
不同环境和状态下的工作效率还是会有巨大不同的,本周逐渐开启了产出模式。正好切换到财报季了,对的,每一次的起点都是基于Gemini的Deep Research,加上NotebookLM的Slide Deck。这变成一个基准,考察目前AI水平的基准。
所以,跟前段时间的文章有一些不同,先贴结果。声明一下:仅代表Gemini生成的结果,并非我的真实观点,同时为了避免不必要的争议,我删去了关于“监管”方面的两页内容。

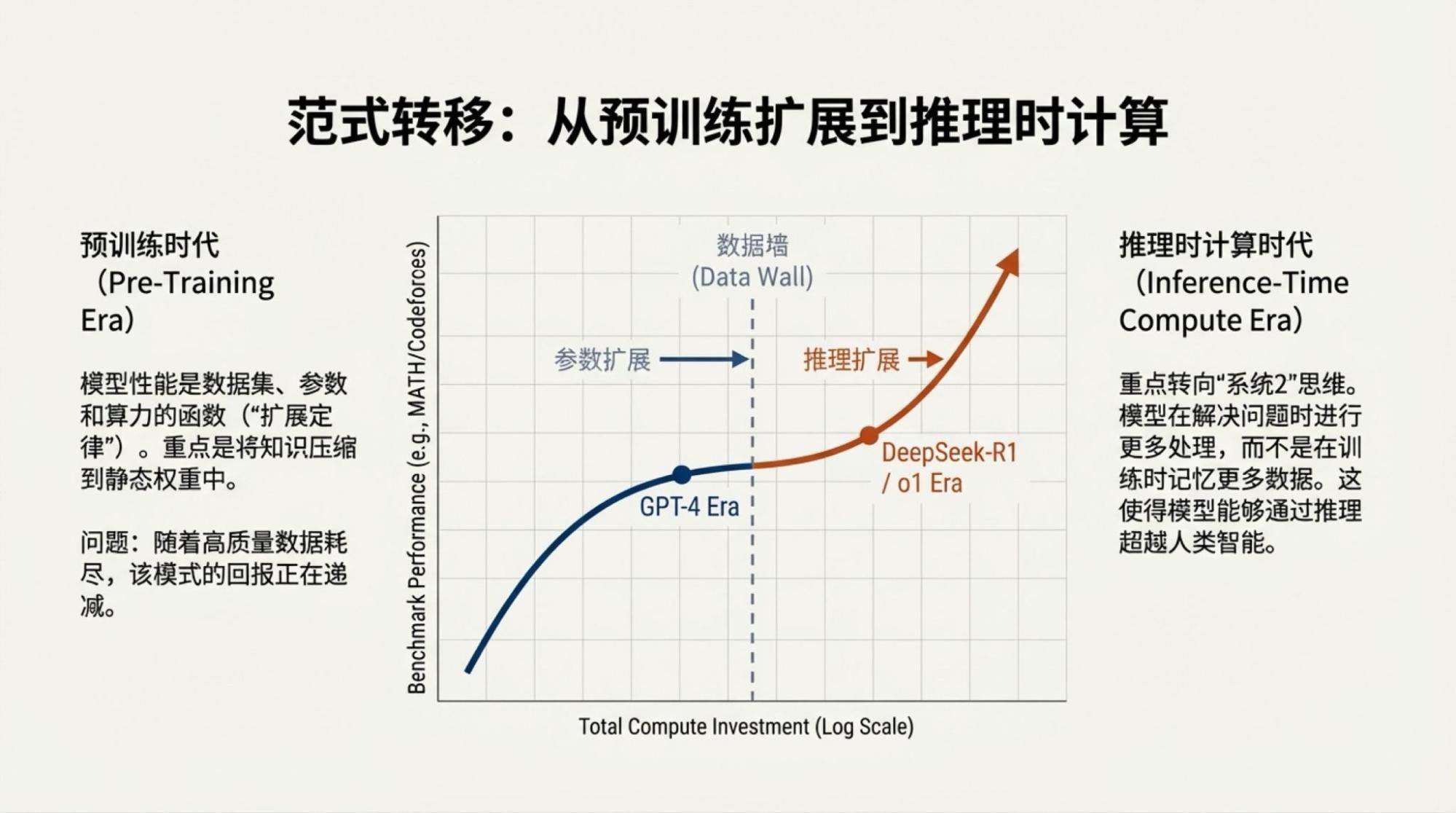


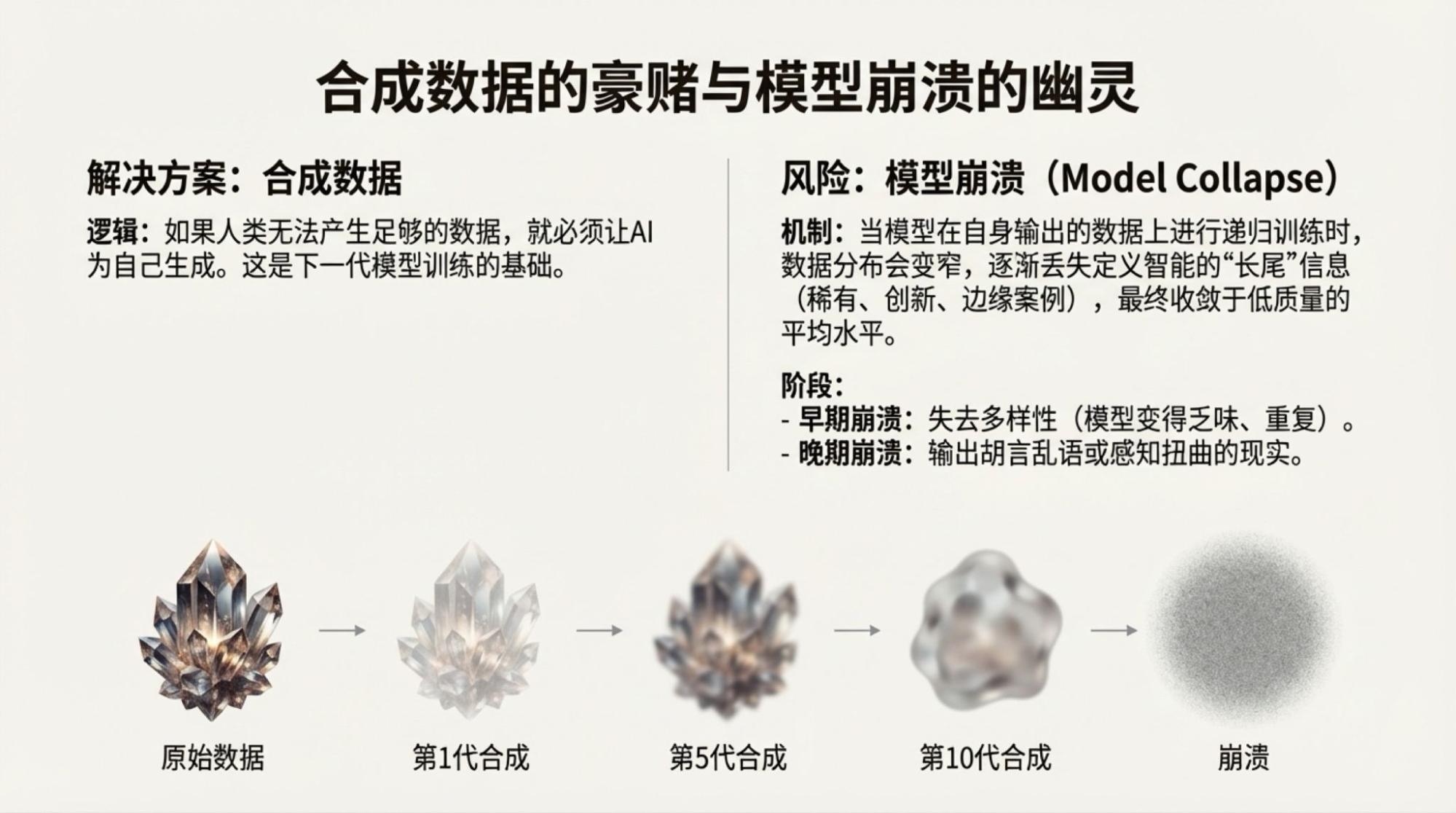
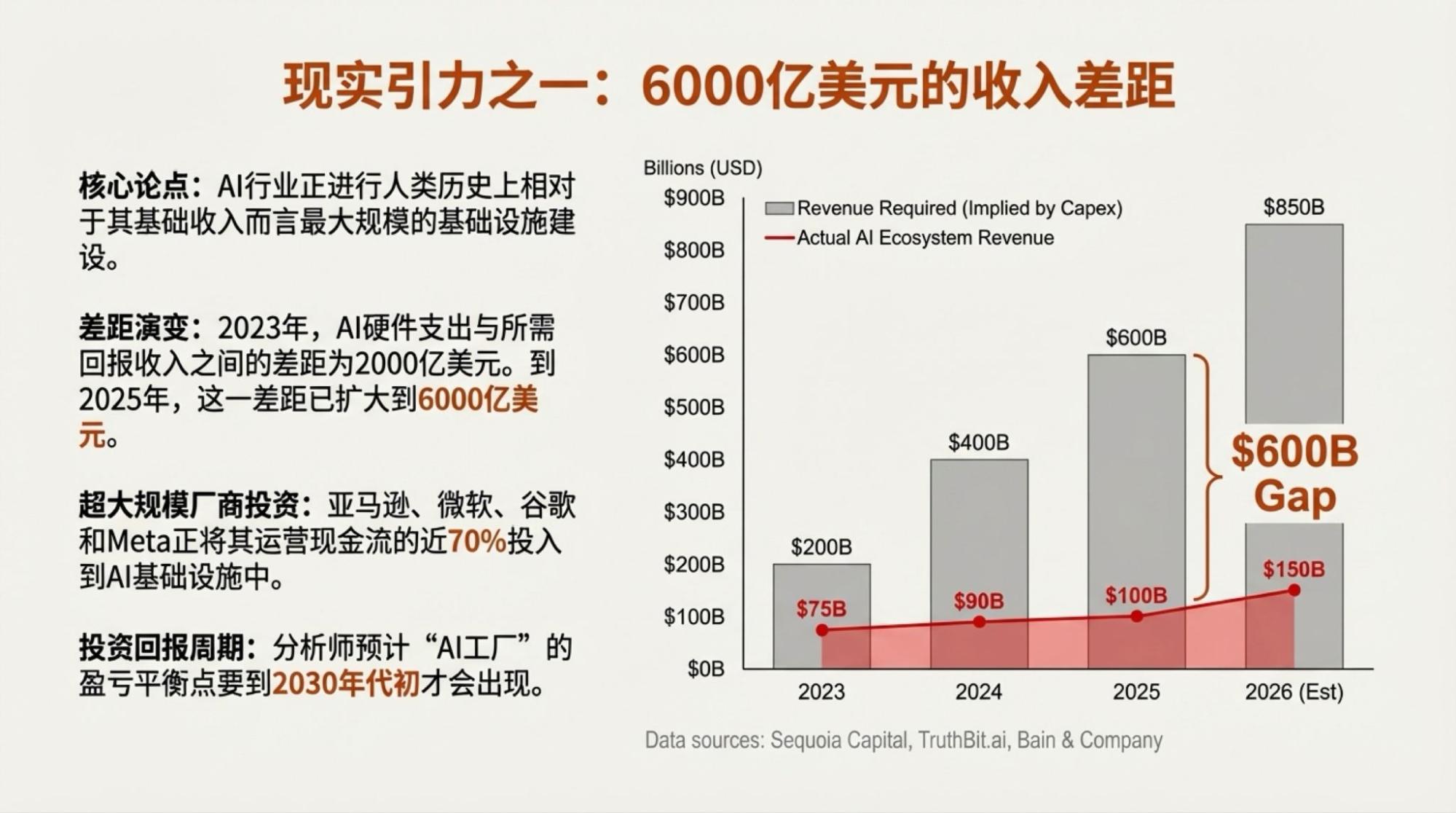
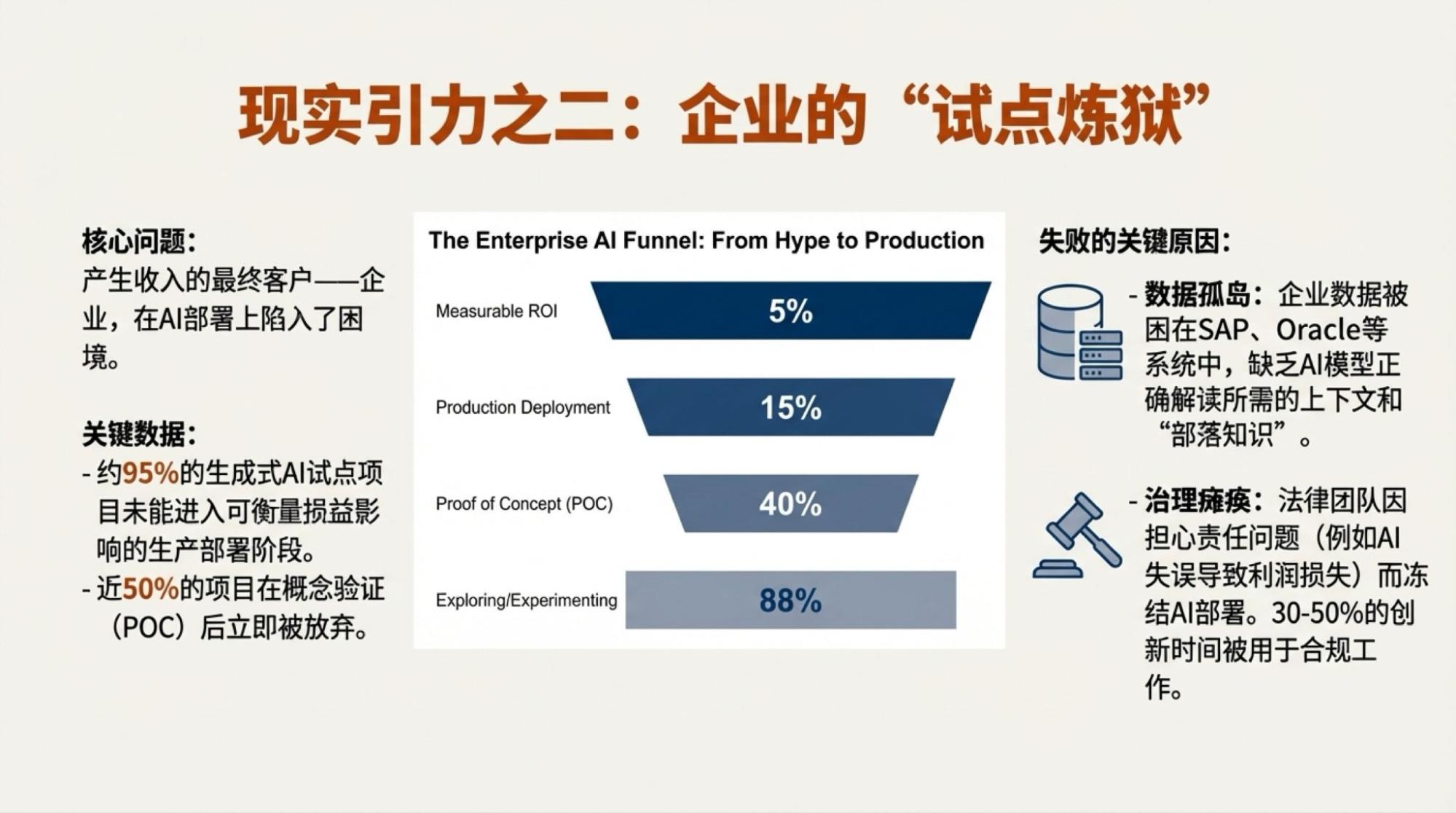

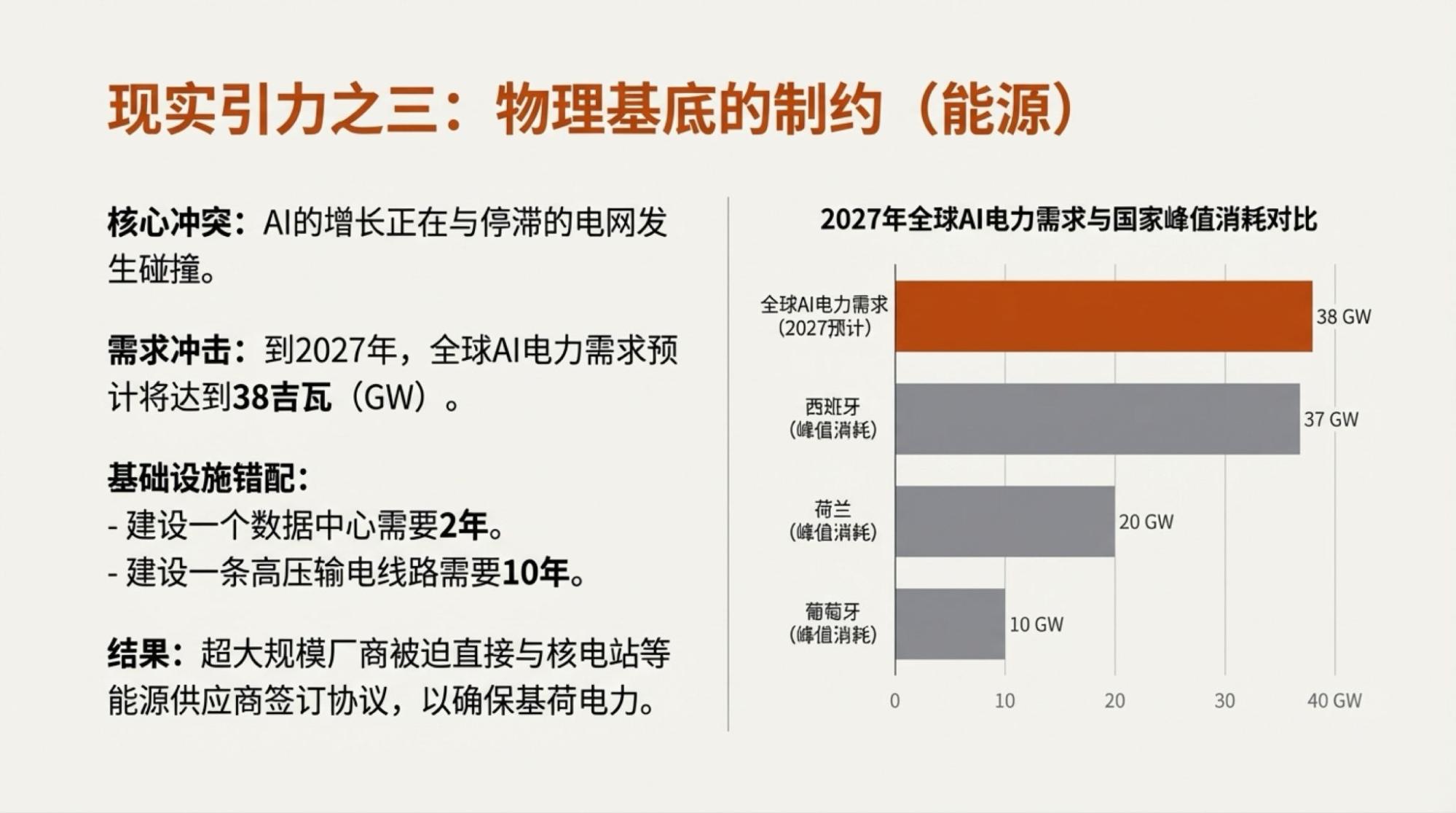




当然,说上面的内容是完全Gemini自主生成的也并非全部事实,我还是highlight了一些争议点,然后,再由模型驱动的两个工具,Deep Research和NotebookLM生成的。
客观而言,目前Gemini-3驱动的Deep Research确实有了明显的进步,比如,可以附加图表了,比如,在Plan过程中加入了较为严格的时间对齐要求(这是为了修正Gemini模型从2.5到3一直没有解决的“时间幻觉”问题)。
但是,这些都是在Agentic层面的调优,而不是pre-training阶段带来的提升。
当然,加上NotebookLM的Slide Deck后,看起来“高级”了很多,同时,存在的问题也显化了,就是AI的能力边界问题:
模型就是喜欢用“大词”,当然,罪魁祸首是互联网数据,是我们自己,是“注意力经济”,“rubish in,rubish out”,不过可能有人就是喜欢这样的大词,至少我,是很不喜欢的;
从Gemini-3的能力发挥而言,Deep Research更充分一点,NotebookLM在Nano Banana Pro的加持下很“好看”,但是注意力显然是不足的,“幻觉”也更明显;
从Gemini-3和Gemini-2.5的比较而言,我主观上认为,提升自然是有的,但是在注意力方面,几乎是没有进步的,这是模型的硬伤。直接结果是如果上下文超过200K,模型输出质量会明显下降,在这方面3似乎比2.5的问题还严重一点点,我理解是“思考”在作祟;
不少交流都认为一季度或者二季度基于Blackwell集群训练出来的模型会有“质的飞跃”,我对这一点依然保持相对谨慎的态度,在transformer架构下,我认为瓶颈已经很明显的指向数据和架构本身了。我们可能可以期望架构的优化,能够让更小规模的模型接近目前前沿模型的能力,但是让前沿模型通过规模提升得到“质的飞跃”的难度则要大很多;
虽然2025年,在Agent和多模态的加持下,模型看起来能够完成的工作多了很多,事实也是如此,但是,以Gemini为例,2.5到3,原先会错的地方还在错,真正亮眼的还是多模态,可是基于token的多模态还能获得多大的进步,也是需要观察的;
那么,问题来了,进入到充满争议的2026,边界还能近一步拓展吗?
按照我的习惯分成两个层面来讨论,第一个层面,是如何提升模型的输出质量:
显然,当模型升级时,输出质量总会提高的,所以,“等”一直是最好的答案;
提高人的输入,不是简单的提示词,不是简单的agent调用,不是上下文工程,是类似Claude的skills.md的东西,但skiils更多是规则约定,而人的输入必须包含某种outline似的思考结果,所以,是人自己的独立性启发;
第二个层面,是如何提升最终结果的输出质量,当然,是指人如何在迭代之中:
工具与流程,AI工具可以有很多,vibe coding下,“用完就扔”也没什么可惜的,重要的在于为了达到最终的业务结果,人是如何“搭积木”的,所以,没什么文科生理科生的区别;
人与AI一起迭代,如果LLM实质是一种压缩的话,那么人与AI共同工作的状态就是“扩展-->压缩-->扩展-->压缩”循环往复的过程,直到对结果满意;
人要编辑AI的结果吗?不要,我们没有能力修改生产效率是我们一百倍以上的机器产生的结果;
如果我们相信,AI就是可以完全改变这个世界,那么,眼前的必要一步就是如何让AI进入我们的世界,模型依然在进步,即使真的AGI来了,它也不会解决每一个“最后一公里”问题,边界最终由“人”来突破,但不一定需要亲自动手,做个现在和未来有限一段时间的AI的“人类导师‘的角色,至少,这个过程可以很享受的。