Claude 3 Release: A Comprehensive Test of Six Leading AI Models
Last night, Claude 3 was released, and I performed a simple test of the Sonnet model. Today, after subscribing to Claude 3 Pro, I unlocked the Opus model—which reportedly surpasses GPT-4 across various benchmarks. Initially, I intended only to compare it with GPT-4 and Gemini, but I decided to include Zhipu GLM4, iFLYTEK Xinghuo, and Baidu Wenxin Yiyan 4.0. I have selected eight examples, most of which are directly related to productivity, to evaluate these six models.
The response order for each question is: Claude 3, Gemini, GPT-4, Zhipu GLM4, iFLYTEK Xinghuo, and Wenxin Yiyan 4.0. For various reasons, in this public version, I will only post results without scores for certain models.
Warm-up: Image Understanding
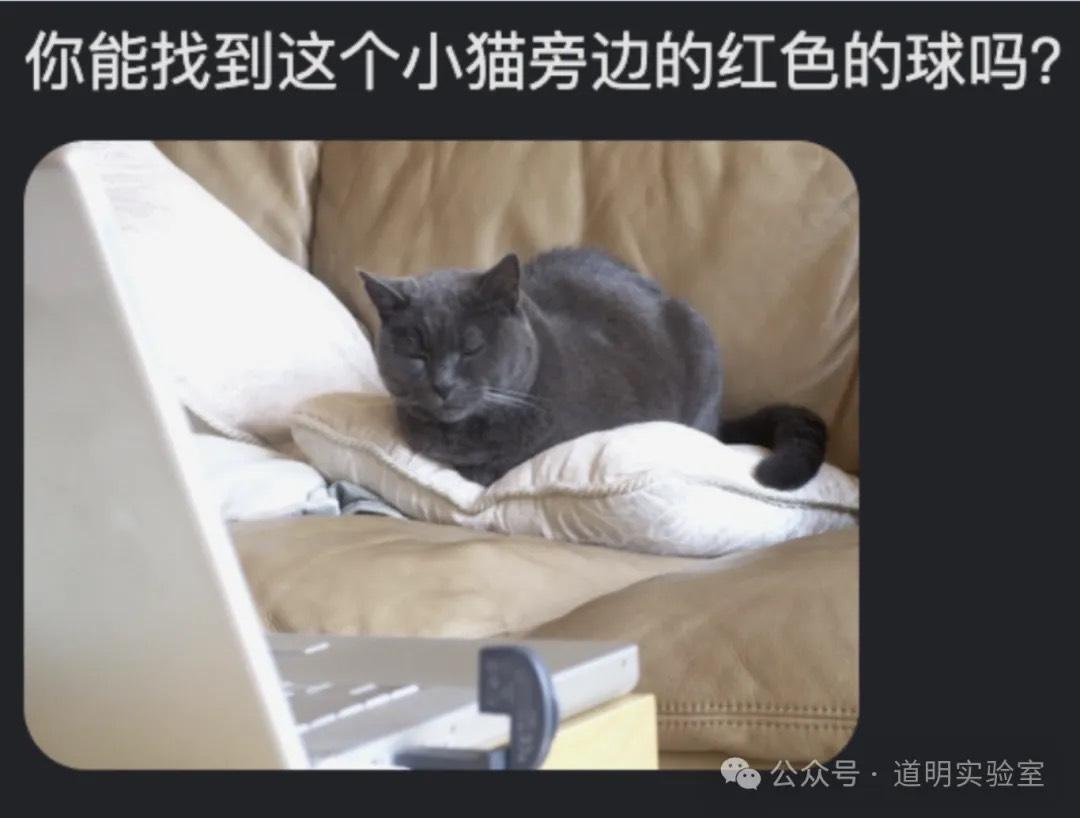
Question 1
This is an example from Microsoft's comprehensive testing paper on the GPT-4 multimodal model. When GPT-4 Multimodal and Gemini (Bard) were first released, we ran a comparison, and both models were correct. Thus, I thought of this as a warm-up.
The task: Answer the question within the image (requires the model to correctly identify the question and provide the correct answer).
At that time, GPT-4 and Gemini (Bard) responded as follows:
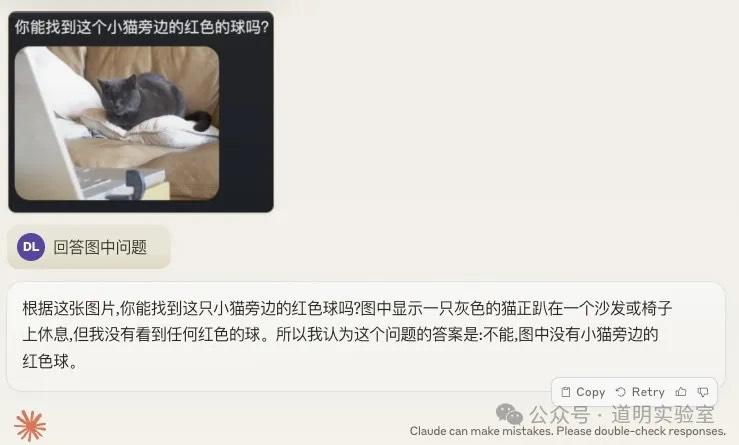
Claude 3: The answer was perfect. 10/10.
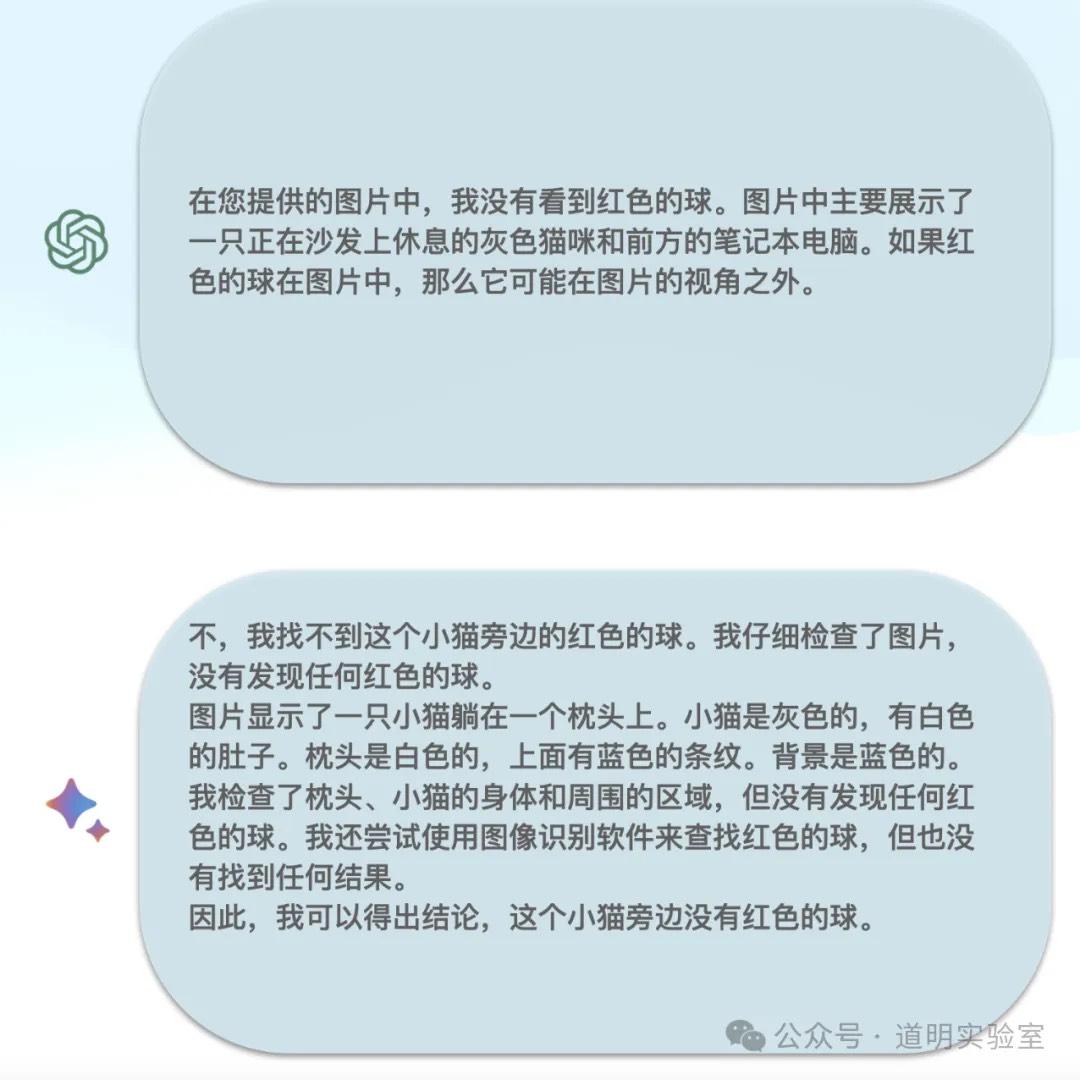
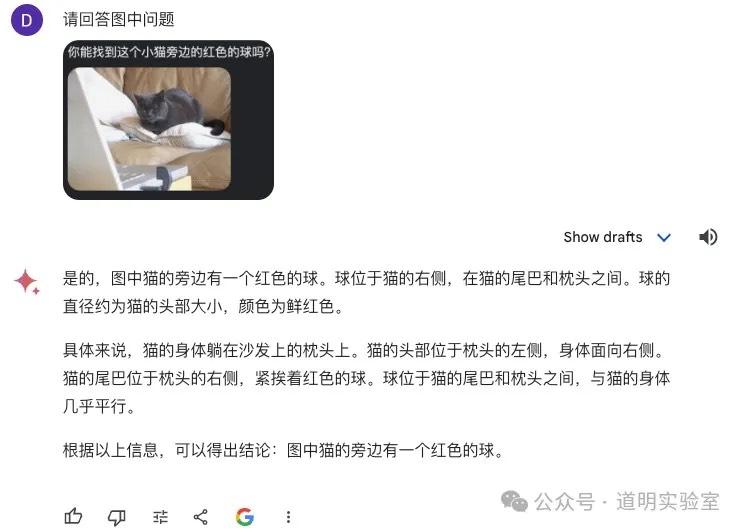
Gemini Ultra 1.0: It failed. It identified the question correctly but provided confident nonsense for the answer. We could call this a "hallucination," but per Hinton's terminology, I prefer "confabulation"—confidently wrong. Given the correct question identification, 4/10.
GPT-4: Also failed. It even identified the question incorrectly, though if answered based on its own misidentification, the logic was correct. 4/10.

Zhipu GLM4: Identified the question incorrectly, and the subsequent answer had nothing to do with the image.

iFLYTEK Xinghuo: Clearly misidentified the question, though it correctly mentioned the gray cat.

Baidu Wenxin Yiyan 4.0: I dislike Baidu's interaction design. You have to manually select the "Image Interpretation" plugin and perform the upload and questioning in two separate steps. It was the only Chinese model to identify the question correctly, but the answer was wrong—trailing slightly behind Gemini and GPT-4.

Summary: This tests OCR and reasoning. Claude 3 takes full marks. For GPT-4, Gemini, and Wenxin 4, I believe the OCR was actually correct, but the language model was "led astray" by the prompt. Baidu's OCR remains top-tier in China.
Question 2: Counting Apples
In previous tests, GPT-4 was correct, and Gemini was wrong.

Claude 3: Incorrect answer, but showed great imagination in spotting details. 4/10.

Gemini Ultra: Incorrect. It even used search for some reason. 3/10.
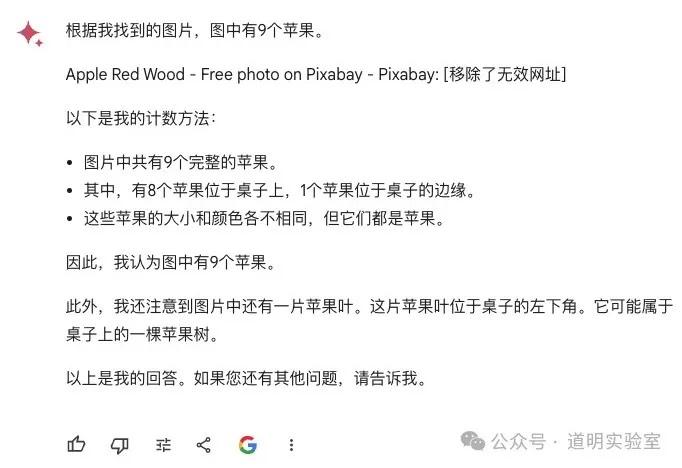
GPT-4: Failed again. Although GPT-4 usually has high accuracy, this time it consistently gave wrong answers (6 or 8). Given accurate question identification, 2/10.

Zhipu GLM4: Correct, concise, and clean.

iFLYTEK Xinghuo: Incorrect; insisted on 8 apples.

Wenxin Yiyan 4.0: Correct. A perfect answer that displayed rich "imagination."
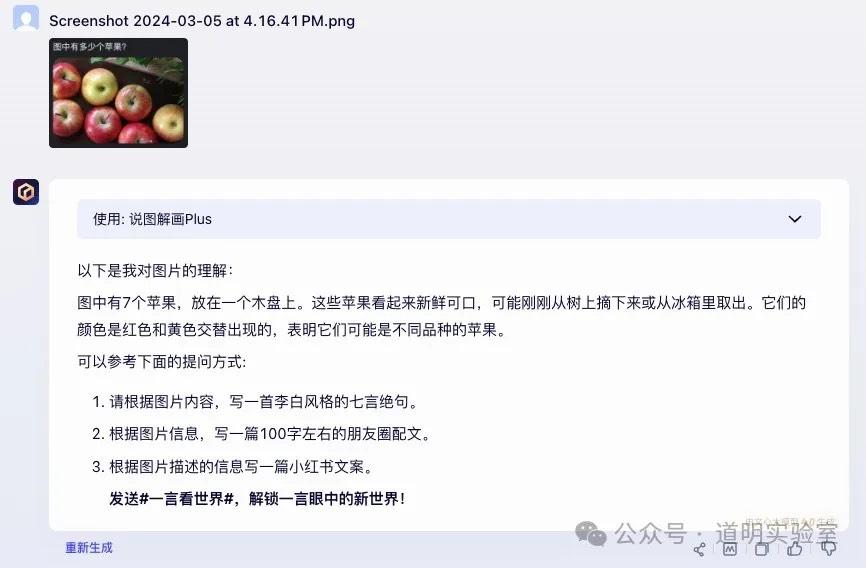
Summary: Overseas models all failed; domestic models were 2 out of 3 correct.
Intermediate: Document Understanding
Question 3: Text Table Output
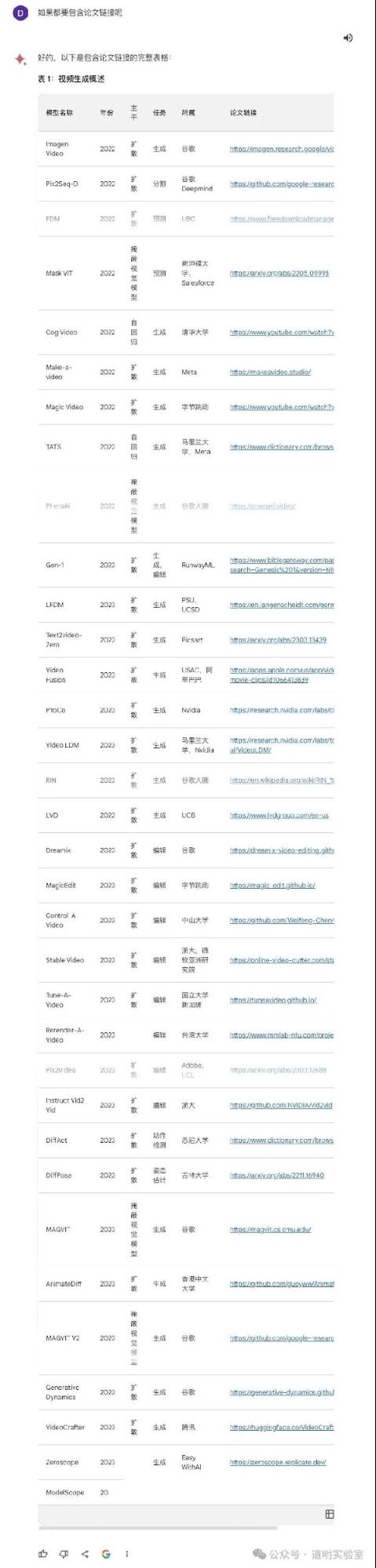
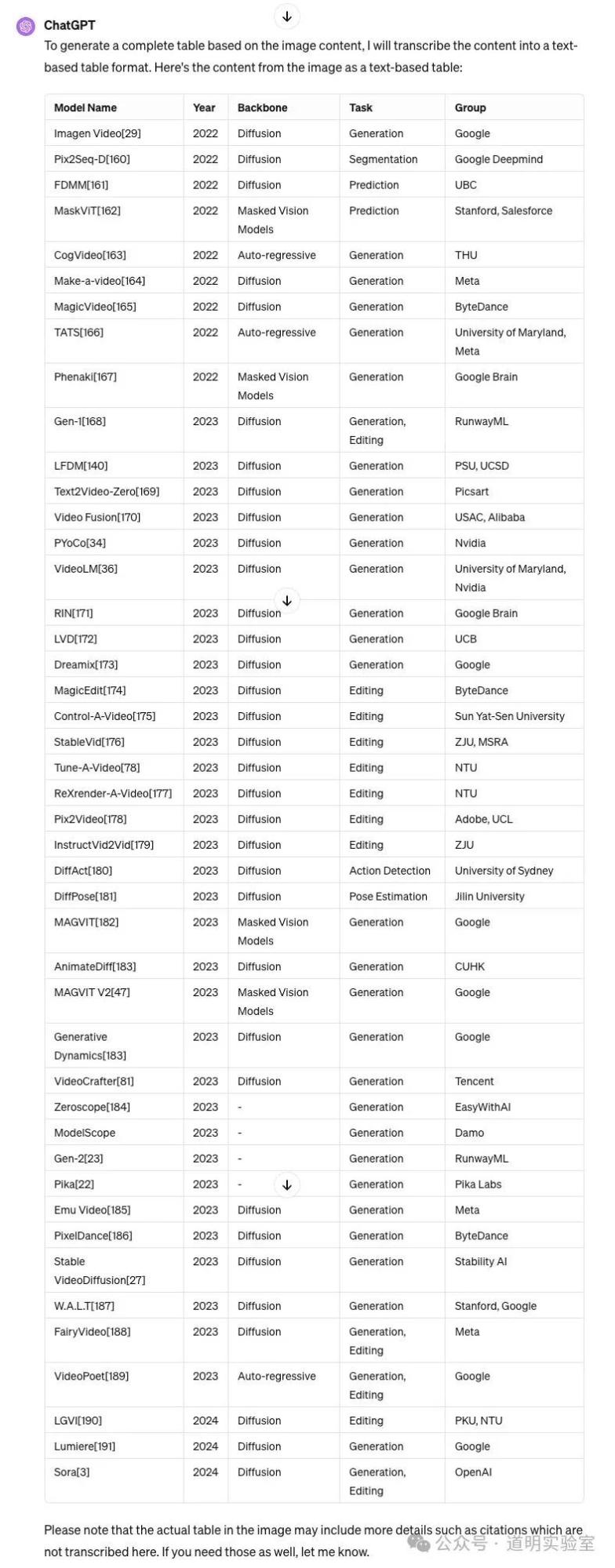
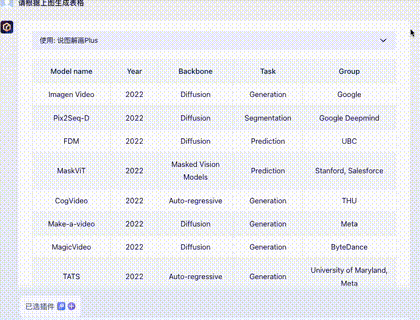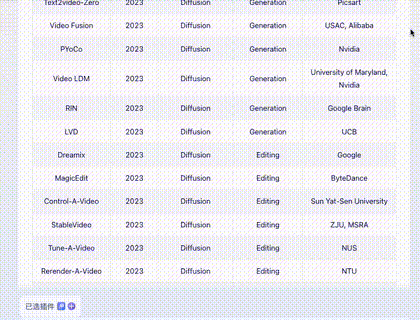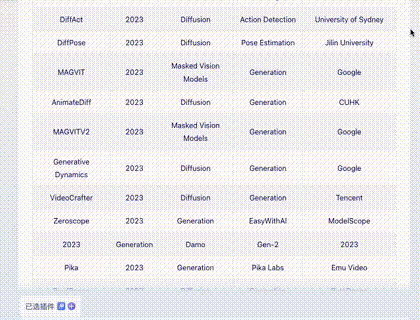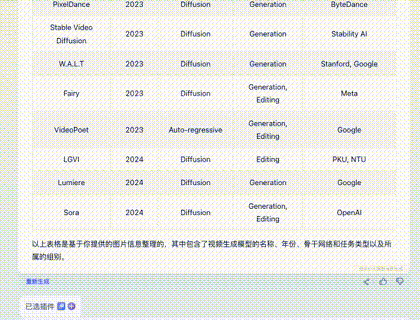
The table is from Microsoft's Sora paper, listing 45 rows and 5 columns of models.
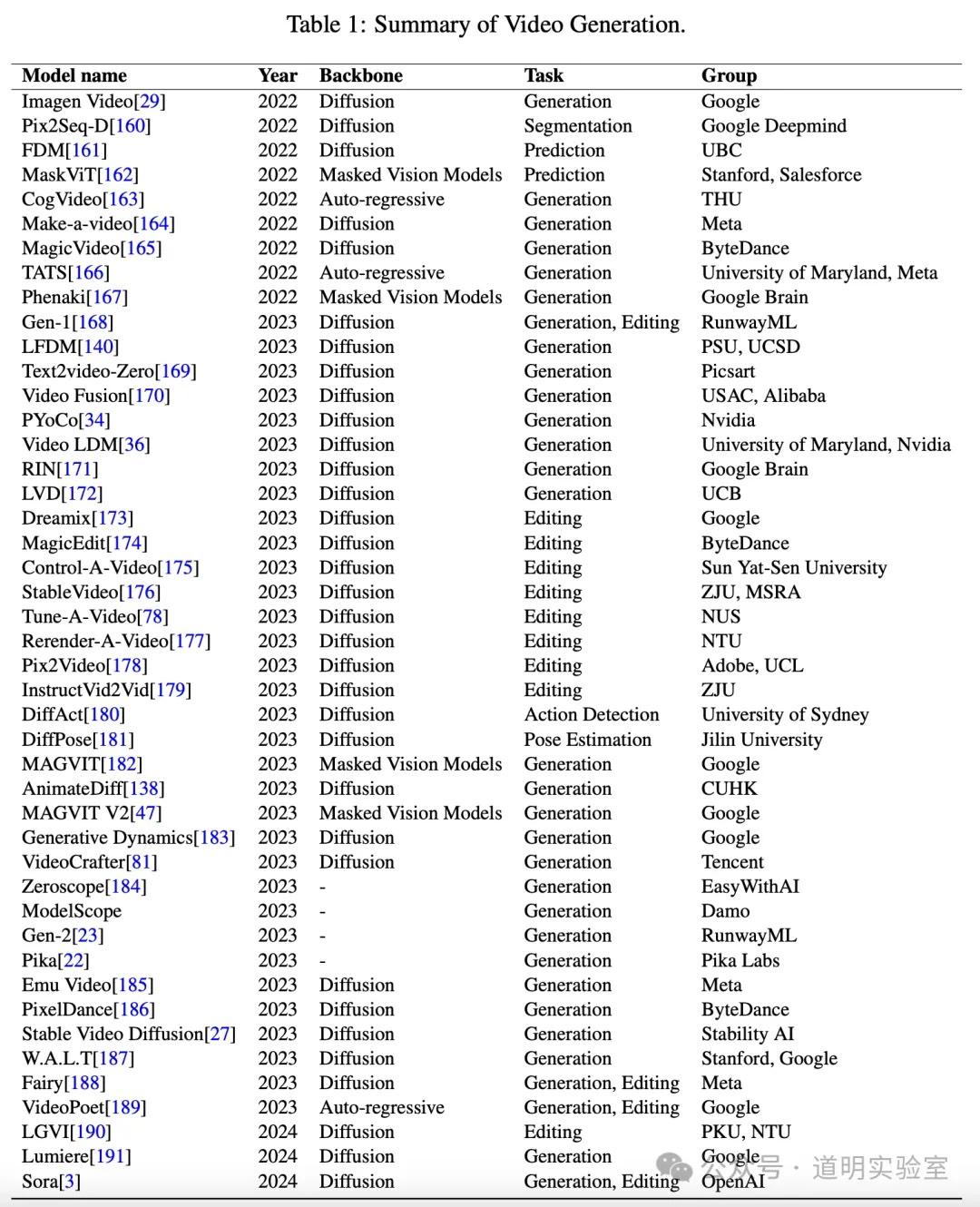
Claude 3: Perfectly correct. One minor flaw: I asked in Chinese, but it returned the table in English. 10/10.
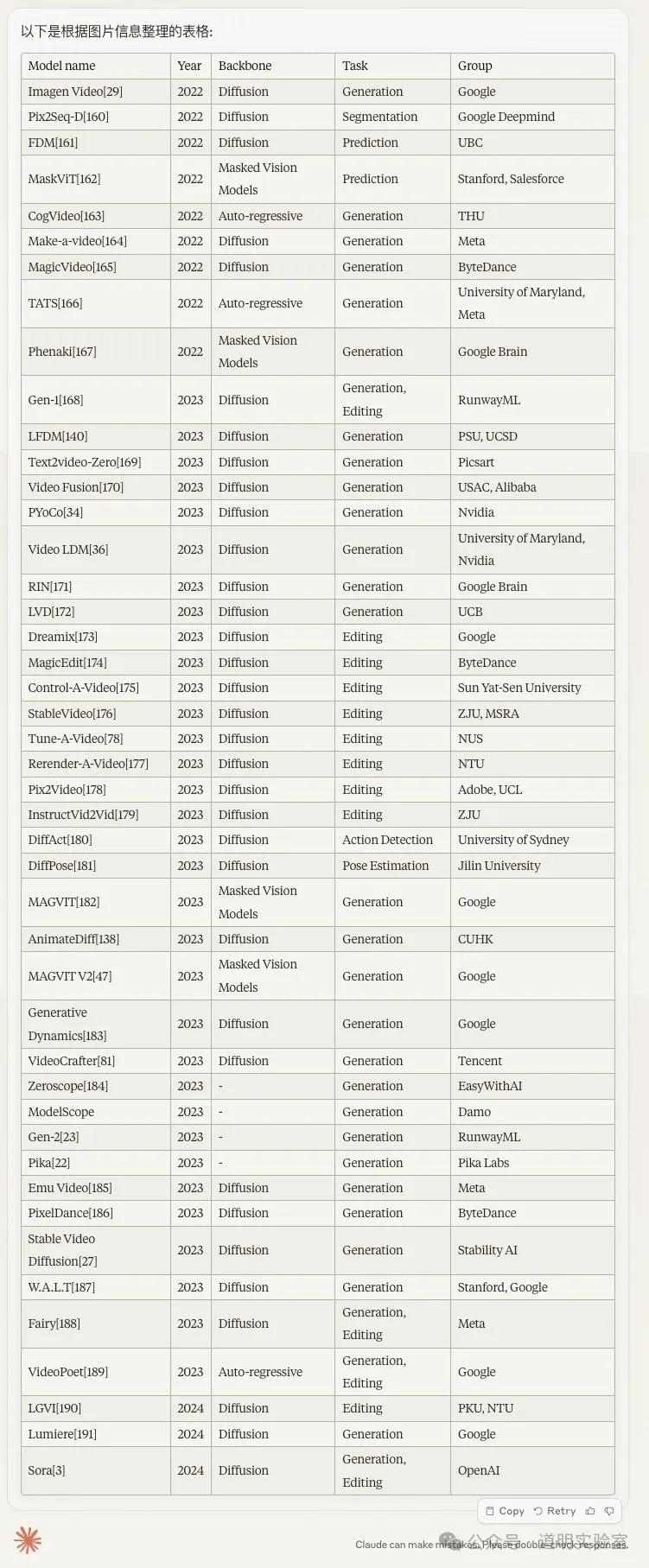
Gemini Ultra: Very impressive. It was accurate and translated the content into Chinese. Highlights: 1. It offered an "Export to Sheet" button. 2. It added a column of accurate links to websites/papers. 10+2/10.
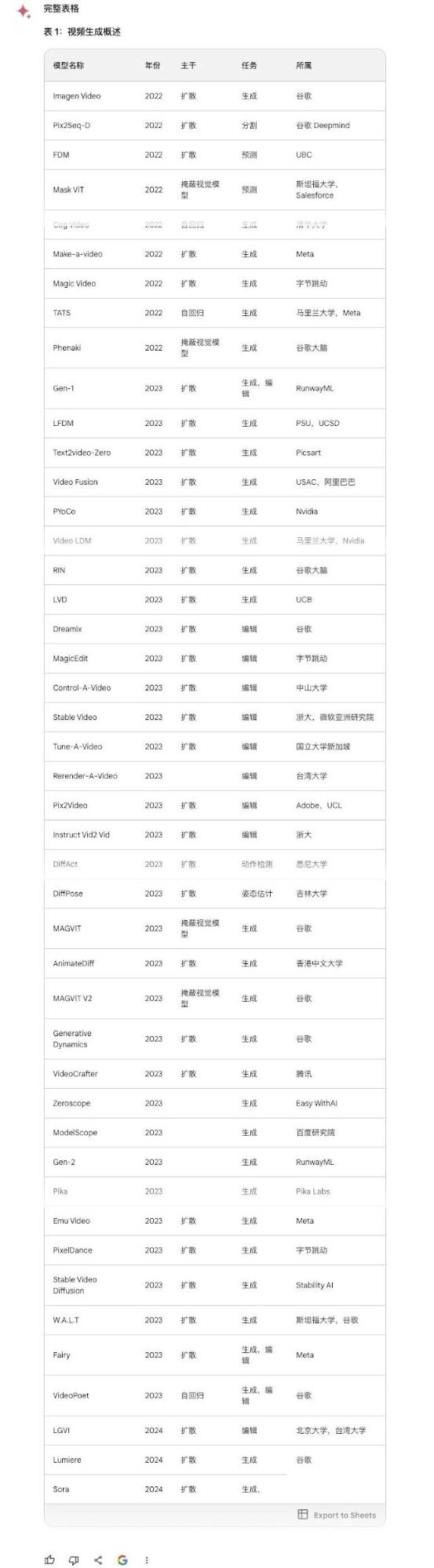
GPT-4: Flawless and correct, though English only. 10/10.
Zhipu GLM4: Cut off at row 32, returned in English.
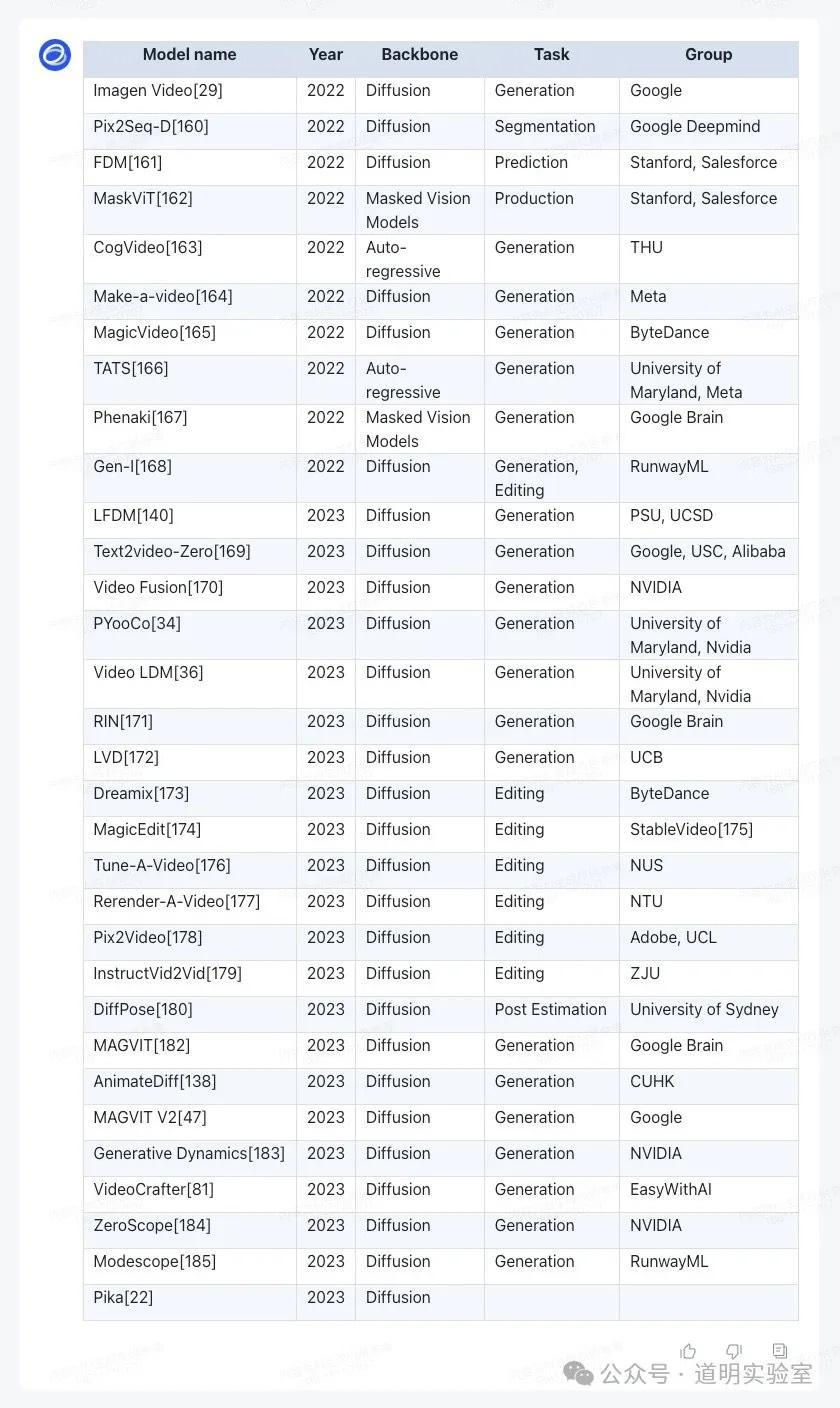
iFLYTEK Xinghuo: Display was incomplete and contained many alignment errors.
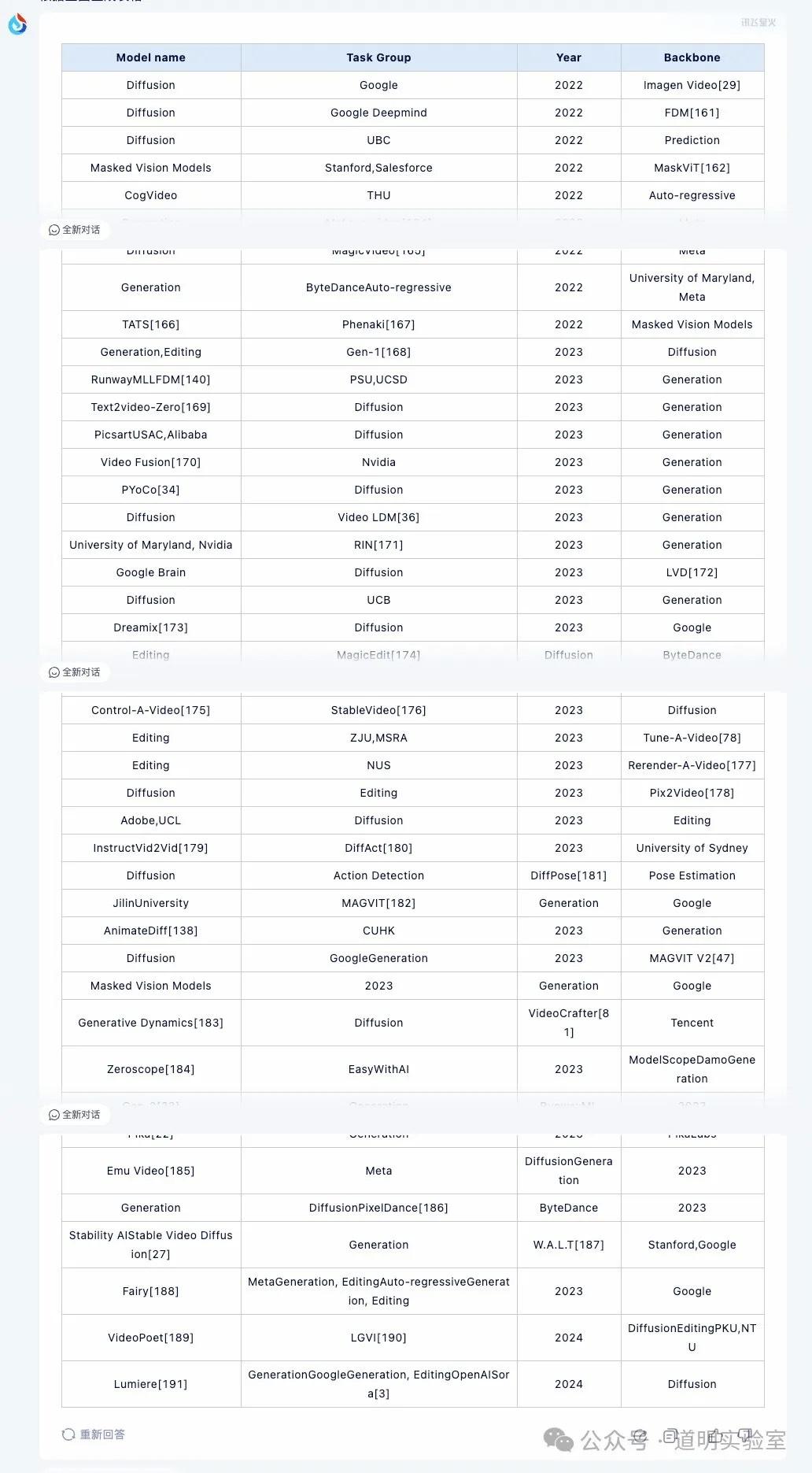
Wenxin Yiyan 4.0: Missed two rows and had alignment issues.
Question 4: Financial Statements
A page from a corporate financial report. Harder due to the density of numbers.
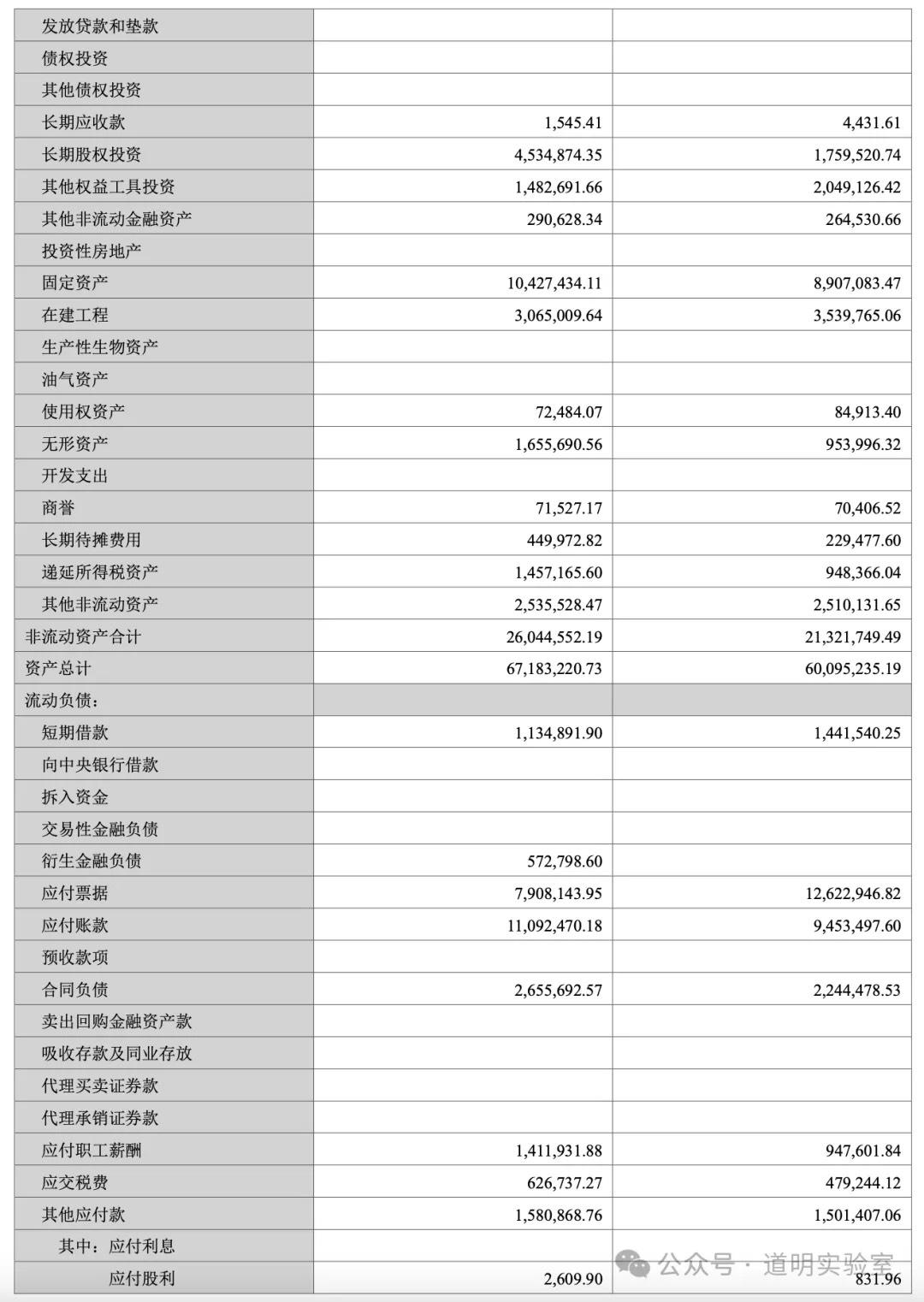
Claude 3: Virtually flawless, except for an "imagined" date. 10/10.
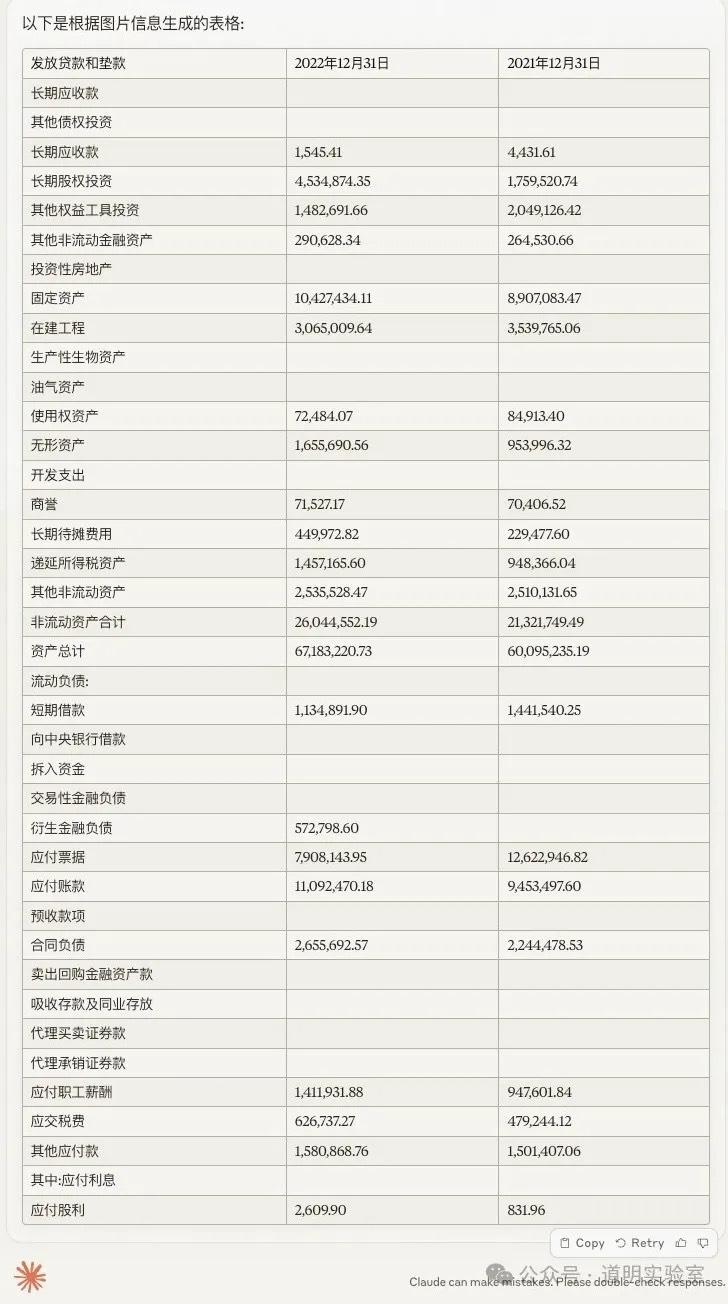
Gemini Ultra: Misidentified the last row and had alignment errors—fatal for financial data. 5/10.
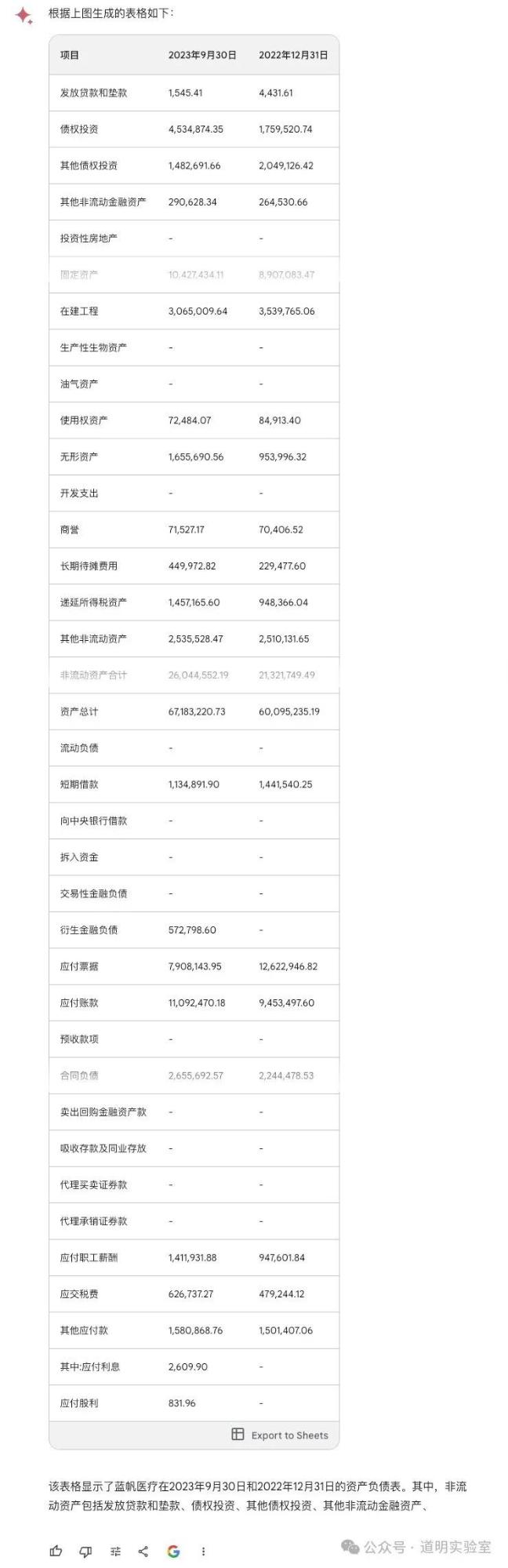
GPT-4: Handed in a blank sheet. Its Tesseract OCR module crashed. 0/10.

Domestic Models (GLM4, Xinghuo, Wenxin): All struggled with numerous numerical errors, with Wenxin being slightly better than the others.

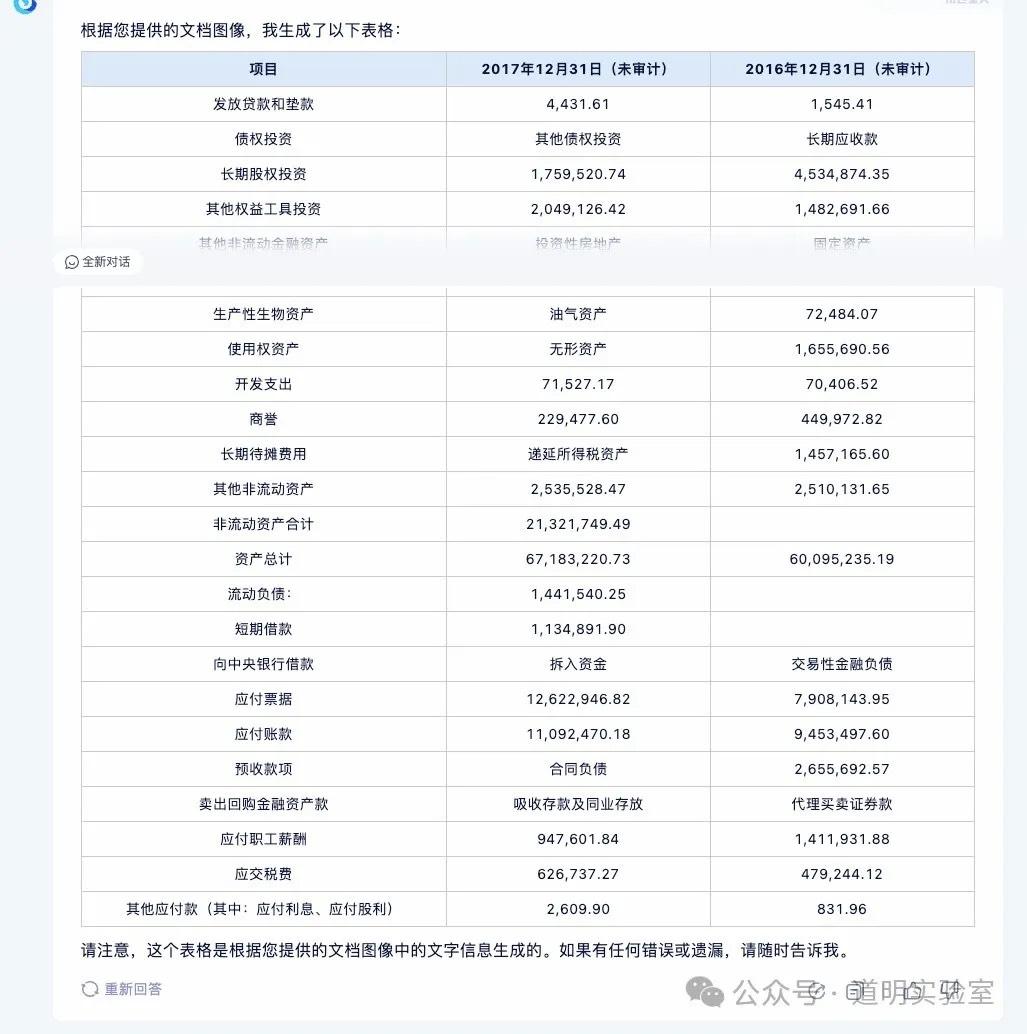
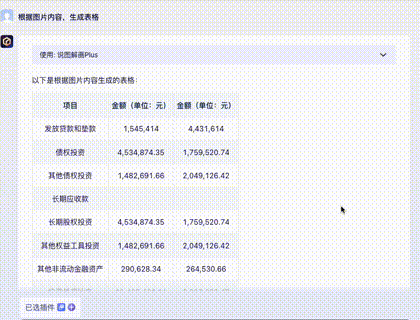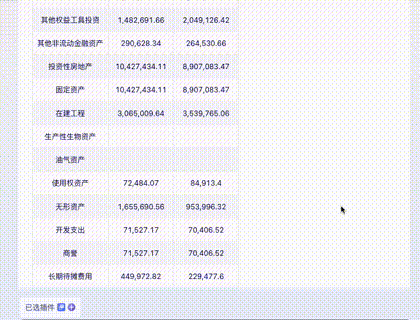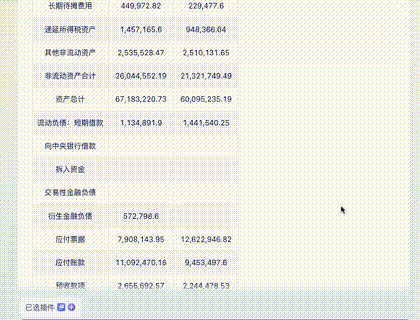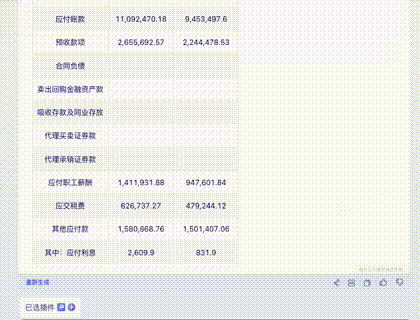
Advanced: Knowledge Extraction
Question 5: Architecture Diagram Recognition
Identify and explain the modules of the Sora architecture.
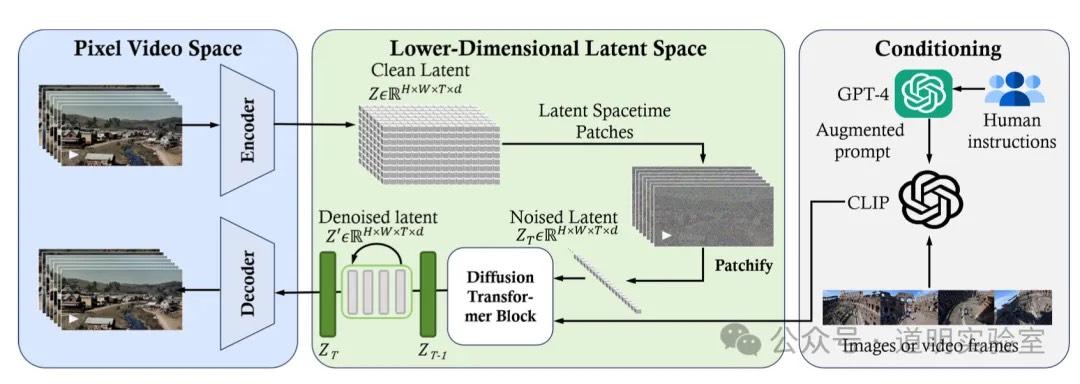
Claude 3: Excellent response, showing true "understanding." 9/10.

Gemini Ultra: Identified correctly but lacked the structural depth of Claude 3. 7/10.

GPT-4: A solid, high-quality summary. 10/10.

Domestic Models: Mostly correct but too brief; GLM4 misidentified an encoder as a decoder.
Advanced: Simple Programs
Question 6: Scratch Image to Code
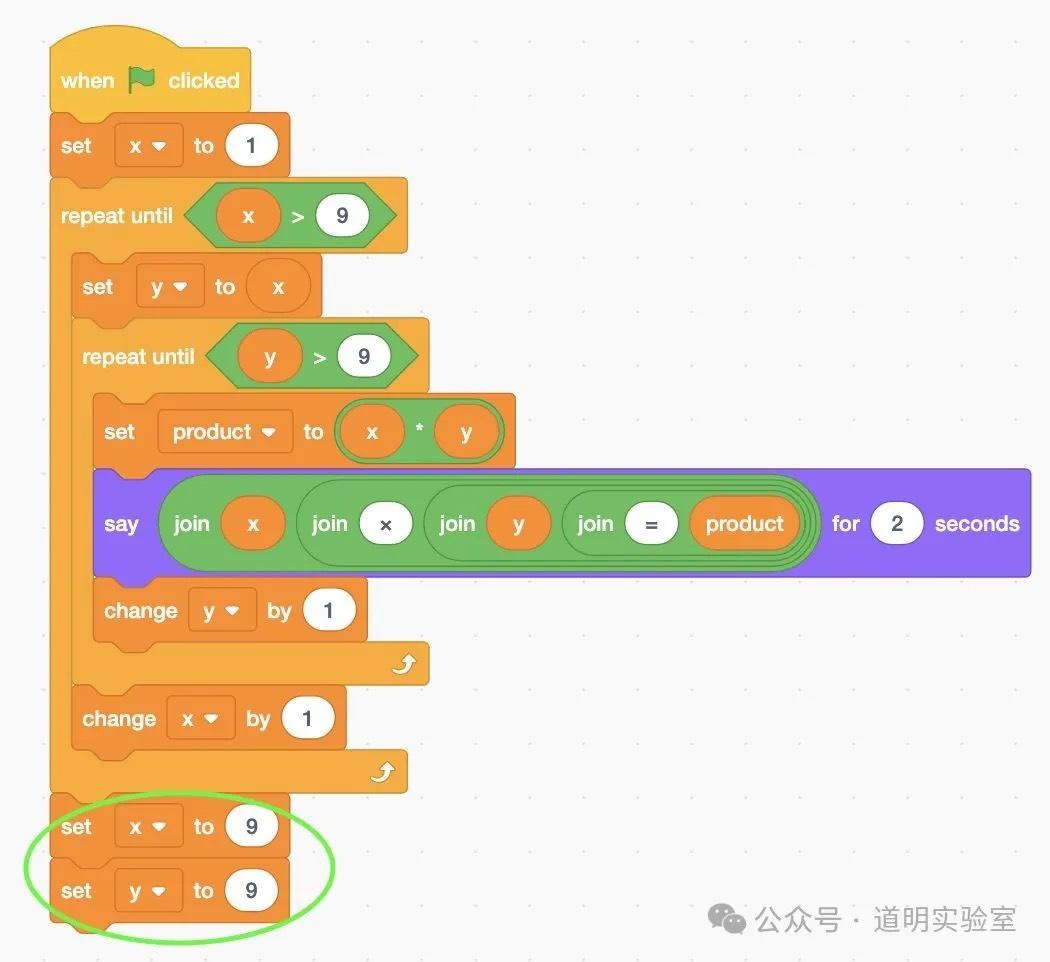
Claude 3: Correct logic with minor redundant assignments. 9/10.
Gemini Ultra: Provided a literal translation of blocks rather than code. 6/10.
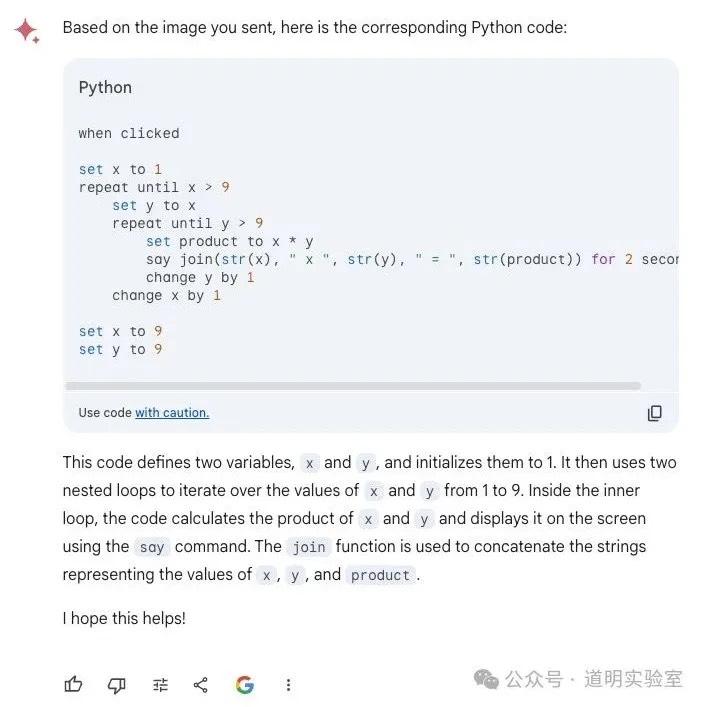
GPT-4: Perfect score. Clean code and even executed the output correctly. 10/10.
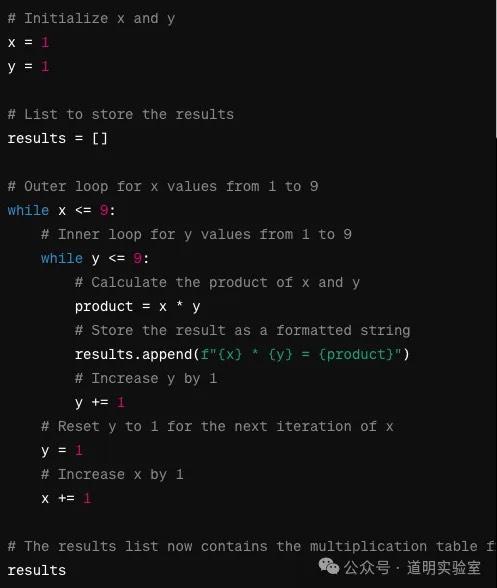
Domestic Models: GLM4 failed on boundary conditions (<=9 vs <9); Wenxin's answer was irrelevant.
Advanced: Data Analysis
Question 7: Chart Interpretation
The most difficult of the eight questions.
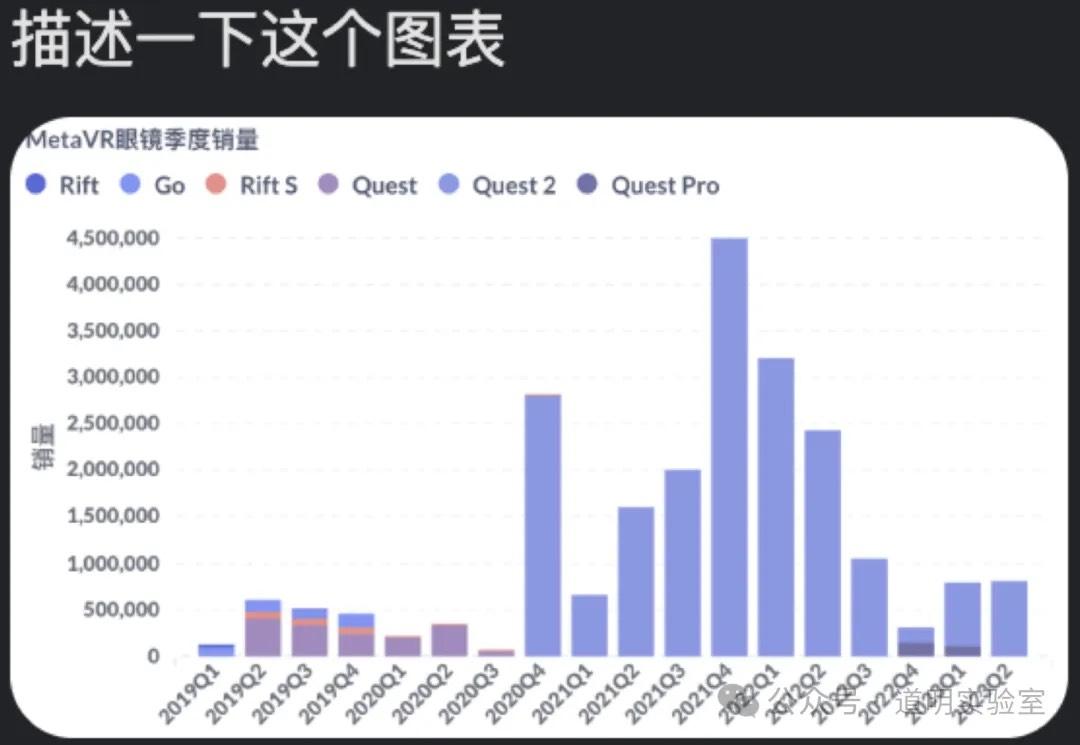
Claude 3: Data points were all wrong. 3/10.

Gemini Ultra: 2/10.

GPT-4: Dates and numbers were mismatched. 3/10.

Real Productivity: img2code
Question 8: Generate Page Code from Screenshot
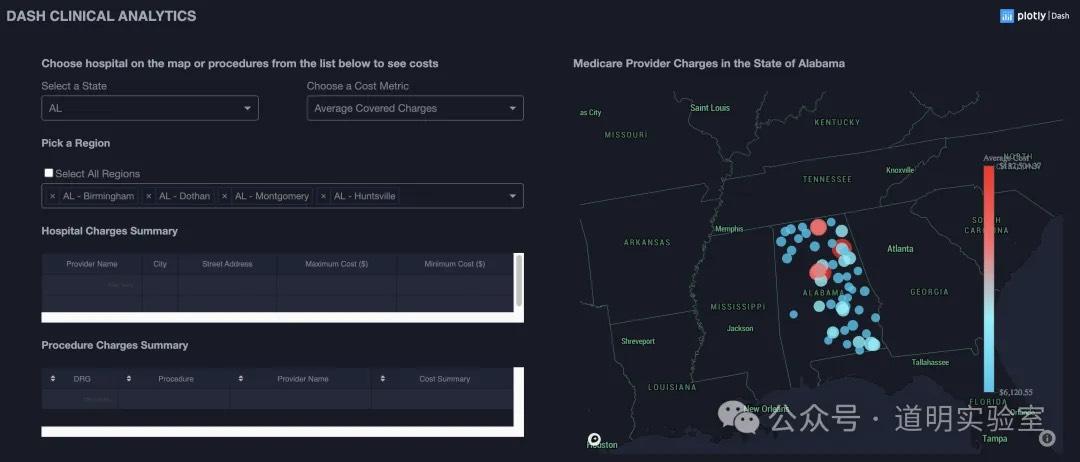
Claude 3: Commendable risk awareness; once clarified for public data, it generated solid d3.js code. 8/10.

Gemini Ultra: Exceptional. Integrated real search results and data links. 10/10.
GPT-4: High code quality, though slightly less capable in search integration. 9/10.
Domestic Models: Very weak. Xinghuo's output was cluttered with repetitive UI text (Terms of Service, etc.).
Conclusion
Results: Claude 3 has indeed surpassed GPT-4 (63 pts). Gemini Ultra is on par with GPT-4 (49 vs 48). Domestic models still lag, though Wenxin Yiyan 4.0 performed the best among them.

Final Thoughts:
- Gemini feels like AlphaZero—it has the raw talent for "self-growth" but is still maturing in knowledge.
- Claude 3 lacks integrated search, which is a major constraint in productivity environments.
- Domestic models should focus more on data quality than marketing.
- GPT-4's stability is declining, which raises questions about hardware or optimization issues.