
Tencent's AI Lab recently released a new paper. I was planning to comment on it yesterday, but I initially put it aside because the topic seemed a bit "sensitive" at first glance. After re-reading the paper this morning, I realized there's much to discuss, so I decided to update with this piece and postpone the previously planned topic.
A quick preview: the next topic will be about "wearable AI."
First, the paper is titled Scaling Synthetic Data Creation with 1,000,000,000 Personas. It essentially discusses how to utilize 1 billion "personas" to produce synthetic data at a massive scale.
Part of the data is open-sourced, and the project address is:
https://github.com/tencent-ailab/persona-hub
Looking at the title, you can likely guess the "sensitive" point I mentioned: these 1 billion personas are actually abstracted from real "web data." From a purely technical and research perspective, this is a fantastic idea and exactly what big tech companies should be doing. However, from a data security perspective, the original data sources are somewhat vague, and the processing details are lacking.
Even the project team repeatedly mentioned various ethical risks; therefore, in their open-source project and synthetic datasets, they only included 200,000 personas.
Getting back to the point, I believe a company like Tencent, which has dealt with "sensitive" information for over twenty years, wouldn't make a rookie mistake. So, the following analysis focuses purely on technology and application prospects.
- What is this project?
Above is a schematic from the paper. To summarize in one sentence: through "role-playing," large models generate data for training and fine-tuning across various fields, including mathematical problems, reasoning tasks, fine-tuning instructions, knowledge, game NPCs, and function calls (tools), etc.
- What exactly is a Persona?
A persona is a form of role-play, but these roles are extracted from real "web data" to represent the characteristics of certain types of people. In this project, they manifest as descriptions like "who someone is and what their job is." Simply put, they are prompts. If you are somewhat familiar with LLM prompting, you know we often ask models: "Assume you are [X], please help me with [Y]." This "Persona" is the embodiment of those prompts.
- Why use "Persona" prompts?
The paper includes a diagram, but in the era of Claude 3.5, 2D images feel too ordinary. So, I asked the model to generate a demonstration animation for me.

To explain:
We often say LLMs are "compressors." What are they compressing? Knowledge! (As I wrote before the OpenAI livestream demo). This means the model training process involves compressing vast amounts of knowledge into the parameters of a neural network.
The generation process of an LLM is "decompression," restoring those parameter weights (which only the model understands) back into "knowledge" that humans can understand (hence the saying "generation implies understanding").
However, models are incredibly massive. How do we make them "decompress" effectively and accurately? This relies on prompts and the attention mechanism.
By using Persona prompts, we activate information in the model that has a higher correlation with specific knowledge areas, thereby "decompressing" more "accurate" knowledge. This is the goal of this paper.
- How is the performance?

The above is a summary by Claude 3.5; it is very accurate, and the data is correct. The conclusion is that after fine-tuning a Qwen2-7B model with synthetic math problems, its math score reached 64.9%, exceeding early versions of GPT-4 Turbo.
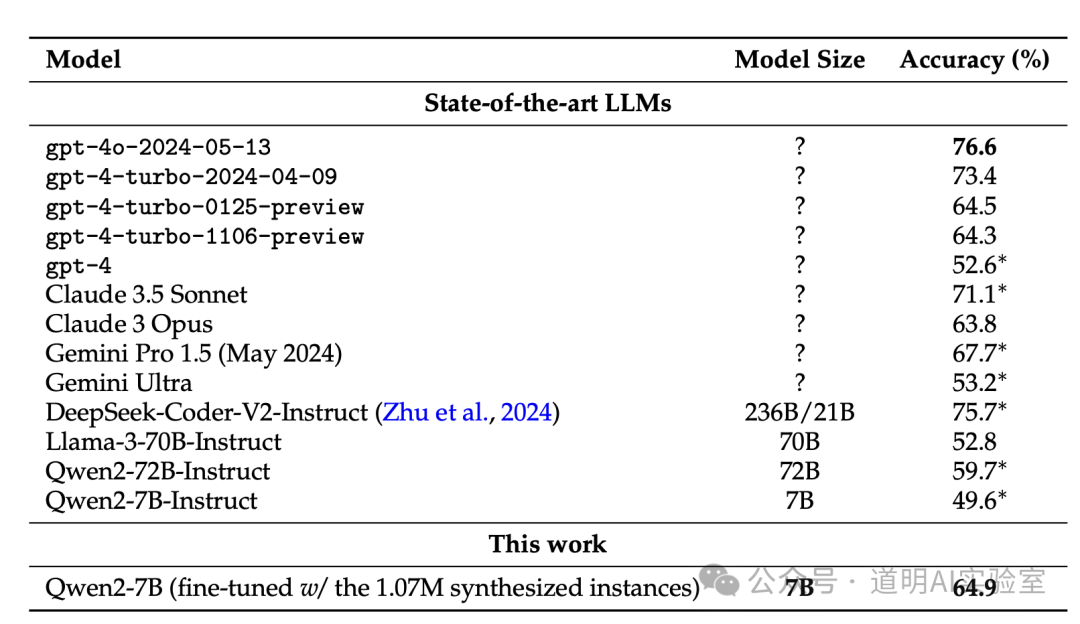
- Conclusion: Where is it used?
The evaluation above provides a great example: model fine-tuning. Of course, with such a massive volume of data, the potential application scenarios are much broader.
Final thoughts: One trend is now very certain—as models reach today's levels, "synthetic data" plays an increasingly vital role. I would even argue that the quality of "synthetic data" exceeds that of most real-world data, as demonstrated in this paper. We can systematically generate specific synthetic data at scale to strengthen model capabilities. Some call this "emergence," others are skeptical, but no one can deny that models are becoming increasingly useful for everyone.
However, for models to achieve the "emergence" that some believe in, a massive amount of data is required. Even when using synthetic data, the computational resources consumed are staggering. Looking at the magnitude of "1 billion" in this paper, it is already mind-blowing. This is a game for big corporations.
Recently, people often ask me: how much compute is needed for training? How much for inference? But is compute only for training and inference? Furthermore, in the foreseeable years, as long as we need to pile up more data, we will still lack the compute for the largest clusters. In that case, is the meaning of "counting the numbers" really that significant?