
关于明年的前瞻,在脑子里又过了很长的一段时间,在我构思期间,一个可预期的重大变化发生了:Gemini-3和Nano banana Pro模型的发布。它的意义不是某个评分榜,不是似乎证明scaling law依然工作,无论在预训练还是后训练。它的意义在于:当模型在某个领域打破人类能力的天花板时,带动的是整个数字世界的变化。
于是,从形式上讲,这一篇前瞻,我不需要去整理数据,整理图表,视频,去引用,因为模型可以帮助我,尽管依然不够完美,但它已经在几乎所有的工具性的部分大幅超越了我,不仅是能力,更是执行效率。
从内容上讲,这一篇前瞻,可以更宏观一点,因为细节的部分,模型也可以去填补,不必在我的“指挥之下”,而是在任何人的指挥之下。
In Case文字很无聊,那么可以有一些不同的表达形式:一些“脏东西”。


那么,从哪里开始呢?
从智能开始。当那些巨头们不惜一切代价投算力,投数据中心,投电力时,只有一个终极目标:智能。我们依然不太能够完整的表述出“智能”是什么,但它应该像人类一样,可以主动思考,可以适应足够广泛的场景,自主执行,自主成长。
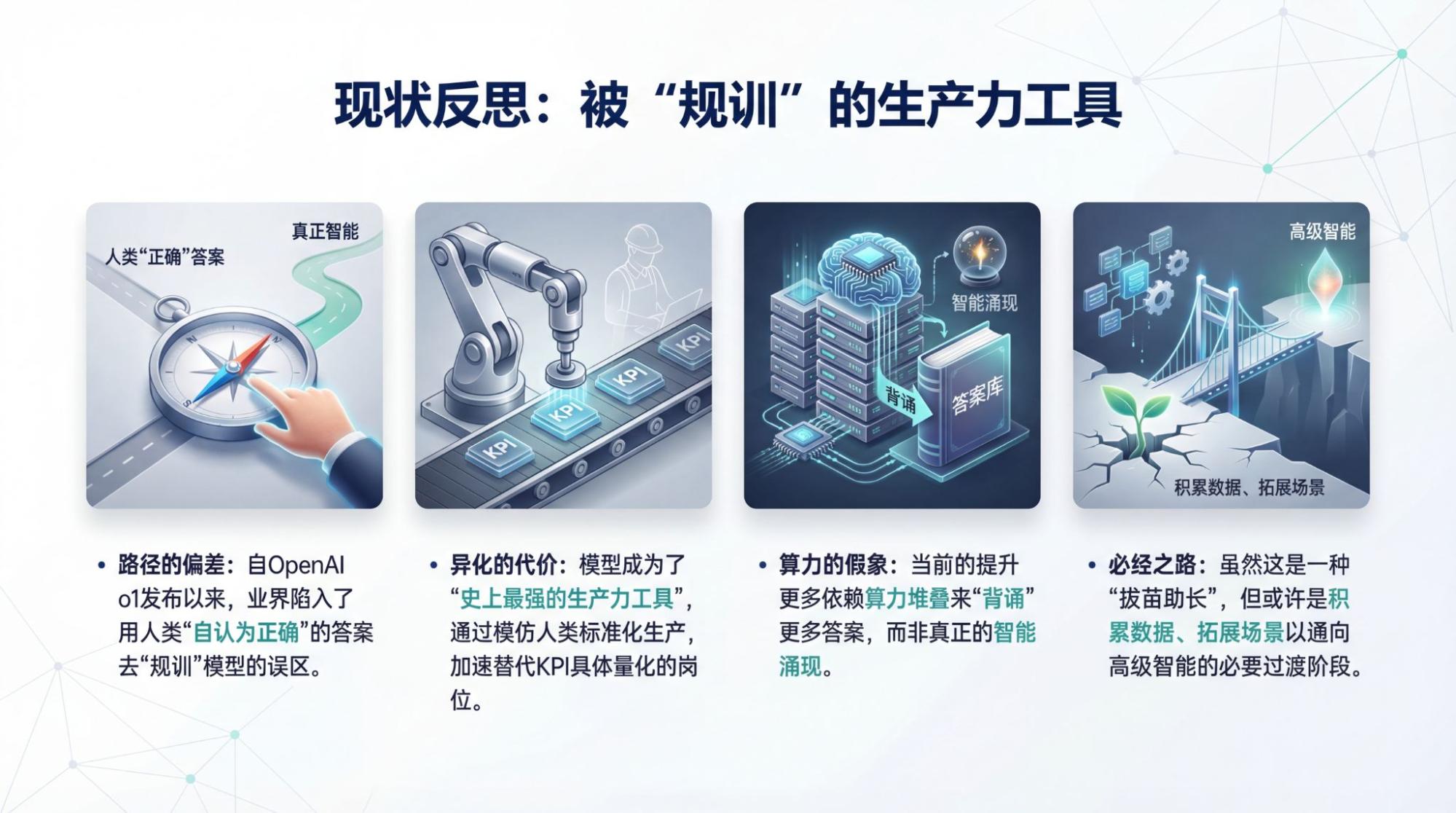
这是这篇前瞻标题的起点:“The Bitter Lesson”,“强化学习之父”Sutton的总结。很多中文翻译成“苦涩的教训”,我会觉得“艰涩”可能会更适合当下和未来。
所谓the bitter lesson是指,任何试图教模型规则和知识的“规训”,最后都会被“让模型在更多数据中自我成长”打败。
如果我们相信这一点的话(至少我完全相信),那么现实的问题是两个:当下的模型走在正确的路上吗?未来的方向又在哪里?
这才是我认为使用“艰涩”可能会更好的原因:因为如果我们相信数据,就会知道数据拓展之路会多么艰难。
回到现实的问题。
当下的模型走在正确的道路上吗?我认为不是。自从去年OpenAI发布o1思考模型以后,就不再是了。我们为了让模型看起来有用,就使用了一堆我们人类“自认为正确”的答案和过程来规训模型,让它可以“模仿”我们做很多事情。
这个问题,其实我讨论了好几次了,从很大程度上而言,这是一件好事,它让AI真的提前成为了“史上最强的生产力工具”。
但它又是一种破坏性巨大的“异化”,它选择了一条最好走的路,在数据最多的地方,在人类曾经“最自豪”的领域:所谓的知识与刷题,所谓的标准化生产。
在今天我们已经无须讨论AI会不会取代人类工作这个问题了,因为很多岗位正在而且会加速被迭代掉:那些KPI最具体最量化的领域。
之所以更多的岗位看起来依然安全,背后的原因只有一个:算力不够。
我认为这条路不是通向我们理解的智能的正确道路的原因也只有一个:模型只是在快速背诵人类实践得到的答案,而这个答案本身是否正确,其实谁都说不清楚。
算力提升10倍,我们可能可以多记住两三倍的“答案”,算力提升10倍,我们可能可以在同样的时间里多背诵两三倍的“答案”。仅此而已。
不过,这又可能是我们的必经之路,当算力和数据不足的时候,我们也许只能靠不断加入人类的“小聪明”去“拔苗助长”,但这种拔苗助长也许也可以让我们获得更多的数据,拓展更多的场景,最终得到不需要“小聪明”的高级版。
只不过,这条路必然充满“艰涩”。
第二个问题,未来的方向又在哪里?每一个人都可以对自己的“智能”有不同的理解,可是,知识本身似乎并没有让我们变得更“聪明”,我们的聪明更多好像是从一次次错误教训中吸取的,只不过不同的人从犯错中举一反三的能力并不相同,不同的人从别人的错误中吸取教训的能力也不同。我们尝试,犯错,思考,优化,再尝试,成功,再思考再尝试再犯错……
无数次的往复成就了我们每个人的现在,成就了人类的现在:一个理发师做学徒时手脚一定是很笨拙的,一个实习护士大概率也找不准静脉的准确位置,可就是在无数次的重复和尝试中,才成就了他们或者她们的熟能生巧。我猜想,大概率他们或者她们成长过程中的数据并没有被显性地记录下来,但我们的大脑可能就会在我们无感的情况下,开启“看不见的数据训练模式”,最终让我们变得更快更高更强。
我不知道如果这些数据全被显性记录下来,能否让模型也达到这样的“熟能生巧”,大概率是可以的。但,大概率它又不会与我们人类走同样的“成长之路”:同样一个人,经过一定时间的训练,就能可见的大幅提升四则运算的速度,而模型,速度的提升可能更多需要依靠算力的提升来达到。
即使有足够的数据,同样硬件下的反复训练可能并不能提升模型的速度。尽管很多算法优化可以显著提升模型的速度,但是正如大量的计算机算法一样,我们竭尽全力,也许O(N*N)到O(NlogN)也就是我们可以达到的极限了。
但如果,我们不做什么规训,不做什么优化,只要有足够的数据,模型是不是终有一天可以自己找到大幅优化自己的方法?如果我们相信“艰涩的教训”的话,应该可以相信这点,至少我很相信。
我们没找到这些方法,只是因为它们还在我们所谓“知识的盲区”,但只要有足够的数据,未知就可能成为已知。
那么,会是世界模型吗?
我给不出“世界模型”的具体定义,甚至所有号称研究世界模型的团队或者领军人物,可能给出的答案也五花八门:有人认为我们可能需要一个完全数字化的这个世界的镜像,有人说到需要对力有表达,有人说,它要符合物理规律……
但是,似乎他们收敛到了一点:数据。但是,似乎,他们又自相矛盾,如果数据是最重要的,那我们为什么还要强加规则呢?
某种程度上,如今所说的“世界模型”可能只是继思考模型后又一条错误:我们总想用自己的“成功经验”去规训模型,可是我们自己其实都根本不理解数据。
但无所谓,无论是走哪条路,无论是未来的路到底在哪里,大概率,足够的数据积累都是必经之路。
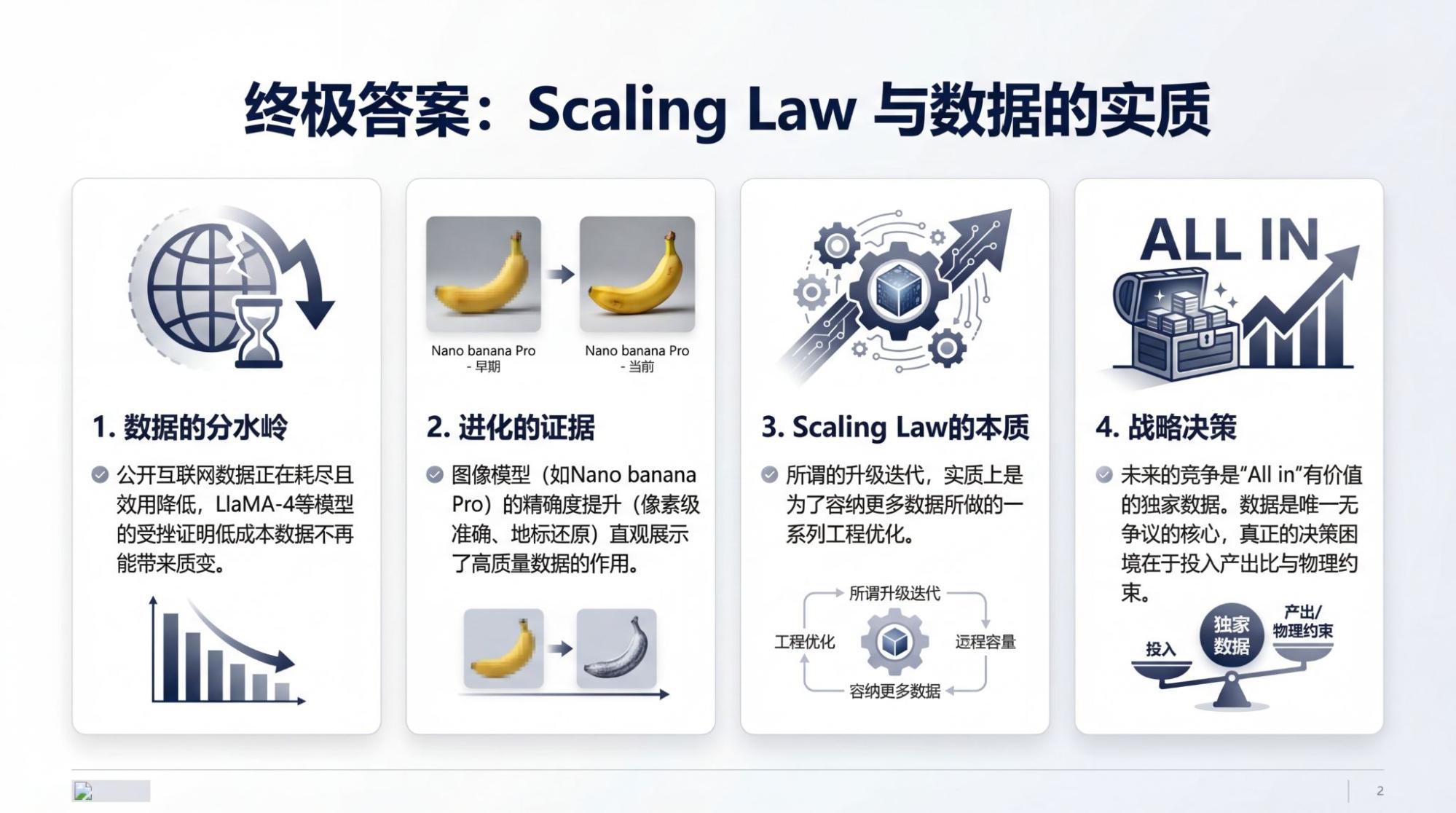
公开的互联网数据确实在快速耗尽,不过,即使公开数据依然大规模使用,真正给模型带来提升的也不再是这些低成本的数据了。否则,LlaMA-4模型不会失败了,否则Grok系列模型不会看起来很好,用起来总是低于预期了……
如今的模型过于“直接”了,直接到,在一代一代的模型迭代里,肉眼可见的进步都可以用数据来解释:如果文本模型还不那么直观的话,那么类似于nano banana(pro)模型这样的图像模型可以很清晰的看到数据量增大的效果证据,不是来自于可以将文字渲染正确,而是对真实世界描绘的精确度,来自于地标信息的准确性,来自于信息图里每个元素的准确性。

依然回到不少人看起来挺不适的一张信息图,问题从来不在于好看还是不好看,问题一直在细节之中。

我们很快就可以获得像素级别的完全正确,同时获得不断提升的像素,从1k到4k,为什么下一步不可以8k?
每一个像素也都在诉说着模型蕴含越来越多数据的证明,而所谓的升级迭代,无非就是为了容纳更多数据的一系列工程优化罢了,这也是Scaling Law的实质。
All in,在一切大量产生有价值独家数据的节点上,如果“是否值得用更大的投入去容纳这么多数据,是否可以等一等硬件进步的累积再以更低成本的方式迭代”逐渐成为一个物理约束和收支平衡考量下的决策困境。
数据,是唯一没有争议的。有争议的,只是,哪些数据?