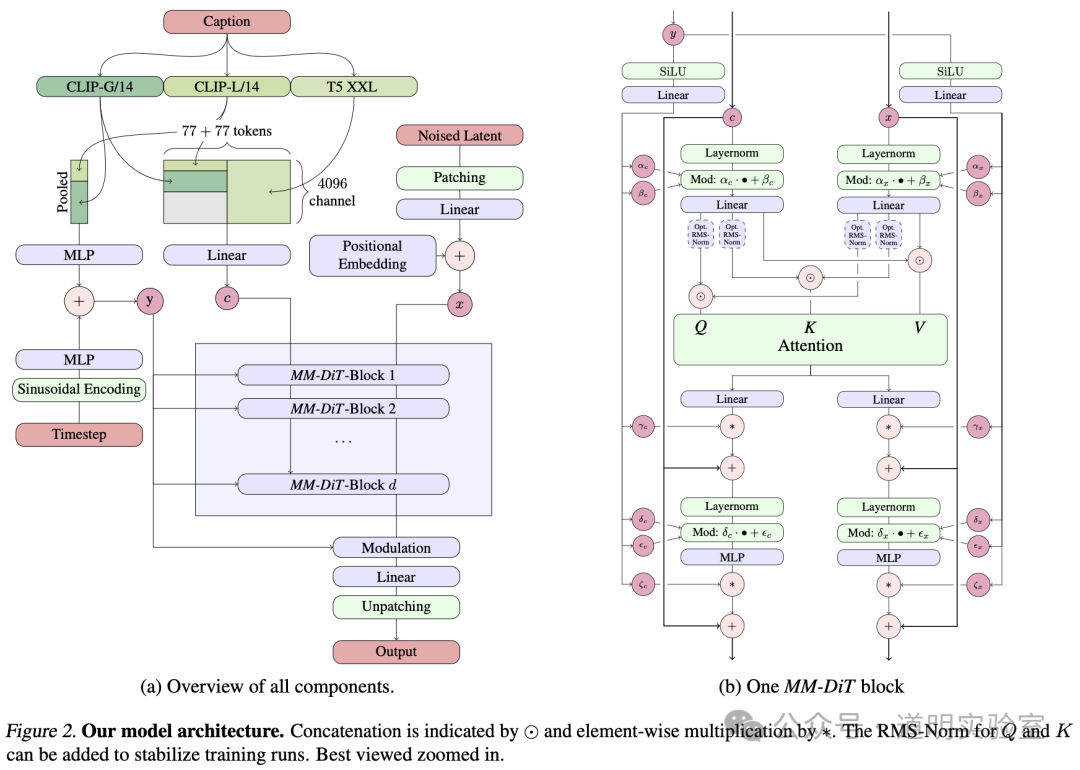
Below is the model architecture diagram for Stable Diffusion 3. As usual, I will share some thoughts and evaluations of this model.
Indeed, this architecture is quite sophisticated, utilizing two DiTs. In simple terms, one handles images while the other handles text, before they are fused. More complexly, the component responsible for text isn't just about text; it incorporates models like CLIP, which can be understood as a model that maps text to images.
Consequently, this model should possess superior text comprehension, supporting more complex prompts. By introducing DiT, it also ensures better consistency in the results.
Furthermore, such an architecture allows for easy scaling and could potentially reach the inflection point of "emergence."
The problem is: at least over 99% of people, myself included, cannot replicate this model.
For secondary market investment, this isn't necessarily an issue—replicable targets often lack unique value. One simply looks at the results. However, the characteristic of this field is that changes are never sustainably trackable; the progress curve is not continuous but consists of one pulse after another.
Yet for researchers, or those hoping to tap into new business opportunities based on so-called AI capabilities, this is an incredibly terrifying state: an opportunity suddenly "appears," and then it's suddenly "game over."
NVIDIA's stock price has nearly doubled again in the past two months. Companies like Stability.AI cannot even secure enough resources and had to announce on their official website that a new cluster built with 4,000 Intel Gaudi2 AI accelerators is now in place.
Computing power is naturally one of the barriers blocking most people. Data? Even more so.
Transformers have proven to be highly scalable, but on small scales and small datasets, their performance is inferior to traditional models. In other words, without massive clusters and immeasurable amounts of data, we cannot witness "emergence" as it happens.
While OpenAI's move toward being "Closed" is a choice based on various considerations, the reality is that model training has already entered a path of rapid enclosure. It's just that due to the time required for training, there is a time lag before outsiders see the manifested results.
The increasing enclosure of model training does not mean open-source competitiveness is weakening. More companies and individuals will persist with "open source" as both a competitive strategy and a means to gain more professional feedback.
Perhaps more and more people will have to abandon their "illusions" and choose to become what Cohere defines as "Independent Researchers," working for "Large Language Models" rather than attempting to understand or even control them.
Verticals and "small data"? It's like digging a well a few meters deep only to find the groundwater table rising rapidly; individual vertical "shafts" are instantly connected into a single ocean by the flooding water.