终于有时间了,按照计划,开始测试exolabs的集群推理方案。为什么我更看好算力异构。
项目地址:https://github.com/exo-explore/exo
本来我计划是要测试llama-3.1-405b的,但是目前社区里的支持MLX的405b权重文件还无法下载,所以,我还在下载本地模型进行权重文件转换的过程中,估计至少还需要一天时间(今天把网络带宽都留给了其他模型的下载)。
所以,在这一次测试中,我使用了三台Mac Studio(M2 Ultra,192GB内存),分别跑llama-3.1-8B,llama-3.1-70B和Mistral-Large模型。其实,这些模型的int4量化版本在单机上都可以运行,但是我还是希望测试,当使用集群时,是否能够提升推理性能。
在之前的一篇文章里(三台M1的Mac Mini,等于一个22B模型),我已经介绍了通过雷电4接口组建Mac集群的方式,这次,Mac Mini换成Mac Studio,连接方法是一样的,类似于下面的示意图,机器是三台。

不过推理框架,直接使用了本文开头介绍的exolabs,而不是llama.cpp,exolabs框架底层直接调用苹果的开源推理框架MLX,Alex(对,就是这两天转发很多的使用两台macbook pro跑405B模型的bro,过去一段时间我们交流较多,只是我直到今天才有时间开始跑测试)和他团队刚刚发布的新项目。
安装非常方便,在M系列芯片的苹果电脑上就是简单的三句指令:
git clone https://github.com/exo-explore/exo
cd exo
pip install .
然后在每台机器上运行后,机器会主动寻找其他可连接的设备,运行后的命令行界面返回信息审美还是在线的。下面三张图,分别是一台机器、两台机器、三台机器推理时的状态,非常简洁。
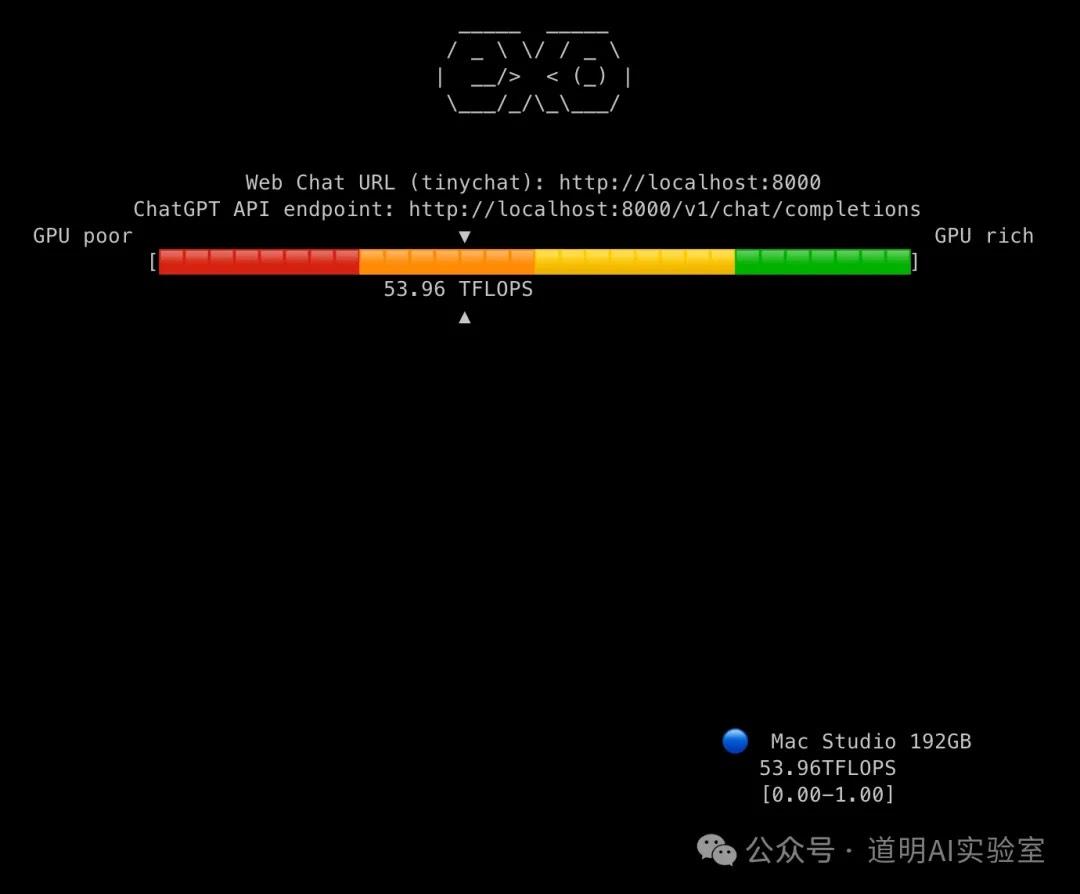
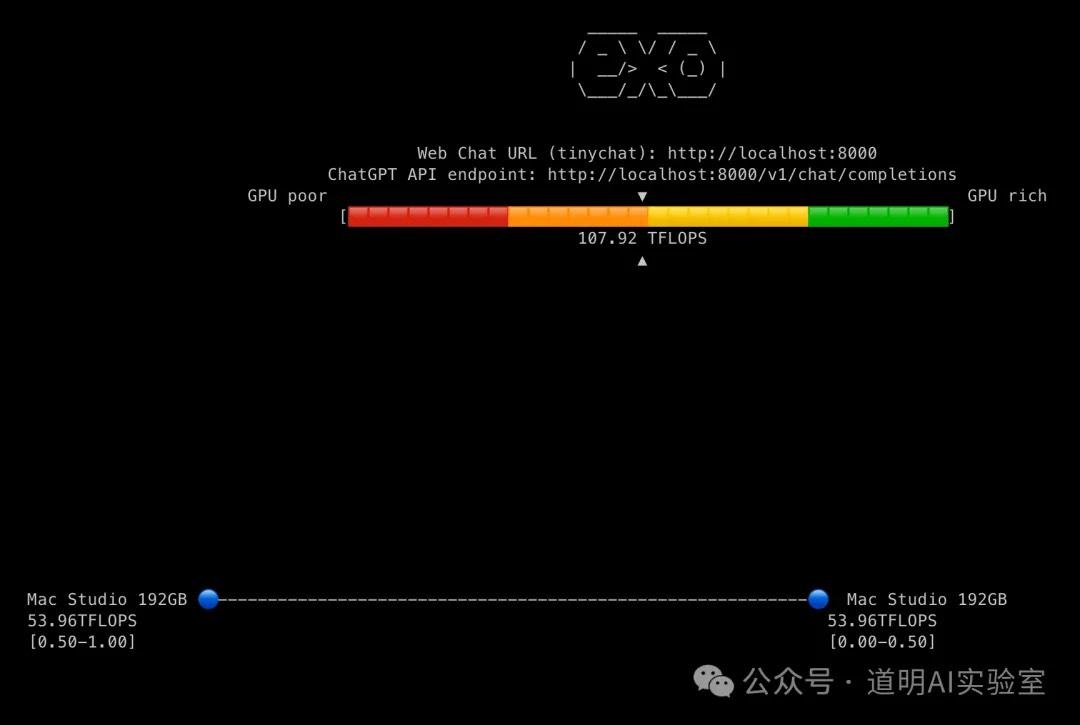

我分别测试了一台、两台、三台机器环境下推三个模型(llama-3.1-8b,llama-3.1-70b,Mistral-Large,123B 参数量)的速度。
三个模型都是int4量化版本,权重文件大小分别是4.5GB,39.7GB和69.1GB。
然后把9组测试结果发给了GPT-4O作图如下:
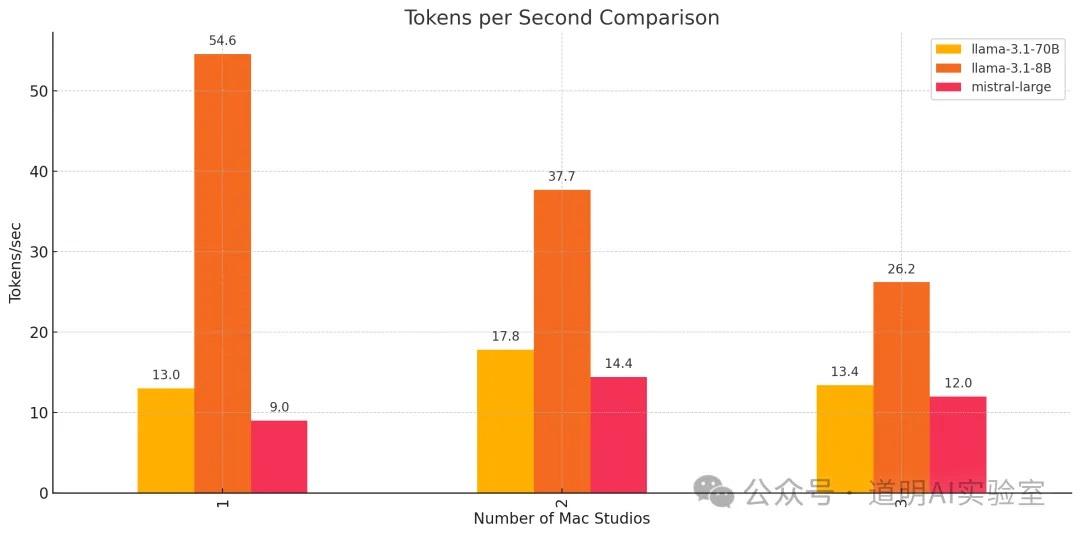
结果很有意思:
1、对于8B模型而言,推理性能最好的是单机,54.6tokens/s,然后每加一台机器,性能都会下降30%左右,很显然网络延迟显著超过了单token的生成时间;
2、无论是llama3.1的70B还是Mistral-Large的123B,两台机器推理性能相比一台都有提升,mistral-large的提升更为明显,但是,三台机器相比两台的性能就下降了;
3、相信,如果到了405B模型的话,应该会呈现出三台好于两台好于一台的状态,如果确实如此的话,那么多机集群就不仅仅是能够推模型,还可以有一定的性能保证,比如,是否可以达到10tokens/s?
4、其实,整个白天,我测试了很多情况,在一些测试中,70B和123B模型出现过三台性能最佳的情况的,我怀疑是网络的波动造成的:每台机器我还同时连着10G的以太网,在运行过程中,我没有制定互联的接口,有可能存在有时候走了40G的雷电接口,有时候又走了相对低速的以太网的情况,这一点需要在后面看一下源代码,再进行调整。
但是,无论如何,这个结果依然很有启发。
我想这不是有些朋友认为的无意义的“自娱自乐”或者又一个“挖矿项目”,通过苹果设备搭建低能耗的集群,实现大小模型共存的多Agents环境,再配合Claude3.5,GPT-4o等更强大的云端模型,“一人公司”是有很强的现实可行性的。
同时,我也相信,推理性能还是具备非常大的优化空间的,这也是有实际意义和可行性基础的,至少,苹果明确的表明,它们的云端模型AFM-Server就是跑在自家的Apple Silicon芯片上的。