Entering April, Databricks released DBRX, AI21 released Jamba, Google DeepMind released Gemma and RecurrentGemma, and Mistral once again quietly provided the download link for Mixtral 8x22b...
Add to that Meta's LLaMA-3, rumored to begin gradual release next week, and the open-source world is indeed bustling: GPT-3.5 has already been surpassed by open-source models. The only question is: who will be the first to exceed GPT-4 (though GPT-4 is no longer the absolute best, it still represents a very important watershed)?
On the other side, after Google's Cloud Next conference, a series of Gemini-based features were quickly integrated into Vertex AI, Workspace, and Google One, and the Chrome browser was updated. OpenAI updated GPT-4 Turbo, enhancing capabilities across multiple dimensions. Just a few hours ago, xAI released the preview version of Grok-1.5 Vision multimodal.
Everyone is still sprinting toward AGI. However, before models truly capable of complex "thinking and reasoning" emerge, what this generation lacks is not models, but elements for implementation: cost, ecosystem, and usage scenarios.
A premise: Models have become an important daily tool for many.
Although it seems that high-frequency users under current model capabilities number only around 100 to 200 million globally, models have become a vital daily tool for this group for search, knowledge processing, learning, research, and more.
Unlike the characteristic of mobile internet where marginal usage costs approach zero, the cost of using generative AI is not only non-negligible but is increasingly becoming one of the most critical factors in commercial deployment.
How to Lower High Inference Costs
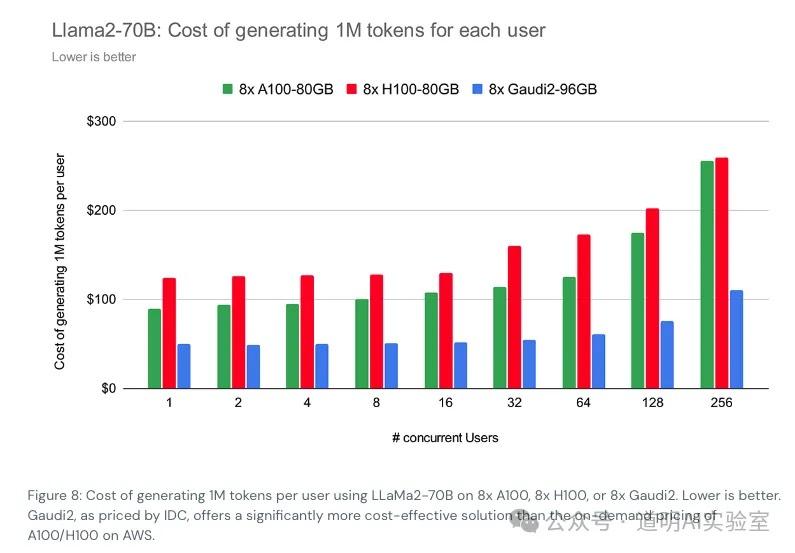
I am still inclined to cite the inference cost calculation for the LLaMA-2 70B model recently calculated by Databricks. Of course, there are several assumptions here: 1. The model is unoptimized; 2. Hardware costs are calculated based on public cloud service prices.
Under these assumptions, the cost is roughly $150 per million tokens generated, while the GPT-4 API cost is $30 per million tokens. This is a massive gap. Although we know OpenAI's cost for using Microsoft cloud services is significantly lower than public prices and GPT-4 inference deployment must have undergone extensive optimization, even with MoE pricing, the parameter scale loaded during GPT-4 inference is significantly higher than LLaMA-2 70B. On the other hand, the "laziness" and "deterioration" of GPT-4 complained about over the past few months are likely due to quality sacrifices made to reduce inference costs.
We know that through Mixture of Experts (MoE) structures, knowledge distillation (teacher-student models), parameter pruning, and quantization, inference performance (tokens output per second or minute) can be significantly improved and costs reduced.
OpenAI has undoubtedly put a lot of effort into reducing inference costs, but through various indirect calculations, we likely still reach this conclusion: the revenue OpenAI receives from users still does not cover the costs paid for inference.
Behind this, OpenAI has still paid the price of "users complaining about declining quality."
In the long run, if the transformer architecture does not change, the only "lossless" way to truly reduce inference costs seems to be: lowering hardware costs, including acquisition costs and usage costs primarily driven by energy consumption.
Undoubtedly, Google has a unique advantage in this regard, as Google's models run on self-developed TPUs for both training and inference.
This is likely the fundamental reason why giants like Microsoft, Meta, and Tesla are doubling down on self-developed chips. However, Google's TPU has already iterated to its fifth generation. Clearly, this path requires accumulation measured in units of five to ten years.
Is Open Source Just for Being Free?
Open source originally referred to opening up source code. Its true meaning is that by making code open for use, all developers (regardless of whether they have contributed) form a mutual aid model: 1. For many common basic functions or difficult problems, there's no need to start from scratch, greatly improving efficiency; 2. Because the source code is open, problems and bugs are easier to find and fix earlier. Although open code allows ill-intentioned people to look for vulnerabilities in widely used code to find "attack" vectors, the speed of fixing "security holes" also becomes very fast: the spear and the shield are always complex companions.
Today's AI open source is rarely "Open Source" in the full sense, as that would mean fully opening both training code and training data: a model is a specific result obtained from specific data through a specific training program on specific hardware. While some projects do achieve this full openness, what people generally consider "open source models" is the provision of at least the model weight files for public download (whether they can be used commercially without restriction or only for non-commercial research depends on the provider's commercial license agreement).
It can be said that the greatest contribution to current AI models, regardless of the provider, comes from the open-source community. Not only because the well-known transformer architecture is open, but also because many ideas and tools used in training models are open source, and most of the foundational data is open. Without the open-source community, there would be no generative AI as we know it today.
Therefore, claims that "closed source is better" have no basis: we can make a poor closed-source model, or we can make a very good model and then close it or even charge for it. Open vs. closed source is not a matter of model quality; at most, it's a matter of outcome: because better models often require more investment, and users are more willing to pay for better models.
Of course, for many startups, providing an open-source solution is often the core part of the product, while charging for a complete suite built around that core (such as more user-friendly interfaces, lower barriers to entry, more extended features, better support, etc.). This has been a very popular method over the past decade, and now, in the era of AI models, some companies are beginning to adopt it. Although open source objectively serves as advertising and lead generation, the longer-term and more profound impact is that a truly good product core (code module or model) can attract more developers to help improve it, together enhancing and enriching the core's capabilities in a virtuous cycle. Developers don't use it just because it's open source; they are willing to provide feedback and improvements within an open-source ecosystem because of a good program or model.
While there are many examples of excellent open-source projects ending due to the energy and maintenance costs of core developers, the most common outcome is that more enthusiasts or even commercial companies are willing to take over the improvement and maintenance work.
There are also many instances where commercial companies see a project's potential and develop a closed-source paid version on its basis, while other developers are willing to carry the torch of continued maintenance and the cause of open source.
AI today is another sturdy tree growing in the open-source ecosystem. The largest number of excellent programmers are not in those tech giants; many excellent programmers within tech giants are also active in various open-source communities. Everyone draws nutrients from the open-source world and gives back.
Perhaps a more appropriate expression is: open source and closed source are not opposing contradictions; closed source is just a subset of the programming world, but that programming world is open source.
When Open Source Models Surpass GPT-3.5, It Means a Passing Grade and Accelerated Implementation
A year ago, we were still amazed by ChatGPT, discussing when other models would surpass GPT-3.5, and even feeling a slight threat from the release of GPT-4 multimodal.
In just one year, the open-source models receiving attention have all significantly surpassed GPT-3.5 levels. Even the latest Mixtral 8x22b has the potential to approach or slightly exceed GPT-4 in certain capabilities (it's called "potential" because currently only the pre-trained version is available; many capabilities need to be released through fine-tuning).
The models we have at our fingertips have already exceeded the passing grade, and accelerated implementation in various fields has become a definite present and future.
Then, we will find that: scenarios are important, ecosystem support is important, and inference cost is important. There are many solutions for each, but the balance between capability and inference cost is the first problem any high-frequency user needs to face.
Pay the cost, solve the problem, then pay more cost to solve more problems. Whether to live on the C-end, similar to "sending rockets" in live streams to satisfy spiritual needs, or to live on the B-end, directly solving efficiency problems in work and production—that is the question.