While the market continues to question the commercial monetization of this wave of generative AI, it is simultaneously impossible to deny that the pre-release of Llama-3 has ignited a new wave of model enthusiasm. Microsoft and Apple have released open models, with Apple's model being "truly open source." Furthermore, financial reports from Google and Microsoft have demonstrated AI's powerful driving force for cloud business, providing the determination to continue increasing infrastructure investment and confidence that AI can sustain revenue growth.
Almost overnight, sentiment has shifted from pessimism to optimism.
However, as consistently discussed in offline exchanges: the momentum remains. While the progress curve of models seems to be flattening slightly, the next generation of models represented by GPT-5 is on the way. Although the release timing remains uncertain, a leap in foundational model capabilities is expected (though this improvement in reasoning ability may not be as immediately visually striking to most people as models like Sora)……
What we are seeing more of is models being applied across various fields as productivity tools, beginning a penetration process from tech companies to non-tech companies. Whether it is the high growth of cloud business or the increased focus on inference costs and on-device model deployment, it all signifies that an explosion in implementation is imminent. Though, this is an explosion in model implementation, rather than an "AI application explosion."
Reviewing three recent aspects, it is not difficult to spot the upcoming trend changes:
1. Llama-3, Phi-3, OpenELM, and Qwen1.5-110B Kick Off the "Open" Model Wave
To avoid conceptual confusion, from now on, I will categorize what are commonly referred to as "open-source models" into three types:
- Open Models: Refers to models where only the weights are open for download with near-total free commercial use licenses. Developers can download the model, deploy it locally, and run it offline, but details of the training and data are not public. Examples include Meta's newly released Llama-3 and Microsoft's Phi-3 released shortly after.
- Open Training Code, Closed Data: Previously, Llama models fully opened training code and even provided some public data. Looking at model evolution trends recently, model architectures have gradually stabilized. Increasingly, generative data is being used to enhance model capabilities. In the future, opening code but keeping data proprietary is expected to become the mainstream approach.
- Fully Open Source: This means opening not just the training code, but also the data used and the model weights. The latest representative is Apple's OpenELM model, alongside the previous OLMo.
Indeed, the third category (fully open source) aligns best with the complete definition of software open source. However, training large models today—even small-scale ones—requires computing power beyond the reach of individuals or even small-to-medium startups. The significance of opening code and data is no longer about lowering the barrier to entry, but more about research and preparation for future risks.
For many applications, even type 1 (open weights) is highly practical as long as the commercial license is favorable. As mentioned, more models are choosing to open training code and a portion of data (type 2). Since high-quality data and synthetic data are becoming the most critical factors in model quality, open-sourcing training code provides developers with more confidence and positive feedback, helping models improve faster.
Llama-3, released last week, not only sparked a surge in the community as shown below but also drove a wave of open model releases.
Models attracting significant attention include Microsoft's Phi-3, Apple's fully open-source OpenELM, and Alibaba's Qwen1.5-110B.
As the title of my April 1st article stated: It is showtime for open-source models.
Showtime for open-source models begins, and the inference market officially opens.
Due to space constraints, I will skip the pros and cons analysis of each model and directly provide new insights derived from their characteristics:
- The Scaling Law remains effective, but it presents curve characteristics different from the 2020 OpenAI paper. The chart below shows the measured relationship between model parameters, data, and model loss rates from OpenAI's 2020 paper, "Scaling Laws for Neural Language Models." This curve led researchers to two points of consensus: both parameter scale and data increases improve model performance, and parameter scale and data volume should match.
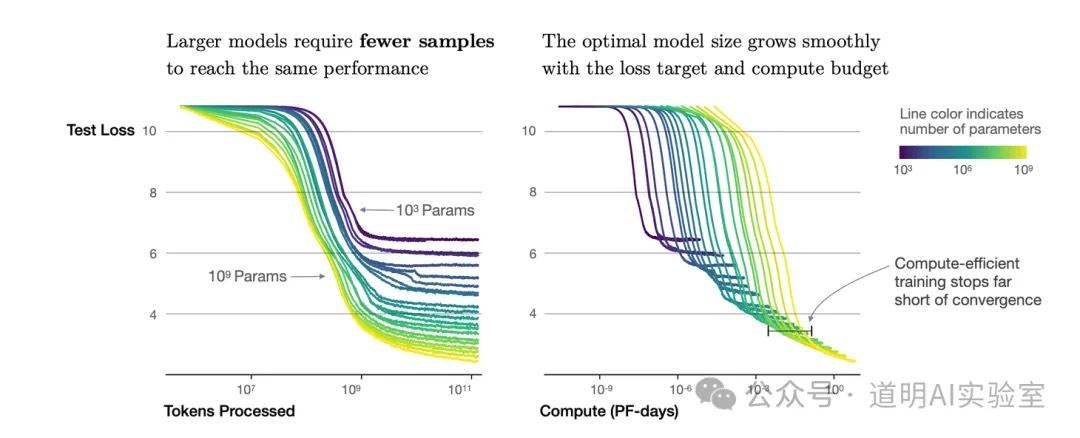
However, both Llama-3 and Phi-3 have reached new conclusions: with a fixed parameter scale, significantly increasing the data volume alone allows small-parameter models to outperform larger ones. Llama-3's training data increased from 2T in the previous generation to 15T, and Phi-3's training data reached 3.3T. Performance in these new versions improved drastically. While the curve shape (where the loss rate reduction speed converges from geometric to logarithmic as data volume increases) hasn't changed, the curve has clearly expanded on the x-axis: the later arrival of second and first-order derivative inflection points means the same model can accommodate much more training data.
The role of synthetic data is growing. Not long ago, everyone worried about "internet data depletion." Now, Phi-3 highlights that synthetic data played a vital role in its training. The Llama-3 team's conclusion is interesting: using data generated by Llama-2, they trained data quality classifiers to strictly screen training data. Does this mean the data barrier has lowered? On the contrary, it has risen significantly, as knowing how to generate enough high-quality synthetic data will become the most important know-how.
Training more data with smaller parameter models further raises the computing power barrier for training, but significantly lowers the barrier and cost for inference deployment. Discussing large vs. small models can be controversial, but Llama-3 data shows the 8B version used 1.3 million H100 GPU hours, while the 70B version of the previous Llama-2 generation only used 1.7 million A100 GPU hours. Those who understand the difference will understand the implications.
Indeed, we are about to see: 1. A flood of derivative versions of various models; 2. Edge deployment becoming extremely easy with standard performance; 3. Local model execution on phones becoming a reality and being rapidly optimized. If one scenario needs to be identified for a large-scale acceleration of AI application implementation, it is the mobile phone.
2. Model Training is Knowledge Compression, Inference is Decompression; Models for Everyone is Becoming Reality
Although the phrase "large models are the compression of knowledge" is frequently cited, in many discussions, I find the percentage of people who truly understand or agree with the meaning of "compression" is low.
We often focus on visual shocks like "GPT can write articles" or "Sora can generate movies," overlooking the original goal of generative AI: a knowledge container. When traditional symbolic AI methods could no longer exhaustively define "knowledge rules" through clever methods, using deep neural networks as containers to compress surface-level corpus into them and letting models "emerge" with self-acquired knowledge became a more feasible choice.
Indeed, from any training process, it is easy to conclude that large models are essentially about probability; I once thought so too. However, a vast amount of research over the past year has confirmed an inference: models extract a massive amount of "knowledge" and possess basic reasoning capabilities.
This reinforces the belief: a model's ability to generate implies that it understands.
Last November, after watching the OpenAI DevDay livestream, I excitedly wrote: "What if everyone owned a large model?" The rapid reduction in deployment barriers might make this dream a reality very soon.
Looking at this dream now, I have gained deeper insights:
- If a model is a container of compressed knowledge, everyone owning a model means everyone has a "knowledge plug-in."
- Yes, generative models can answer our questions, enhance search, act as a copilot for organizing knowledge, writing documents, programming, or creating games/movies, and act as agents to complete tasks.
- However, a personal generative model might also mean the ability to create various environments or "worlds" according to our imagination. The decompression process is actually a process of creating one "world" after another.
- In these worlds, we can expand our imagination infinitely and also train true intelligence.
- This process is the path many model developers envision toward achieving Artificial General Intelligence (AGI).
- If current generation capabilities significantly boost our efficiency, then intelligence honed through trial and error in enough model-created "worlds"—even if it doesn't reach AGI immediately—can once again ascend a dimension and shock humanity in a new way.
- This hypercycle will likely experience two consecutive dimensional upgrades: the "creation from nothing" of generative AI, and the "emergence" of intelligence within generative worlds.
- This is likely why Sam Altman mentioned in a recent speech that many current research endeavors and startups focused on fixing current AI shortcomings will become obsolete when more intelligent models arrive (Many current ventures and research endeavors are predicated on rectifying AI’s shortcomings. However, with the advent of advanced models like GPT-5 and GPT-6, such efforts may become obsolete).
I believe Transformers help us compress information better and the Scaling Law gives models a concept of "knowledge." Currently, this work is well-accomplished. Whether through better "decompression" effects or lower access barriers, this work will continue to progress. Generative AI is a vital cornerstone on the road to AGI, and a new turning point is approaching: intelligence growing atop the generative cornerstone.
Generative worlds, AGI, computing for all things, the metaverse, and endless growth in compute demand—these concepts, often seen as "hype," are logically unified in this dimension. A dimension far larger than any previous era, even if assessing the total scale of the mobile internet (the current era) remains difficult.
3. The Prerequisite for Large-Scale Generation is Cheaper Computing; Cloud and Edge are the Most Feasible Directions
Compression consumes compute, decompression consumes even more, and the generation process is a process of compute consumption.
Computing cost is both a production cost and a resource drain. Perhaps at some point, we will find more efficient ways to compute. However, while human biological computation consumes very little energy, the resource cost the Earth pays to sustain human existence is astronomical. In contrast, even by optimistic estimates, generative computing's consumption will hardly exceed 5% over the next five years.
However, we are always more concerned with visible costs. The cost of model decompression (inference) is the most critical subject alongside model capability, occupying half of my discussions over the past month:
- Open-source Llama-3, Nvidia GB200, and Inference
- How the 30x boost in GB200 inference performance was achieved
- Inference costs and Open Source
- Cohere releases enterprise-focused models; inference cost becomes the key for the next stage
Technical discussions aside, from an economic perspective, there is only one effective way to lower the cost of a commodity for a massive population: sharing.
If we need large-scale hardware (like the newly released Nvidia GB200 NVL or future hardware) to significantly reduce the overall cost of use, thereby lowering the cost for each individual, the Cloud is the best method.
Growth in cloud business observed in Microsoft and Google’s reports can be partially attributed to their superior models, but mostly because it is the lowest-cost way for enterprises or individuals to use models.
Naturally, the other extreme direction is also viable and trending: deploying models on the cheapest hardware possible, such as mobile phones. This requires better compression (higher capability with smaller parameter scales) and better hardware-model synergy. As discussed in the first section, this is already happening.