Kimi Chat火了,因为开始滚动推出200万上下文的试用,也因为,它在一个还不错的模型基础上已经可以提供20万上下文的长文档能力。大概在Claude3发布的那一天,在老朋友提醒下,我开始将Kimi Chat列入日常观察名单。
客观而言,Kimi是第一个达到“可用”级别的“国产大模型”。至于说怎么去打榜刷分,怎么跟海外去比较,在当前这个时点,实际意义其实并不大。
日常工作生活中,我们大概有一些高频应用场景:知识搜索或者问答;翻译;写文章或者邮件;处理长文档。目前看起来,或许,翻译是最刚性的, 文章或邮件其次,知识搜素及问答看个人习惯……
处理长文档,确实是最有潜力的。所以,各家都在想办法提高上下文长度(一次可以向模型输入的token长度):GPT-4-Turbo支持128K(约6.4万汉字),Claude3可以支持200K,Gemini 1.5 Pro可以支持1M(这个已经逐步给开发者测试,我上周拿到后也做过评测)。
“国货之光”Kimi公开可以支持200K,逐步开放2M文字的测试。
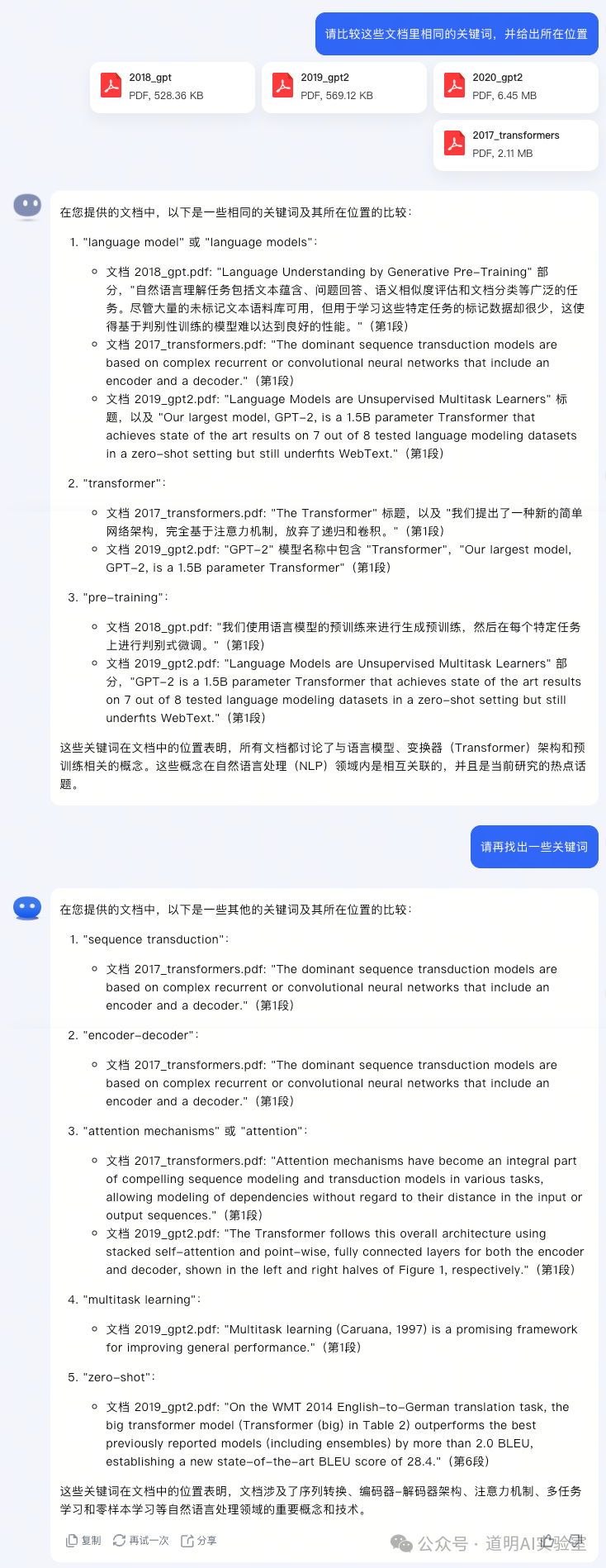
上下文就等于大模型的内存,更长的上下文意味着模型接受更多的信息,理论上,也就可以处理更多信息。以Kimi Chat为例,在公开可用的200K上下文版本里,上传四篇论文,其实就是2017年的transformer,以及gpt和gpt2。
截图展示了“可用”级别的模型能力。处理长文档的能力也没话说,特别是当更长的上下文支持时,跨文档对比的能力在实际使用中是非常重要的。
但是,发现没有?模型并不能在一个回答中给出全部答案。
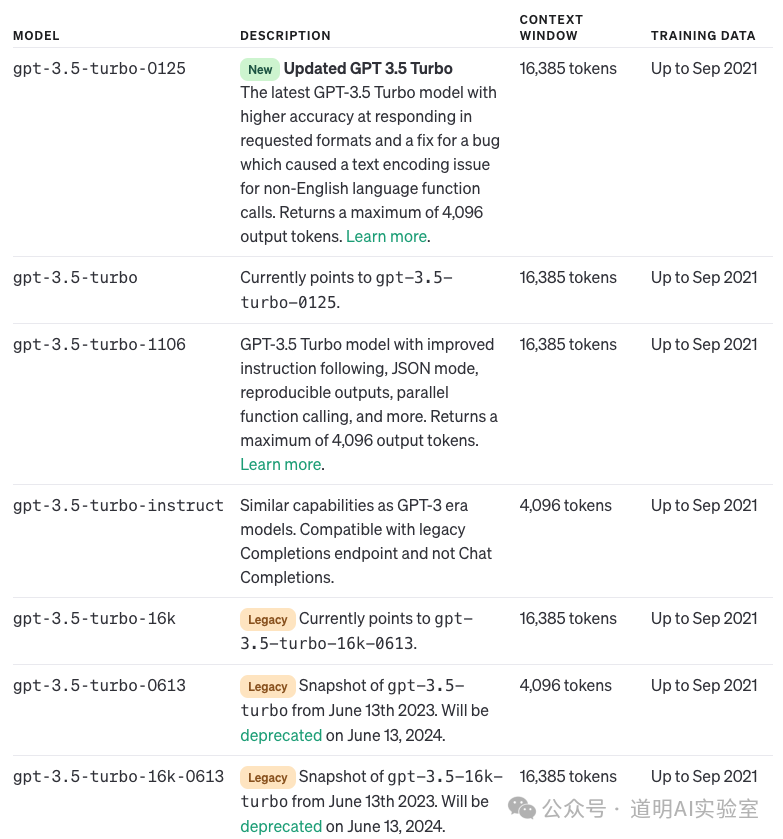
因为,虽然支持200K的上下文输入,但是输出还是被限制在相对较低的水平。Kimi的文档里没有特别明确输出长度的最大值,而在GPT-4里,这个值是4096个token,Claude3也是4096,Gemini 1.5是8192,1.0是4096和2048。
所以,目前的解决方案就是多轮对话里要求继续。看起来,Kimi做的还不错。但是,给我印象最深刻的确实还是Gemini 1.5 Pro,在前天让模型翻译Sam Altman接受采访的文字版本时,继续了超过二十次,但是每一段拼合在一起时,都是通顺的,没有重复一个字,也没有漏掉一个字。
长上下文输入,对于模型而言,是一次压缩,能力则体现在压缩的损失度,有一个“大海捞针”(Needle in a Haystack)测试,可以相对客观的评价这种损失率:在一个非常长的文本的不同位置加入一句话(针),然后看模型能否通过prompt方式把“针”准确的找出来。
在月之暗面(Kimi Chat母公司)的官方资料里,给出了前后几个版本的测试结果。
最好的结果是,输入上下文长度从1k到128k,每个“针”都能被准确的找到。
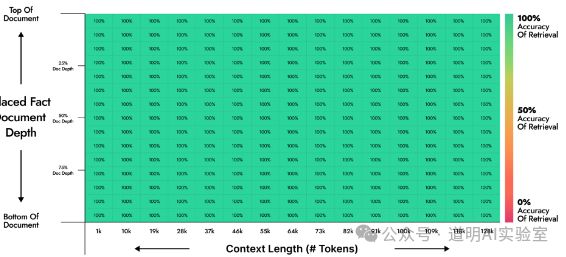
但是,当Kimi模型进行了一次升级后,即使做了优化,这个结果也变差了。
感兴趣的,可以移步
Kimi Chat“大海捞针”测试
Moonshot AI,公众号:Moonshot AI
Kimi Chat 公布“大海捞针”长文本压测结果,也搞清楚了这项测试的精髓
当然,Gemini在1.5 pro的技术文档里也做了类似的测试。当然,他们最长做到了10M(千万token)。

小结:超长上下文可以带来真正的生产力应用;但是输出长度不足还是限制了模型的能力;Kimi Chat和Gemini一样,基本找到了“无损压缩”超长上下文的方法;其实,模型依然还是不稳定的,每一次升级都会导致输出结果的前后不一致。
为什么“上下文输入长度不断提高,输出长度却一直没有显著提升”?我初步的答案是:提高上下文输入长度对模型预训练影响不大甚至可以不需要重新预训练,而提高输出长度很可能需要重新预训练,并且至少是线性的拉长预训练时间。
超长上下文可以应用在哪里?
批量处理文档
处理超长视频及声音:上课或者演讲视频,超长会议纪要……
知识汇总、比对,长文本翻译,财务分析,小说、剧本理解……
是的,超长上下文一直是我期待的,我们也在各种场景持续进行各类应用测试,但是,随着使用的深入,它也不断在改变着我的一些认知:
时至今日的大模型,已经不是一个简单的多少参数规模的单一神经网络或者MoE,而是一系列模型和技术的综合体,比如超长上下文的“无损压缩”技术其实跟基础的预训练模型耦合度有,但绝对不是很高。
我以前一直认为模型只要到“可用”,剩下的可以开发各种配套工具和代码来进入生产环境,但是现在看来,“核心模型”的能力依然是最重要的基础,海外的三个(GPT4,Claude3,Gemini)明显在这方面优势非常明显。
大模型的输出依然非常不稳定,即使使用场景不变,输入数据不变,prompt不变,输出结果也会差异巨大。这对应用落地的挑战依然非常巨大。这或许也是OpenAI的API保留尽可能多历史版本选择选项的最重要原因。
我一直认为AI可以不断降低门槛,从一般用户的视角看,或许位是这样的。但是从应用落地的视角看,或许是不同的故事。模型应用程度越深,对模型本身、场景、技术的理解和整合能力要求就越高:当模型本身就可以解决90%以上问题时,剩下10%问题解决的门槛大概率是比以前更高的。
我们只能期待,下一个更好的。