进入四月,Databricks发布了DBRX,AI21发布了Jamba,Google Deepmind发了Gemma和RecurrentGemma,Mistral又一次悄悄的给出了Mixtral 8x22b的下载链接……
加上传言中下周就将开始逐渐发布的Meta的LLaMA-3,开源世界确实很热闹:GPT-3.5已经都被开源模型踩在脚下,问题只是,谁会成为第一个超越GPT-4(虽然GPT-4已经不是最好的了,但它依然代表非常重要的分水岭)的语言模型。
另一边,Google的Cloud Next大会后,把基于Gemini的一系列功能快速集成到了Vertex AI,Workspace和Google One中,Chrome浏览器也进行了更新;OpenAI更新了GPT-4 Turbo,提升了多方面的能力;就在几个小时前,xAI发布了Grok-1.5 Vision多模态的预览版。
大家依然在通向AGI的道路上狂奔,但是,在真正具备复杂的“思考与推理能力”模型出来之前,在这一代,缺的已经不是模型,而是关于落地的要素:成本,生态,使用场景。
一个前提:模型已经成为很多人日常使用的重要工具。
虽然看起来现有模型能力下的高频用户量全球也就在一两亿这个量级,但是无论搜索,知识处理,学习研究还是其他,模型已经成为这部分人群日常重要的工具之一。
不同于移动互联网用户边际使用成本趋近于零的特点,生成式AI的使用成本不仅不可以忽略不计,甚至越来越成为商业落地上最重要的因素之一。
居高不下的推理成本如何下降
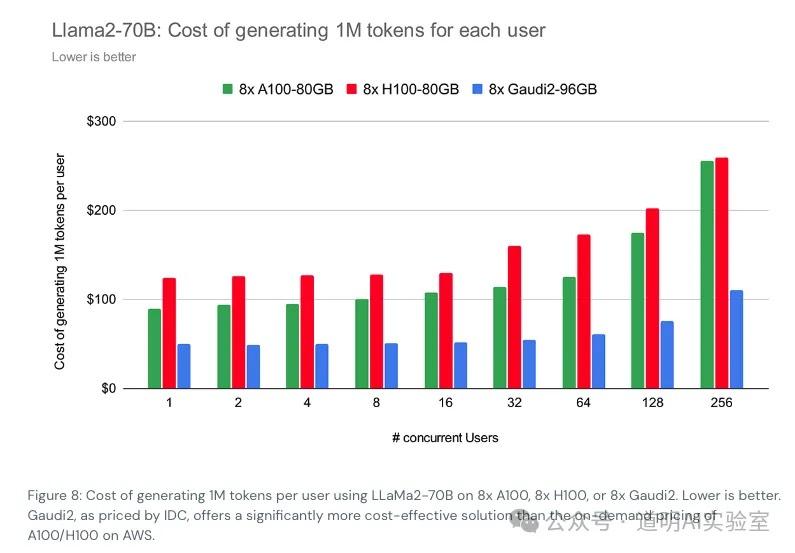
我依然愿意去引用前段时间Databricks计算的LLaMA-2 70B模型的推理成本计算。当然这里有几个假设:1、模型未经过优化;2、硬件成本按照公开的云服务的价格计算。
在上述假设下,大概每生成一百万的token的成本是150美金左右,而GPT-4的API调用成本是,每一百万token收30美金。这其中是一个巨大的差距,尽管我们知道OpenAI使用微软云服务的价格肯定显著低于公开价格,GPT-4的推理部署一定经过了大量的优化。但是,即使是MoE价格的,GPT-4推理时加载的参数规模也显著高于LLaMA-2的70B,另一方面,过去几个月一直诟病的GPT-4“变懒”与“变差”,背后最可能的原因还是因为降低推理成本而作出的质量上的牺牲。
我们知道,通过混合专家(MoE)结构、知识蒸馏(教师-学生模型)、参数裁剪、量化等方式,可以显著提高推理性能(每秒或者每分钟输出的token数量),降低推理成本。
OpenAI一定在降低推理成本上付出了非常大的努力,但是经过各种间接计算,很可能我们依然会得到这样的结论:OpenAI从用户获得的收入依然覆盖不了为推理付出的成本。
而这背后,OpenAI依然付出了“用户抱怨质量下降”的代价。
长期来看,如果transformer架构不改变,那么,真正降低推理成本的“无损”方式,似乎只有:降低硬件成本,包括购置成本和能耗为主的使用成本。
毫无疑问,这一方面,Google具备独特的优势,因为无论训练还是推理,Google的模型都跑在自研的TPU上。
这大概是微软、Meta、特斯拉这些大厂都在加码自研芯片的根本原因,但是,Google的TPU已经迭代到了第五代,显然,这条路,需要以五到十年为计量单位的积累。
开源只是为了免费吗?
开源,Open Source,最早是指开放源代码。它真正的意义是,通过代码开放使用,使得所有开发者(无论是否对开源做出过贡献)都形成一种互助模式:1、对于很多常用的基础功能或者难题,不必全部从头做起,大幅提升效率;2、因为源代码开放,所以对于程序的问题和bug更容易被发现,也更容易尽早被修复。虽然,因为代码开放,别有用心的人会盯着使用多的代码寻找漏洞,从而找到“攻击”的方式,但也正因为代码开放,修复“安全漏洞”的速度也变得很快:矛与盾总是复杂的伴生双面。
如今的AI开源,已经很少有完全意义上的Open Source了,因为这不仅意味着训练代码的完全开放,还意味着训练数据的完全开放:模型是特定数据通过特定训练程序在特定硬件上得到的特定结果。虽然还是存在一些项目,是做到上述意义的完全开放的,但是大家普遍认为的开源模型,就是至少提供模型权重文件的公开下载(是否可以商业无限制使用,还是只能作为非商业的研究使用,则要看模型提供方的商业协议约定)。
可以这么说,如今的AI模型,无论是哪一家的,贡献最大的就是开源社区。不仅仅是因为大家熟知的transformer架构是开放的,也因为在训练模型中用到的很多想法和工具都是开源的,更因为绝大部分的基础数据也是开放的。没有开源社区,就没有如今的生成式AI。
所以,有些人宣扬的“闭源更好”,其实,是没有依据的:我们可以做一个很差的闭源模型,我们也可以做一个很好的模型,然后闭源,甚至收费。开源与闭源,根本不是模型质量的原因,最多,是结果的部分:因为更好的模型往往投入更多,更好的模型用户也更愿意付费。
当然,对于很多初创公司而言,提供一个开源的方案,往往是产品的核心部分,同时提供围绕核心开发出的整套产品(例如更友好的界面,更低的使用门槛,更多的扩展功能,更好的服务支持,等),进行收费。这确实是过去十多年,非常流行的一种方式,如今,到了AI模型时代,一些企业也开始采用这种方式。虽然,客观上,开源起到了广告和引流的作用,但是更长期影响更深远的作用是:真正好的产品核心(代码模块,或者现在的模型)可以吸引更多的开发者一起来帮助改进,一起提高和丰富核心的能力,形成良性循环。开发者不会因为开源而使用,却会因为好的程序或者模型愿意在开源生态下反馈和改进,从而变得更好。
虽然,因为核心开发人员精力和维护成本问题,优秀开源项目不得不终止的例子屡见不鲜,但是伴随而来结果最多的也往往是更多有志之士甚至商业化公司愿意承接起项目的改进和维护工作。
也有不少的例子是,商业化公司看到了项目的潜力,在这个基础上发展出了闭源收费版本,同时,却也有别的开发者愿意扛过继续维护的大旗,继续着开源的事业。
如今的AI,是开源生态里长出的又一棵茁壮大树。最大量的优秀程序员并不在那些科技巨头里,科技巨头里也有大量的优秀程序员活跃在各大开源社区中。每个人都从开源世界里吸取养分并回馈。
或许,更合适的表述是:开源与闭源不是对立的矛盾体,闭源只不过是程序世界里一个子集而已,这个程序世界,却是开源的。
当开源模型超过GPT-3.5时,意味着及格了,也意味着各种落地加速了
一年前,我们还在惊艳ChatGPT,还在讨论什么时候别的模型能够超过GPT-3.5,甚至也在为GPT-4多模态的发布而隐隐感到一种对自身的威胁。
仅仅一年,能够被关注到的开源模型都已经显著超越了GPT-3.5的水平,甚至最新的Mixtral 8x22b都存在了在部分能力上接近或者略超GPT-4的潜力(为什么说是潜力,因为现在能够获得的只是预训练版本,很多能力需要通过精调释放)。
我们随手可得的模型,都已经超越了及格线的水平,在各领域的加速落地也成为非常确定的现在和未来时。
然后,我们会发现:场景是重要的,生态支持是重要的,推理成本是重要的。每一项都有很多解决方案,但是关于能力和推理成本之间的平衡,是任何高频使用者,首先需要面对的问题。
付出成本,解决问题,然后再付出成本,解决更多的问题。是活在C端,类似以前直播间“刷火箭”满足精神层面的需求,还是活在B端,直接解决工作生产的效率问题,这是一个问题。