Over the past period, my focus has been concentrated on the following aspects:
- What does the continuous improvement of open-source model capabilities mean?
The showtime for open-source models has begun, and the inference market is officially open.
Inference costs and open source.
- What kind of AI do we need?
What kind of AI do we need (I)? — Productivity Tools
What kind of AI do we need (II)? — Starting from the fading hype of GPTs
- If model capabilities are met, what will happen to the inference market?
Cohere releases enterprise-oriented models; inference cost becomes the key for the next stage.
How did the 30x improvement in GB200 inference performance come about?
Now, the open-source version of LLaMa-3 is here. In just over a day, various fine-tuned models based on LLaMa-3 have sprouted up: having an open-source model close to the GPT-4 level is something the entire community has long anticipated. Now that the moment has arrived, the level of excitement for developers is no less than when ChatGPT was first released.
Although, for experimental purposes, I am still laboriously running INT4 quantization programs on an Intel Meteor Lake, a MoE model based on LLaMa-3 is already available on Hugging Face: 4x8B.
It appears that the four expert domains focus on: Chat, Code, Assistant, and Thinking.
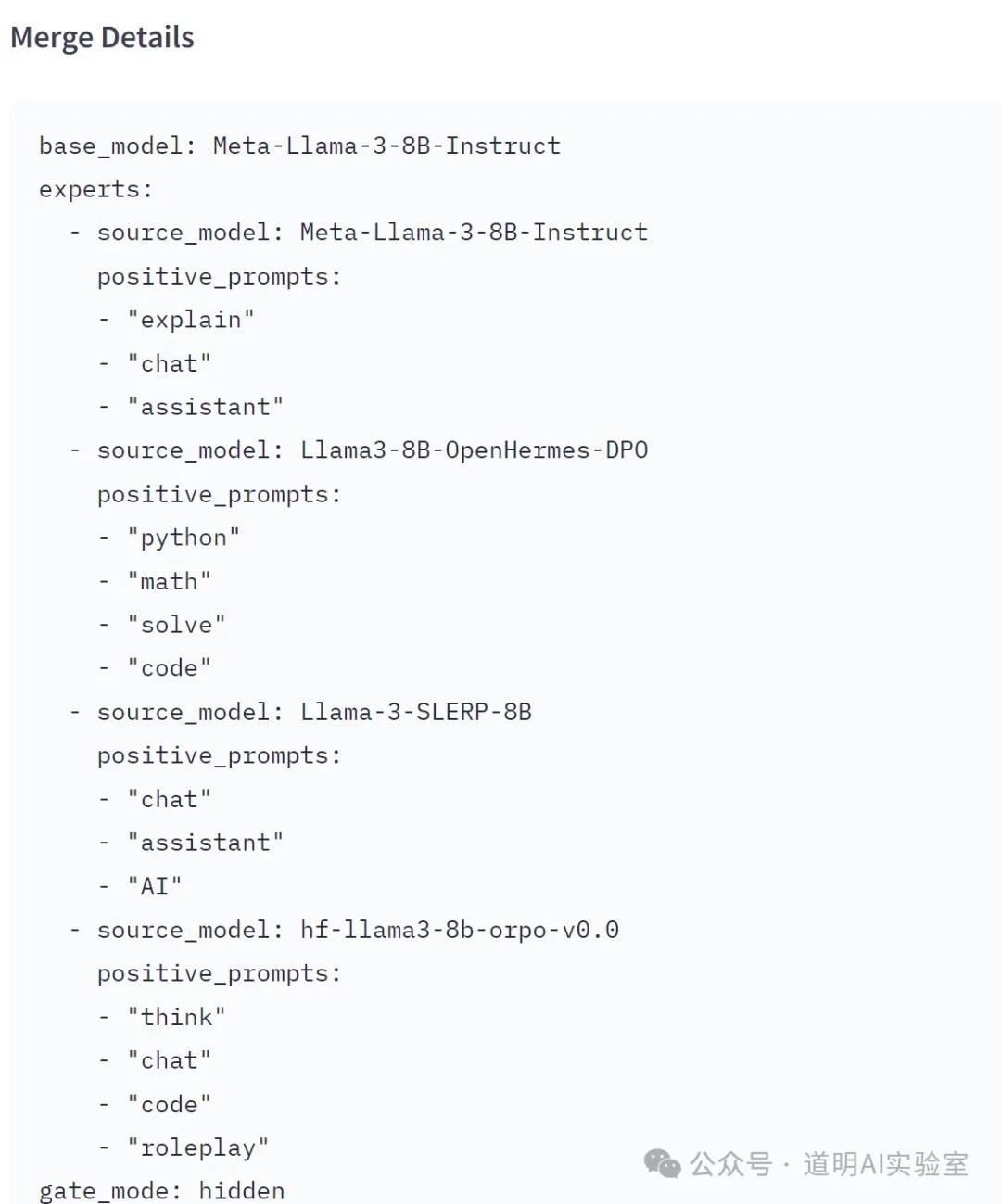
Of course, the performance of this specific model might not be great. After all, in such a short time, it only proves the technology is viable; true capability enhancement through fine-tuning or optimization still requires time.
However, we can clearly see that the technology stack applied based on existing model architectures is maturing: with the support of computing power that ensures inference performance, good base models can be plug-and-play.
This is increasingly becoming a consensus. That is why I listed the questions I've been considering recently and documented them as articles of my thought process. Below is the basic logic of my thinking:
As models progress—whether open-source or closed-source—more application scenarios will emerge. However, I have never believed that AI application development is a low-barrier job. Partly for this reason, we will see a massive amount of enterprise or personal private deployments. Inference cost is the first consideration for everyone.
As an individual, performing inference on a PC is cool. Building a personalized AI PC has practical scenarios and huge room for expansion; however, for team collaboration, the cloud is the only choice.
For teams and companies, provided the model meets requirements, token throughput is the most critical metric. This is because (Tokens Needed / Throughput) * Cloud Pricing equals cost—and that assumes 24/7 continuous token output.
I previously shared Databricks' discussion on token throughput and cost calculations for different hardware. The basic conclusion is that while there are many non-hardware methods to reduce inference costs, costs remain high on existing computing power.
If we choose not to use privately deployed open-source models and instead call commercial model APIs (whether open or closed), the token fees are also substantial. For example, GPT-4 charges $30 per million tokens.
If Nvidia relied on extreme interconnect technology to make training large-scale neural network models possible and accelerated the landing of models like GPT-3, then today's GB200 NVL72 is Nvidia once again using extreme interconnect technology to make a rapid drop in inference costs possible. My preliminary calculation suggests a decrease of at least 4.8 to 6 times. (Reference: How did the 30x improvement in GB200 inference performance come about?)
Not everyone has models large enough to require a GB200 NVL72 cluster for inference, but a rapid drop in the baseline cost will bring down all inference costs. As for how to implement it, cloud service providers will figure that out.
So, will there be a rush to buy? That's a matter of opinion.
If LLaMa-3 brings a significant jump in baseline model capabilities, then small-parameter models will also see a massive capability boost (whether by scaling with more data or through knowledge distillation using teacher-student models). Actually, the application imagination brought by mobile-side inference is even greater.
There will likely be a process: better models emerge as a result of greater computing power, followed by sufficiently good open-source models. Since open-source deployment is flexible, edge and device-side deployment become imaginative. If these are widely adopted, applications will explode. If applications explode, there will be a shortage of data. And by the way, "copyright is also very important."
Point number ten is for those who "know."