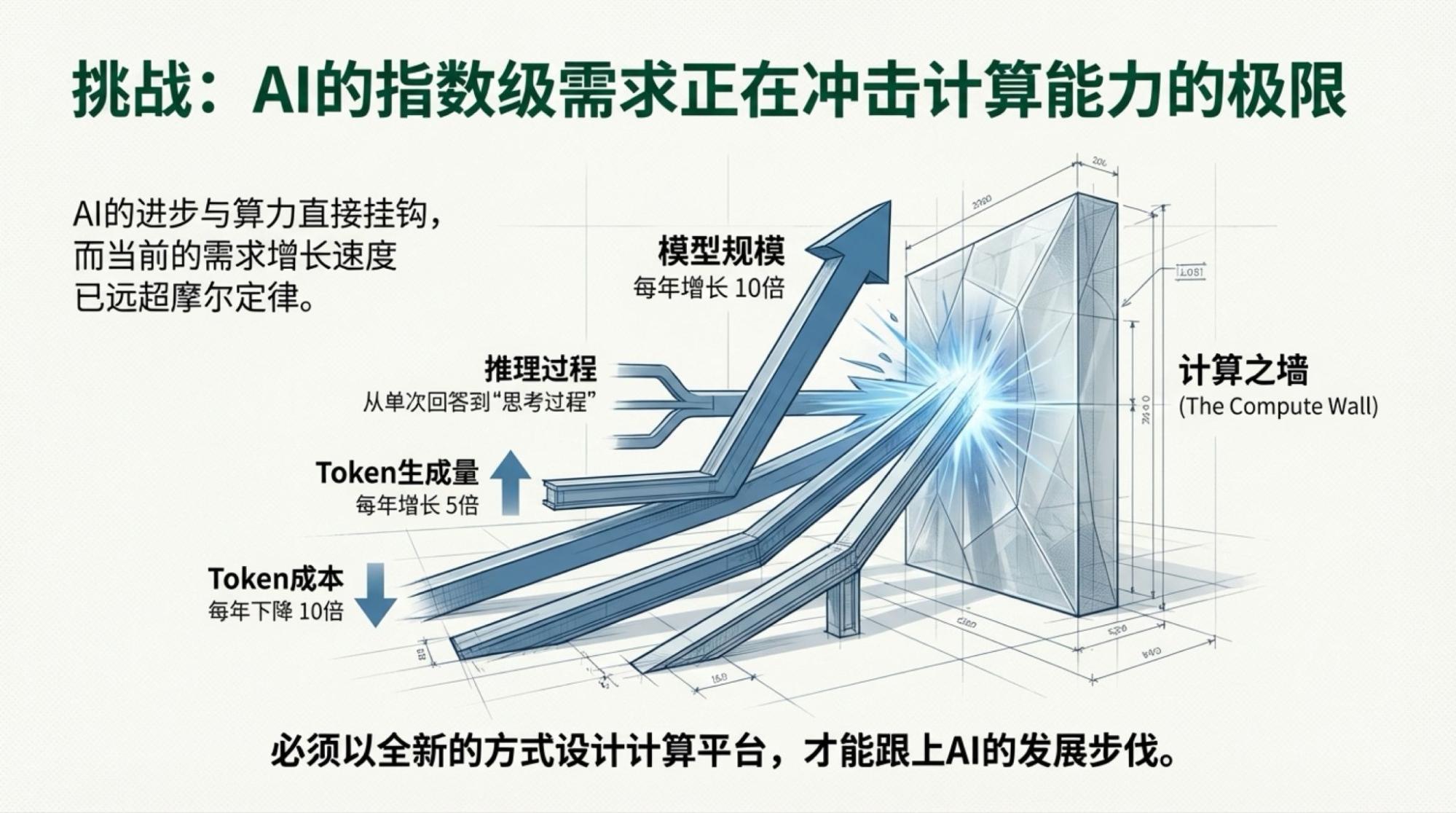
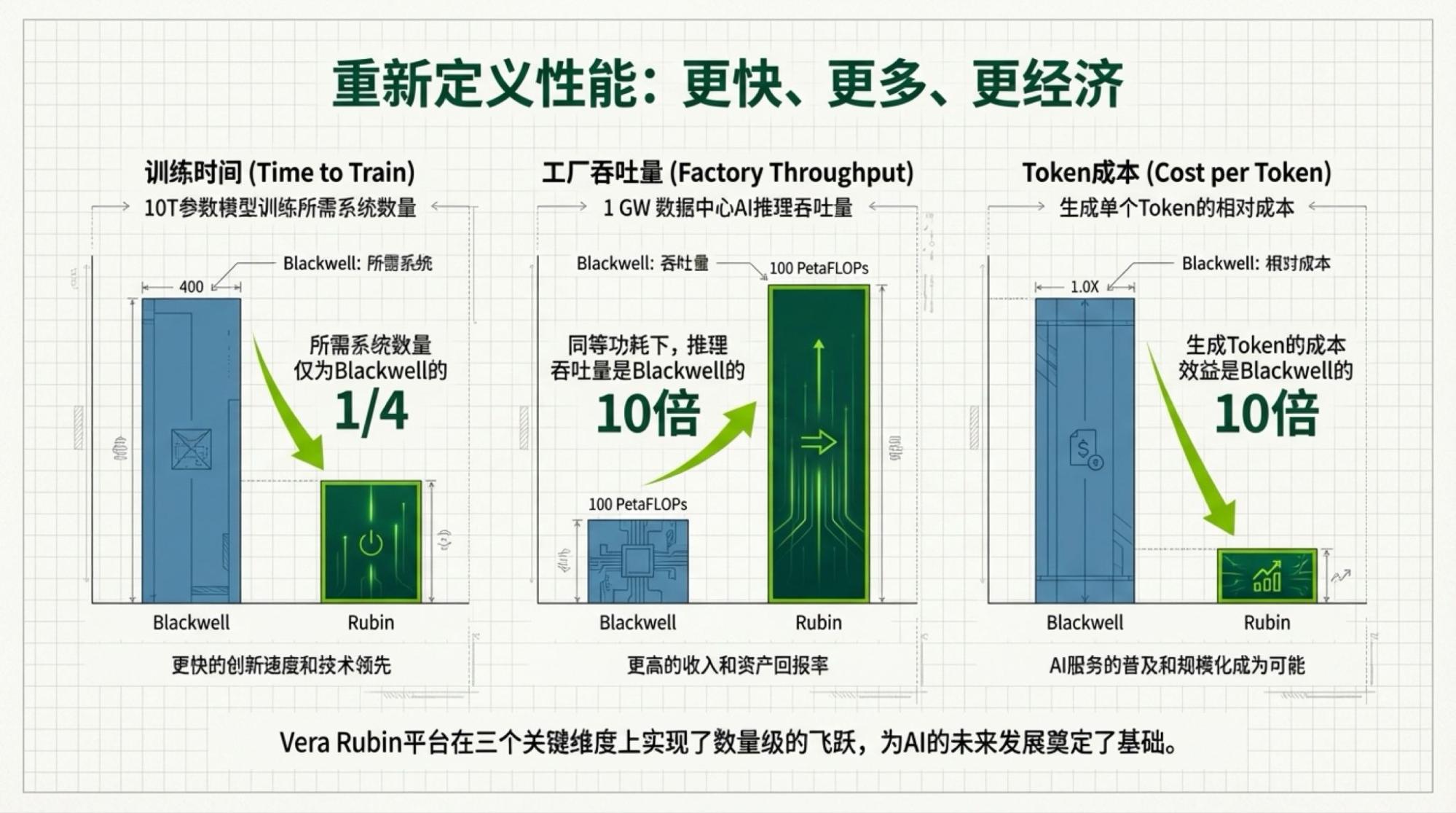
而我要写的部分,从结论而言,很简单,就是标题表达的,事实和逻辑会稍微复杂一点:按照Jensen演讲预热时主持人的观点,token用量将年增5倍,按照Jensen介绍Rubin NVL72系统的性能时讲述的,推理成本将变成十分之一。
当我看到NotebookLM生成的这一页时,相信跟很多人的感觉是一样的:这是要迎来AI通缩时代吗?
于是,重新快速过了遍视频,找到了前面所说的出处:token量的五倍来自于主持人的表述,十分之一来自于Jensen或者说英伟达官方的介绍。
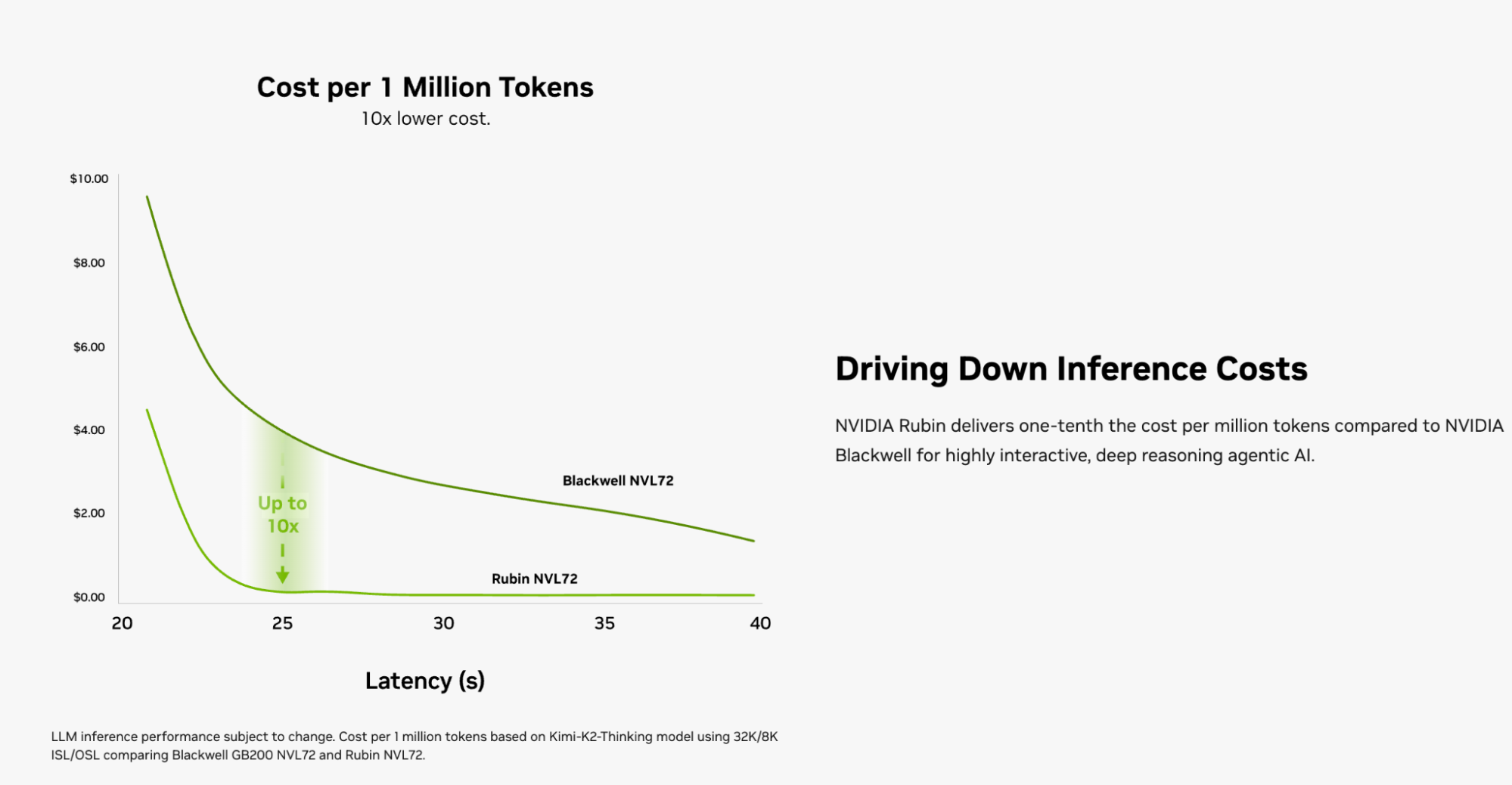
上图来自官网:https://www.nvidia.com/en-us/data-center/vera-rubin-nvl72/?ncid=no-ncid
当然,现在还没有看到任何Vera Rubin NVL72实际部署的新闻,即使部署了,也主要是用来训练的,即使Blackwell出货这么多,相信目前更多的推理还是运行在Hopper架构或者更早的TPU上的。
然而,对于我们一直在说的“杰文斯悖论”就会是很非常有趣的局面:成本下降速度和token用量增速,到底哪个跑得快?2026年说不定会有一个意想不到的答案。
我还维持着2026年token用量“三到四个月翻番,模型成本下降三分之二”的预测上,但这不代表模型推理服务有巨大的增长,因为竞争会导致绝大多数模型推理服务可能是免费的。
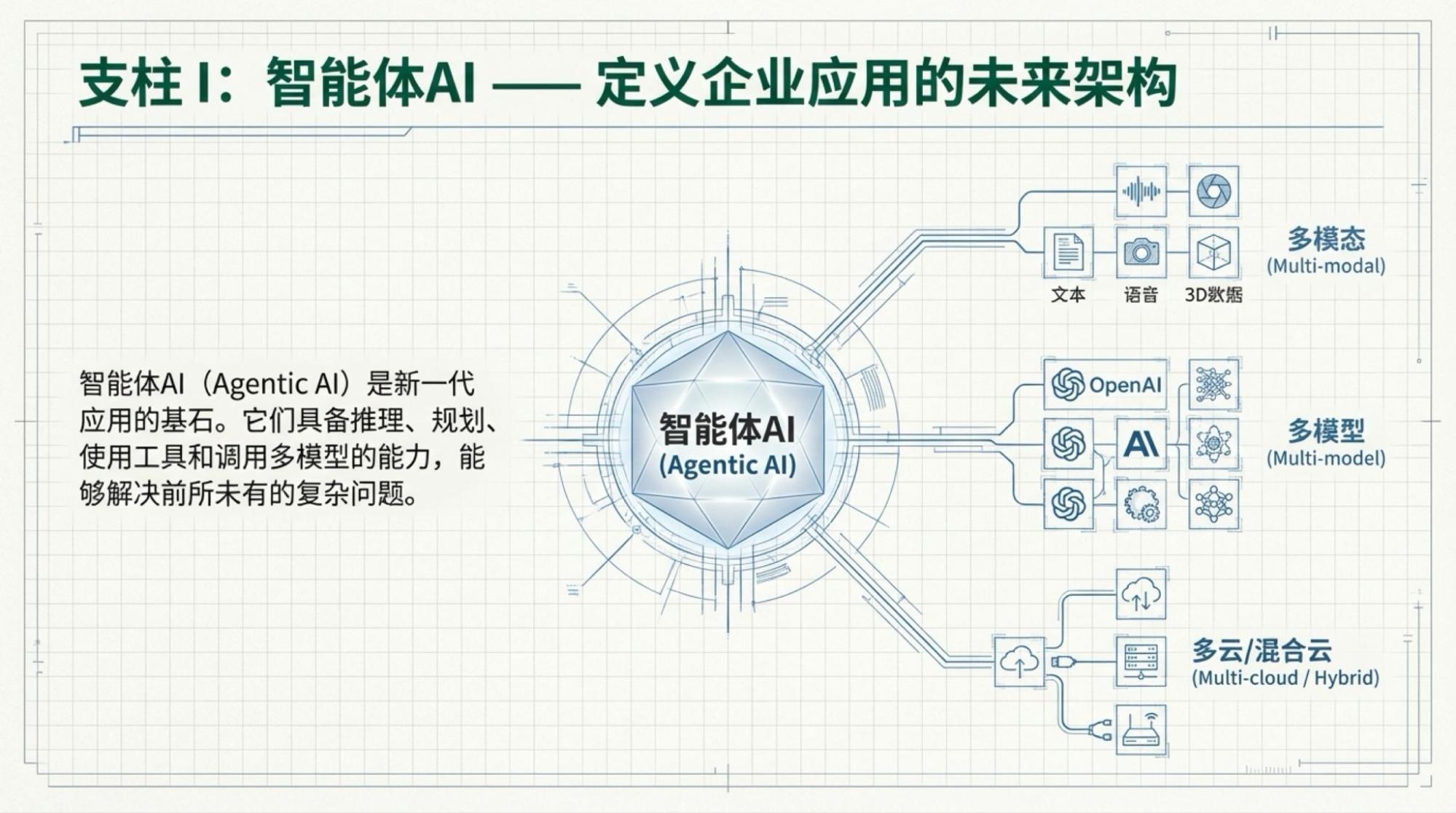
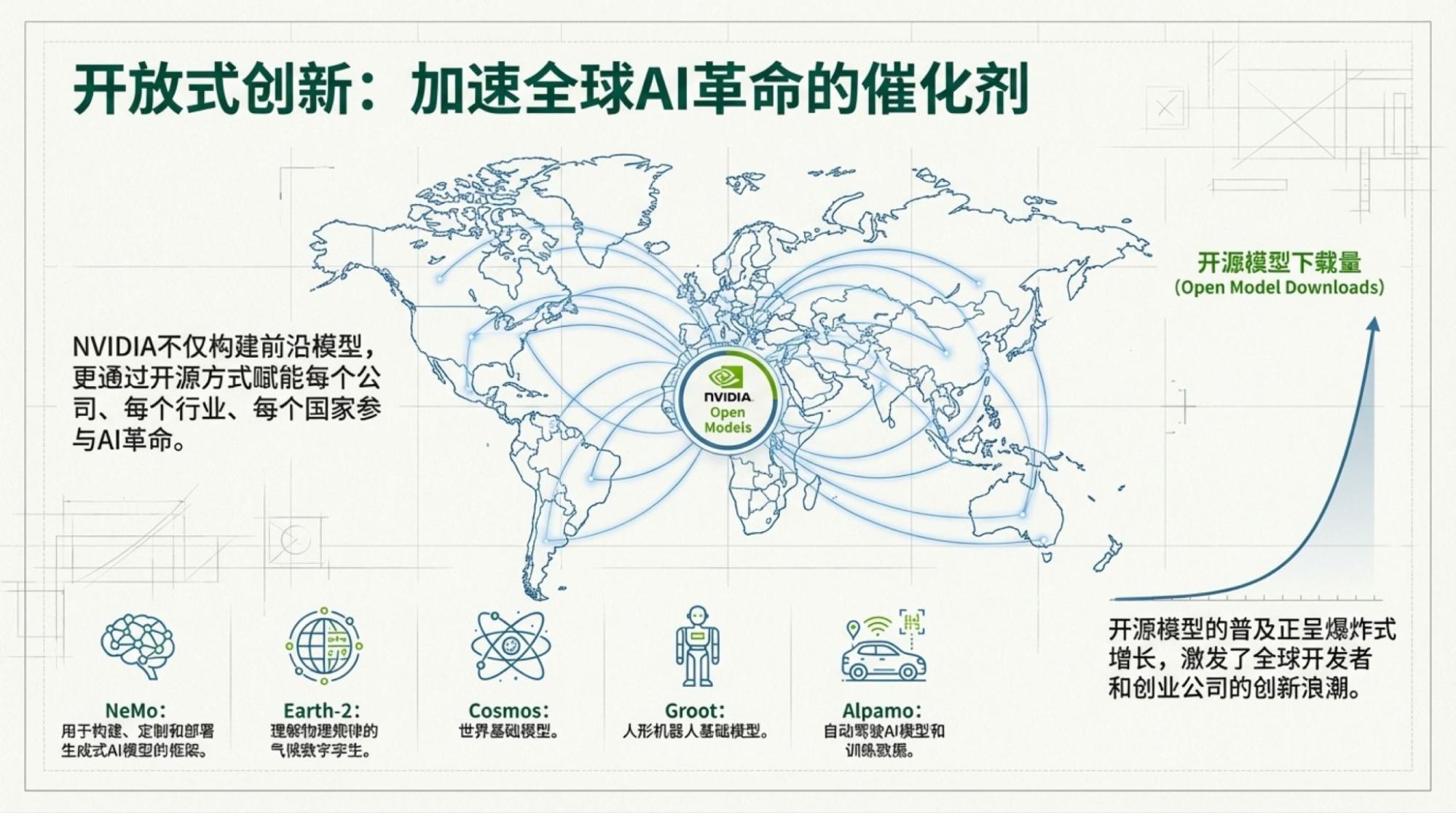
关于模型部分,Jensen的重要观点来自于开源模型(开放权重)的普及,我一直觉得英伟达对推理市场的理解并不基于“御三家”(OpenAI,Google,Anthropic),而是基于更广阔的“私有化部署”(更多也是在云环境里)。我也认为开放权重模型的私有化部署很快将挑起绝大多数AI任务的重任,特别是如果我们看到纯语言模型部分,即使Gemini-3相比Gemini-2.5,其实进步也并不显著的时候,开放权重模型大概也只需要再有一代的升级就可以满足更多场景需求了。2026年,Llama-3,DeepSeek时刻大概率会再来一次的,只是不知道是哪一家“扛旗”了。
所以,基本上,AI在技术层面和经济层面表现之间的“剪刀差”就是在拉大的。“AI通缩时代”符合技术推演的逻辑,但就是不符合经济学原理。所以,要么,经济学那些基本假设很难被挑战,要么,经济学教科书即将进入历史的垃圾堆,发生哪一个,我都觉得挺好的。
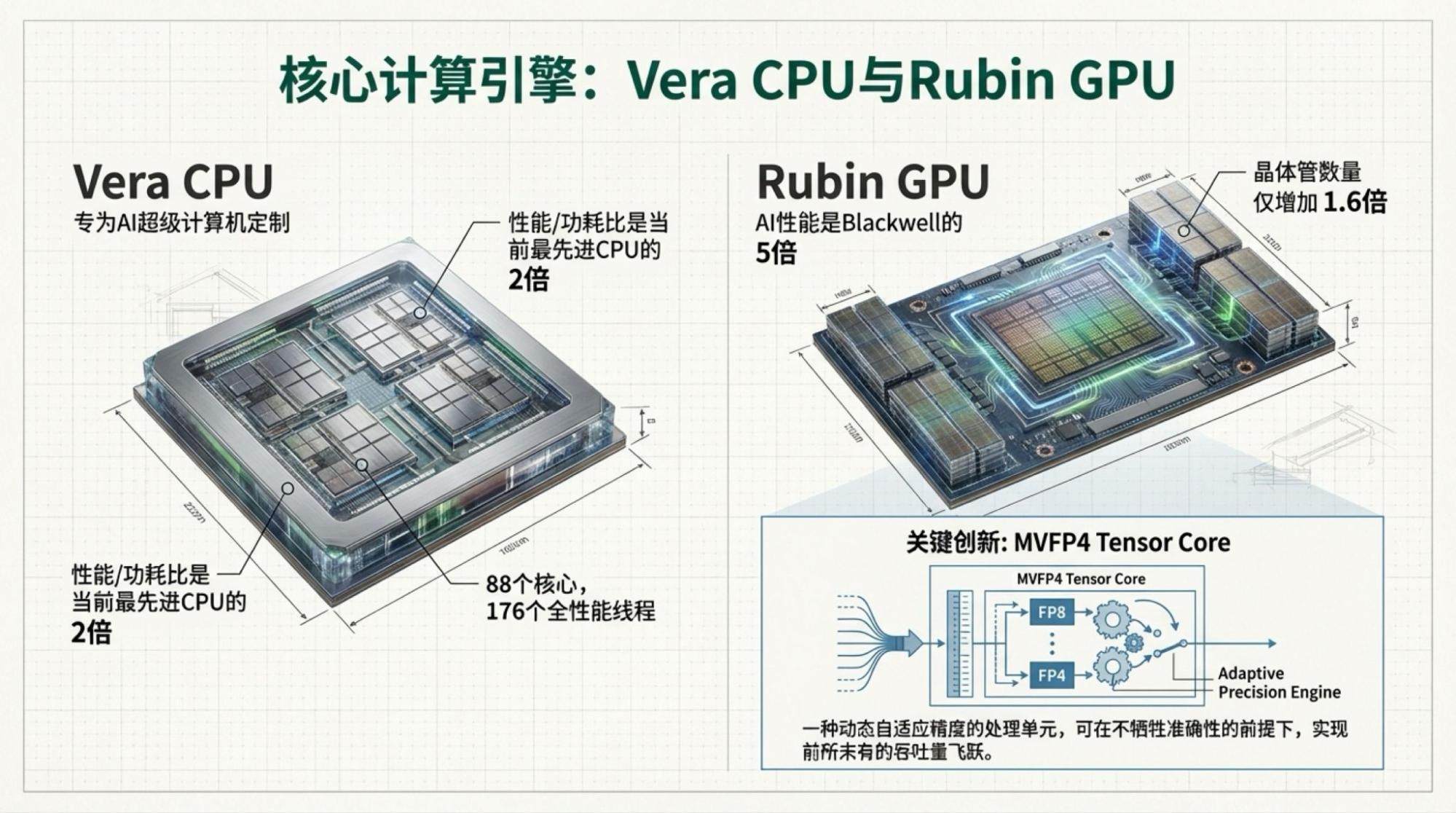
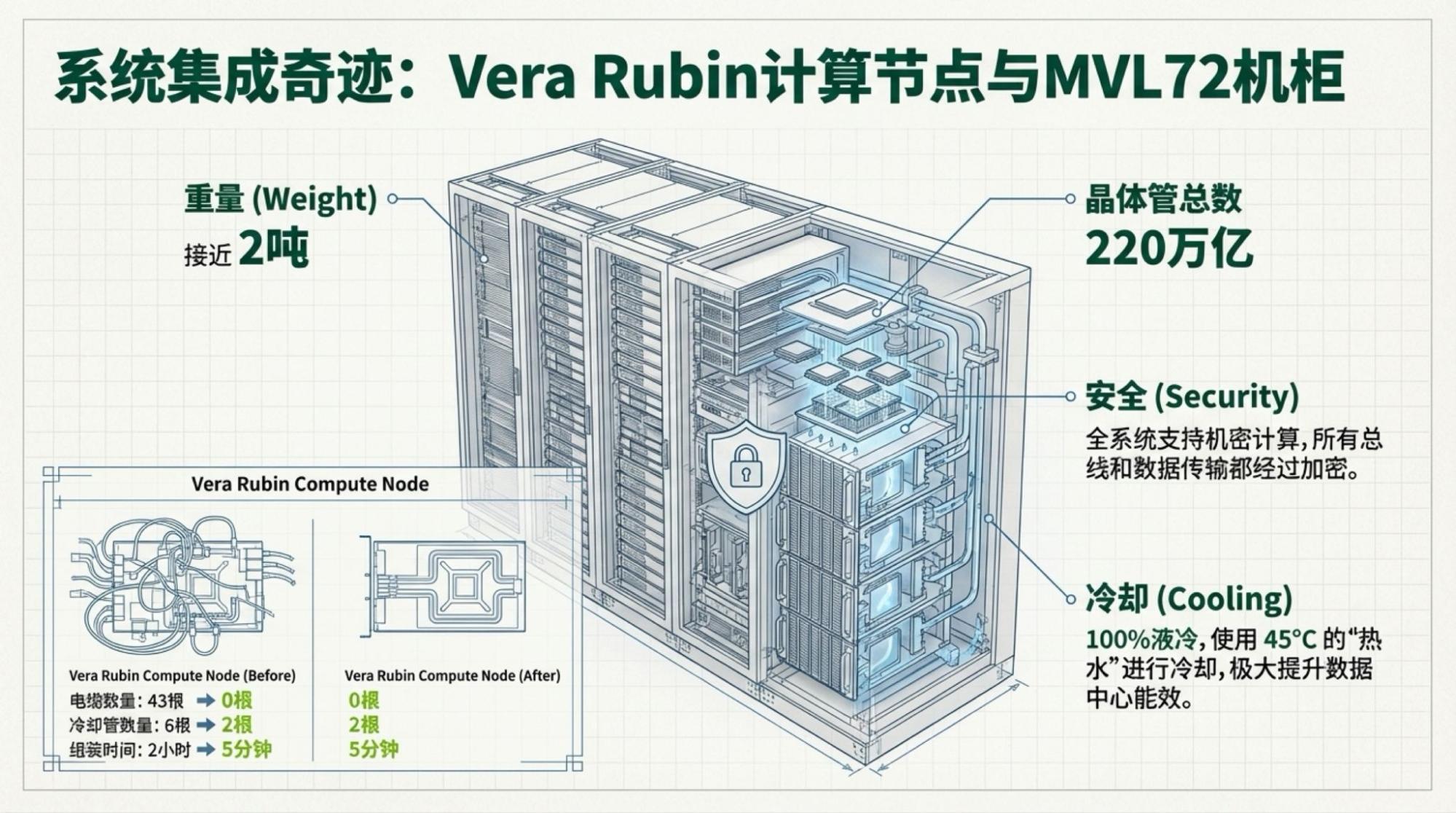
我还感点兴趣的是Vera Rubin,尽管所有信息大家基本早就知道了。但还是有有些细节挺有意思的。

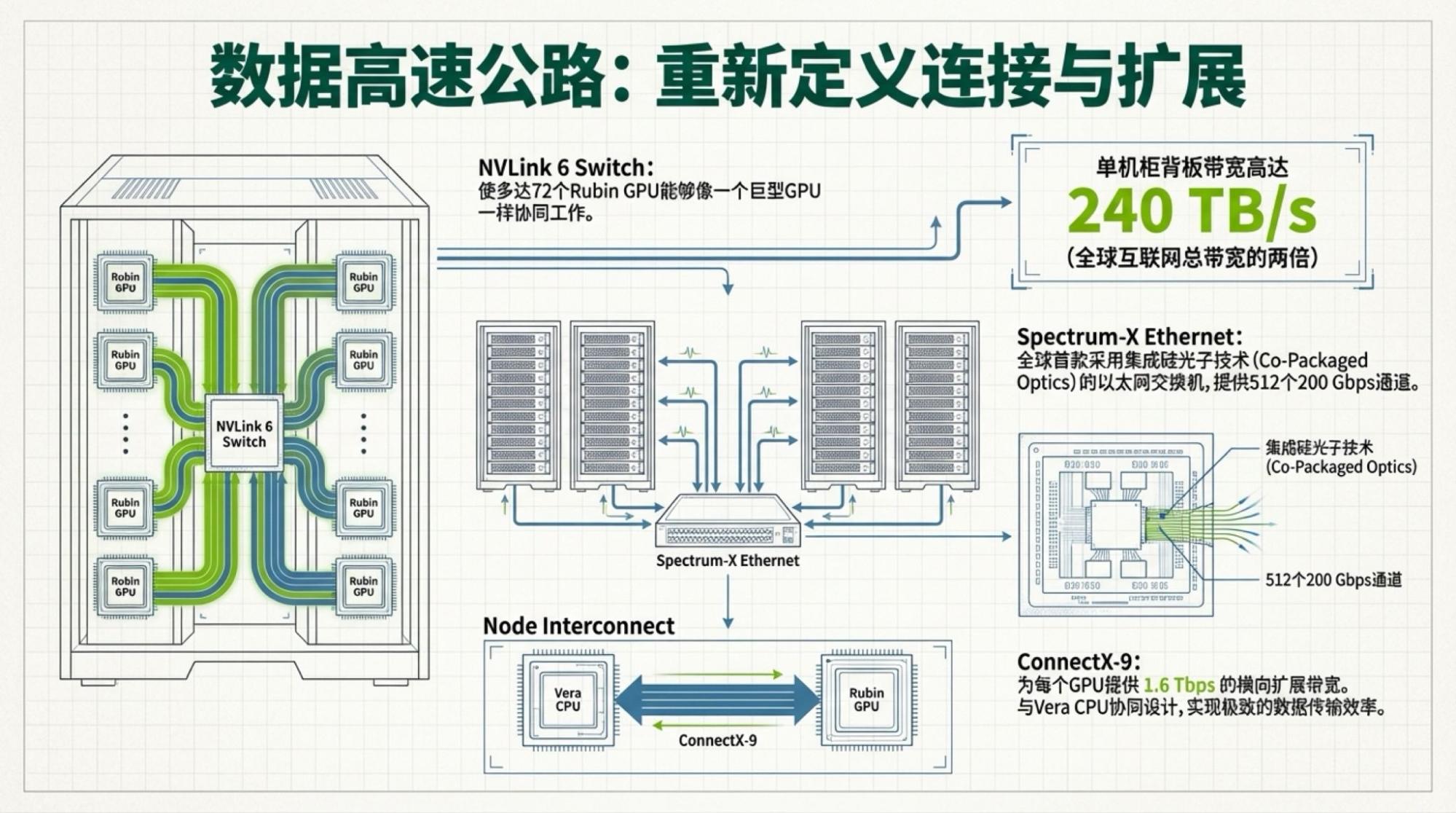
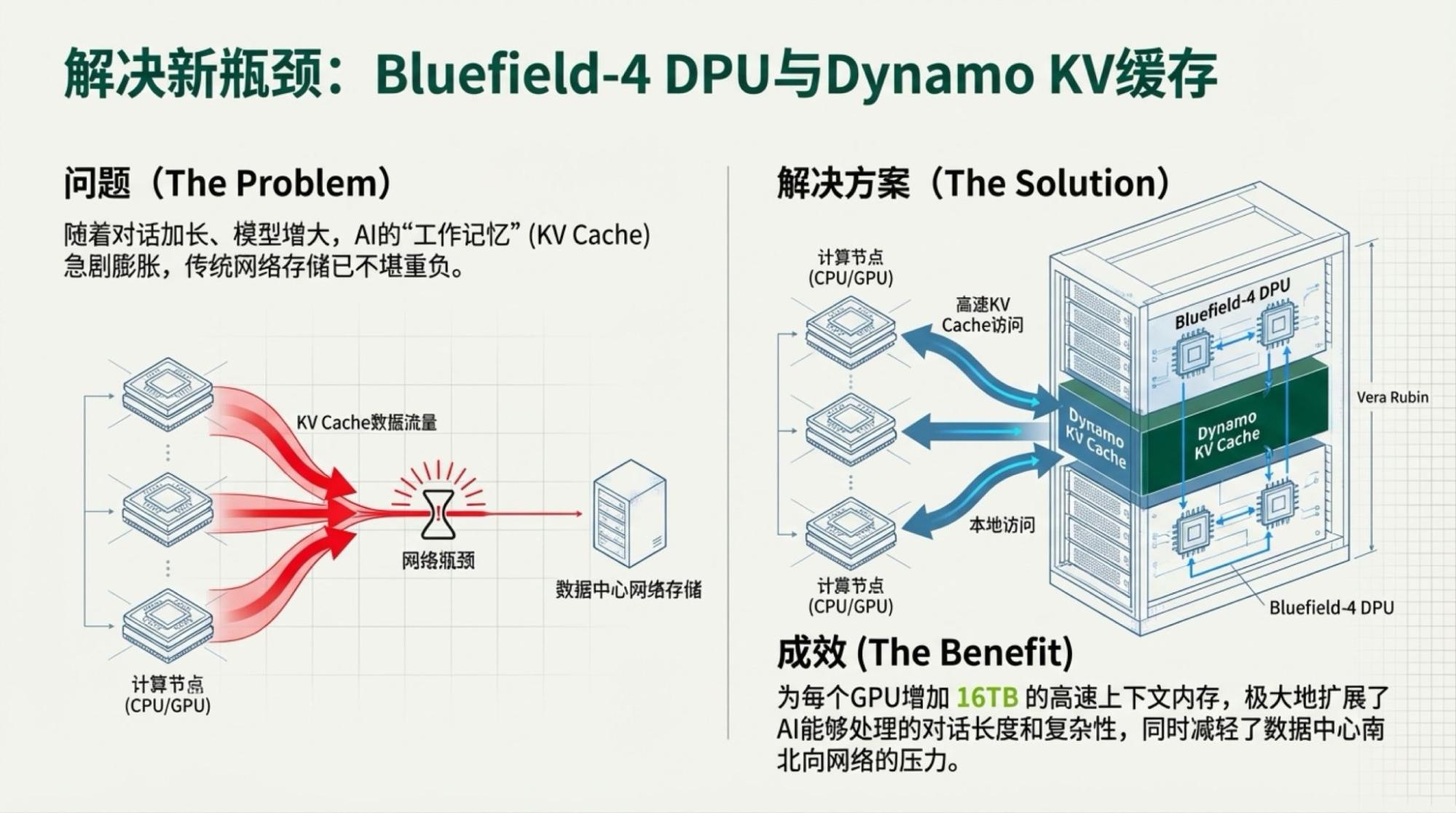
上图依然来自于英伟达官网。所以,它告诉我们什么?制程和内存带宽贡献了所有的性能提升。互联带宽管什么?管到底在“制程和内存带宽的提升上”打多少折。但它就是很吃模型架构,显然,MoE模型架构要求极大的芯片间数据传输量,这也是TPU可以训练出Gemini-3的最重要原因。
所以,真正的瓶颈到底在哪里,一目了然。
无论“AI通缩”会不会立即来到,我都不可能再手工做ppt,手工画图,手工写全部代码……
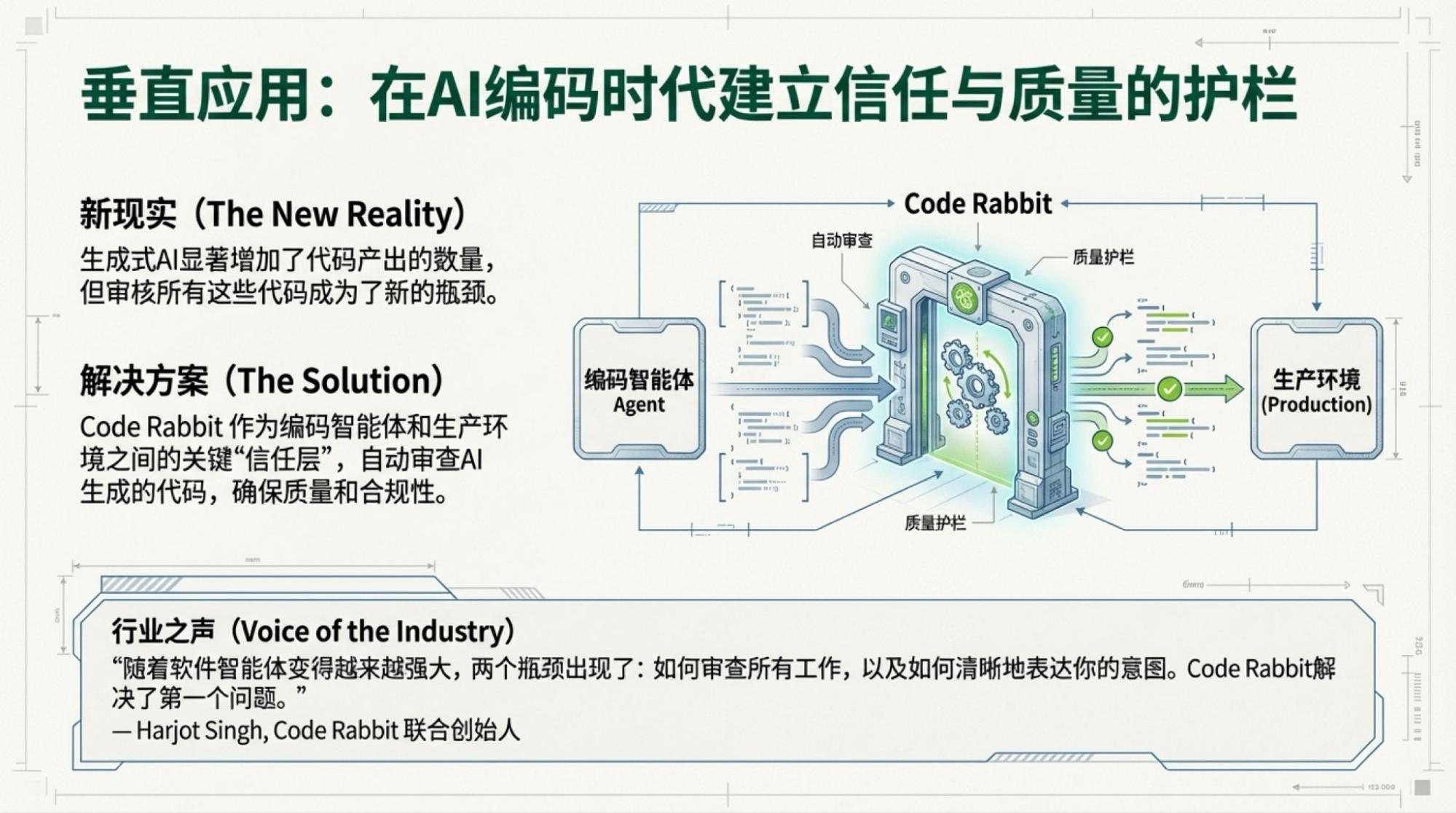
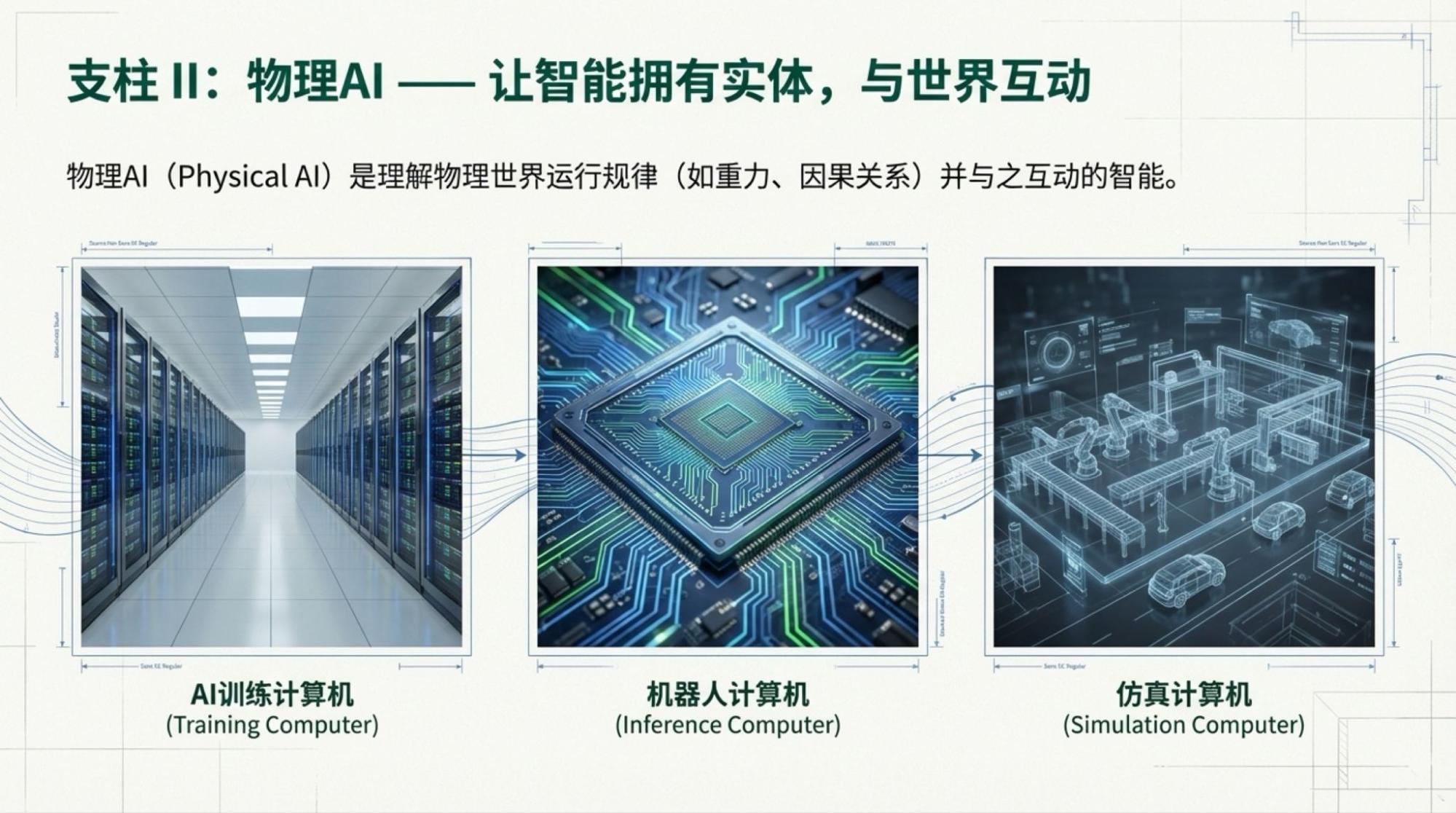
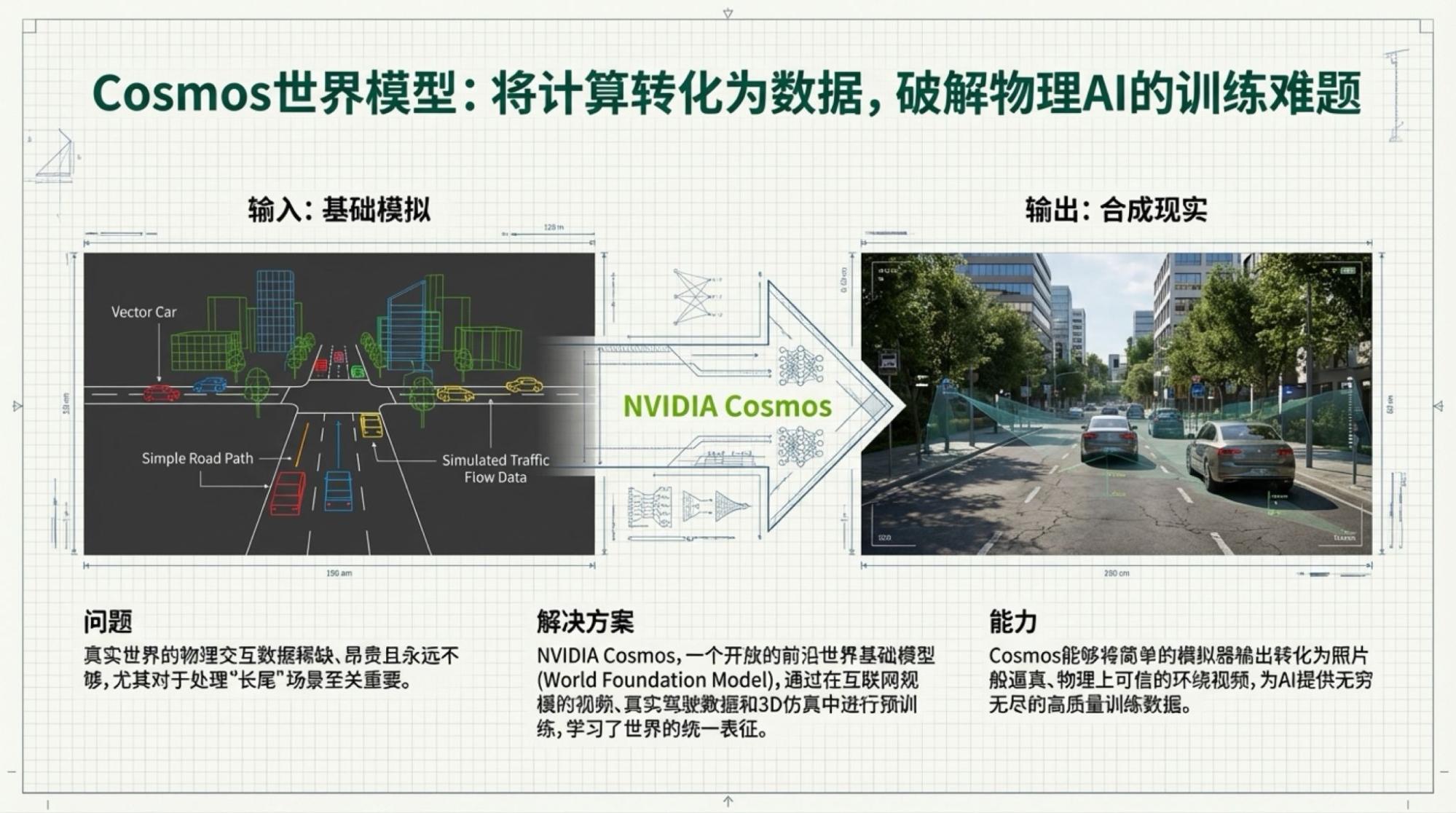
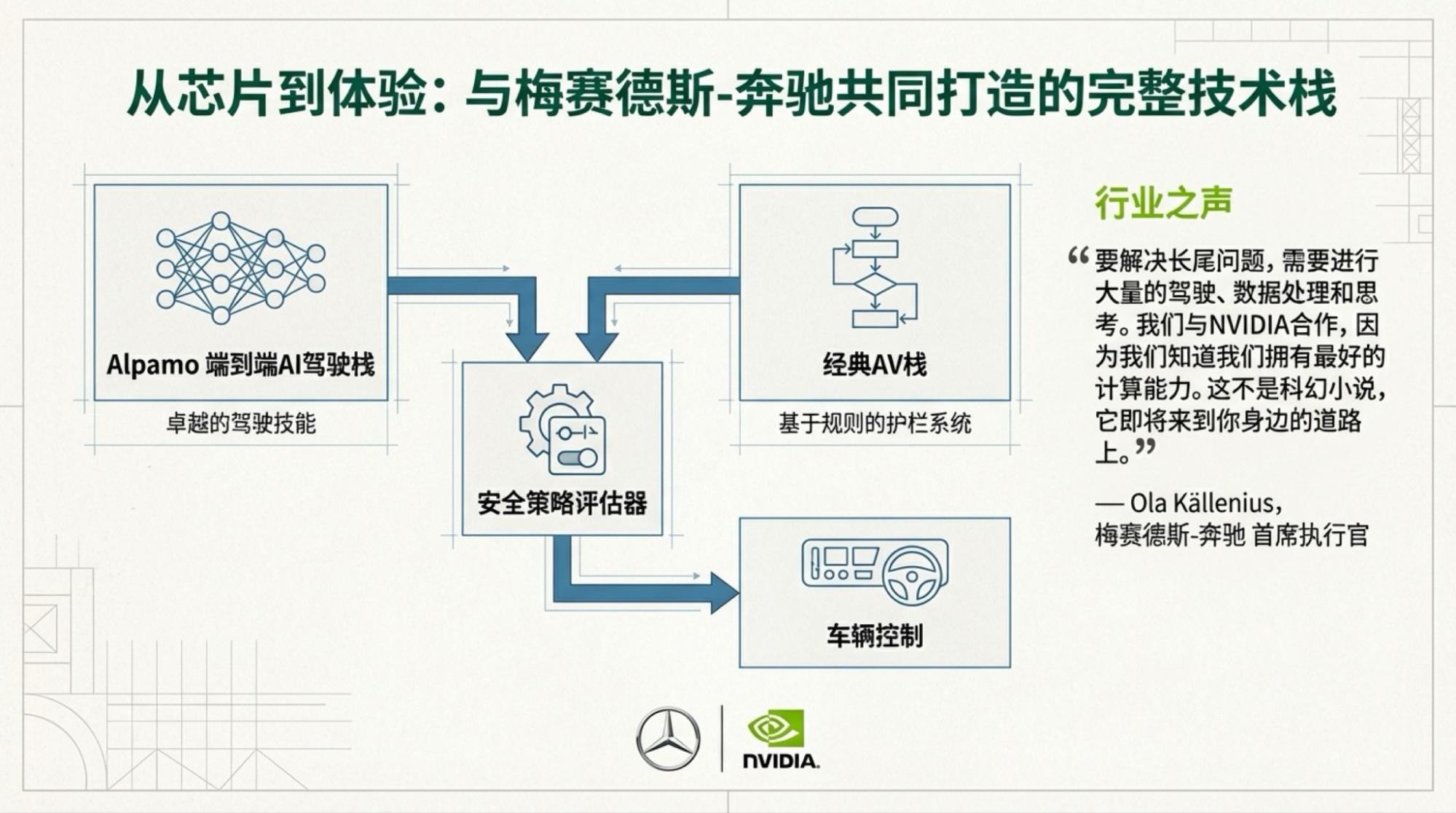
搭配实况视频,我用自己的工具做信息图(因为NotebookLM的画质不行),用NotebookLM做Slide Deck。
一个小插曲让我做了两个版本的信息图:一份是基于NotebookLM直接对视频的总结;一份是基于NotebookLM对于Youtube生成的Transcript的总结。
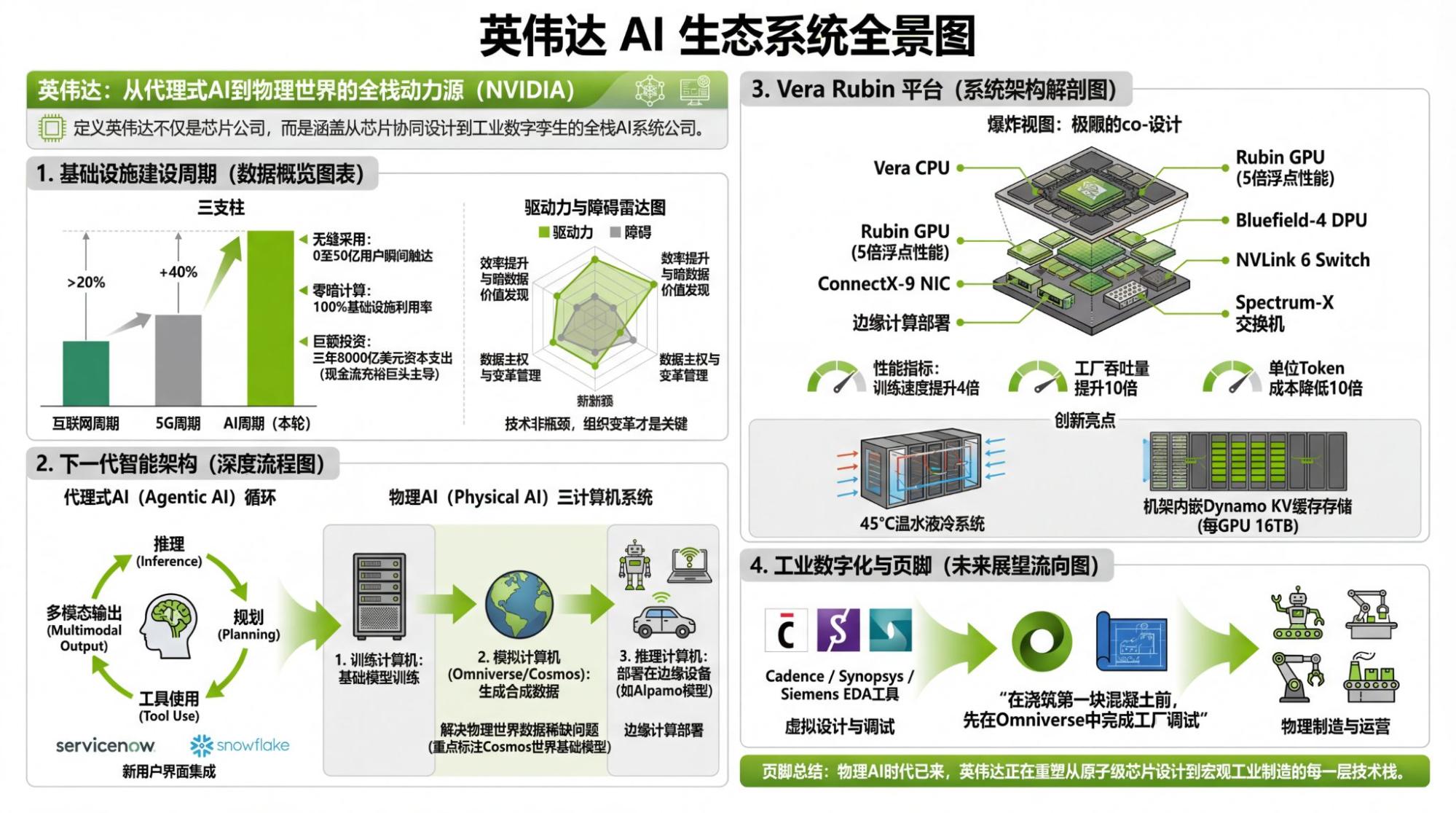
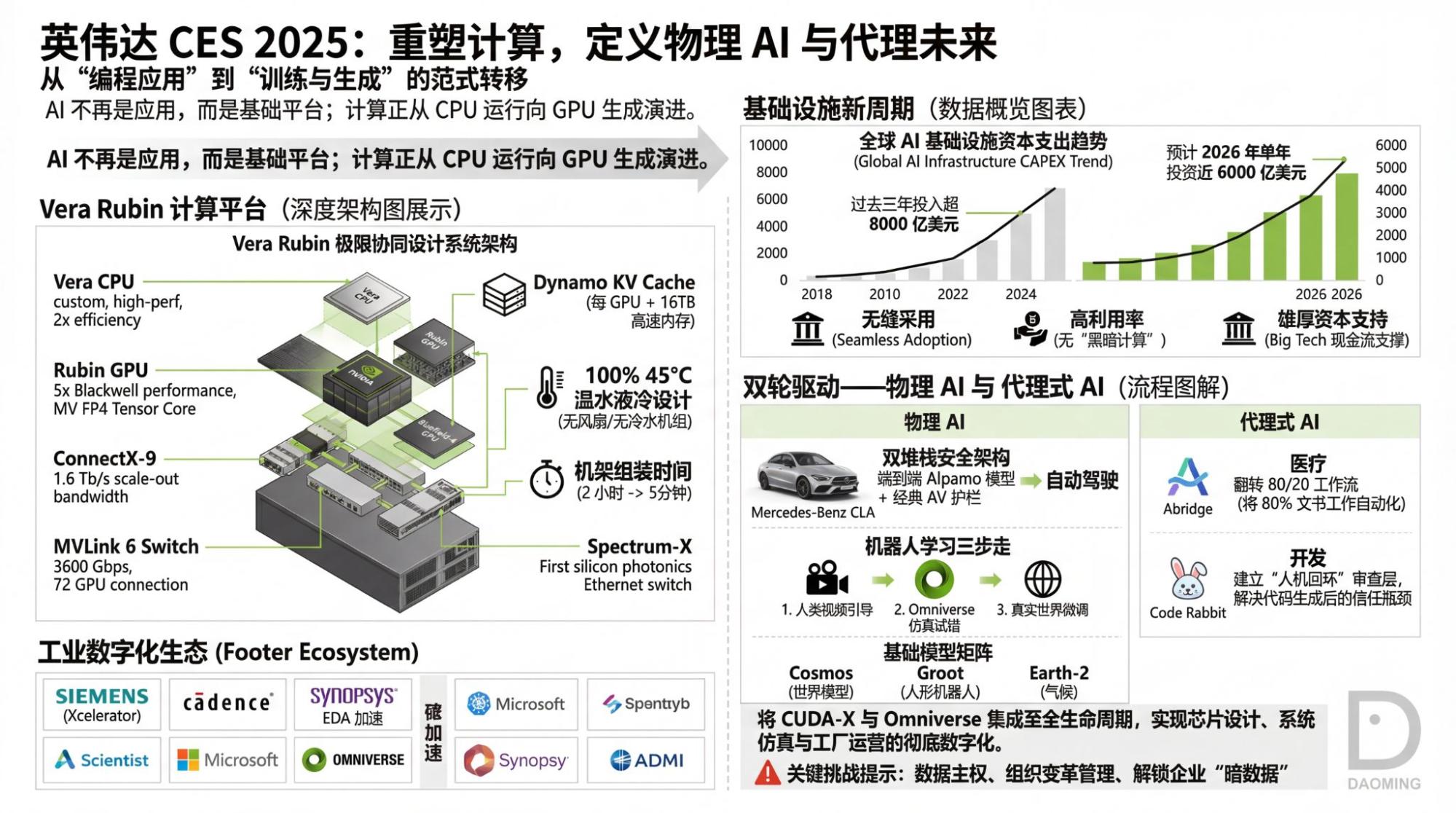
客观而言,我会稍稍喜欢第二个版本(基于Youtube的transcript,但这里面有个错误,NVLink变成了MVLink,确认了一下,transcript里就是这样的),看起来对于NotebookLM而言,读文字还是比读视频可以处理更多的信息量(token限制下)。当然,上面的错误也很明显可以看到:我们认为“智能”的模型其实一点点也不“智能”。
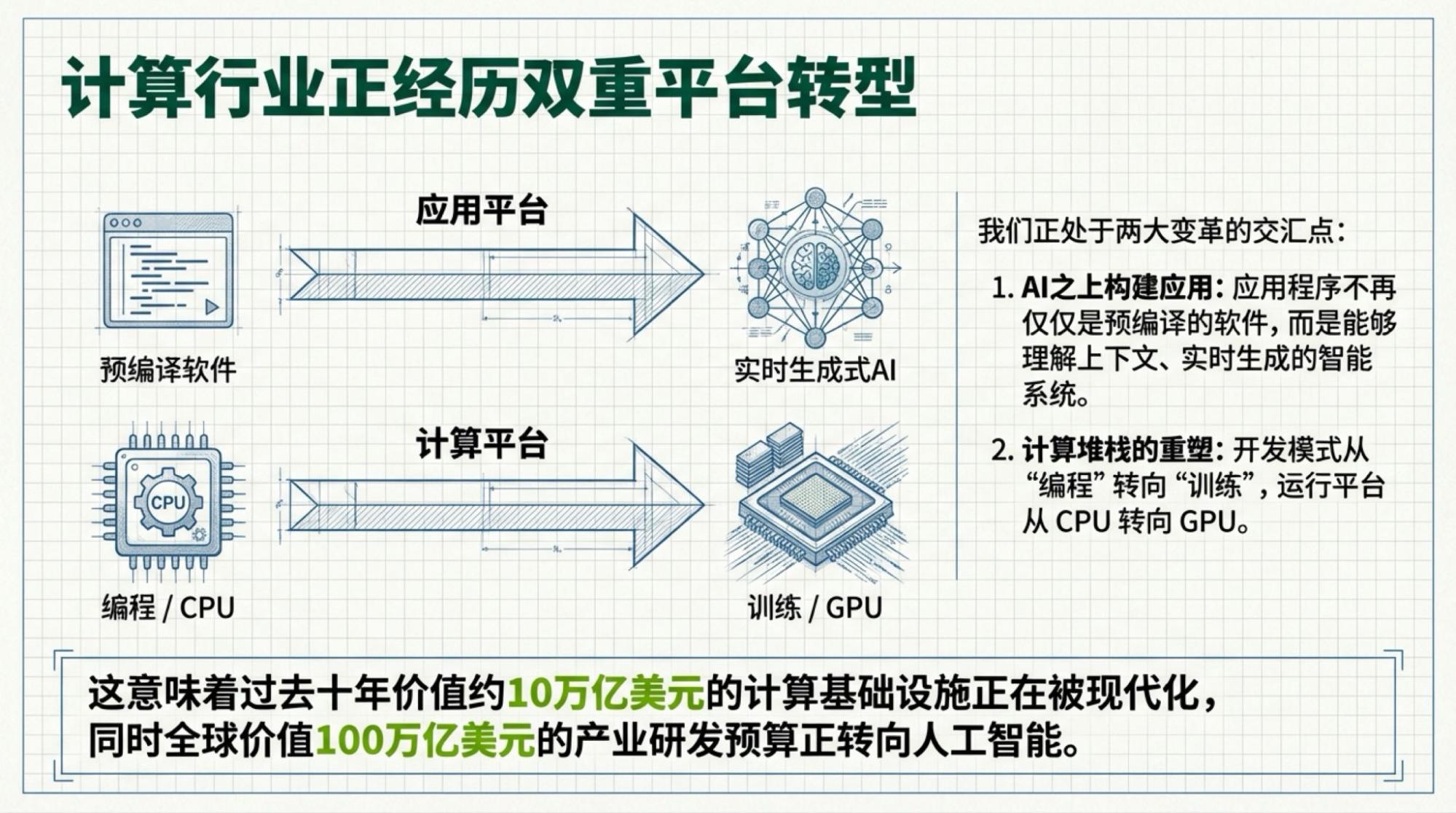
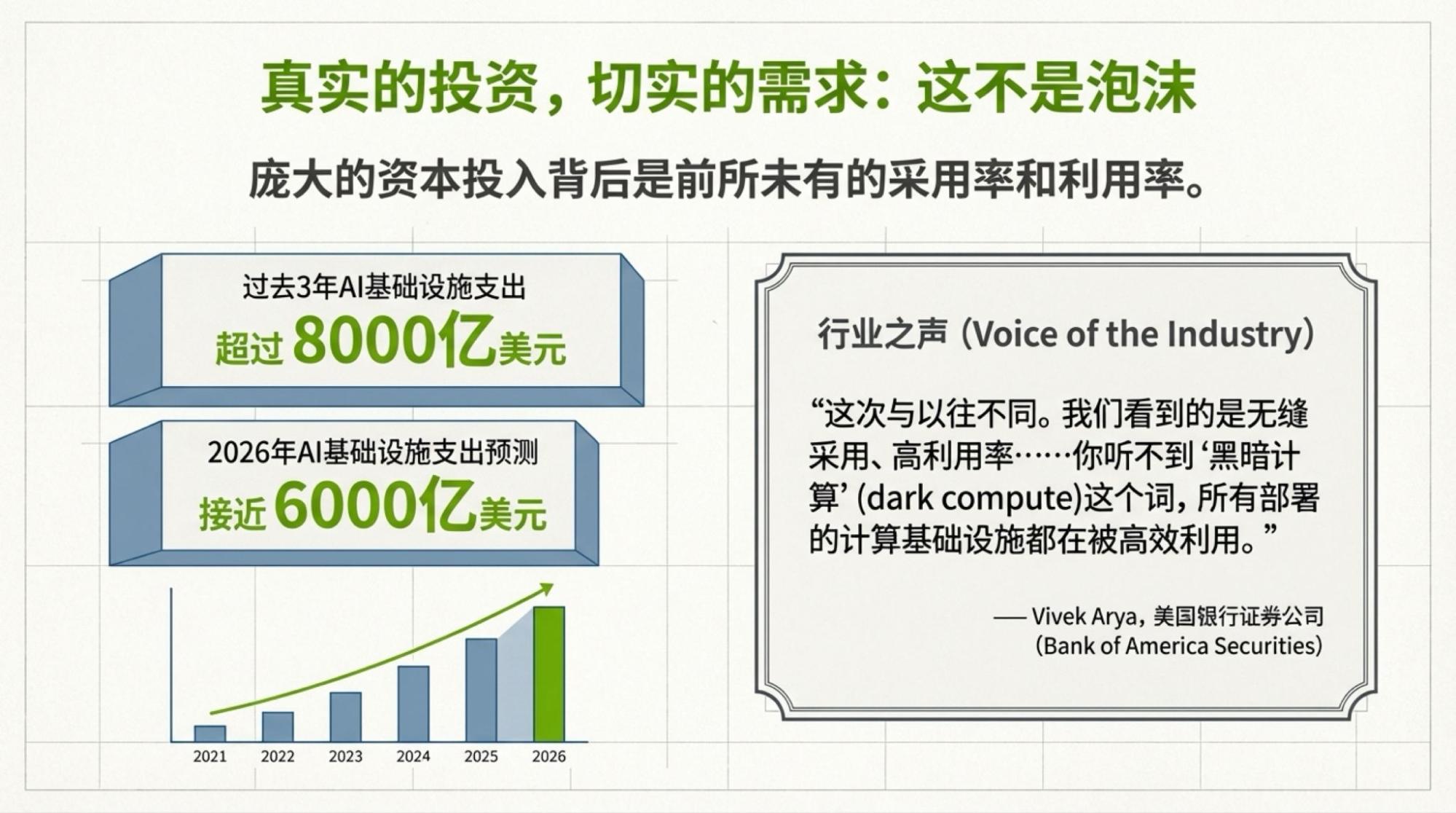
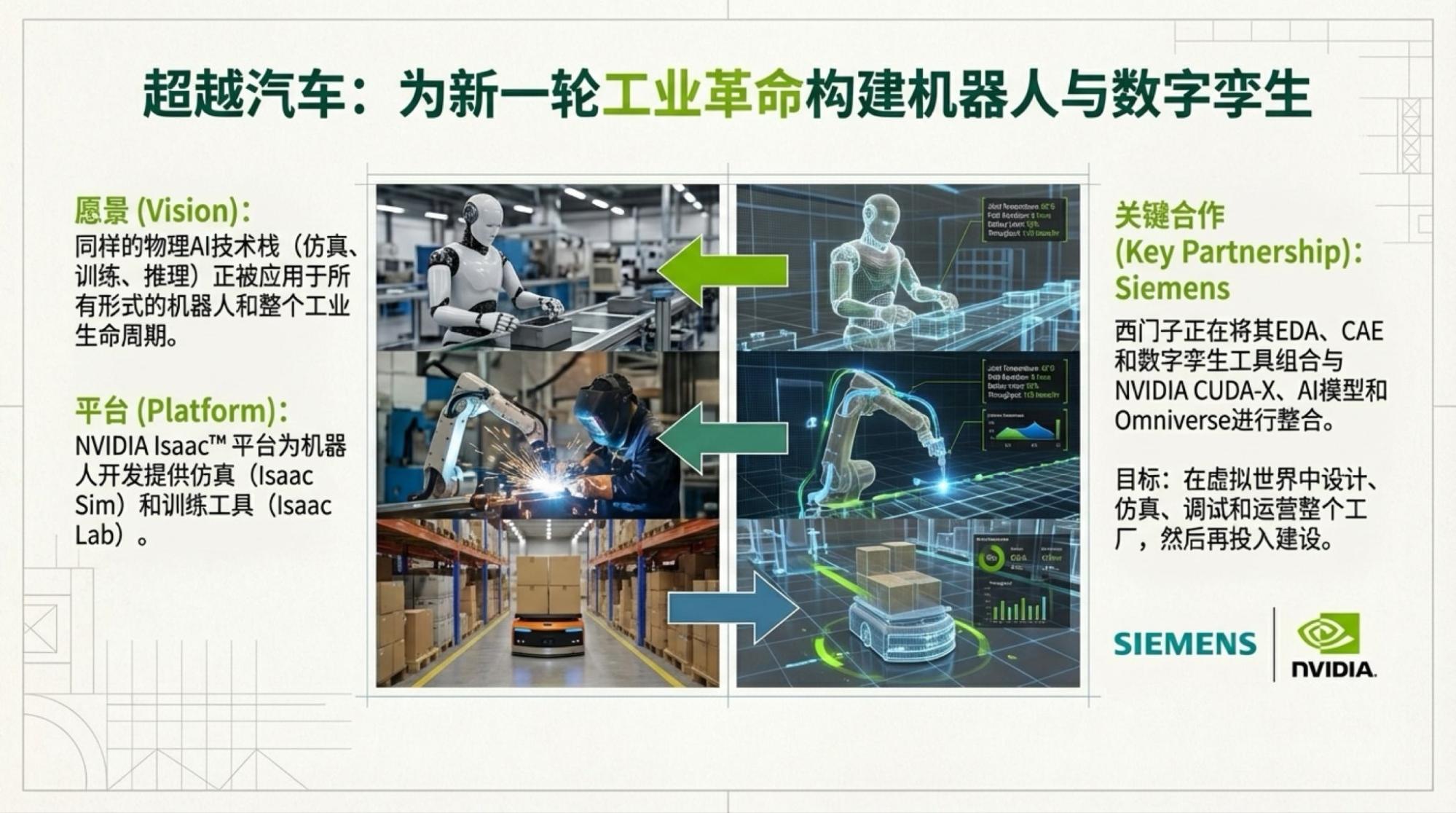
下面是每一页的Slide,基于视频内容的。