Just last week, the ChatGPT plugin feature was officially shut down. It has been nearly a year since its release on March 23, 2023, but considering the actual rollout in June 2023, the lifespan of ChatGPT plugins was roughly nine months.
OpenAI's official explanation is that the plugin functionality has been fully replaced by the GPT Store, hence the official closure.
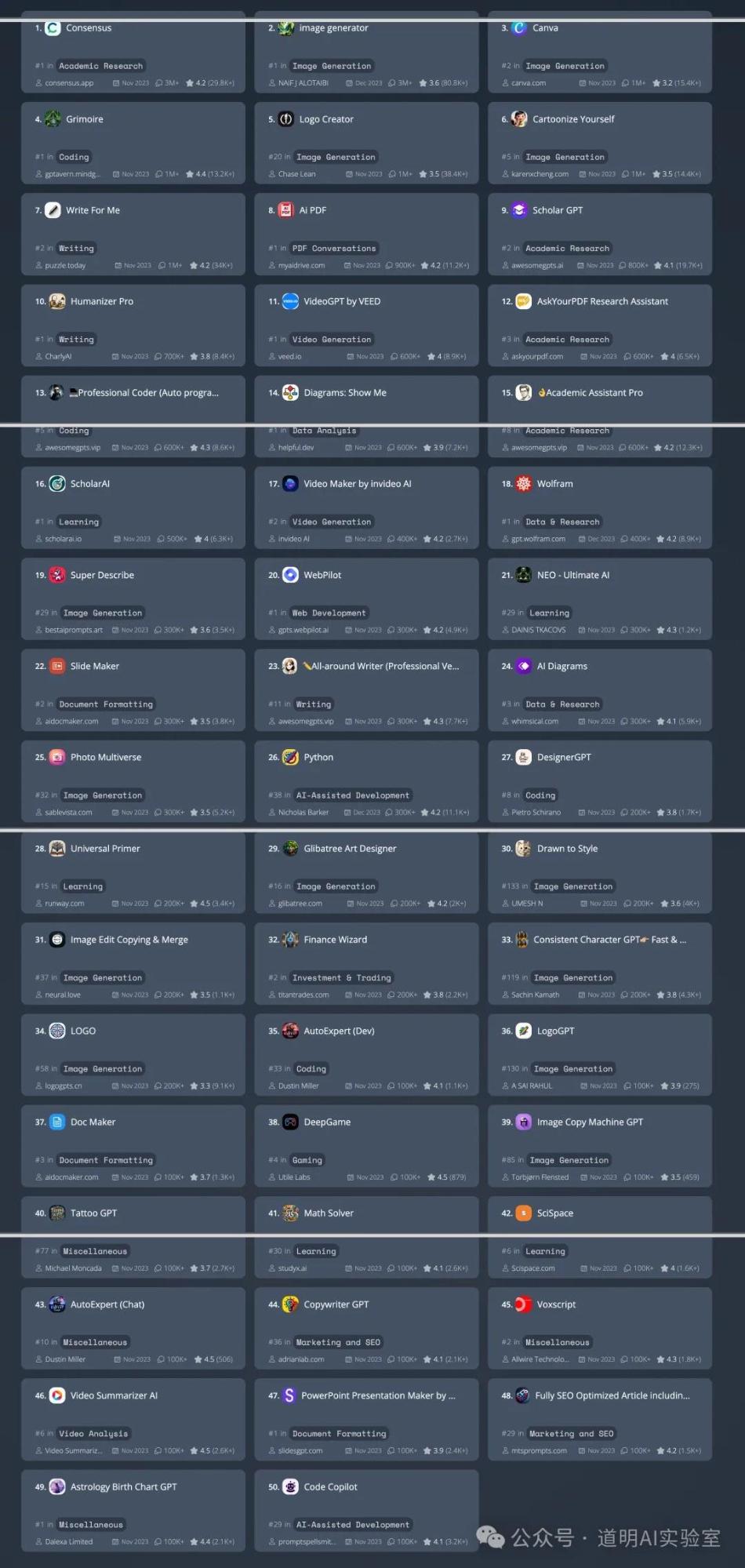
However, if we look closely at the GPT Store data from whatplugin.ai cited yesterday, the situation isn't quite as OpenAI described: even the top-ranked Consensus GPT has only surpassed 3 million conversations, which is not even in the same order of magnitude as OpenAI's daily active user count of 60 to 70 million.
The reality might be that even GPTs haven't actually taken off.
When plugins first came out, I excitedly spoke about their advantages and even wrote a small plugin to facilitate data processing. When the GPT Store launched, I also created several GPTs, again to make data handling easier.
The current outcome is far from what was initially expected, but upon reflection, it is actually quite logical.
We need productivity tools like ChatGPT, and we also need auxiliary tools that can enhance the model's capabilities.
However, no matter how many people use it, ChatGPT cannot become a traffic entry point. Traffic begins with GPT and ends with GPT. This is actually how AI should be: a closed loop.
We are still accustomed to using "Internet thinking" to analyze AI and its applications. However, just as the mobile internet is not the same species as the desktop internet, AI is not the same species as the mobile internet.
In fact, whether it is plugins or the GPT Store, they both represent a massive opportunity: all work related to information processing is worth redoing with large models, and once base models become powerful, the cost of redoing them is theoretically extremely low.
Thus, we saw that when plugins were first introduced, document processing plugins became very useful—parsing PDFs for large models to "learn" from and turn into knowledge bases. Currently, the most popular GPTs are still closely related to "knowledge bases."
But the prerequisite for these "add-ons" to exist is only when the capabilities of the large model have not yet reached those boundaries. When GPT-4 introduced document upload support, paid PDF parsing plugins were declared "dead" almost instantly. In the mobile internet era, developers might just use platform traffic, while the product's core competitiveness lies in itself. In the AI era, developers use the platform's (if we can still call it that) capabilities, which also constitute the product's core competitiveness. However, this seems to bring a paradox: if the demand a product addresses is real, then it is also something people want the large model to support "natively," and the large model will inevitably support it "natively."
Perhaps, before the emergence of AGI, what we need is simply this kind of AI: 1. It reduces or completely replaces "my" dependence on others without affecting others' dependence on "me"—out-competing others while not burdening oneself; 2. It allows us to pay for model service subscriptions and then cancel subscriptions to other tools, thereby reducing costs.