
The open-source LLaMA-3 is finally here: the first batch includes two versions, 8B and 70B, with more on the way, including a multimodal version reaching up to 400B.
The key is that it's open-source, and you can experience it right now via Meta AI.
Of course, let's go over other critical highlights (if you want to see a summary from Gemini 1.5 that's better than mine, please scroll to the end):
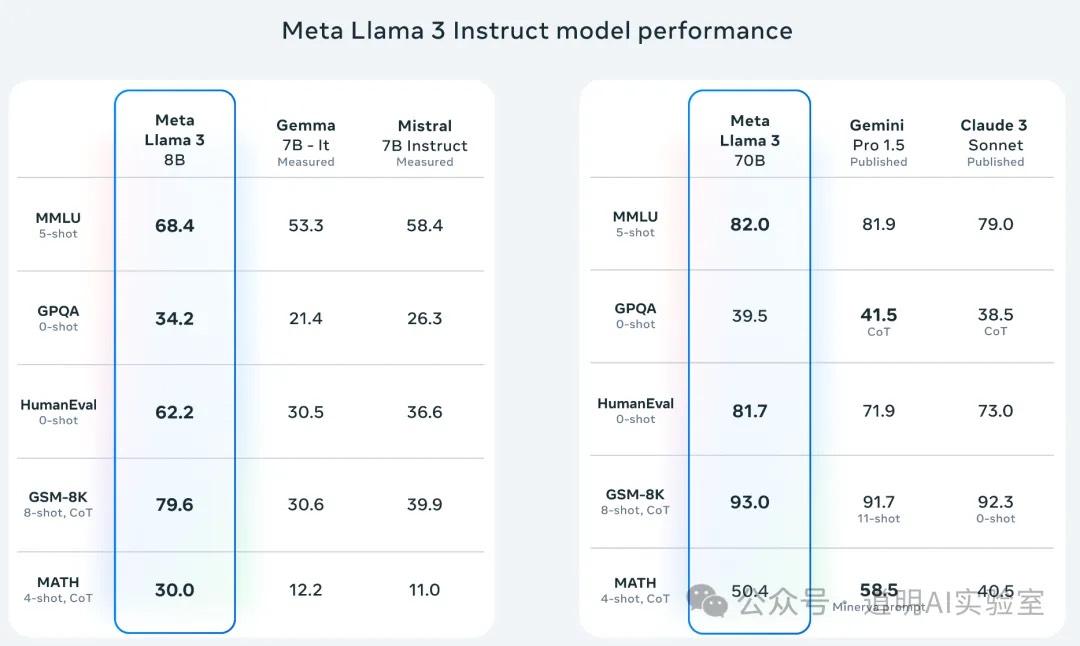
First, regarding model performance: the smallest 8B version significantly outperforms other open-source models of similar parameter scale. The released 70B version even has the "courage" to compete with Gemini 1.5. While current benchmarks have many issues, it's a safe inference that the 400B LLaMA-3 will match or even partially surpass GPT-4.
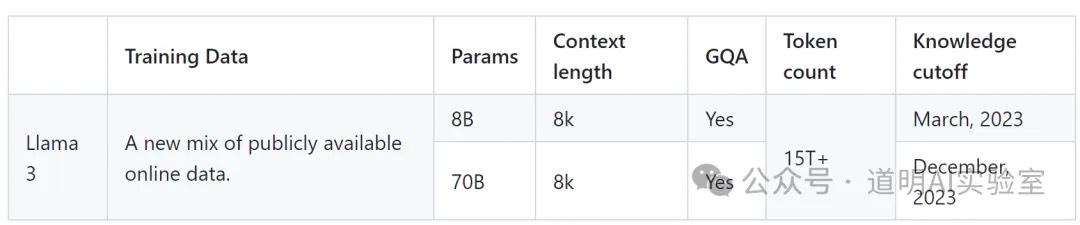
Second, the training data reached 15T. Due to time constraints, I haven't checked the exact training data volume for LLaMA-2, but I recall it being in the 2T-3T range, which implies at least a fivefold increase in data volume.
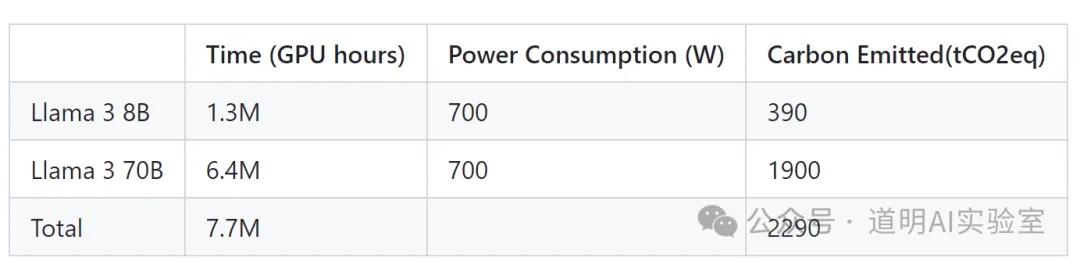
Third, the training time for the 70B model was 6.4 million GPU hours (using H100-80GB, 700W versions connected via NVLink). Assuming a 90-day training window, that translates to 2,963 cards. However, based on technical details from other models, typically one-third of a 90-day training cycle is for pre-training, while two-thirds go toward testing, fine-tuning, and alignment. Therefore, the 70B model likely utilized a cluster of approximately 8,000 to 10,000 H100s. Since the 400B model is still being optimized, Meta's intro disclosed that the largest model used 16,000 GPUs. An interesting detail: although the 70B is 8x larger than the 8B, it used less than 5x the GPU time. This is because larger clusters were used, but it also shows that within the range of a 20,000-card cluster, the larger the scale, the higher the efficiency.
Fourth, Scaling Laws still hold: both the 8B and 70B models saw significant performance gains as training data scaled from 200B to 15T, meaning this path remains viable.
Fifth, training involved 31 languages (non-English accounting for 5%). The vocabulary reached 128K tokens with a batch size of 8k. While long-context support can be added later through various techniques, this implies the model's native output capacity hasn't seen a massive jump compared to other mainstream models.
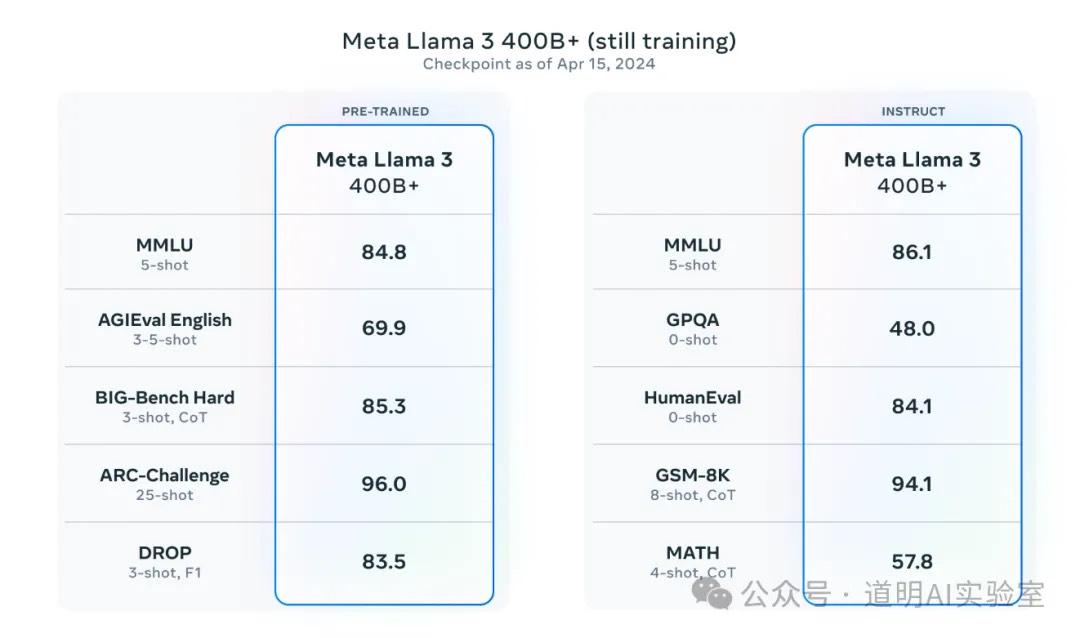
Sixth, the larger 400B multimodal model is still in progress, but the performance of the April 15th checkpoint is already astounding.
Conclusion
While Meta has the capability, expecting an open-source LLaMA-3 to completely surpass GPT-4 (or Claude 3, Gemini 1.5) remains an optimistic hope. However, by matching or approaching GPT-4 in an open-source format, Meta has fulfilled everyone's expectations for LLaMA-3.
As mentioned recently, the best closed-source models represent the ceiling of human capability, while the best open-source models represent a public benefit—a universal baseline. AI is about democratization, even if this democratization is terrifying for commercial entities.
LLaMA-3's importance for the next phase of AI development might even exceed the anticipated GPT-5. In the next 3 to 6 months, we will see various models "dominating leaderboards." Everyone will have access to better models, but they still won't become the "killer apps" people use daily because efficiency gains still face many hidden hurdles.
As repeatedly emphasized, the importance of the model itself in real-world AI deployment is decreasing. Ecosystems, scenarios, data, and workflows are becoming more critical. The requirement for a unified understanding of business logic and technical architecture is becoming higher.
Private deployment and use of models with hundreds of billions of parameters will increase. Deploying one requires at least 8 H100-level GPUs or ASICs; the demand for inference seems boundless.
Better large models mean better small models. 3B, 2B, or even 1B models that outperform the previous generation's 7B or 13B models will emerge, bringing more imaginative prospects to the acceleration of AI phones and hardware.
Finally, in one sentence: the trend is still getting stronger.
Gemini 1.5 Summary:
