Updates have been fewer lately, partly due to work reasons and partly because, as we enter the second half of 2024, the time seems ripe to integrate various models into our workflows and re-optimize processes and tools. A lot of time has been spent on "brainstorming" and experimentation (I've tried dozens of tools and solutions; I can share them one by one when I have time).
During this process, three things have become relatively clear: 1. Models will continue to grow more powerful—we just need to wait; 2. One's own understanding of the business and data (knowledge bases) are the most valuable resources; 3. The tools we need might all start from a "whiteboard."
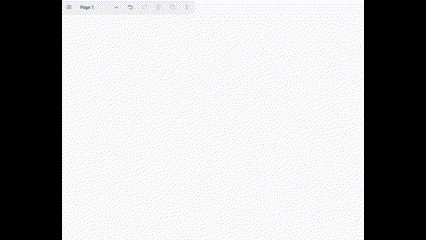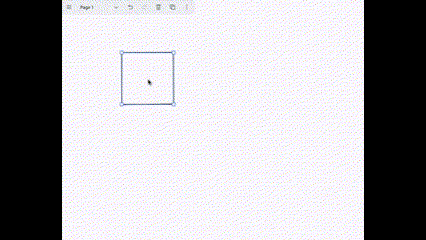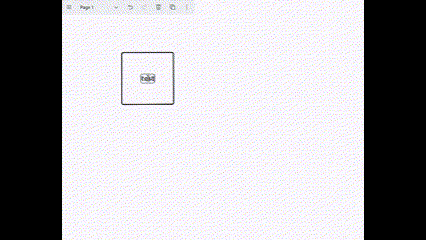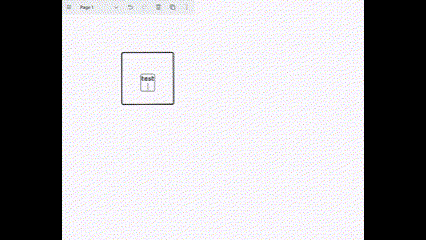
So, as I entered a cycle of "desk work," I began trying to build with blocks starting from a whiteboard. A recent weekend project was: giving screen control to the model, instructing it to "draw a box named 'test' on the whiteboard," letting the model operate the mouse to complete it on a whiteboard tool called tldraw.
The actual result is shown in the short GIF below.
Yes, a human can perform such a simple operation. However, if we consider the working methods of the next era—breaking through the current bottleneck where "time is consumed by low-level repetitive work"—this kind of start is a way I've finally "convinced" myself of after over a year of thinking and deduction.
A whiteboard means building everything from scratch. But behind this "zero" is a large model with unimaginable knowledge, combined with the data and knowledge bases accumulated over many years.
Therefore, once construction begins, it's possible to reach or even break through previous ceilings in a very short time—a "short" time measured in days or even hours.
Based on models, there are roughly two ways to build: one is simulating human operations; the other is generating a large amount of code.
The former is similar to my small experiment above. Coincidentally, the second method saw a much more complete solution than any previous code generation scheme in the Sonnet 3.5 model released by Claude the day before yesterday, called "Artifacts."
If the "Copilot" Microsoft has been promoting still involves many "unfriendly" interaction methods, then both simulated human operations and Claude's Artifacts feature provide a completely friendly, natural, "What You See Is What You Get" (WYSIWYG) experience.
We will definitely love it, just as many people loved ChatGPT initially.
For me, it's as if Claude has hired a "super assistant" for me.
What I want to do in this article is demonstrate how to use about ten minutes to complete a conceptual roadshow PPT for "Crude Oil Supply and Demand Analysis" (Apologies, I just unsubscribed from Microsoft's Copilot+ service because it was outclassed).
As soon as Sonnet 3.5 came out the day before yesterday, it went viral. Almost all voices were saying it "kills GPT-4o," and some even shouted "AGI." Indeed, with sufficiently strong reasoning, stable and accurate code generation, and the WYSIWYG Artifacts, these comments are not exaggerated.
Let's begin. I will divide my interaction process into four steps, recorded in four videos totaling nine minutes with no acceleration. This means it took less than ten minutes from start to final result.
- Standard operation: generating a mind map.
Actually, Kimi was already able to support this WYSIWYG mind map function based on mermaid.js, but: 1. Due to the gap in model capability, the points of analysis are significantly fewer; 2. Under the technical framework, the versatility of rendering functions still lags.
The above is just a standard operation because, as analyzed, almost all mainstream models can support generating a mind map from scratch; Kimi can display the diagram in real-time (so, saying Claude's Artifacts "copied" Kimi might make some sense).
- However, we want it to include data, because an analysis is based on data.
The first time, the generated code had omissions, causing the page to display incorrectly. But after checking and regenerating, it was correct. This interaction actually makes the model feel more "human."
Of course, because it didn't search for the latest data, much of the data is "incorrect" at this point in time.
So, I made a new request: change a specific data point, such as U.S. crude oil production data.
It understood and did it. This understanding and the stability of code generation come from the model's native capabilities. Perhaps the era really did change in the summer of 2024, as previously expected.
- With the mind map, I want it to generate a PPT and draw corresponding charts.
The first generation looked more like a document. Although it drew charts, I wanted a multi-page PPT. So, I asked it to modify it, and it followed through faithfully. The fonts, chart styles, and data remained unchanged, once again demonstrating sufficiently stable coding capabilities.
- But this isn't quite enough. The color scheme doesn't look professional, the fonts aren't standard, and I want to add some conclusions.
Again, it faithfully understood the intent, adjusted the colors, and changed the fonts. It also added conclusions. During the first generation, the returned token count was limited, so the page didn't display correctly. The second time, I asked it to be more concise, and it went smoothly.
Ultimately, I obtained the following PPT pages.
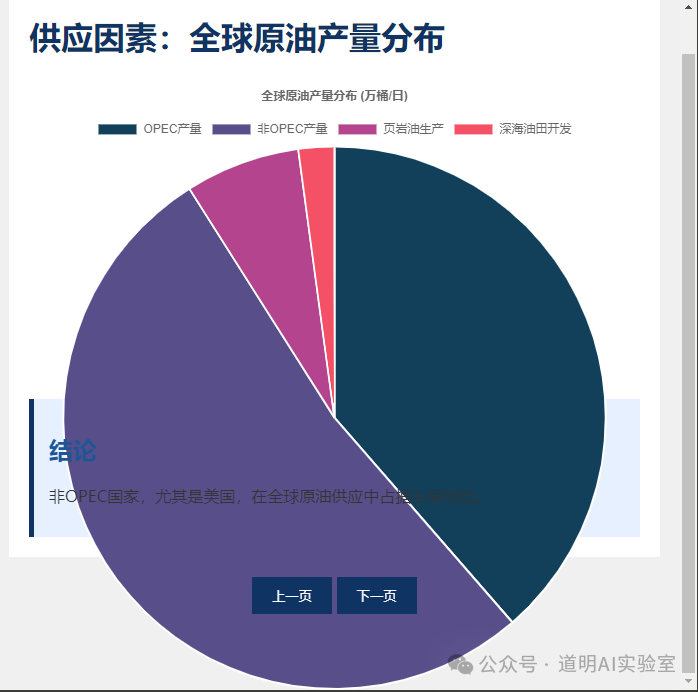
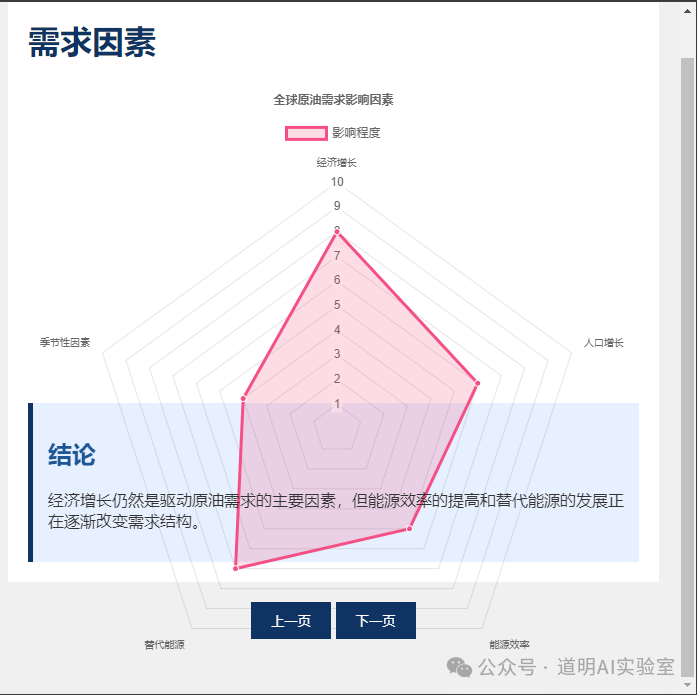

My conclusions:
Although self-media is flooded with various fancy ways to play with Sonnet 3.5's Artifacts—mostly generating small games—I certainly don't think we need to generate games for ourselves. However, I believe generating content directly related to productivity is a solid demand (I also tried generating some explanatory animation effects, but won't include them due to time and space constraints);
While the phrase "hiring a super assistant" is a bit of an exaggeration, as long as you are willing to spend time refining the process, the results will certainly far exceed what's possible now;
We see that models will rapidly get better, at a speed far exceeding our personal rate of progress. Where is personal value? I think it might lie in deep thinking and the accumulation of knowledge bases;
Can it replace my team colleagues? Obviously not, but that's only because we've already greatly expanded everyone's boundaries and output capabilities through various models and technical support over the past three or four years. Understanding tools and outputting based on knowledge bases is not something current models can challenge—but what about in two, three, or five years?
What else do we need: new workflows based on tools and models; solutions for private deployment; and seamless integration of data and knowledge bases.
I believe the problems we face today are the same problems faced by the implementation of various generative AI ends.
So, this isn't just a simple introduction and promotional article for the Sonnet 3.5 model and Artifacts, is it?