Yesterday, as rumored, OpenAI released its latest "GPT-4o mini" model—smaller, faster, and cheaper, though it did not "open source its weights" as many had hoped.
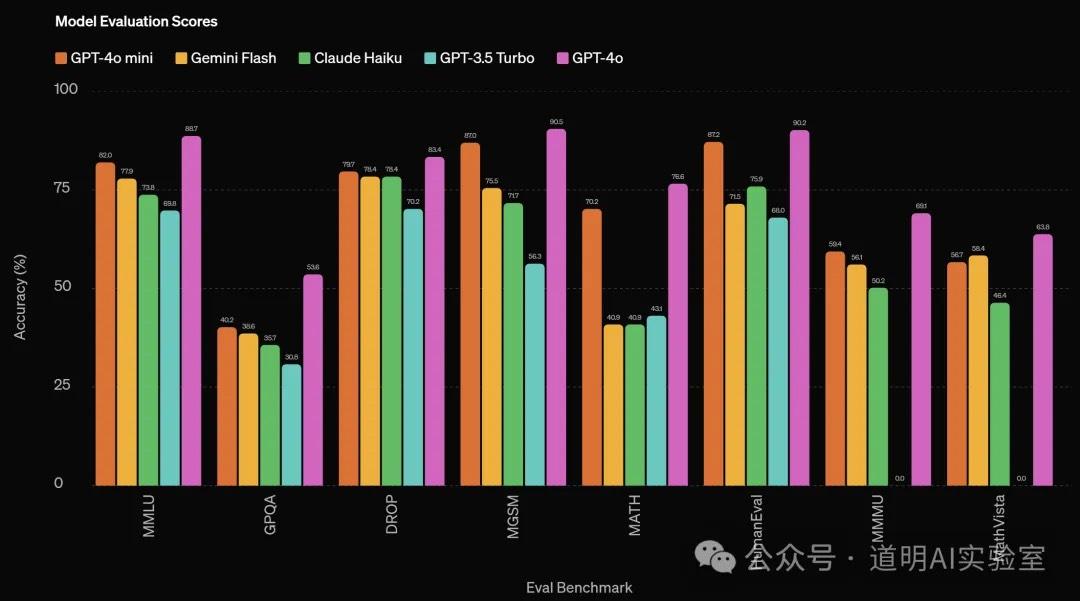
Of course, the model has plenty of highlights. First is its performance: conservatively speaking, its performance significantly exceeds that of models with a similar parameter scale, though these are OpenAI's own benchmark results.
Secondly, the model's inference speed is noticeably faster, and API costs have dropped drastically: down from $15 per million tokens for GPT-4o to just $0.6 per million tokens, making it one-twenty-fifth of the original price.


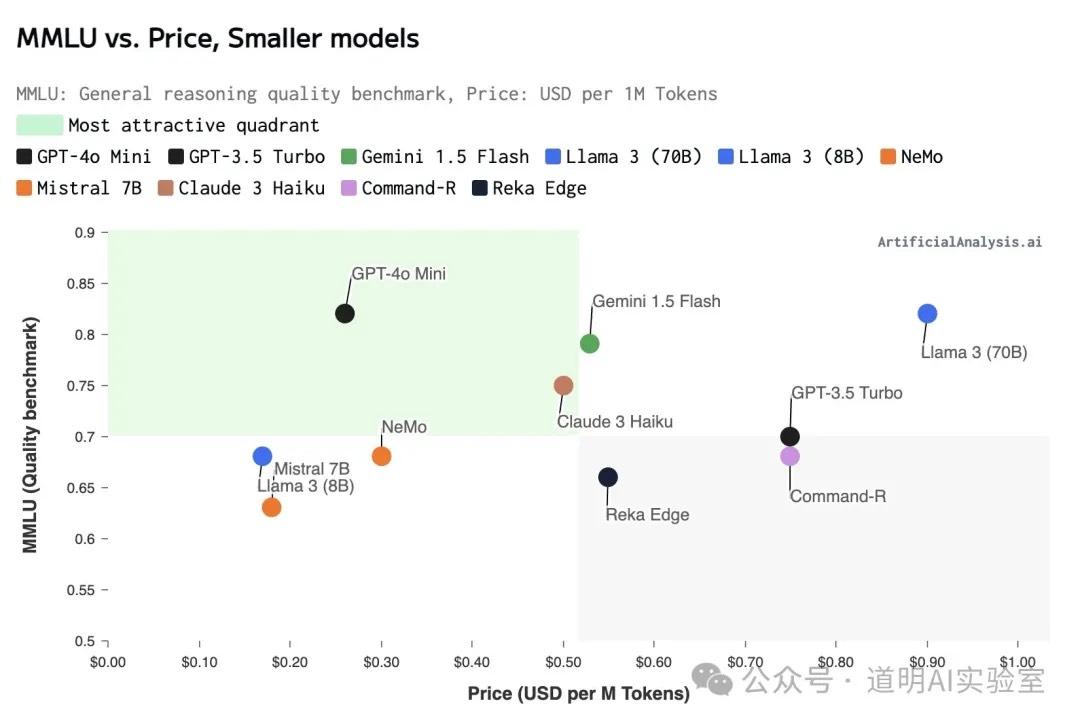
Significant cost reduction is the primary driver behind OpenAI's release of this new model. On average, it remains cheaper even when compared to similarly positioned models from Google and Anthropic (Gemini Flash, Claude Haiku).
However, questions follow. First, on a technical level: how was the GPT-4o mini model created?
While OpenAI hasn't disclosed any details, it is essentially certain that it was derived through knowledge distillation (also known as the teacher-student model) from GPT-4o. Simply put, questions and answers from GPT-4o were used to train a model significantly smaller than itself (the student), allowing the smaller model to achieve roughly 80-90% of the original model's (the teacher's) knowledge coverage. It's like a teacher giving a student a set of specific exam prep questions before a test. If the test questions fall within that set, the student might score 80 or 90 points; if they encounter questions outside that set, the results could be disastrous.
The benefit of this approach is that it drastically reduces model size. Initial estimates suggest that GPT-4o mini's parameter scale likely does not exceed 30B. Several models can be loaded onto a single GPU, and at this scale, older GPUs like the A100 can still be utilized. Even with H100s, the requirements for interconnect speeds between cards and machines are significantly lowered. All of this substantially reduces actual inference costs. For API users, getting 80-90% of the performance at 1/25th of the price is "theoretically" attractive (more on that in a moment).
This might be a "clever move" by OpenAI in its current state to attract customers and generate revenue. However, the problem is that behind this "clever move," it may actually signal that OpenAI is losing its "halo."
Releasing multiple sizes of the same generation of models for different target segments is the strategy Google started with Gemini, which Anthropic's Claude 3 then followed. Google's approach is easily interpreted by the market as catering to a powerful edge application ecosystem; Anthropic is playing the role of a market challenger, so copying the leader is fine. However, OpenAI cannot afford this. The market expects OpenAI models to be undisputed leaders. The fact that the next-generation model (let's call it GPT-5) was not released in the first half of this year has already fallen far short of market expectations. The stunning voice and vision interaction features demonstrated during the GPT-4o launch are still nowhere to be found in the official rollout. Suddenly releasing a strange "mini" model makes it look like OpenAI is being led by its nose, only bringing more skepticism. Countless examples prove that in competition, losing the top spot can lead to losing the second and third spots, resulting in a bottomless decline.
OpenAI may believe users want cheaper API pricing. Yes, users certainly do—the cheaper, the better—but this is relative to the best models. No matter how good a "student" is, they are still a student. At the "mini" level, there are numerous options in the market. The Llama 3 family can be deployed locally, fine-tuned securely with private data, and has many variants optimized for specific fields (like coding or math). More flexible usage and lower operation/maintenance costs will shift the balance toward open-source options for users when they aren't using the absolute best model.
Even if benchmark results suggest GPT-4o mini still significantly outperforms mainstream open-source models, the market almost unanimously expects Meta to officially release the Llama 3-405B multimodal model next week (July 23rd). In Meta's scores released during the Llama 3 launch, that model outperformed GPT-4. While it remains uncertain whether Meta will open-source (open weights) that specific model, at the very least, releasing a slightly smaller parameter model is the baseline expectation. This means GPT-4o mini will likely lose its slight edge over open-source next week.
Therefore, the crux of the problem remains: when will the next-generation GPT be released? Previously, I expected it before the end of June. Although I still believe there is a high probability it will arrive in Q3 (because Claude 3.5 Sonnet has actually surpassed GPT-4o in many aspects, and Anthropic has clearly stated it will release Claude 3.5 Opus—the largest and best one—in Q3; meanwhile, Gemini 1.5 Ultra is approaching, and it's not improbable for Google to suddenly drop a next-gen model), I admit that time is running out for OpenAI.
However, the slowing progress of OpenAI does not represent the end of this hyper-cycle. From the moment models could generate "accurate" code and "understand" the human world and language, an era of rapid transformation beyond anyone's imagination had already begun. Although OpenAI is losing its "halo" at the technical level, its management team's business intuition and product taste remain top-tier. GPT-4o mini will still serve as a signal confirming an important trend: lower cloud inference costs and broader edge-side inference scenarios will lead to faster, cheaper code and information generation. The chain reaction of this transformation may still shock us when we look back at the end of the year.