There is a set of models that I've been deeply impressed by since I studied Deep Reinforcement Learning in 2017: ABM, or Agent-Based Models.
I even wrote a set of code to perform simple simulations: assuming the market has agents with different styles trading based on certain strategies, can their collective behavior be used to predict the market?
At that time, simulating as many strategies or trading styles as possible was extremely difficult; it required massive amounts of data and computing power, so I set it aside. Now seven years have passed. Actually, since the release of ChatGPT, I have always felt there should be an opportunity to pick up ABM again, but for various reasons, I've become less focused, so this idea has remained just an idea.
Today, I came across a paper: "Evolutionary Optimization of Model Merging Recipes" by the Japanese team sakana.ai, which utilizes evolutionary algorithms and model merging.
Neither evolutionary algorithms nor model merging are innovative. Friends have discussed merging several models to output a better model before, and various merged models are even dominating the Open LLM Leaderboard.
The Sakana team's achievement lies in using evolutionary algorithms to merge multiple 7B parameter models, reaching state-of-the-art performance and even surpassing many 70B models. The team has open-sourced the algorithm: https://github.com/SakanaAI/evolutionary-model-merge.
Before this, I didn't pay much attention to model merging. On one hand, I thought the logic that merging produces better results made sense; on the other hand, from a daily work perspective, I still focused more on the single best models.
However, today, this paper seems to have reignited the idea of combining Large Language Models with ABM. I just know that I definitely won't have time to try it in the near future, so I'm writing the thoughts down below, hoping they might be inspiring.
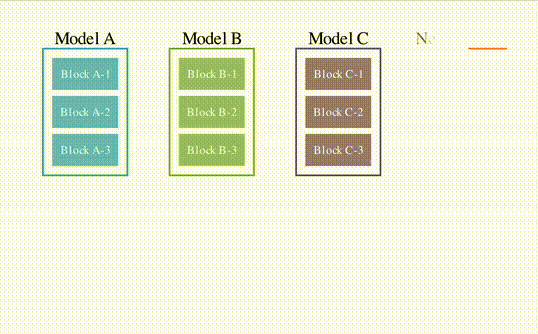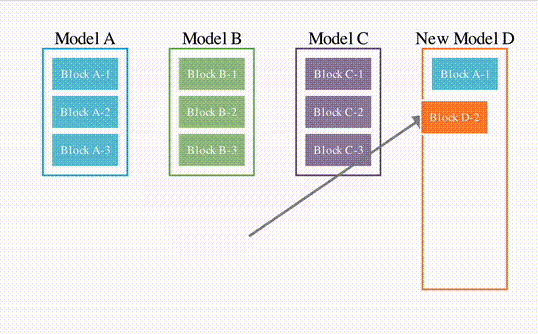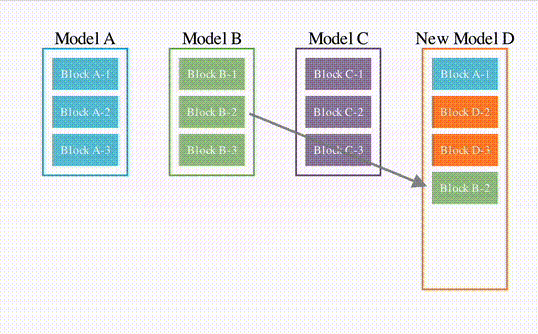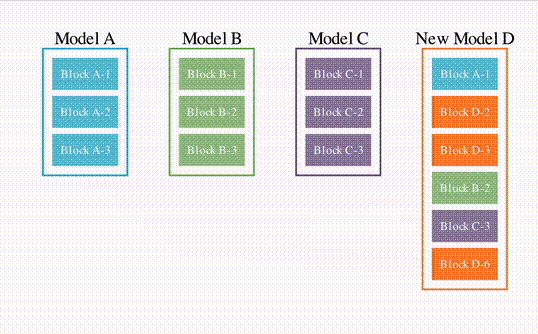
First, a simple schematic diagram imitating the structure of the aforementioned paper.
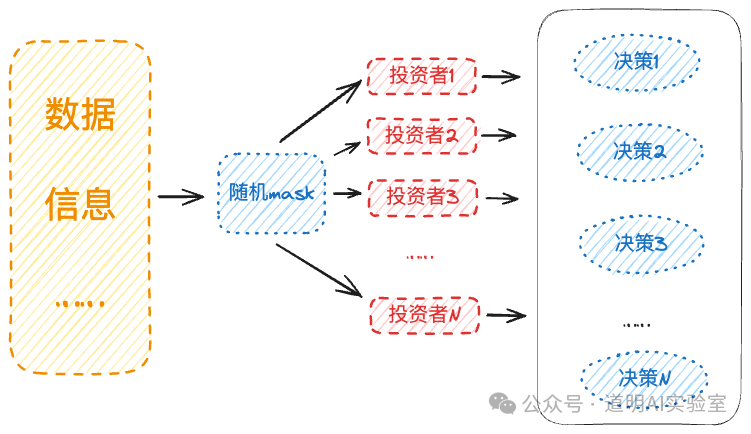
- If the "investors" in the schematic are replaced with "industries" or "companies," the principle might be the same;
- If we imagine the market as potentially thousands of models, whether the models themselves represent different styles of investors or investment targets, the difference lies in the input data;
- In essence, every specific decision is made under incomplete information. Therefore, for each model, random masking should be applied to the inputs to create an environment of information asymmetry;
- Theoretically, Deep Reinforcement Learning and Genetic Algorithms should be combined, allowing for supervised "fine-tuning" using market data;
- LLMs provide an excellent starting point; the purpose of fine-tuning is not necessarily for the model to predict the market, but to form a certain style or an understanding of a "specific target";
- Problem 1: Before the experiment, it's hard to know how many sub-models are needed to reach a "scale effect," but I roughly estimate that several hundred are necessary. If each model is 7B in size with INT8 precision, it might require dozens of H100s or A100s (both A100 and H100 support MIG, Multi-Instance GPUs, which can split one GPU into up to 7 instances, appearing as 7 independent GPUs in a Kubernetes environment). What if thousands of models are needed?
- Problem 2: Theoretically, various structured or unstructured market data are time-series based. I haven't seen particularly stunning research results for time-series Transformers yet. Sora’s combination of spacetime patches based on latent space and DiT shows some glimpses of hope, but applying it to real time-series data may require many attempts.
Conclusion: The above assumptions are likely wrong, but in the era of large models, with basic computing power and data constraints largely met, the cost of trial and error is much lower than before—at least Sora was developed through trial and error. For the foreseeable future, I likely won't have the time or ability to conduct the aforementioned "trials." However, there is one thing I have believed for the past decade: we may not find a single better model to predict the market, but we might find many models that mimic "investment behavior," and their collective output might at least approach the surface phenomena of market operations.
These models might just be the market's "World Model."