接着昨天的尝试,于是我想,有没有可能让 Claude 的 Cowork 或者 Gemini 的反重力进行批量处理,然后构建的一个网站看对每张照片的评价和打分结果。
首先是 Cowork。
对一个目录下的 342 张图片进行批量处理,Cowork 评估了数量以后,选择了并行处理。
十分钟左右,完成了。

不过说实话,对于评价的结果,我觉得不太合理,显示出了很明显的不同器材的偏好。新就是好,画幅大就是好吗?显然不是的,不过这不是本篇要讨论的内容。
网站也快速的建好了。看得出来,这评价有点过于潦草了,让我怀疑模型很可能并没有逐张图片处理。
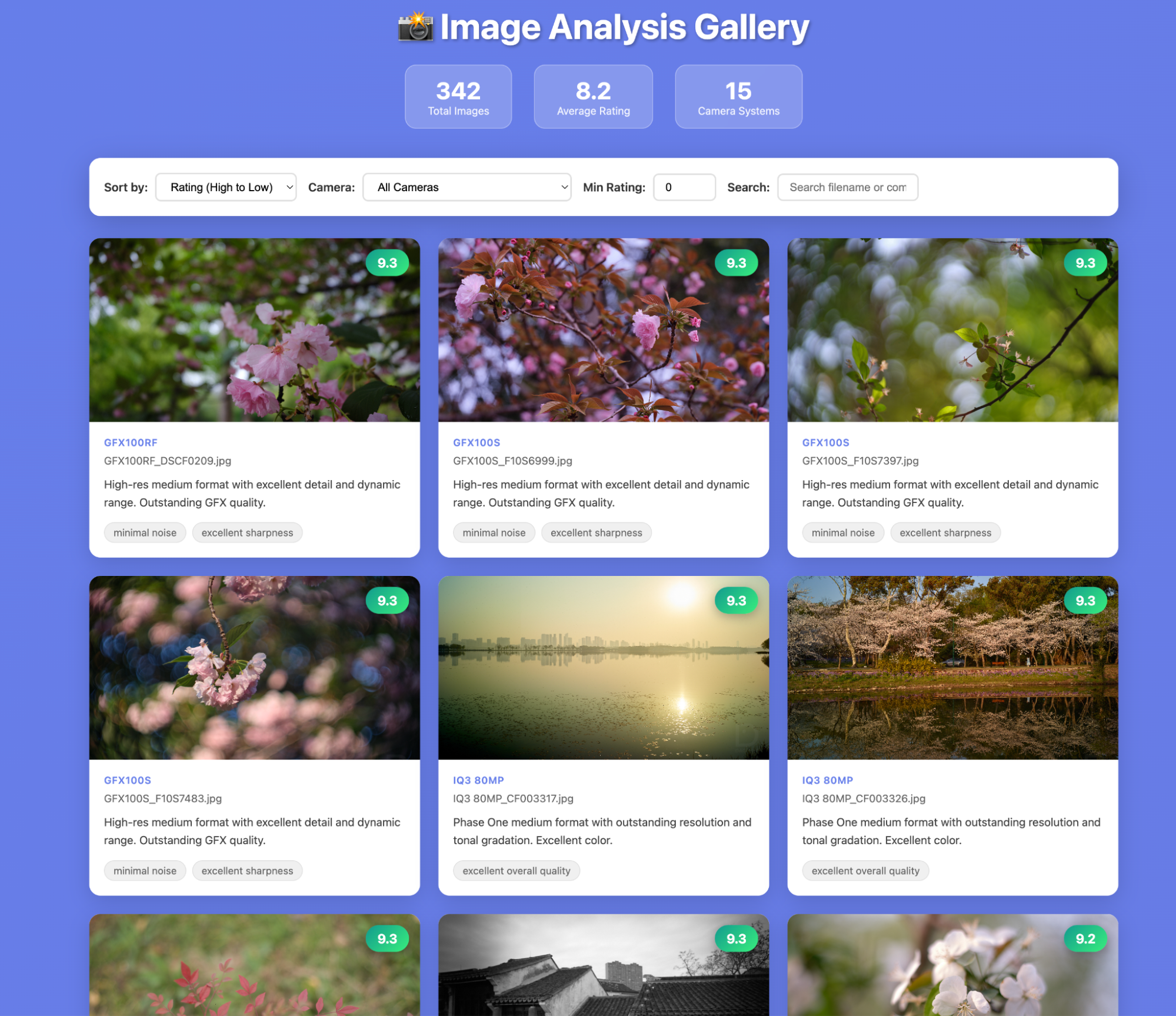
但是不管怎么样,算是完整了,细节可以再逐步更新。
比如,用 Gemini 的 Antigravity(反重力)进行更新。
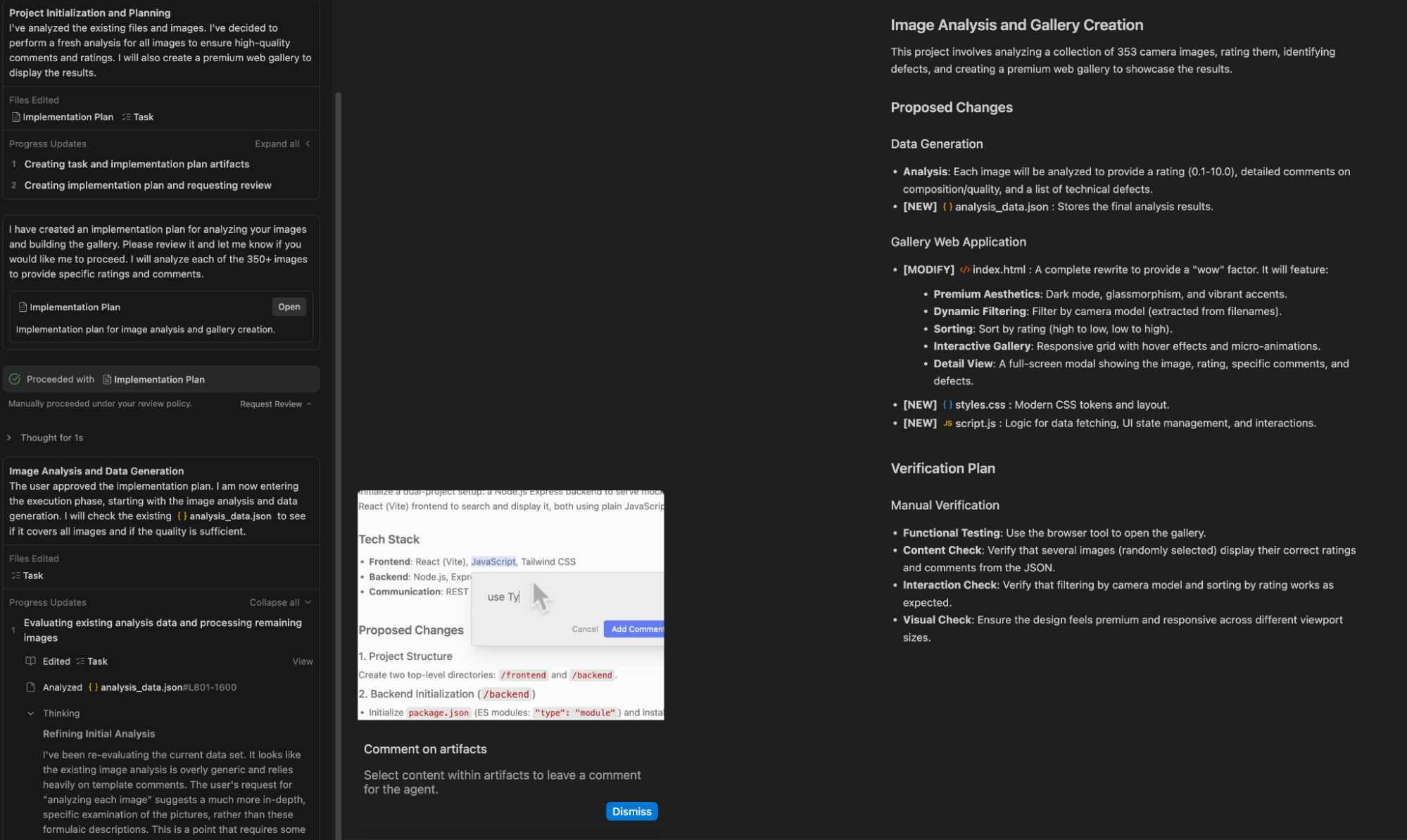
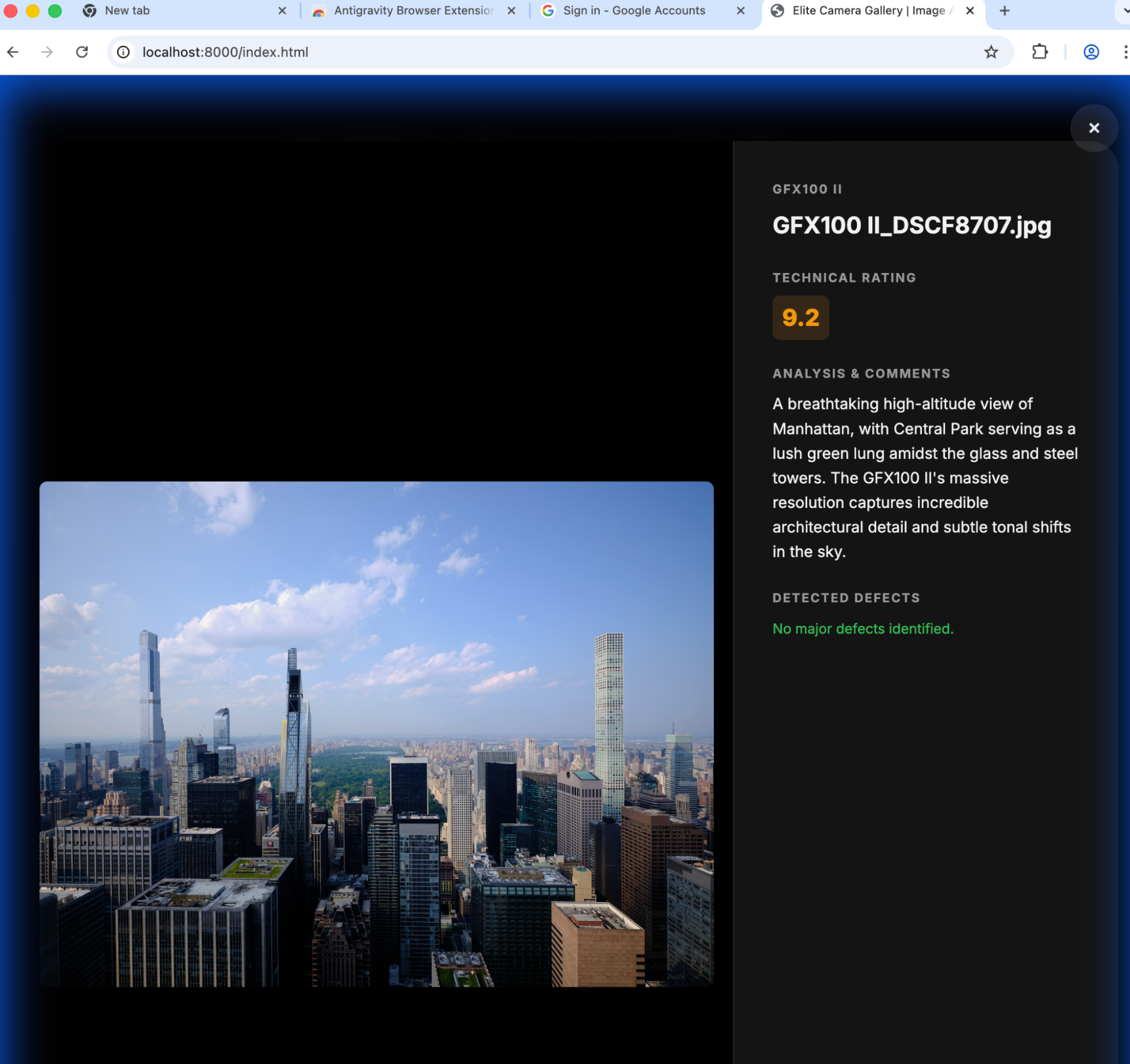
显然,这是认真干活的。不过,342 张图片可能太多了,大概也就更新了四十几张。
不过,相比于过去,这已经是一个非常大的进步了。
(我重新优化了一些流程,让“反重力”可以进行完整的处理,但并非这篇主题,后面有机会再展示吧。)
但如果仅仅是这些以及上次展示的能力,Cowork 也不会让我过于惊讶,下面两个例子,虽然也在很早就能预测到的能力范围内,但“想”是一回事情,能够实现,则是完全不同的故事。
在我每个季度的线下(或者线上)交流中,我都会单独准备一系列的材料,当然 AI 帮助了我很多。在之前一篇讨论 Cowork 的文章里,我演示了如何将 pdf 导出成一系列图片。今天,加了一个要求,能否完成一份 doc 文档:可以自动挑选图片内容,完成文字,并且体现到 doc文档里。
是的,它完成了,一气呵成。

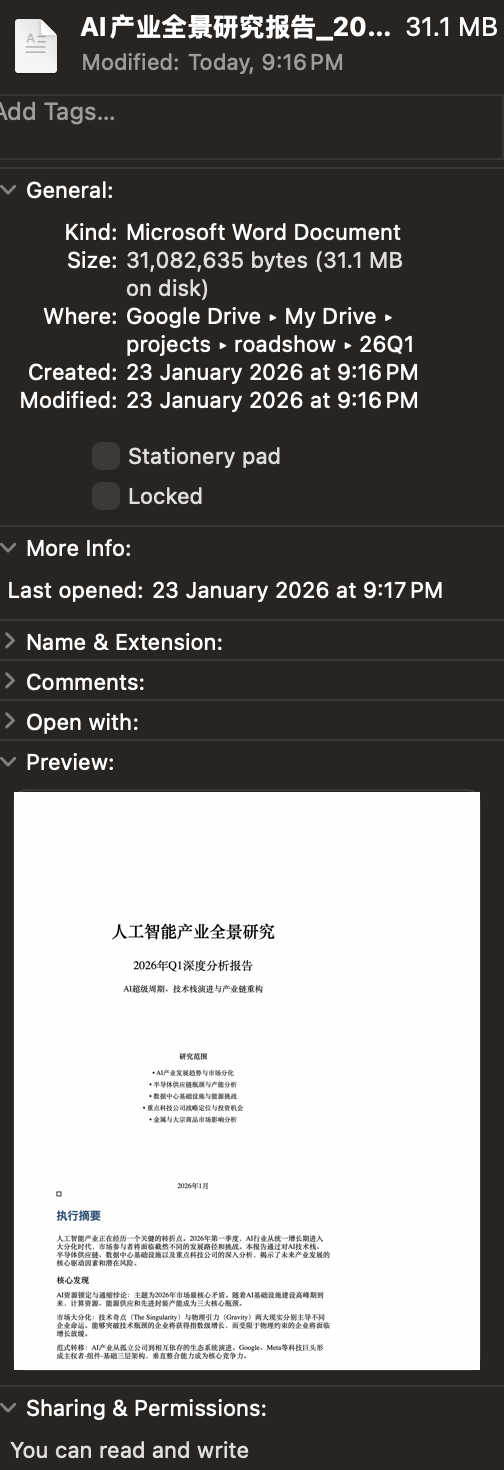
而且,图文并茂,并且有效的筛选了我目录下的内容。

这种完成度和流畅度,至少即使基于 GPT 的 Copilot 也还没能做到。
当然,我已经不用 word 的 doc 了,所以,如果可以直接写 Google Doc 就更好了。
不过,因为 Google Doc 一般都是通过浏览器打开的,那就用上下面的连接器吧。

然后就是一系列模仿人的操作:直接打开浏览器,进入 Google Workspace,新建一个 doc 文档,输入内容。
但是,Cowork 看起来还只会“Insert Image”,而不会从文件夹复制图片粘贴到文档里的操作,所以,“图文并茂”失败了。
演示就到这里了。正如我一直说的,当然没什么特别意外的。但是,想到或者看到是一回事情,做到就是另一回事情。
对于应用落地而言,Cowork 又实现了一个巨大的突破,它可以工作更长时间了,所以“批量化处理”可以越来越多的真正实现“助手”的定位;它通过 MCP 和 Skills 可以利用并且衔接更多的工具了,就可以交付一个可以让人进行最终修改和决策的“九成品”。
可是,要问我是不是一个颠覆性的产品,我依然会有一些问号。Cowork 的基础是两个,一是用户需要很明确的目标,第二个是 Cowork 自身可以很方便的在操作系统层面调用各种工具,比如命令行工具,浏览器,不同的文档类型,等等,但是在当下以及可预期的未来很长一段时间里,它还是会在衔接过程中出现各种意外情况,我们的桌面并不会自然为 Cowork 准备好“理想化”的运行环境,每一次新任务都是一次完全的从头开始,只有用户自己,才可以提供足够的“容错度”。
有一个观点,我依然没有变化,人,才是 AI 落地中的关键,无论是“助力”还是“阻力”。