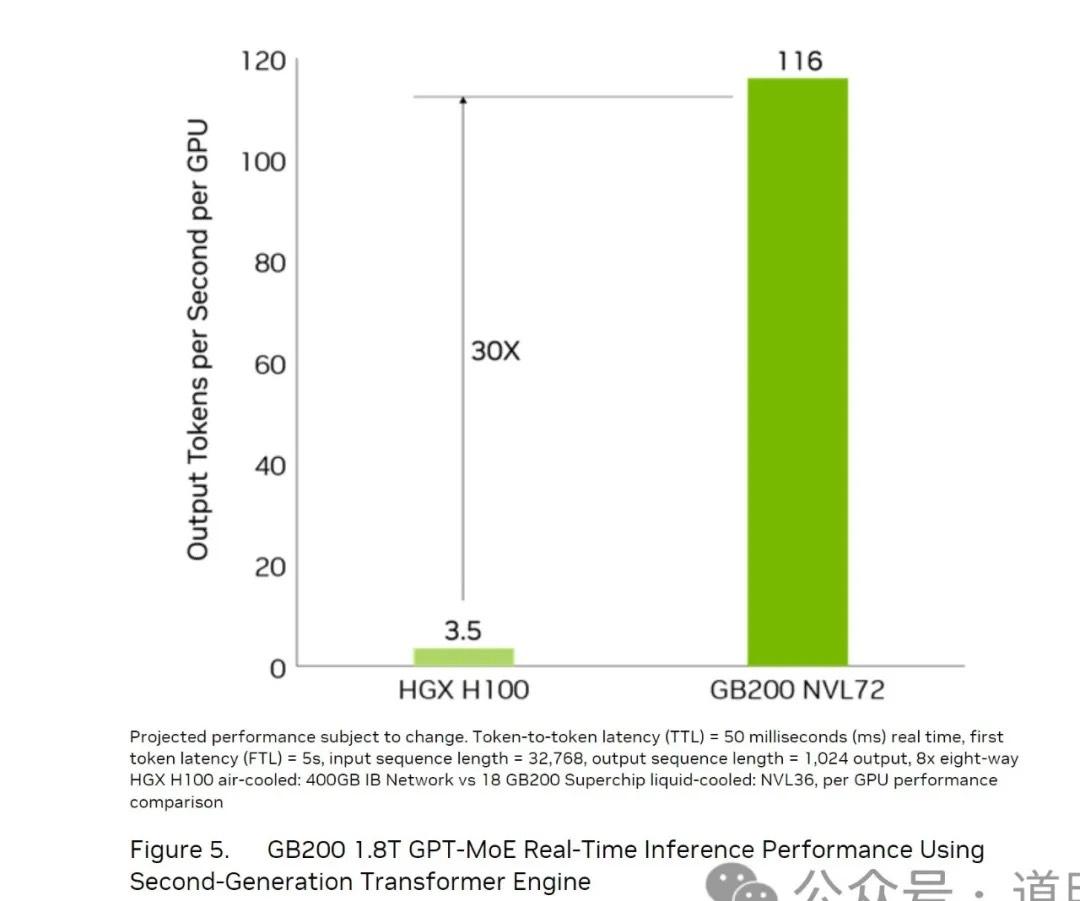
In the latest Blackwell architecture materials provided on NVIDIA's official website, there is a chart regarding inference performance improvements that clearly states a conclusion: by choosing the GB200 NVL72 solution, inference performance is 30x that of the H100 (per GPU).
Of course, such an improvement is based on certain assumptions: an input of 32,768 tokens and an output of 1,024 tokens; with each user request beginning to output the first token after 5 seconds.
While this is a highly idealized assumption—since in the set configuration (H100 connected via single-node eight-card setup, GB200 via the latest NVL72), this method is not friendly to the H100. Due to interconnect performance, the H100 can support significantly lower concurrency in such a setup compared to the GB200 NVL72. Therefore, a 5-second first-token latency has a much larger impact on the H100 system.
However, we can still see the value of the NVL72 interconnect method when applied to inference: when single-die capability is difficult to improve further, system-level capability clearly becomes more critical.
Below is a brief breakdown of how the 30x performance leap is achieved. Since the actual impact involves complex calculations, the simplest calculation methods are used below, ensuring the margin of error does not affect the conclusion.
1. FP8 vs. FP4: 2x
The Blackwell architecture begins to support FP4, whereas the Hopper architecture corresponding to the H100 is still at FP8. NVIDIA's calculations use FP4 for the GB200 system and FP8 for the H100 system. Simply put, this brings a 2x performance boost to inference.
Thus, if we ignore the impact of precision changes, the 30x becomes 15x.
2. Various Parallelisms: HBM Bandwidth and Copper Interconnect
In terms of single-GPU memory, the GB200 has upgraded to HBM3e. Each GPU corresponds to eight HBM stacks, with each stack at 24GB and 1TB/s bandwidth, bringing total memory bandwidth to 8TB/s (compared to 4.8TB/s in the previous generation). Given the "memory wall," we can assume that inference speed is primarily limited by memory bandwidth. Therefore, at the single-GPU level, the performance increase should be 67% (8/4.8 - 100%), or 1.67x.
Parallelism: NVLink has been upgraded to the fifth generation, doubling the bandwidth from 900GB/s to 1800GB/s. This is undoubtedly significant, but the biggest change brought by the NVL72 NVLink interconnect is memory pooling (a concept introduced with the GH200). When memory is pooled during parallel processing, the memory bandwidth is no longer the single 8TB/s mentioned above, but rather N*8TB/s (where N is the number of GPUs). Consequently, NVIDIA cites an HBM bandwidth of 576TB/s for the GB200 NVL72.
How does this work? Once pooled, a model used for inference can use Tensor Parallelism. Combined with MoE (Mixture of Experts) architecture, model weights can be distributed across multiple GPUs (e.g., 16) for parallel computation without waiting for each other during a single inference pass. Thus, the actual bandwidth would be 16 * 8TB/s = 128TB/s.
For the H100/200 architecture, NVIDIA did not emphasize this concept, but since the 8-card DGX is also internally connected via NVLink, it could theoretically reach a maximum of 8 * 4.8TB/s = 38.4TB/s. 128 / 38.4 = 3.33x. If we compare it back to NVIDIA's benchmark H100, where HBM bandwidth is 3.3TB/s, it is actually 128 / 3.3 / 8 = 4.8x.
However, when considering inference for large models like GPT-4, 8 cards are insufficient. Our assumption of 16 cards above was for ease of calculation. In configurations exceeding 8 cards, for H100/H200 DGX systems, the machines operate in a serial relationship: one must finish before the other starts, and the connection speed between them drops to the NVLink rate (900GB/s for the 4th generation).
With an NVL72 configuration, 72 cards can easily accommodate the inference requirements of GPT-4 or even next-generation models.
Of course, in a 16-card model setup, the 900GB/s bandwidth of the previous-gen NVLink only restricts one transmission wait. Based on various data, the overall impact on inference speed goes from the aforementioned 4.8x to approximately 8-10x.
NVIDIA realized this problem earlier and launched the GH200 system with 256-card pooling, but perhaps because the CPU was weak, delivery was late, or the interconnect speed was insufficient, there was a huge discount compared to the theoretical limit, and customers didn't buy in. The NVL72 solves many of these technical problems.
In summary, for a model of GPT-4's caliber, ignoring precision, the actual inference performance per GPU has likely improved by 8-10x compared to the previous generation, thanks to HBM bandwidth and especially the superior GPU pooling effect brought by copper interconnects.
How much will inference costs actually drop?
Objectively, there are many variables. For simplicity, let's discuss it based on the single-GPU performance boost: in a GB200 NVL72 configuration at the same precision, single-GPU inference capability is 8-10x that of the H100 system.
The market generally expects that while NVIDIA's costs for the GB200 system have at least doubled, the selling price compared to the H100 likely won't double. Assuming the total system cost is distributed per GPU, the acquisition cost might increase by 60-70%.
Power consumption per GPU for the GB200 rises from 700W (H100) to 1200W. From a system perspective, an eight-card H100 DGX consumes 6,500W, while the NVL72 system consumes 120KW. Thus, the average power per GPU for the DGX is about 812.5W, and for the NVL72, it is 1,667W. However, this doesn't account for networking power when the DGX uses IB networks, so the H100's actual power per unit is higher. If we assume 1,000W, the GB200 NVL72 power per GPU is roughly 1.67x, similar to the increase in acquisition cost.
Under the assumption that amortization and electricity prices remain constant, the cost per GPU under NVL72 is approximately 1.67x.
Therefore, at the same cost, the inference performance boost is roughly 4.8-6x (8-10x / 1.67x).
In other words: with the GB200 NVL72 configuration, inference costs can drop by at least 5 times. If precision is lowered to FP4, it could be 10 times.
Key Takeaways:
- With the GB200 NVL72 era, significantly lower inference costs mean GPT-4 inference could move from losing money to being profitable (also depending on how much OpenAI's token fees decrease).
- Clearly, if large models become more capable, using NVL72 to run large models will offer a greater economic advantage than using previous-gen architectures to run smaller models.
- On the model side, polarization will likely intensify: models must either be small enough but "good enough," or achieve superior quality at an even larger scale. The middle-of-the-road approach appears increasingly less competitive.