有一套模型,在2017年学习深度增强学习时一直印象深刻:ABM,Agent-Based Model,代理人模型。
我甚至还写了一套代码来进行简单的模拟:假设市场有不同风格的agent,依据某种策略进行交易,他们整体的行为是否可以用来预测市场?
在当时,要模拟出尽可能多的策略或者交易风格,是一件非常困难的事情,需要的数据和计算量都很大,也就放下了。如今七年过去了,其实自从ChatGPT发布后,虽然一直觉得应该有机会重新把ABM模型捡起来,但是因为各种原因自己变得越来越不专注,所以,这个想法只是一直存在于想法状态而已。
今天刷到了一篇论文:《Evolutionary Optimization of Model Merging Recipes》,来自于日本的sakana.ai团队,用到了evolutionary algorithm(进化算法),也用到了模型合并。
无论是进化算法,还是模型合并,都不是创新的,之前也有朋友交流过把几个模型合并再输出,成为一个更好的模型的方案,甚至Open LLM Learderboard上霸榜的都是各种合并模型了。
Sakana团队的成果是利用进化算法将多个7B参数模型合并,达到了state-of-the-art,甚至超过了很多70B模型的表现。团队也开源了算法:https://github.com/SakanaAI/evolutionary-model-merge。
在这之前,其实自己对合并模型没有太多关注,一方面是认为这种合并效果更好应该是符合逻辑的,另一方面确实从日常工作角度出发,依然还是关注最好的模型更多一点。
可是,今天,这篇论文似乎重新点燃了大模型与ABM结合的想法,只是,我知道自己最近一段时间肯定没有时间尝试,所以把想法写在下面,希望能够有所启发。
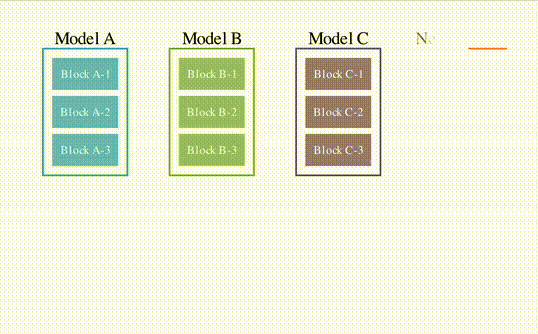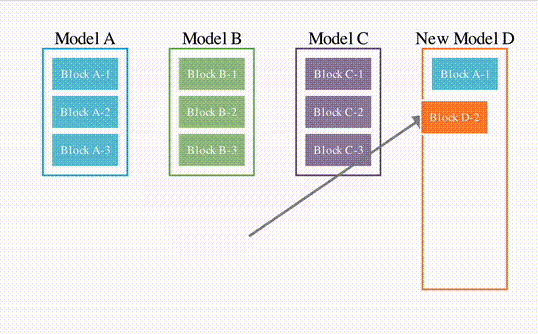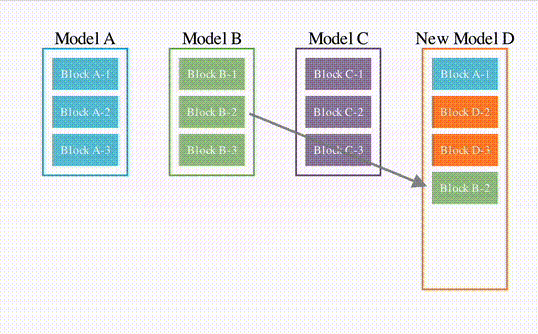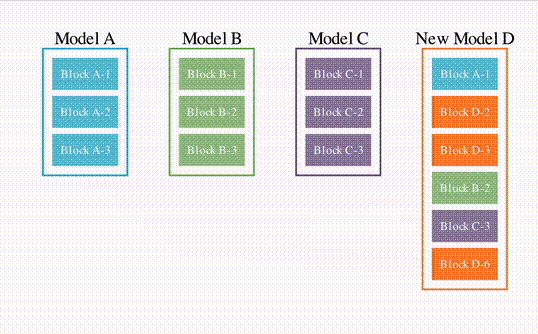
先是模仿上述论文结构的一个简单示意图。
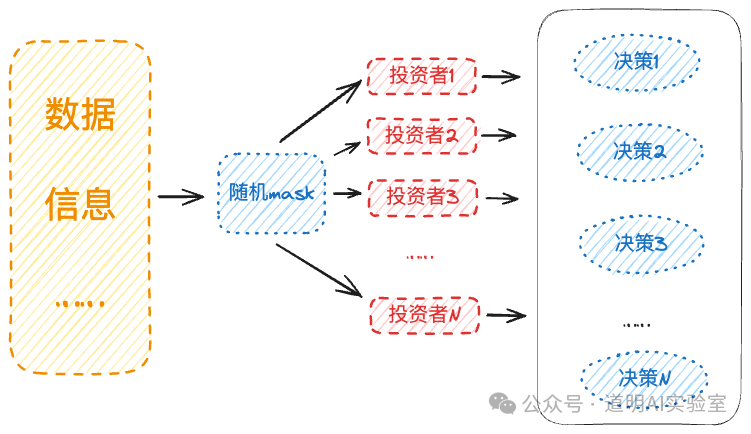
- 如果把示意图里的“投资者”换成“行业”或者“公司”,其实原理可能是一样的;
- 如果我们把市场想象成可能是几千个模型,无论模型本身代表的是不同风格的投资者,还是投资标的,区别在于输入数据;
- 本质上,每一个具体的决策都是在不完全信息下作出的,那么,对于每一个模型而言,在输入时应该进行随机mask(遮蔽),制造信息不对称的环境;
- 理论上,应该结合深度增强学习和遗传算法,这样可以利用市场数据进行有监督的“fine tuning”;
- 其实大模型提供了一个很好的起点,fine tuning的目的也不是为了让模型预测市场,而是形成某种风格,或者对“某一标的”的理解;
- 问题1,实验之前,不太知道需要多少个子模型才能达到某种“规模效应”,但我初步估计,几百个是要的。如果每个模型都是7B大小,INT8精度,那么可能需要几十张H100或者A100(A100与H100都支持MIG,Multi-Instance GPUs,即把一张GPU拆成最多7个实例,对于Kubernetes环境下,看到的就是7个独立GPU)。如果需要几千个模型呢?
- 问题2,理论上,市场的各种结构化或者非结构化数据都是带有时间序列的,时间序列的Transformer还没看到特别惊艳的研究结果,sora基于latent space的spacetime patches与DiT的结合,算是有一些影子,但是要用到真正的时间序列上,可能需要很多尝试。
结语:大概率上面的设想是错的,但是大模型时代,在基础算力和数据的约束条件基本满足的前提下,试错成本远低于以前,至少sora就是试错试出来的。在未来可见的一段时间里,我应该是没有时间更能力进行上面的“试错”。但是,有一点其实过去十年里一直是相信的:我们可能无法找到一个更好的预测市场的模型,但是我们有可能找到许多模仿“投资行为”的模型,它们共同的输出可能至少会接近市场运行的表象。
这些模型,或许就是市场的“世界模型”。