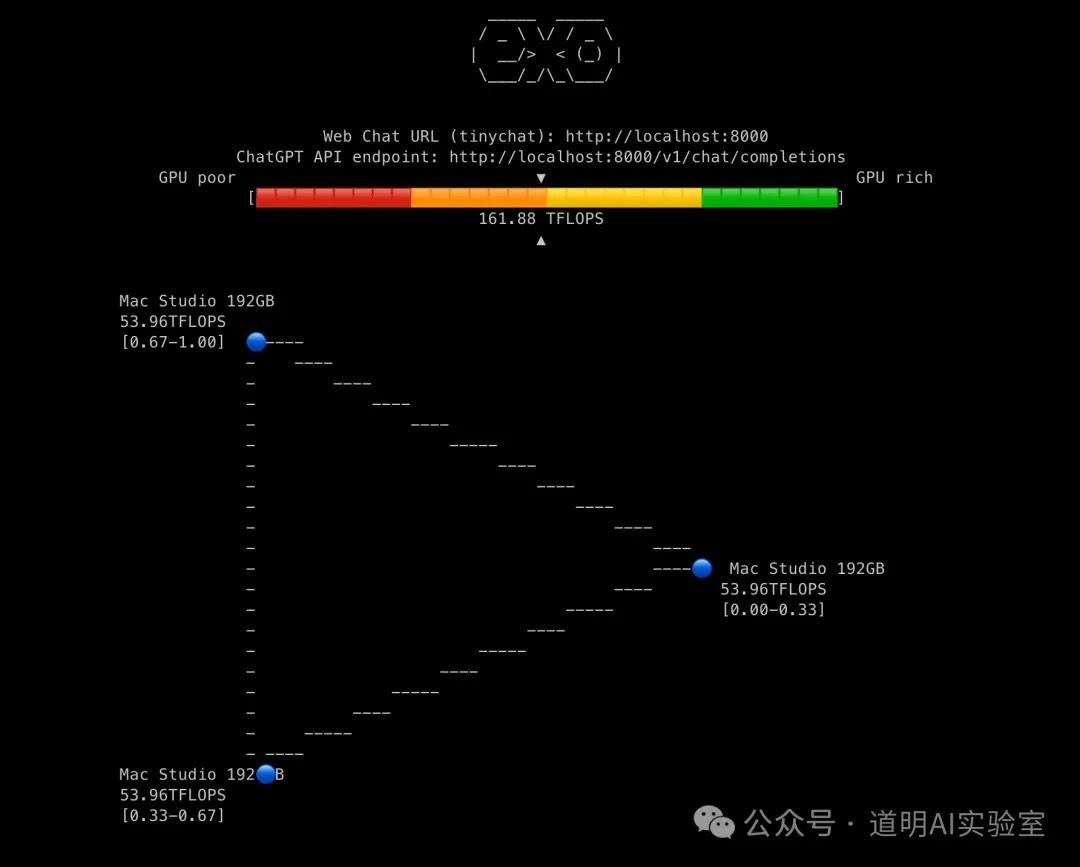
After more than a day of tinkering, I finally managed to get local inference of the Llama-3.1-405B model running on a Mac Studio cluster last night.
The specific method was already introduced in my previous article about running models on three Mac Studios, so I won't repeat it here. I'll briefly summarize the journey:
- When I started, there was no 405B-Q4 model available for download under HuggingFace's MLX_Community, so I had to choose the local mode;
- First, I downloaded the full 405B model weight files (FP16 is nearly 1T, and at a "super high speed" averaging 8-10MB/S, it took more than half a day—very, very fast, right?);
- Used MLX's Convert tool to quantize the model to a 4-bit version;
- Then deployed the model files to each node (to save time, I spent several hours adjusting the network until the speed finally hit the SSD write limit: 240-250MB/S);
- Modified the exolabs code to load my quantized model files;
- Then, a series of tests. My tests with two nodes kept failing, but it finally stabilized with three nodes.
After stable loading, the initial attempt yielded an inference speed of 4 tokens/S. It wasn't slow, but I felt something was off. After another round of network adjustments, finally:

Yes, you read that right: 7.3 tokens/S.
While there's still a gap compared to my calculated theoretical value of 10 tokens/S, I'm already very satisfied.
This is what it looks like running (real-time speed):
Regardless of whether the results are correct for now, at least this speed has reached a usable level.
Then, I couldn't resist comparing it with the results I mentioned earlier using four H100s to run the model (rapidly deployed llama3.1-405B on H100s). That environment consisted of four H100 (PCI-E) cards. I took the lazy route and used Ollama for inference, and the effect was like this:
As for the inference speed:
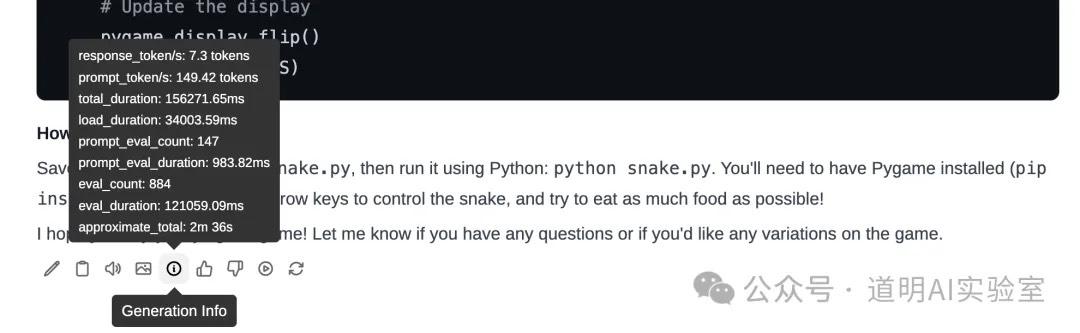
It turned out to be 7.3 tokens/S as well.
To be honest, based on the actual feeling in the video, the H100 speed is definitely a bit faster. I believe this is due to discrepancies in the underlying calculation methods between Ollama and exolabs' UI (tinygrad), but the speed difference is not very significant.
- The H100 environment should still have a lot of room for optimization (Ollama is a bottleneck again);
- The Mac Studio probably doesn't have much optimization room left based on the current code, but modifying the low-level code might work.
Finally, this summer, the long-awaited model has been released, the desired environment has been deployed, and the testing phase has come to an end. It's time to get down to "real business" in the next stage.