
It is necessary to use the shortest possible space to recap some "new models" released over the past week that were somewhat ill-timed, as they coincided with Sora's viral spread.
The road to AGI is full of uncertainties. The ideas of every major player are actually very important. Perhaps the performance of a specific model isn't necessarily eye-catching, but there are more or less many highlights within it. As I mentioned in yesterday's article: confirming some assumptions, refuting others, and proposing new ones...
So, the first one is Meta's V-JEPA, released on February 15.
This is not a generative model; instead, it predicts missing or obscured parts of a video. The full name is Video Joint Embedding Predictive Architecture.
Pre-training uses unlabeled video data.
The goal of the model is to gradually learn and understand the concepts of the physical world internally, much like an infant. An intuitive effect is that the model can understand concepts like "tearing something into two halves."
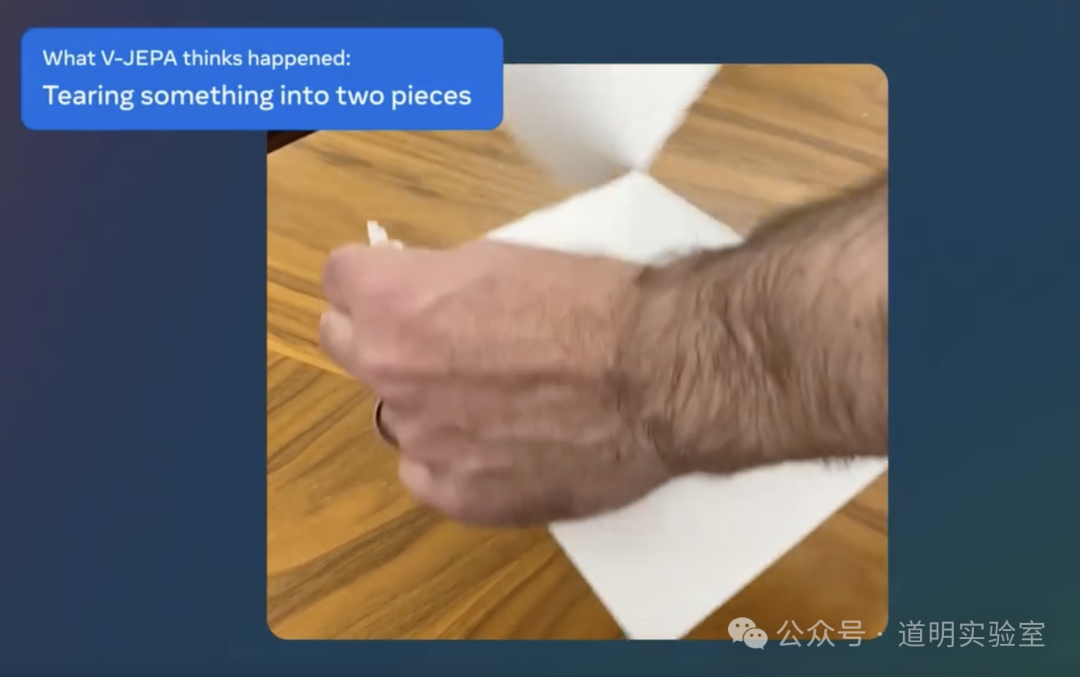
The model is open-source, including training code. It was trained on the "VideoMix2M" dataset, but due to time constraints, I haven't found this dataset yet, so it's unclear if it is publicly available.
Preliminary conclusion: This model is clearly experimental, used to validate hypotheses regarding AI reasoning and planning capabilities. The largest model parameter size is only 630 million, and it is currently impossible to verify if it can scale (performance improving as scale increases), though initial impressions suggest it can.
A "brainstorming" thought: Relying on Meta's own image segmentation algorithm to segment images in the video, applying random masking, and using self-supervised learning—doesn't this feel like our student days when we did practice problems and checked our own answers, eventually reaching a state where "practice makes perfect"?
The second model is Stability AI's Stable Cascade.
- It outperforms Stable Diffusion XL (Turbo) with faster inference speeds.
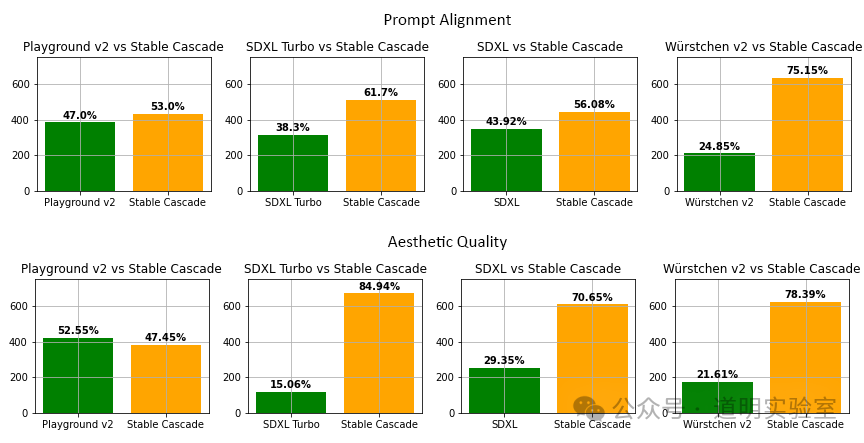
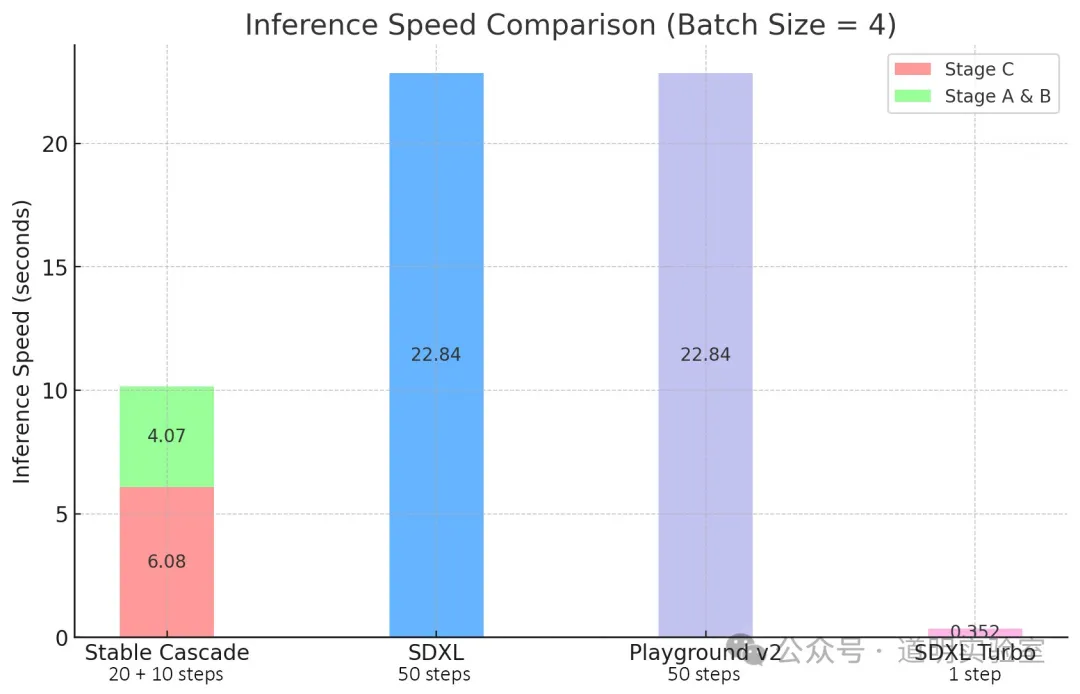
It uses the "Würstchen" architecture, which allows for a smaller latent space, resulting in faster inference and better results.
It is open-source—not just the model parameters, but also the training and fine-tuning scripts.
Hyper-competitive.
The third model is Cohere's Aya, a multi-modal, open-source model.
It "surpasses" all current open-source multi-modal models.
It was co-developed by over 3,000 independent researchers worldwide.
It appears to have very detailed data and model documentation, making it well-suited for a deep dive.
The fourth model is Amazon's BASE-TTS.
A speech synthesis model with a billion parameters, trained on 100,000 hours of data. It claims that "emergence" has occurred.
Summary
AI research is currently the most competitive field. I originally thought we wouldn't see milestone progress from various companies until March or April, but it has already begun. AI R&D seems to be transforming from a series of discrete pulses into a continuous curve.
However, it is increasingly obvious that we rarely see an unknown company suddenly release a major model. If 2023 was the preliminary round, 2024 has at least entered the semi-finals. Companies that haven't made an appearance by now can likely be considered out. How many will be eliminated in the semi-finals? Likely the vast majority.
Closed-source and open-source models are gradually forming their own closed loops. Closed-source models are disclosing less and less information; although their capabilities remain significantly ahead, the usability of open-source models is also rapidly improving. There are a few giants left, while the rest are small workshops or, as Cohere puts it, "independent researchers."
After all, fundamentally, isn't the business logic of AI about cost minimization? The concept of "independent researchers" is very self-consistent.