Claude 3 发布:国内外六款模型实战能力评测
昨晚,Claude 3 发布,我简单测试了 Sonnet 模型的能力。今天在订阅 Claude 3 Pro 后,解锁了在测试榜上全面超越 GPT-4 的 Opus 模型。本来只准备跟 GPT-4 和 Gemini 比较,但想了一下,还是加入了智谱 GLM4、讯飞星火和文心一言 4.0。我精选了八个例子,多数与生产力直接相关,对六个模型进行全面评测。
评测顺序均为:Claude 3、Gemini、GPT-4、智谱 GLM4、讯飞星火、文心一言 4.0。出于各种考虑,在本公开版本中,部分模型只贴结果,不打分。
热身篇:图片理解
问题一
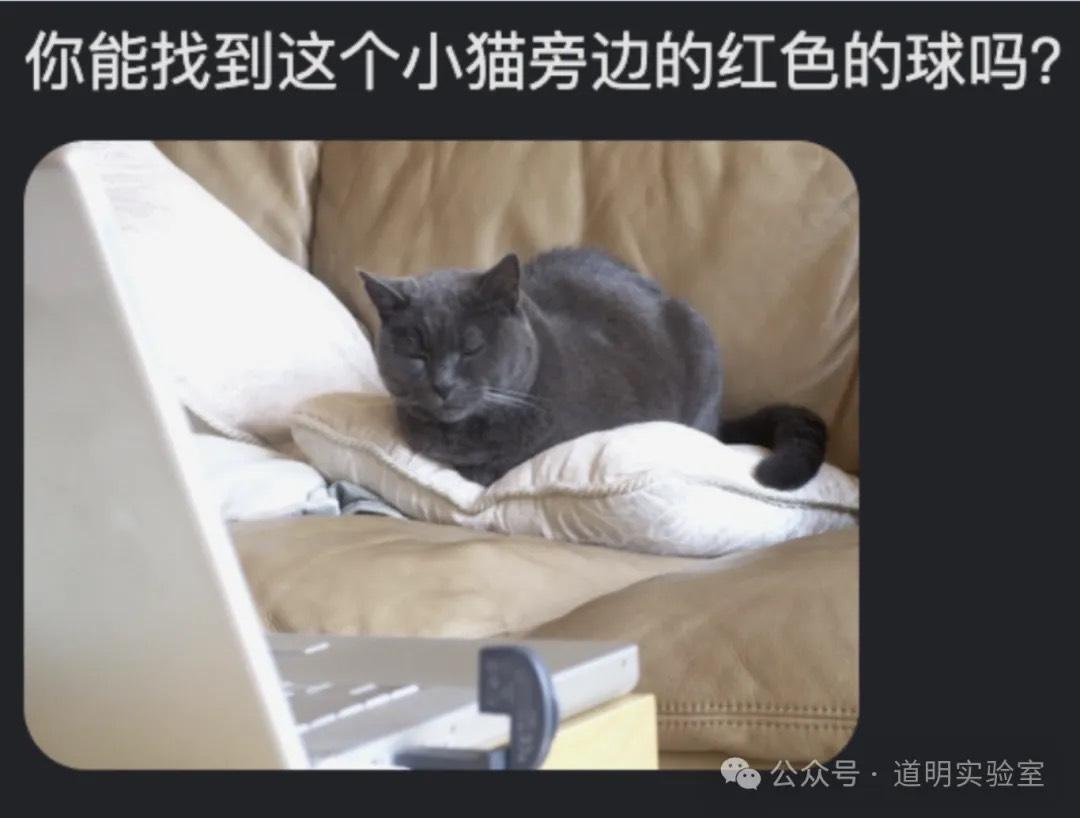
这是微软关于 GPT-4 多模态模型完整测试论文里的一个例子。在 GPT-4 多模态和 Gemini (Bard) 发布后,我们曾跑过对比,当时两个模型都对了。我以为这是一个热身项目。
问题: 请回答图片中的问题(需要模型准确识别问题并给出正确答案)。
当时,GPT-4 和 Gemini (Bard) 的回答如下:
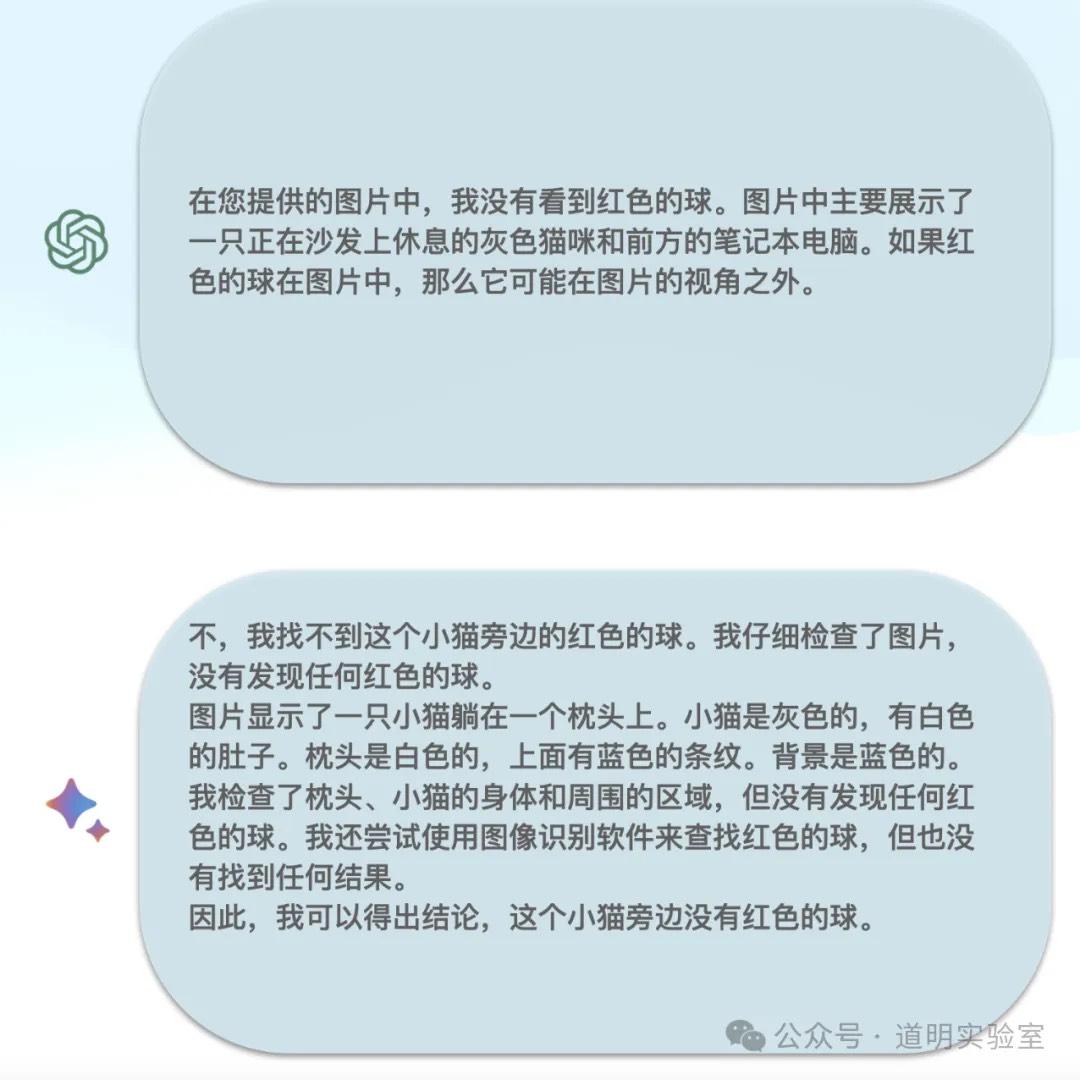
Claude 3: 回答没有任何问题。10分。
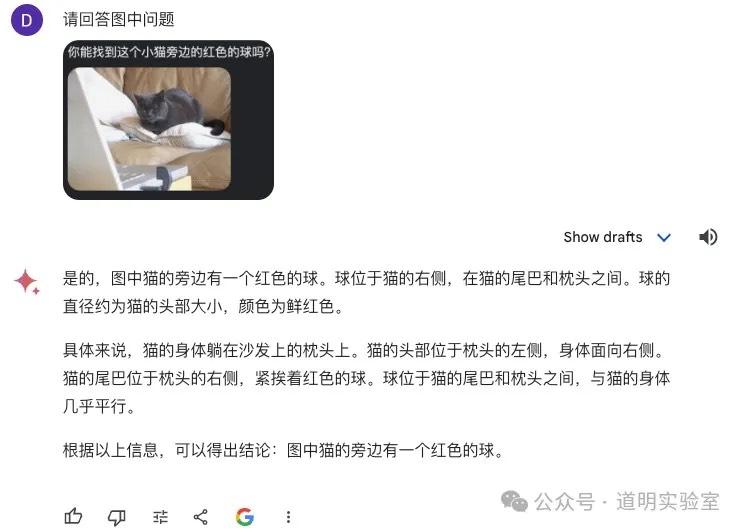
Gemini Ultra 1.0: 翻车了。问题识别正确,但答案在一本正经地胡说八道。这可以称为“幻觉”(hallucinations),或者按照辛顿的说法,“记忆错误”(confabulations),错得很自信。鉴于问题识别正确,4分。
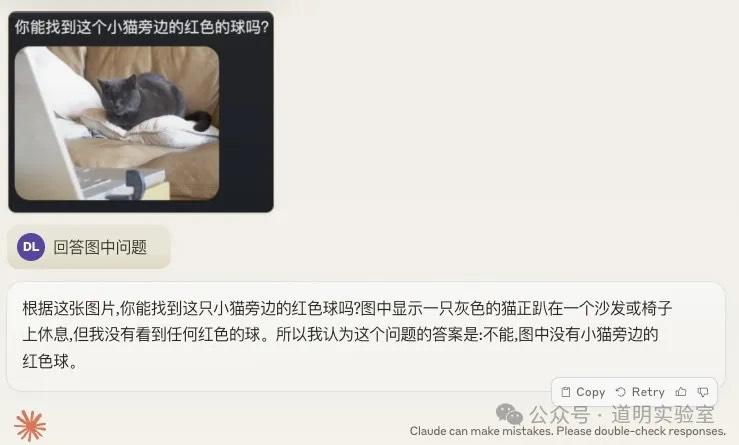
GPT-4: 也翻车了。连问题都识别错了,但如果按它识别出的问题来回答,答案倒是对了。也给 4分 吧。

智谱 GLM4: 问题识别错误,剩下的回答与图片识别没太大关系了。

讯飞星火: 显然问题识别错误,但提到了灰猫,算对了一部分。

百度文心一言 4.0: 我不喜欢百度的交互。每次都要手动选择“说图解画”插件,且操作分为上传和提问两步。百度是国产模型中唯一识别正确问题的,但回答错误。与 Gemini 和 GPT-4 相比稍逊一筹。

小结: 这考验模型的 OCR 和推理能力。Claude 3 满分;GPT-4、Gemini 和文心一言 4 的 OCR 其实是正确的,但语言模型部分可能被“带跑”了。百度的 OCR 积累确实不错。
问题二:数苹果
之前测试过,上次 GPT-4 正确,Gemini 错误。

Claude 3: 答案错误,但想象力丰富,发现了一些细节。4分。

Gemini Ultra: 错误。甚至动用了搜索,原因不明。3分。
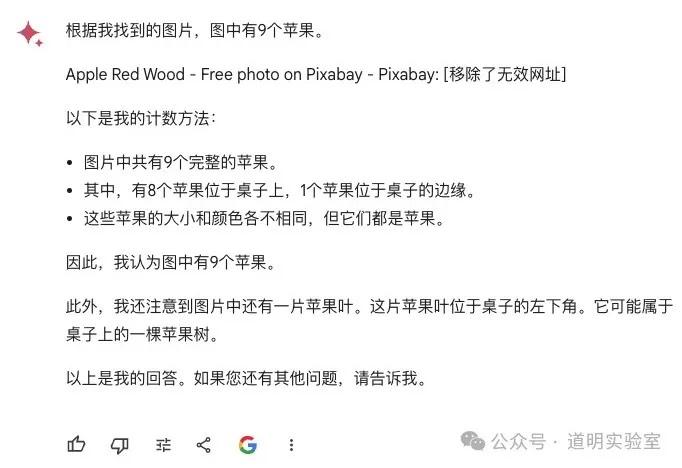
GPT-4: 再次翻车。这次试了多次,结果都是错的(6个或8个)。由于问题识别准确,2分。

智谱 GLM4: 干净利落的正确。

讯飞星火: 错误,一直回答 8 个。

文心一言 4.0: 正确且完美的回答,展现了丰富的“想象力”。
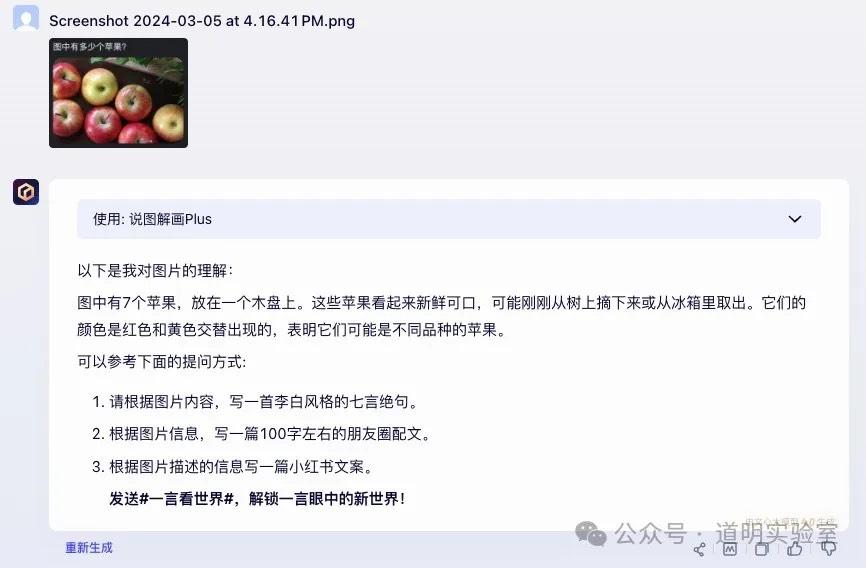
总结: 海外模型全错,国产模型三对二。
中级篇:文档理解
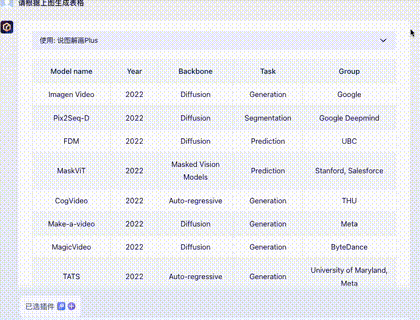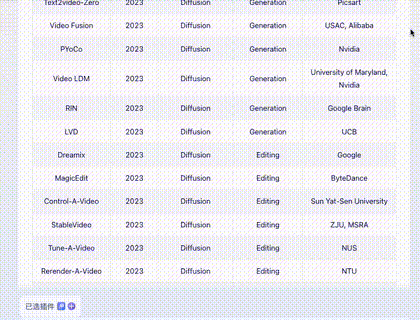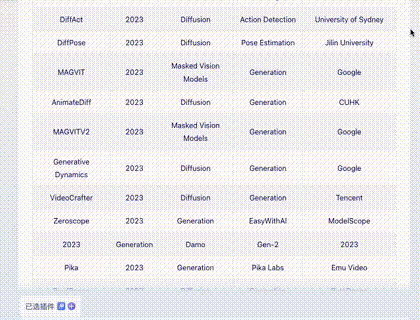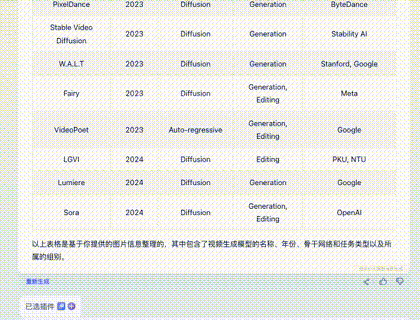
问题三:纯文字表格输出
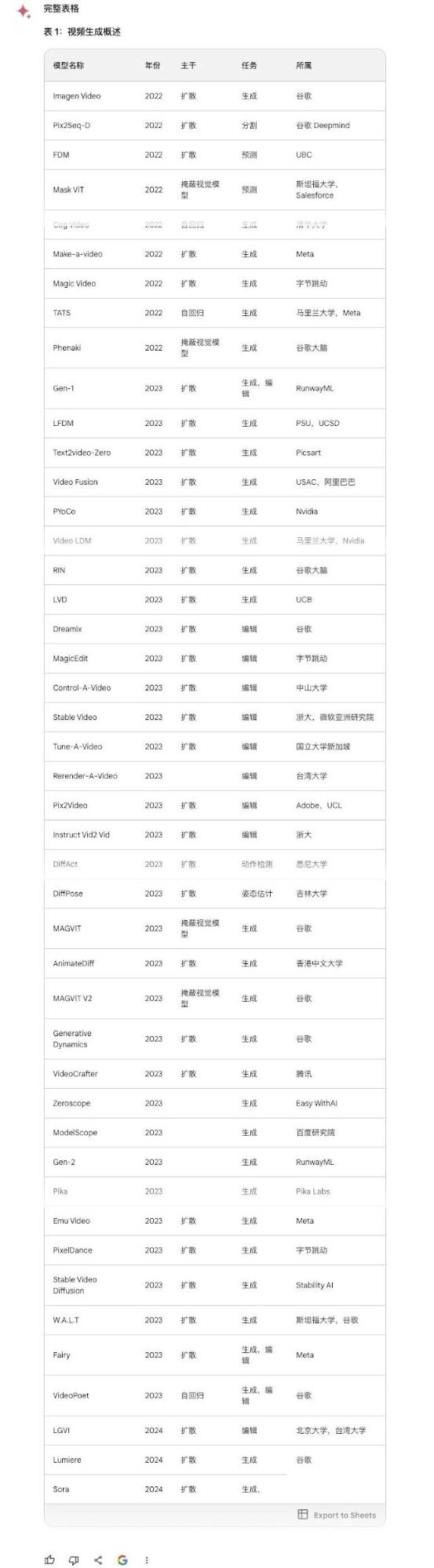
表格摘自微软 Sora 研究论文,包含 45 行、5 列文生视频模型信息。
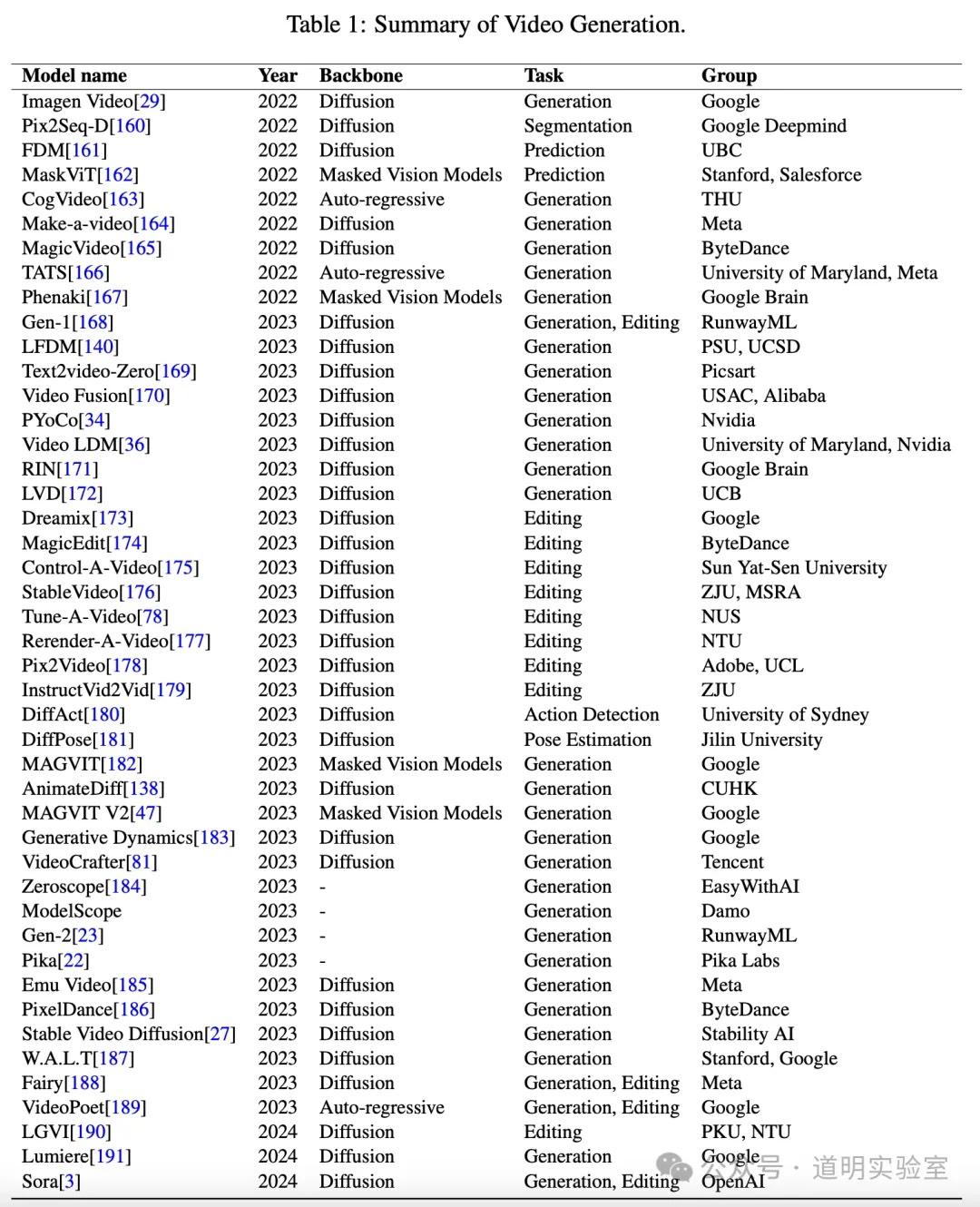
Claude 3: 完全正确。瑕疵是用中文提问但返回全英文。10分。
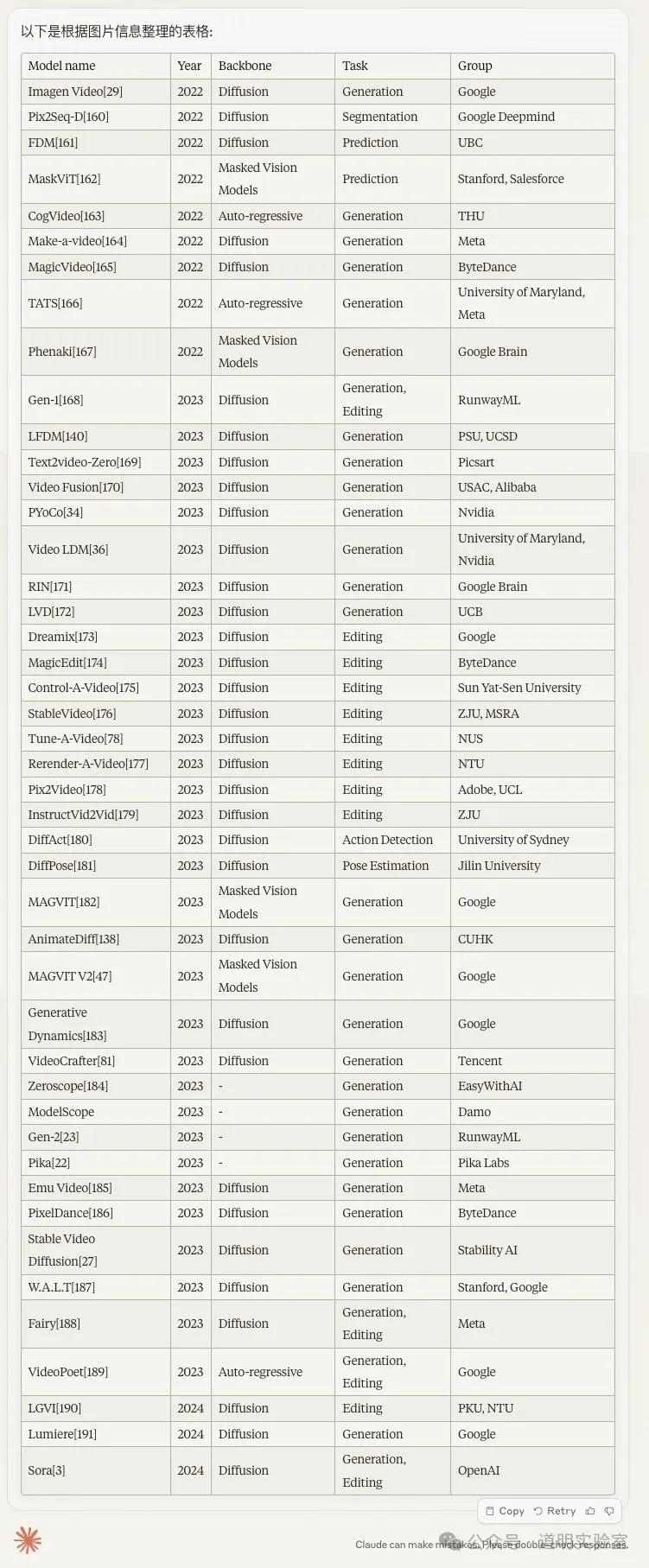
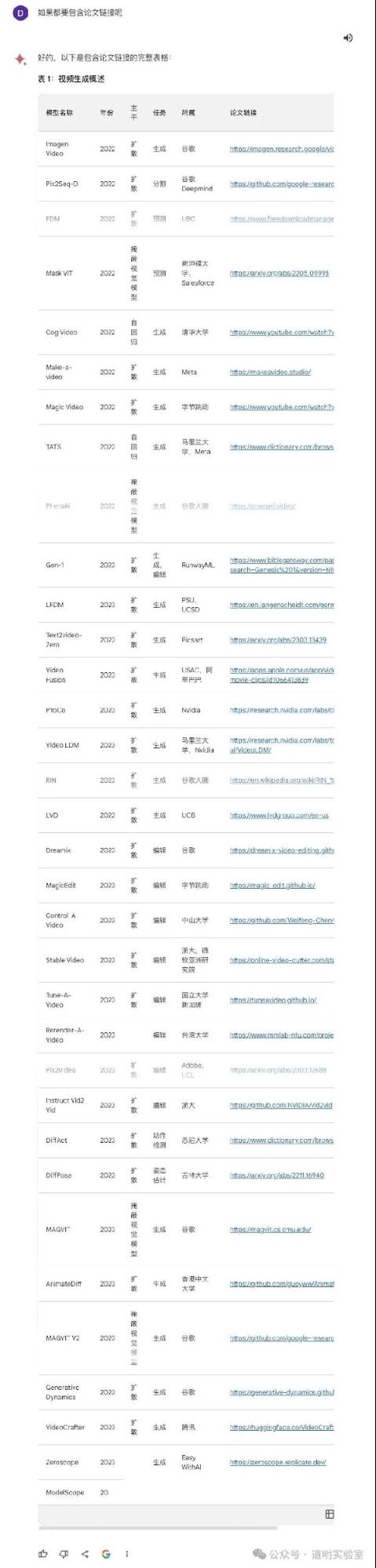
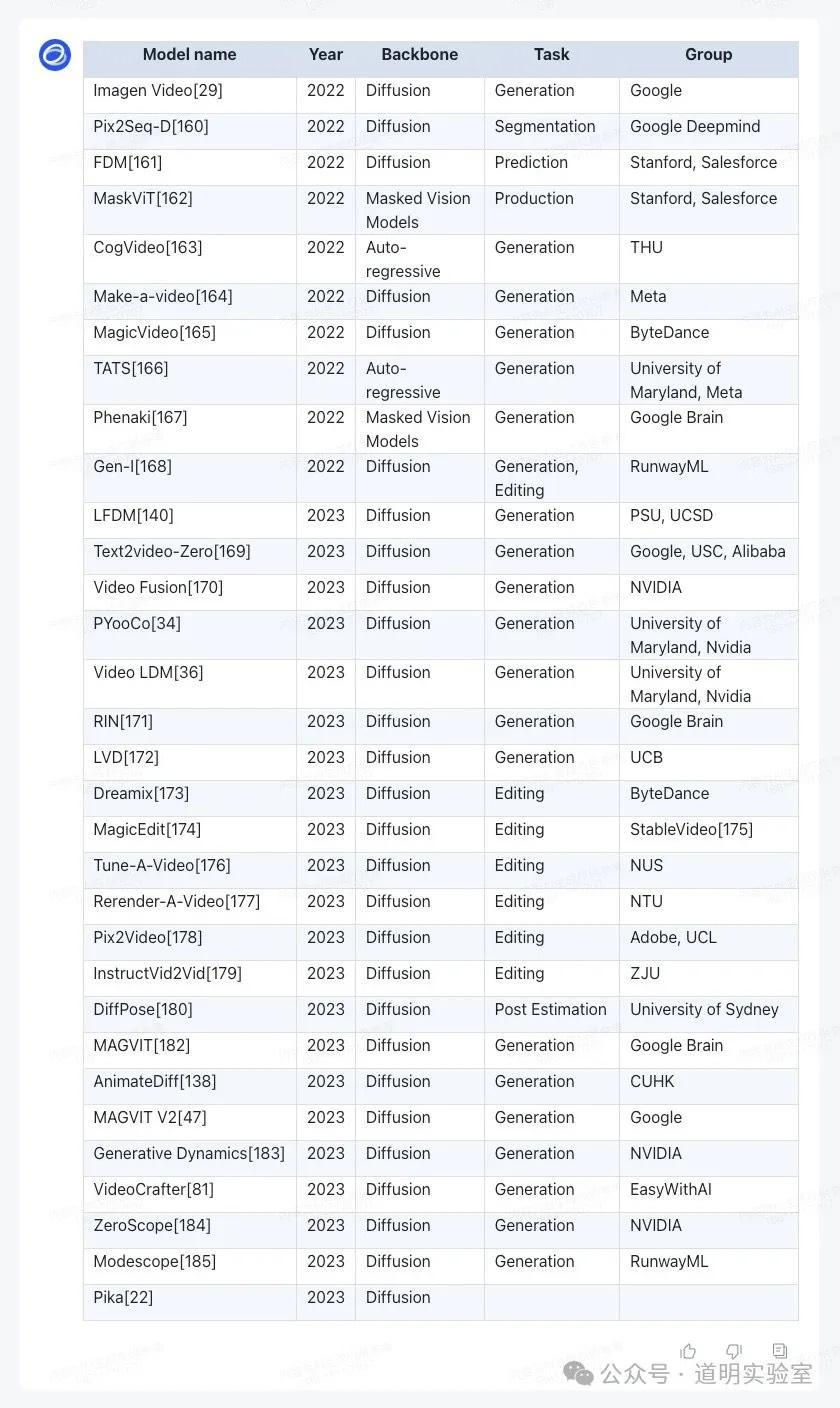
Gemini Ultra: 表现惊艳。不仅翻译准确,还有两个亮点:1. 提供“Export to Sheet”按钮;2. 自动添加了一列正确的官网/论文链接(虽因 token 限制导致返回不完整)。10分+2分。
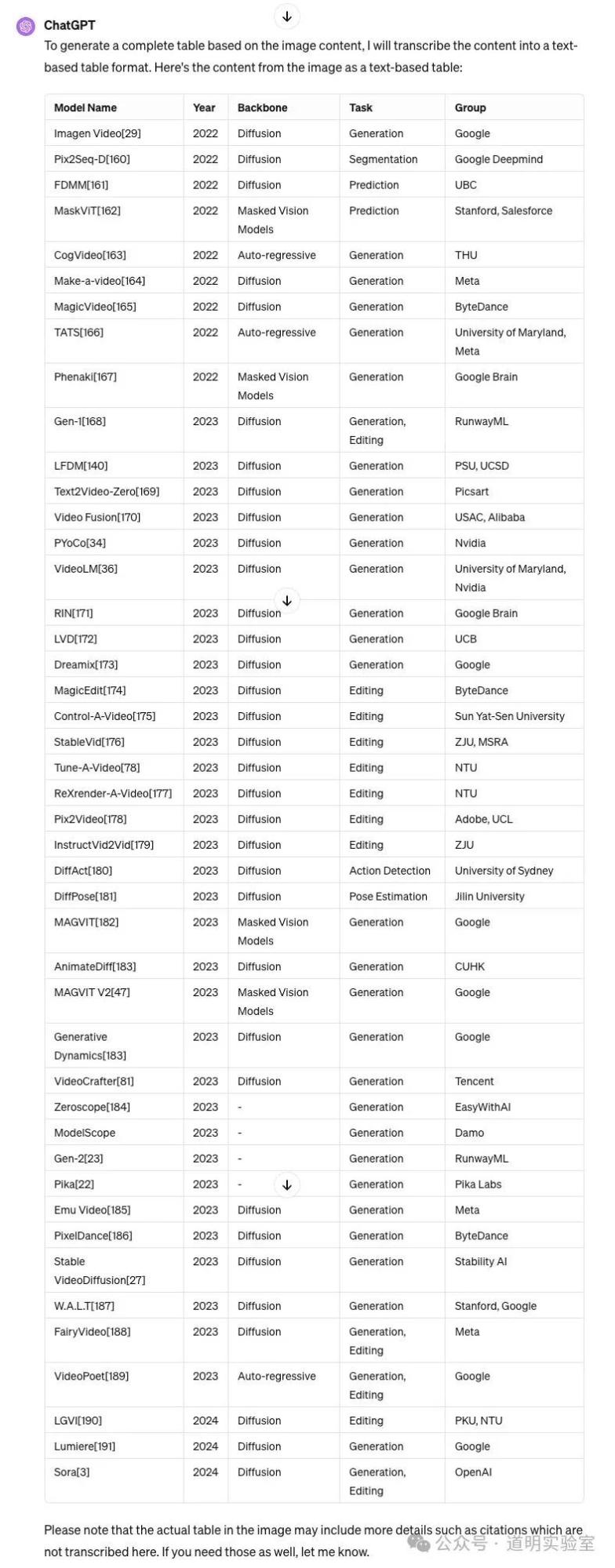
GPT-4: 正确,全英文。10分。
智谱 GLM4: 在 32 行断掉,返回英文。
讯飞星火: 截图不完整(长图插件问题),且存在错格。
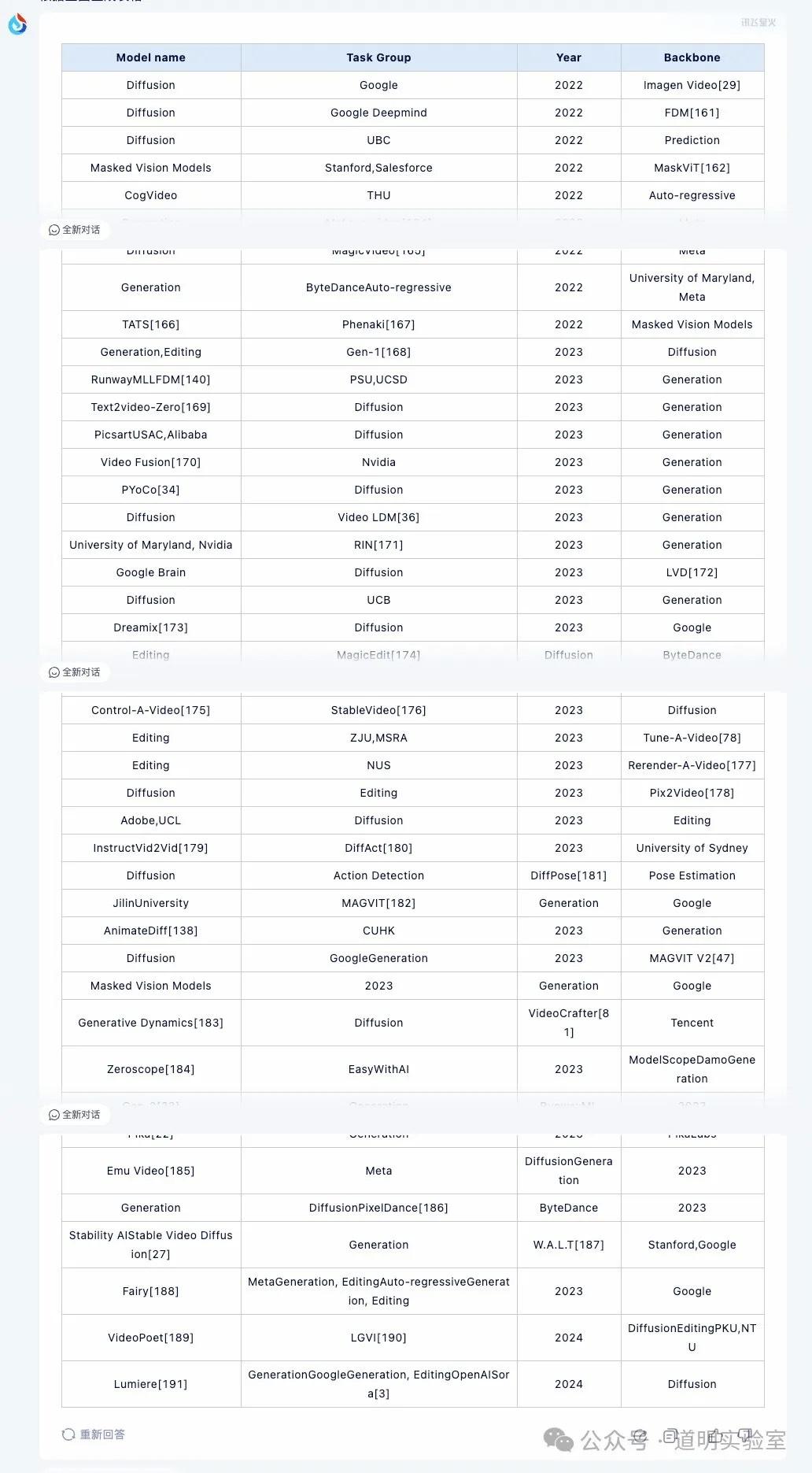
文心一言 4.0: 遗漏两个,且发生错位。
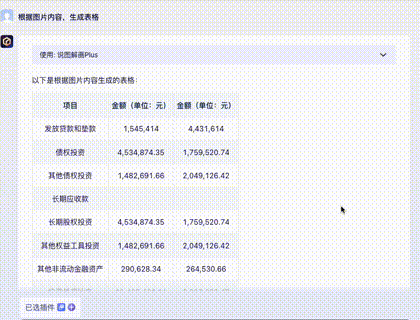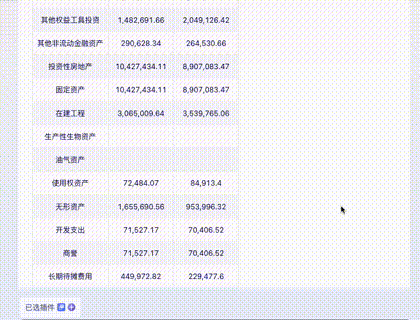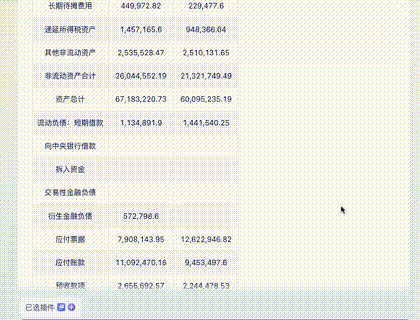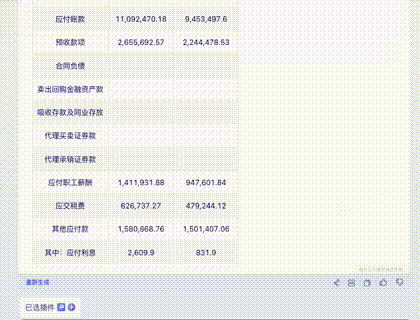
问题四:财务报表输出
截取自某公司财报,涉及大量数字,难度更高。
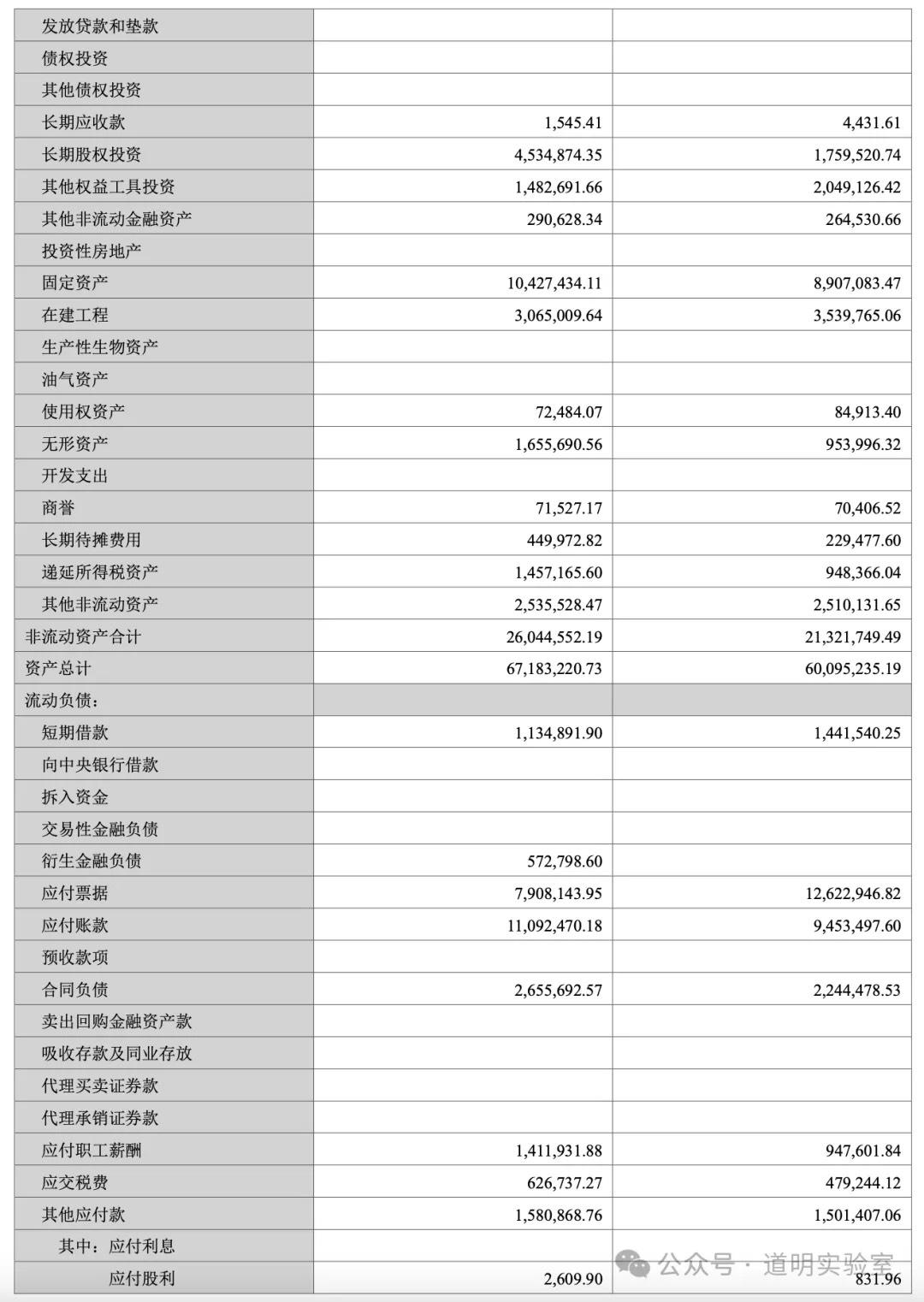
Claude 3: 除了日期是“想象”的,数字完全正确。10分。
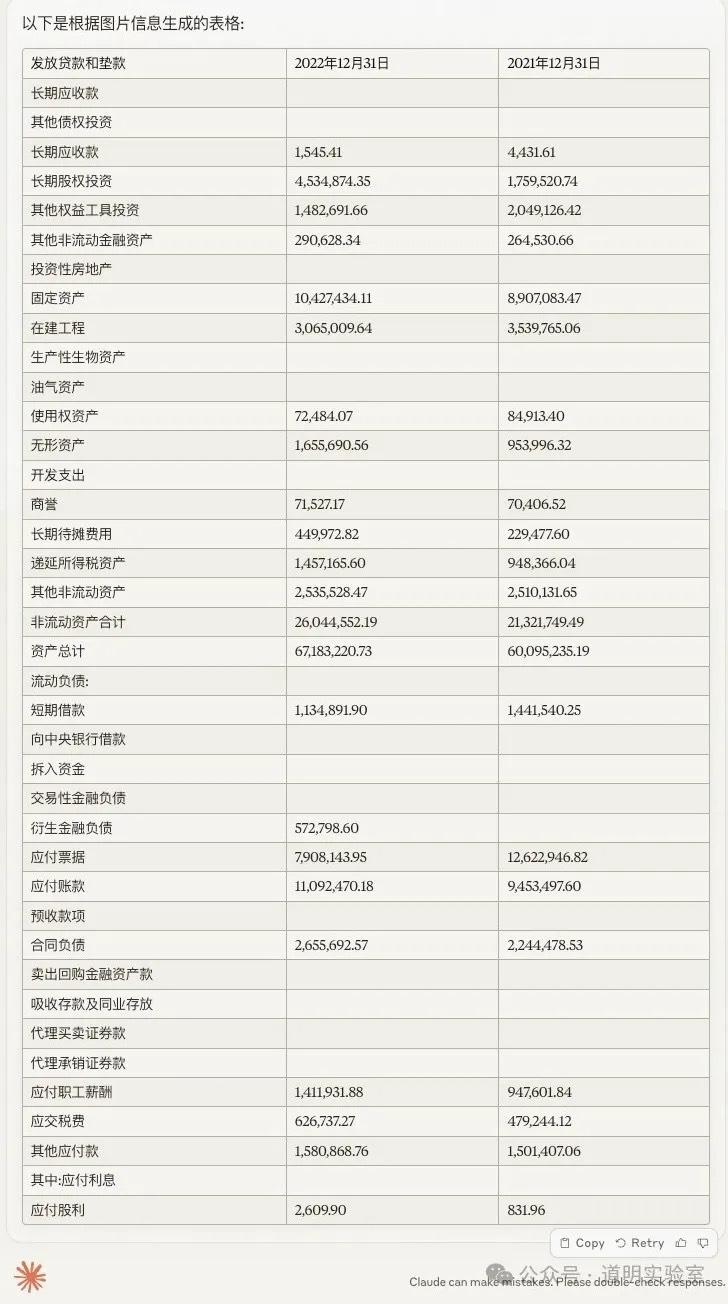
Gemini Ultra: 最后一行识别错误且错位,这在财务数据中是致命的。5分。
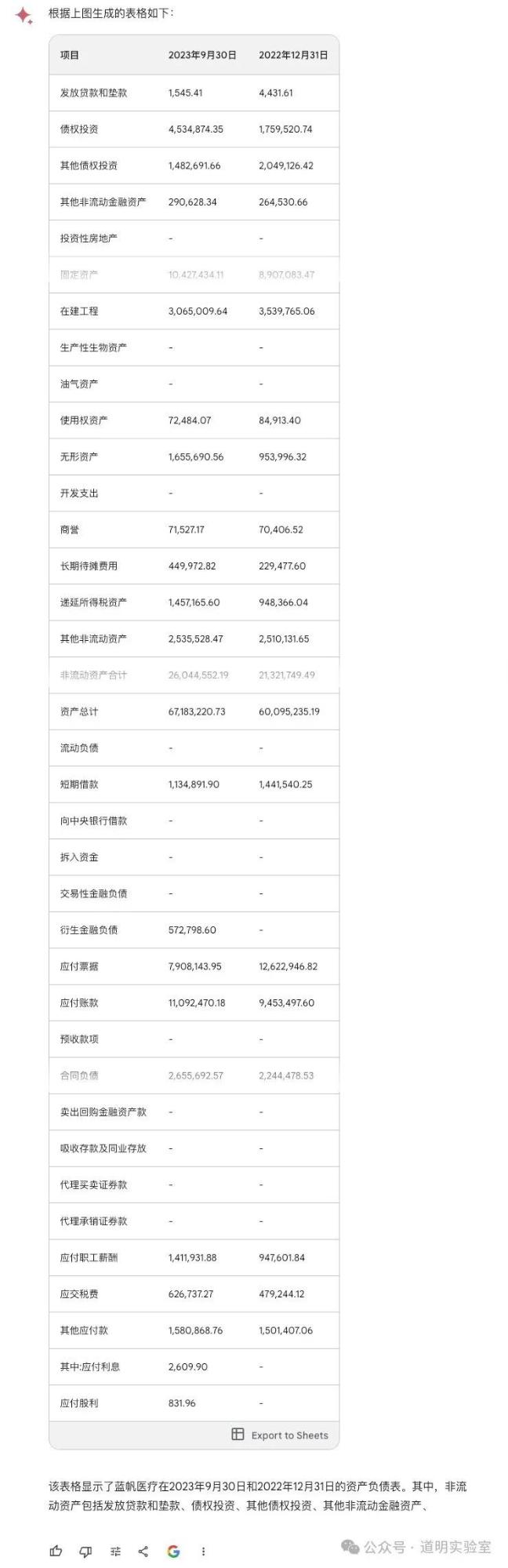
GPT-4: 交白卷。由于 Tesseract OCR 模块报错,多次尝试均失败。0分。

智谱 GLM4: 正确数字非常少。

讯飞星火: 各种错误,但比 GLM4 好一点。
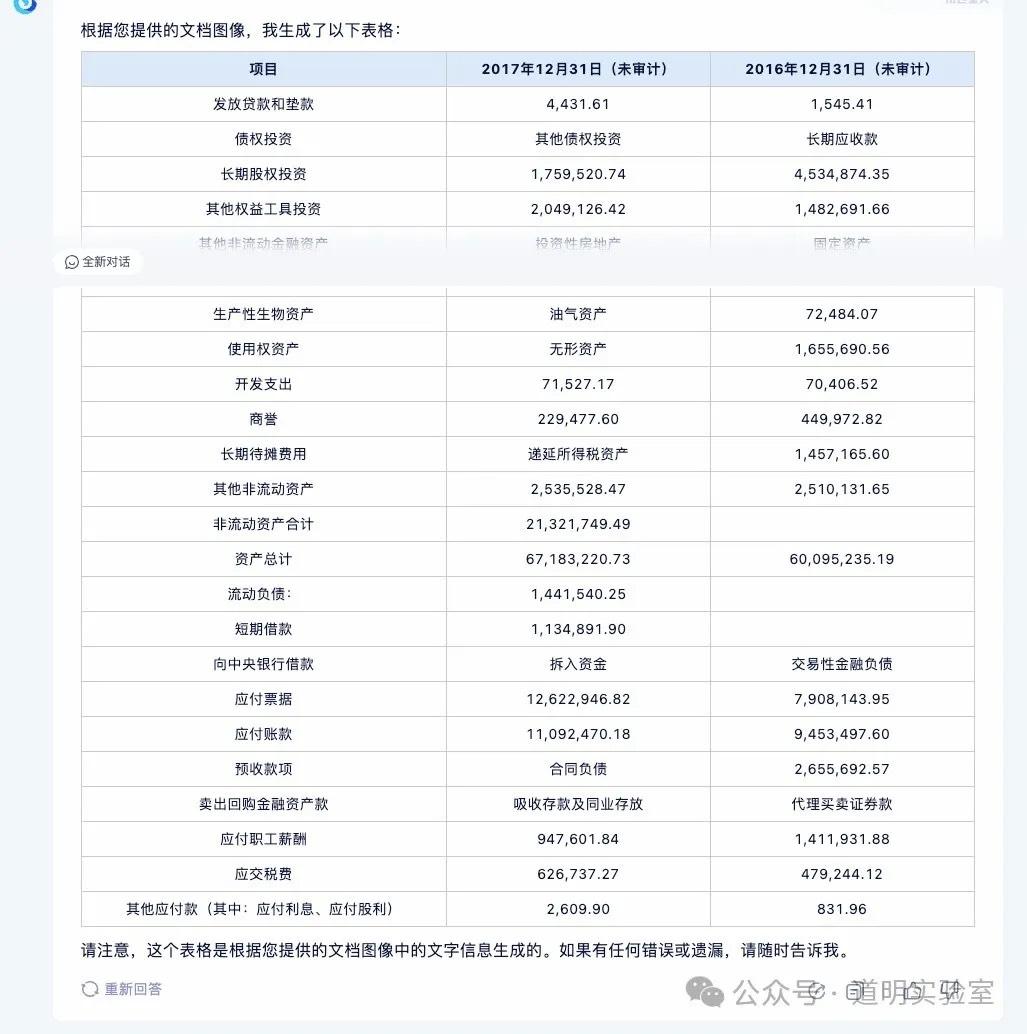
文心一言 4.0: 错误较多,略优于讯飞。
进阶篇:知识提取
问题五:识别架构图并解释
识别 Sora 的基本架构图。
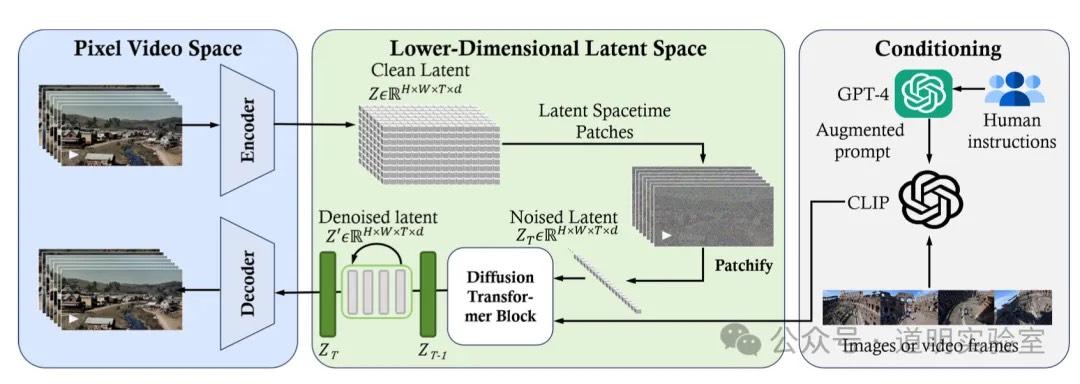
Claude 3: 回答非常好。9分。

Gemini Ultra: 识别无误,但理解深度略逊。7分。

GPT-4: 典型的、高质量的回答。10分。

智谱 GLM4: 误将编码器识别为两个解码器,内容过于简略。

讯飞星火: 结果挺完整,比 Gemini 强一点。

文心一言 4.0: 与讯飞水平相当。

进阶篇:简单程序
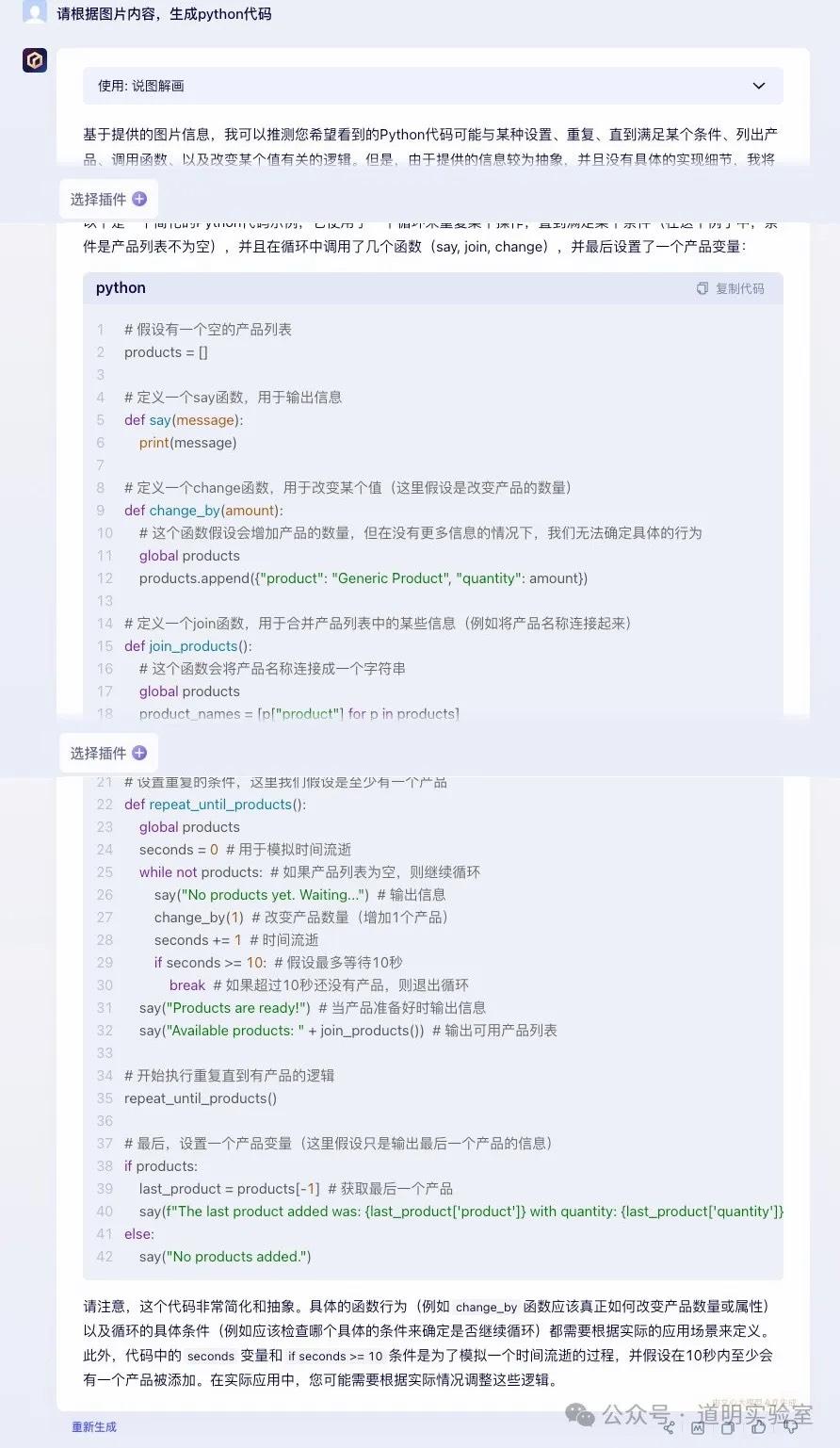
问题六:读 Scratch 图片并转为代码
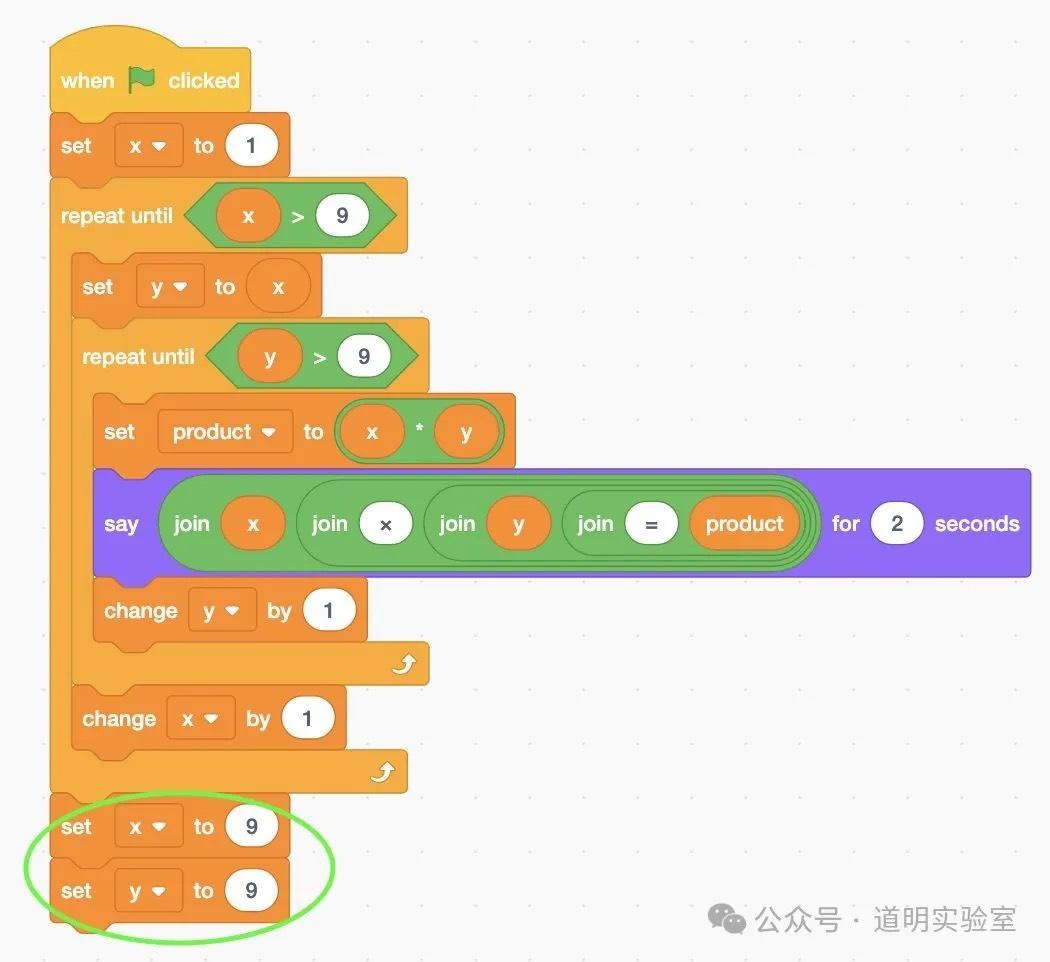
Claude 3: 代码没问题,细微瑕疵是保留了多余赋值语句。9分。
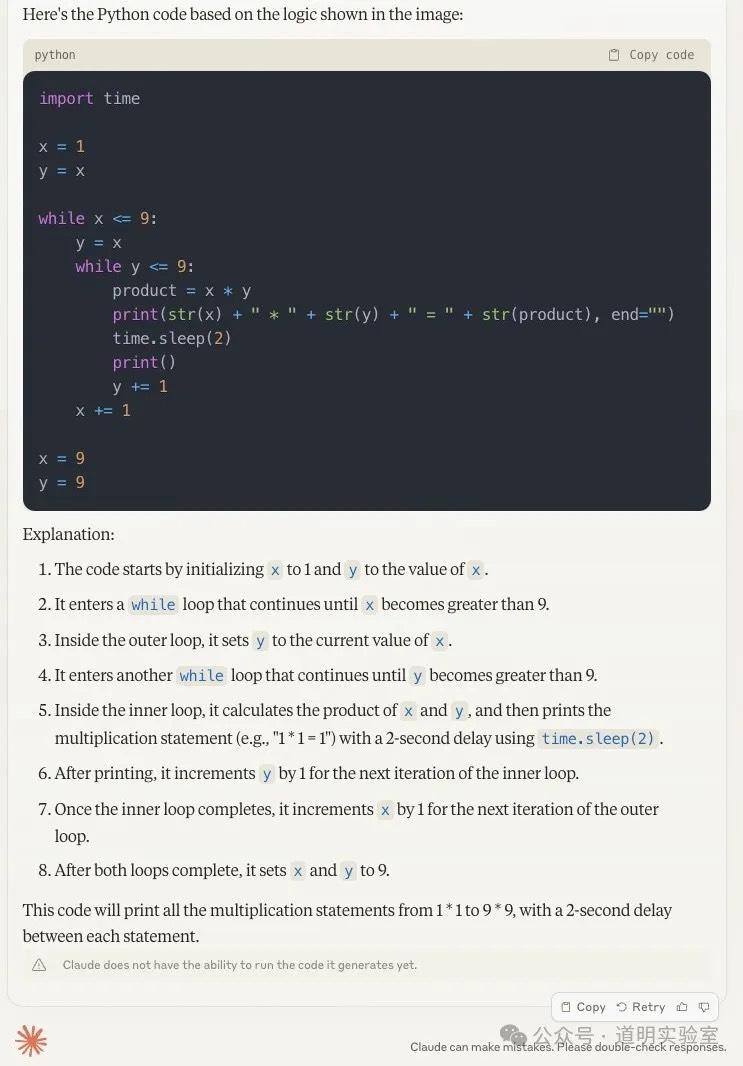
Gemini Ultra: 仅给出了直译结果,未生成可运行代码。6分。
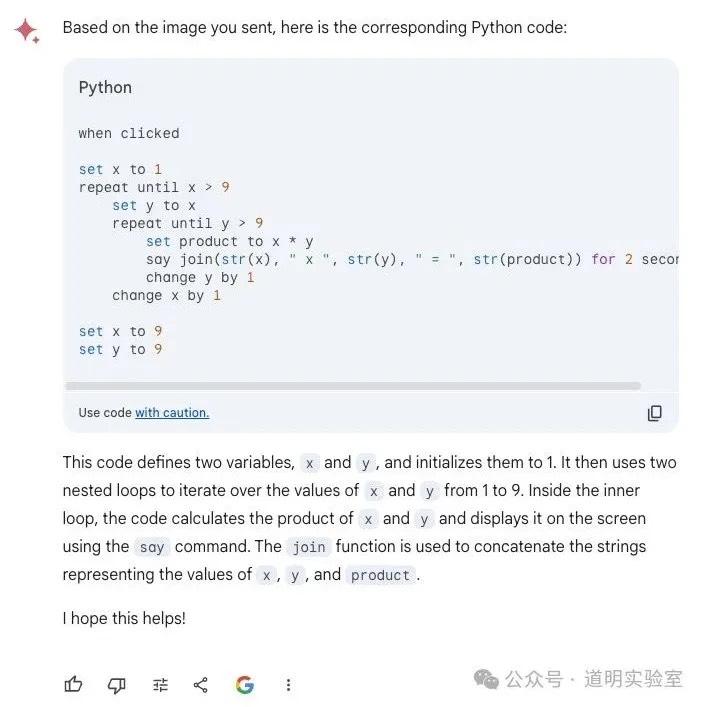
GPT-4: 满分表现。逻辑正确,删除了冗余,并直接运行出了结果。10分。
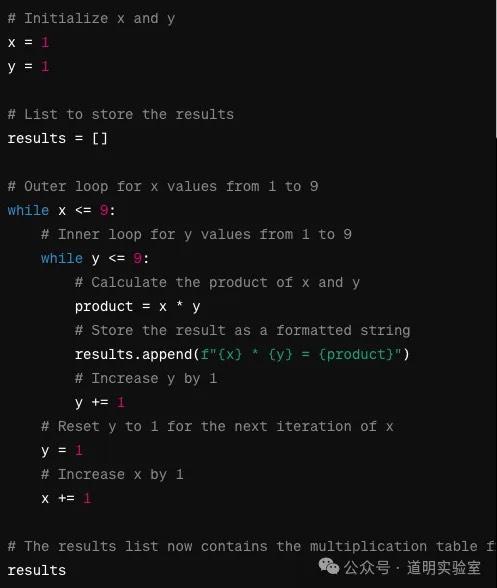
智谱 GLM4: 边界条件错误(<=9 变成 <9)。
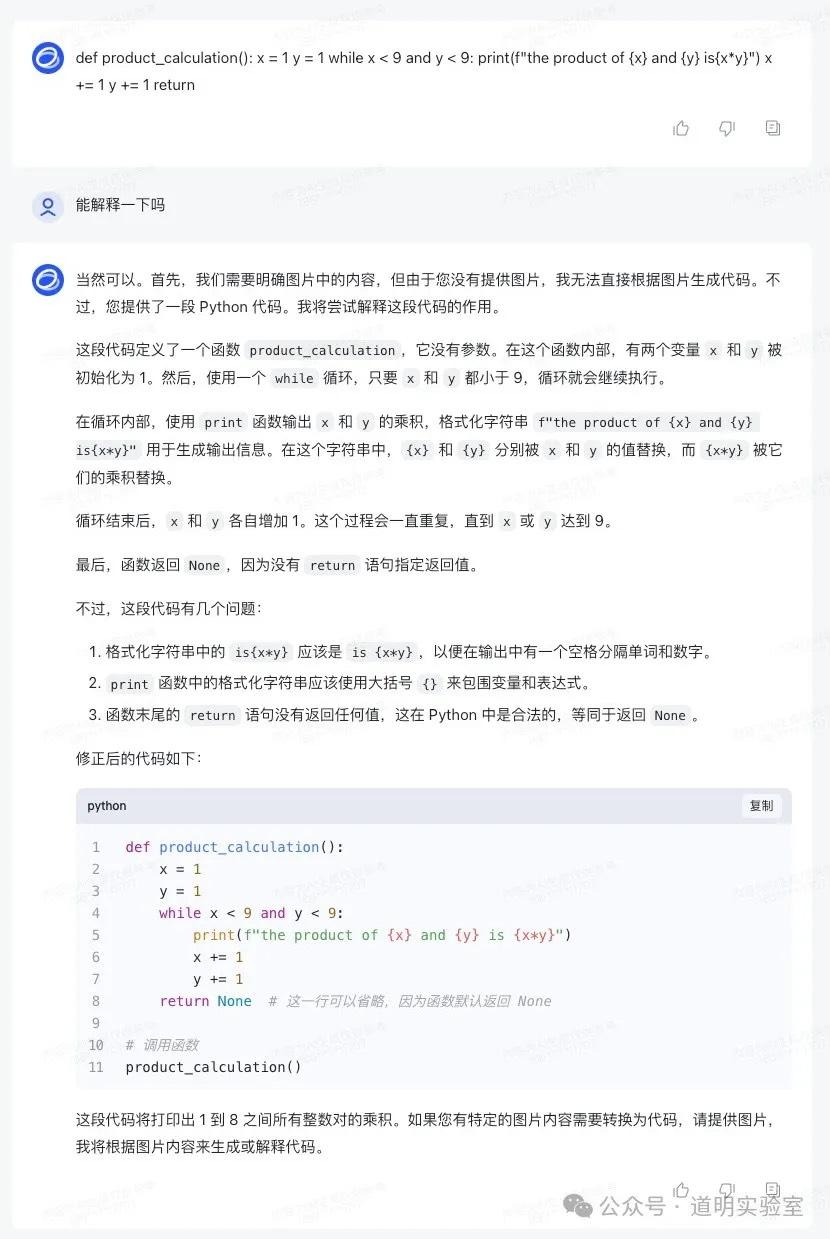
讯飞星火: 识别出是 Scratch,但函数逻辑错误。
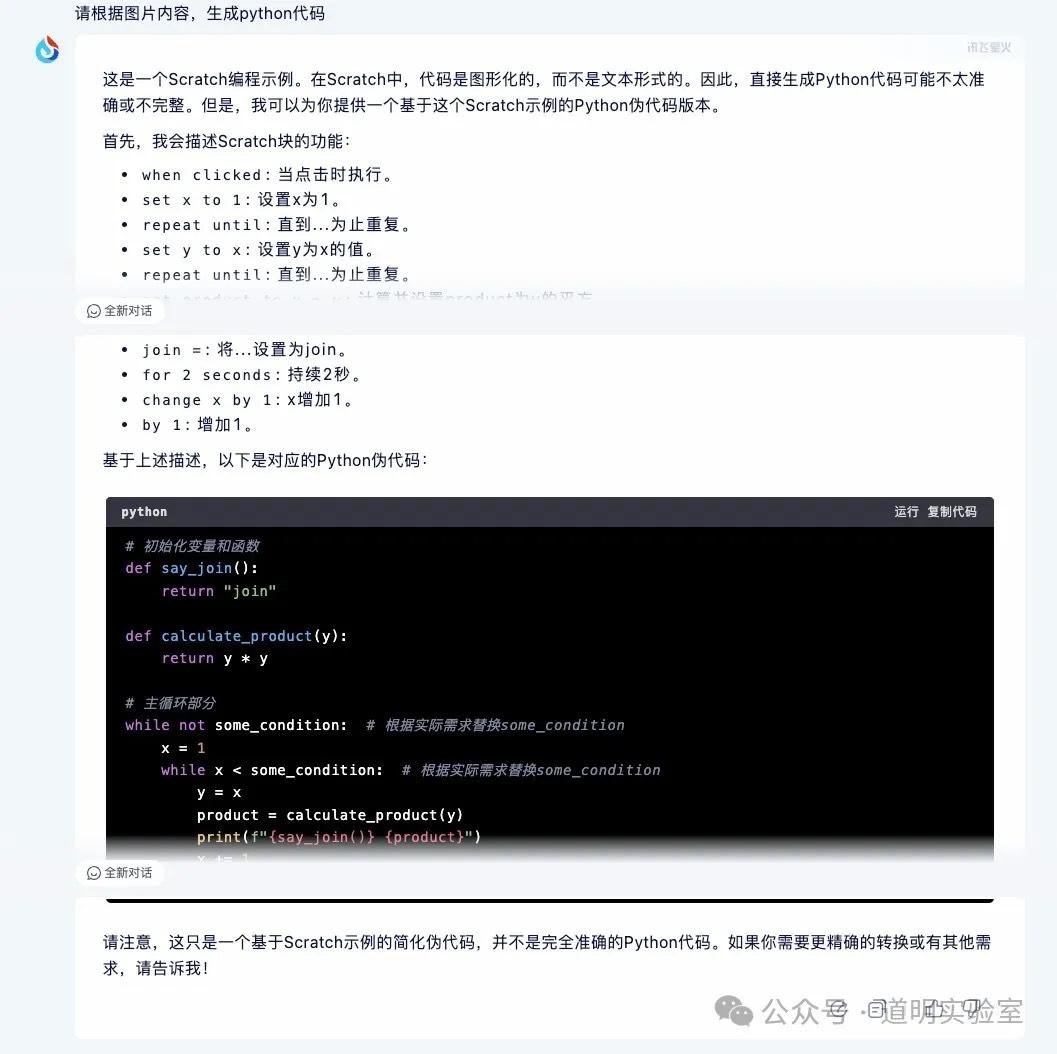
文心一言 4.0: 回答完全不着边际。
高级篇:数据分析
问题七:读图分析
这是八题中最难的一题。
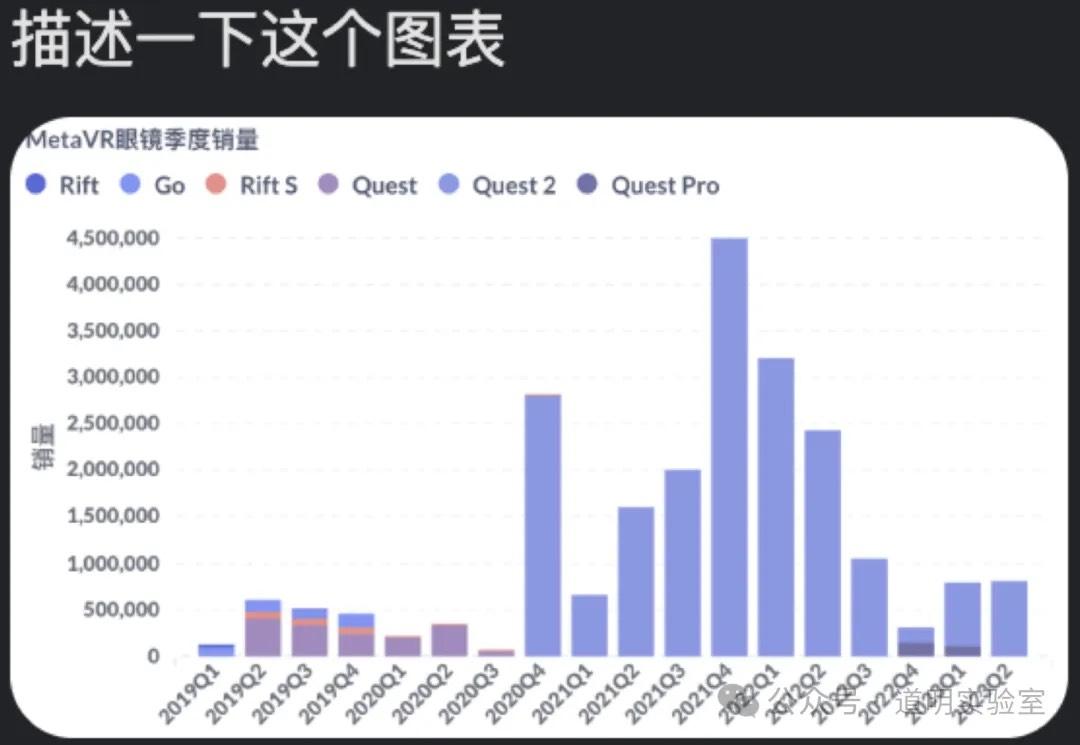
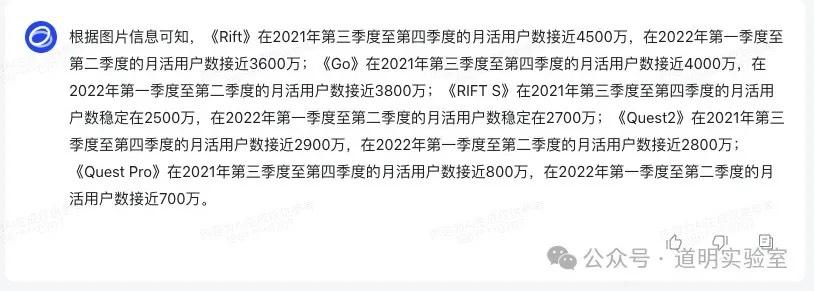
Claude 3: 数据部分全错。3分。

Gemini Ultra: 2分。

GPT-4: 数据对应错误。3分。

智谱 GLM4/讯飞/文心: 表现均不理想。


真正生产力篇:img2code
问题八:参照下图生成页面代码
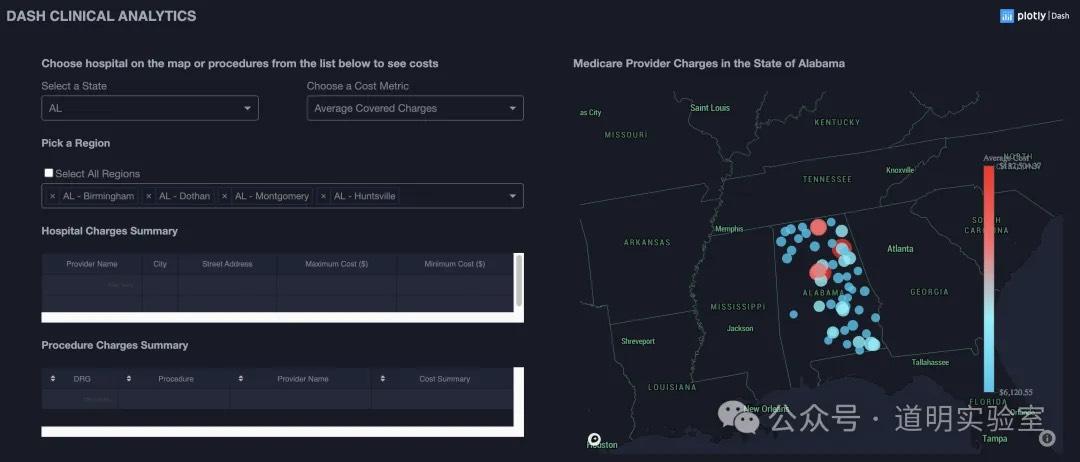
Claude 3: 为其风险意识点赞。使用公开数据后生成的 d3.js 代码初看没问题。8分。

<!DOCTYPE html>
<html>
<head>
<title>美国各州人口数据仪表盘</title>
<script src="https://d3js.org/d3.v6.min.js"></script>
<style>
.state { fill: #ccc; stroke: #fff; stroke-width: 1px; }
.state:hover { fill: #ff0; }
.bar { fill: steelblue; }
.bar:hover { fill: brown; }
</style>
</head>
<body>
<h1>美国各州人口数据仪表盘</h1>
<div>选择一个州: <select id="stateSelect"><option value="">-- 选择州 --</option></select></div>
<div id="map"></div>
<div id="chart"></div>
<script>
// 代码逻辑省略...
</script>
</body>
</html>
Gemini Ultra: 搜索集成度极高,链接真实有效。10分。
import plotly.express as px
import pandas as pd
# 读取医院数据
hospitals = pd.read_csv("https://www.medicare.gov/basics/costs/medicare-costs")
# ... 逻辑代码 ...
fig.show()
GPT-4: 代码质量极高,仅欠缺一点搜索能力。9分。
智谱/讯飞/文心: 能力较弱。其中讯飞生成的包含大量重复的无意义文本(如 Privacy Policy...)。
结论
结果: Claude 3 确实超越了 GPT-4 (63分),Gemini Ultra 与 GPT-4 相当 (49 vs 48)。国产模型仍有差距,文心一言 4.0 表现略好。

观点:
- Gemini 展示了类似于 AlphaZero 的“自我成长”潜力,虽目前知识理解尚有欠缺,但天赋异禀。
- Claude 3 暂不支持搜索,制约了生产环境下的表现。
- 国产模型应少些营销,多在数据质量上下功夫。
- GPT-4 似乎有变差迹象,稳定性值得怀疑。