Kimi Chat has gone viral, partly due to the rolling release of its 2-million-token context window trial, and partly because it already provides a 200,000-token long-document capability on top of a decent model. Around the day Claude 3 was released, following a reminder from an old friend, I began including Kimi Chat on my daily observation list.
Objectively speaking, Kimi is the first "domestic large model" to reach a "usable" level. As for how to chase leaderboard rankings or how it compares to overseas models, the actual significance at this point is not that great.
In our daily work and life, we generally have several high-frequency application scenarios: knowledge search or Q&A; translation; writing articles or emails; and processing long documents. Currently, it seems that translation might be the most essential, followed by articles or emails, while knowledge search and Q&A depend on personal habits...
Processing long documents indeed holds the most potential. Therefore, various companies are finding ways to increase the context length (the length of tokens that can be input into the model at once): GPT-4-Turbo supports 128K (about 64,000 Chinese characters), Claude 3 can support 200K, and Gemini 1.5 Pro can support 1M (which has been gradually released for developer testing; I conducted a review after getting access last week).
Kimi, the "Pride of Domestic Goods," publicly supports 200K and is gradually opening testing for 2M text length.
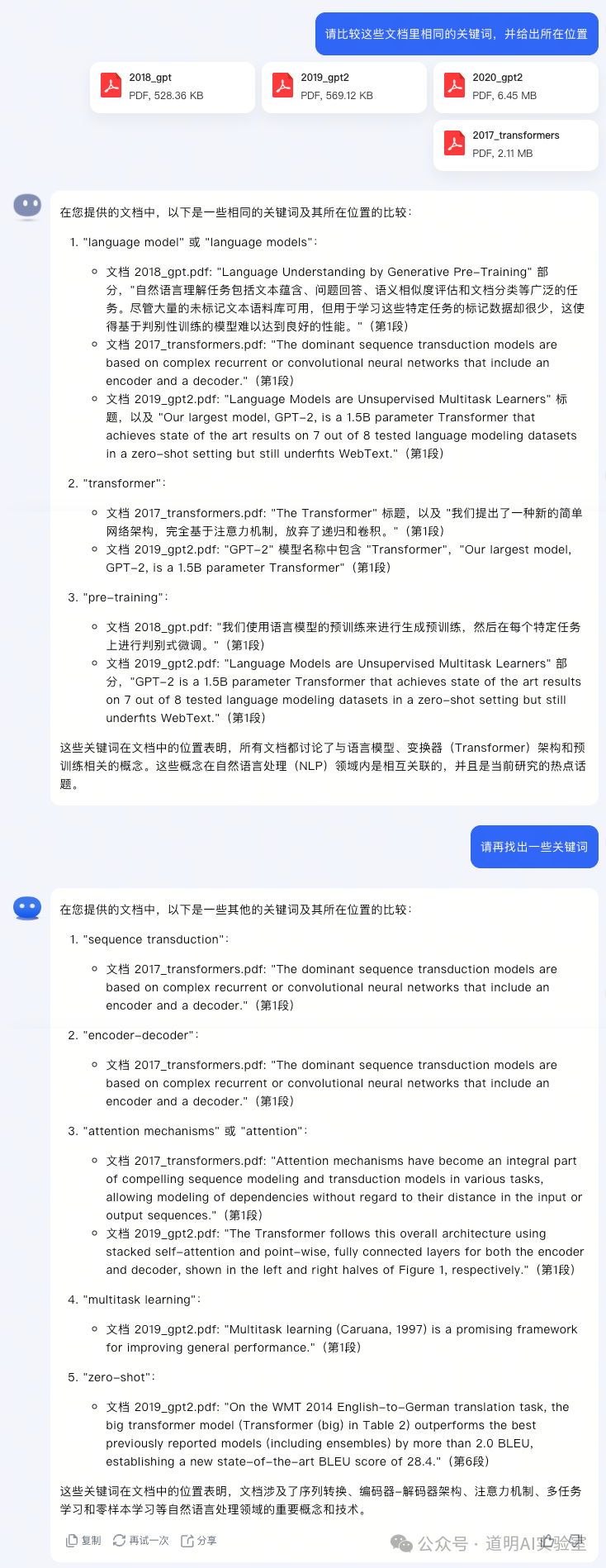
Context is equivalent to the memory of a large model; a longer context means the model can accept more information and, theoretically, process more information. Taking Kimi Chat as an example, in the publicly available 200K context version, uploading four papers—specifically the 2017 Transformer paper, along with GPT and GPT-2—yields results.
The screenshot demonstrates "usable" level model capabilities. The ability to handle long documents is unquestionable, especially when longer context support is available; the ability to perform cross-document comparison is extremely important in practical use.
But have you noticed? The model cannot provide the full answer in a single response.
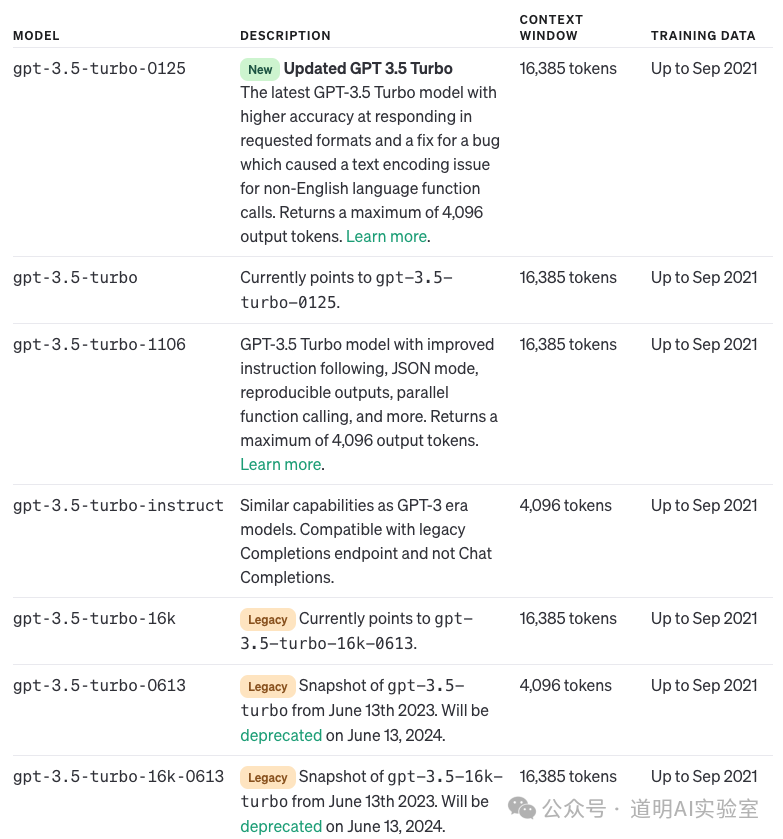
This is because, while it supports 200K input context, the output is still restricted to a relatively low level. Kimi's documentation doesn't specify a clear maximum output length, but in GPT-4, this value is 4,096 tokens, as it is in Claude 3, while Gemini 1.5 is 8,192, and version 1.0 is 4,096 or 2,048.
Therefore, the current solution is to request the model to "continue" in multi-turn dialogues. Kimi seems to do this quite well. However, the one that impressed me most was Gemini 1.5 Pro. The day before yesterday, while asking the model to translate a text version of an interview with Sam Altman, I had to request it to continue over twenty times, but when every segment was pieced together, it was coherent—not a single word repeated, and not a single word missed.
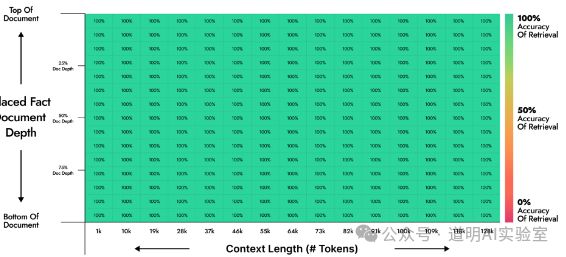
For a model, long context input is a form of compression, and its capability is reflected in the lossiness of that compression. There is a "Needle in a Haystack" test that can relatively objectively evaluate this loss rate: a sentence (the "needle") is inserted at different positions within a very long text, and the model is then tested to see if it can accurately find the "needle" through a prompt.
Official materials from Moonshot AI (Kimi Chat's parent company) provide test results for several versions.
The best result was that from 1k to 128k input context length, every "needle" could be accurately found.
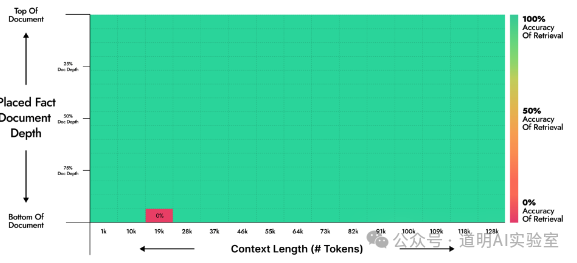
However, when the Kimi model underwent an upgrade, even with optimizations, this result actually deteriorated.
For those interested, you can refer to:
Kimi Chat "Needle in a Haystack" Test
Moonshot AI, WeChat Account: Moonshot AI
Kimi Chat announces "Needle in a Haystack" long-text stress test results and clarifies the essence of this test
Of course, Gemini also performed similar tests in the technical documentation for 1.5 Pro. Naturally, they scaled it up to 10M (ten million tokens).

Summary: Ultra-long context can bring true productivity applications; however, insufficient output length still limits model capabilities; Kimi Chat, like Gemini, has essentially found a method for "lossless compression" of ultra-long context; in reality, models are still unstable, and every upgrade can lead to inconsistencies in output results.
Why is it that "context input length keeps increasing, yet output length has seen no significant improvement"? My preliminary answer is: increasing context input length has little impact on model pre-training and may not even require re-training, whereas increasing output length likely requires re-training and increases pre-training time at least linearly.
Where can ultra-long context be applied?
Batch document processing
Processing ultra-long video and audio: lecture or speech videos, long meeting minutes...
Knowledge synthesis and comparison, long-text translation, financial analysis, understanding of novels and scripts...
Yes, ultra-long context is something I have always anticipated, and we continue to perform various application tests across different scenarios. However, as usage deepens, it continuously changes some of my perceptions:
Large models today are no longer a simple single neural network or MoE of a certain parameter scale, but a complex of a series of models and technologies. For instance, the "lossless compression" technology for ultra-long context is coupled with the base pre-trained model, but definitely not highly so.
I used to believe that as long as a model was "usable," the rest could be handled by developing supporting tools and code for production environments. But now it seems that "core model" capability remains the most important foundation; the three overseas leaders (GPT-4, Claude 3, Gemini) clearly have a very distinct advantage in this regard.
The output of large models remains very unstable. Even if the application scenario, input data, and prompt remain unchanged, the output results can vary greatly. This remains a massive challenge for application deployment. This might also be the most important reason why OpenAI's API retains as many historical version options as possible.
I have always believed that AI can continuously lower the barrier to entry—from an average user's perspective, this might be true. But from an application deployment perspective, it might be a different story. The deeper the degree of model application, the higher the requirements for understanding and integrating the model itself, scenarios, and technology: when the model itself can solve over 90% of the problems, the threshold for solving the remaining 10% is likely higher than before.
We can only look forward to the next better one.