If we go back to 2017, AlphaGo shocked the world. Subsequently, while AlphaZero possessed even greater capabilities and was more "terrifying" from a technical standpoint, it didn't cause as much of a shock as AlphaGo.
The same story has played out with ChatGPT in 2023, GPT-4, and the o1 model released just over a week ago. This is true not just because of the reception they received, but because of the trajectory of technical evolution.
If AlphaGo "acquired" the ability to defeat top human players by "learning all the games in the world," AlphaZero evolved through "self-play" based on an "understanding" of Go. It has now become the ultimate coach, while humans continue to enjoy the beautiful world of playing against themselves.
Therefore:
- First, acquire basic knowledge by learning from massive amounts of data, then continuously strengthen oneself to possess "true game-playing ability."
- The existence of super-human intelligence has not seriously threatened humanity itself.
Regarding the GPT series, let's set the second point aside for now; the first point is almost identical.
Up until GPT-4, the concepts everyone knew were pre-training, transformers, and the scaling law. Yet, it seems most people still don't understand the following two statements:
- Generation implies understanding;
- Large models are knowledge compressors;
Many might jump out and criticize, saying it's wrong to compare GPT to AlphaGo—what about pre-training? What about transformers? What about scaling laws?
Setting aside the facts that "training AlphaGo on human game data is pre-training" and "AlphaGo fully proved the existence of the scaling law," even though AlphaGo initially didn't use transformers, it doesn't mean it didn't use a similar architecture (albeit an earlier, perhaps less performant one) to let AlphaGo "understand" Go through the process of "placing stones."
Generation implies understanding. While this statement remains controversial, the way AlphaGo proved its "understanding" of Go through "placing stones" and "playing matches" serves as an illustration. Returning to large models, representing "understanding" through generation follows the same logic.
Yet, people remain skeptical: models have hallucinations, they are unreliable, they make frequent mistakes, and they even get simple math problems like "is 9.9 > 9.11" wrong. How can they prove they understand?
In fact, who doesn't make mistakes?
A large model is a knowledge compressor. Simply put, it consists of two parts: pre-training is the compression process, and downstream tasks (such as generating text, images, etc.) are the process of decompression and output. Humans frequently suffer from memory loss and false memories; why expect more from a model that is essentially still a "child"?
A year ago, we could attribute most of these errors to pre-training—insufficient scale, lack of data, erroneous data, or short training times leading to a high "loss rate" in compressed knowledge. However, by the first half of this year, with the debut of Gemini-1.5, Claude-3.5, and Llama-3, and the iterative updates to GPT-4 itself, this judgment has largely become obsolete, at least for text-based information. It’s not that pre-training "compression" is perfectly accurate now, but we can assume the knowledge "loss rate" is sufficiently small (leading some to simplistically conclude that the "scaling law has failed," which is a one-sided conclusion I will explain later).
In short, at least in the text domain, the pre-training task of "knowledge compression" is essentially complete. What needs to be strengthened now is the "output" part. If the former is what people usually think of as GPT (though ChatGPT includes both, and any model that outputs normal sentences does), the latter now has an independent name: o1, or the long-rumored "Strawberry." Whether it's fine-tuning, reinforcement learning, or Q*, it was officially launched as an independent "model." However, it is not an entity separate from GPT but a symbiotic one: GPT is the knowledge plugin and memory bank; o1 is the thinker (writer, mathematician, researcher, etc.).
Therefore, the emergence of o1 does not prove the pre-training scaling law has failed; rather, in the text domain, pre-training has largely fulfilled its historical mission. However, pre-training remains extremely important. Remember Sora, which has been quiet for a while? Vast amounts of data exist in the form of images, videos, sounds, and even 3D. Transformers have proven to be highly effective on these data forms, and the scaling law still holds. What's missing is data and computing power (though if you look at the barrier to entry, you'll see the number of players can be counted on two hands).
Returning to the scope of text data pre-training, since models like GPT-4 have proven they can compress knowledge with a very low "loss rate," the focus shifts to how to output—and that's where o1 takes center stage.
Coming back to the "9.9 vs 9.11" question: yes, even early versions of GPT-4(o) gave the wrong answer. It might have possessed: 1. Knowledge of expressing numbers by digits; 2. Basic arithmetic knowledge; 3. Knowledge of comparing numbers. But without a good "brain," it couldn't link them together. Thus, errors and hallucinations were inevitable.
However, if we recall how we first learned to compare decimals, we might realize it wasn't "natural" but required a method—we also compared them digit by digit.
Exactly. By teaching this method to another model and letting it think using the knowledge compressed by GPT-4, the problem is solved. This is the significance of the o1 model and the first of the two final massive hurdles on the road to general AGI.
That's why the o1 team said they spent a year and a half teaching the model to count how many "r"s are in "strawberry." This isn't humans teaching it rules, but once again letting the scaling law work. When a model is trained on enough "paradigmatic" data, the ability for "thinking" and "reasoning" "emerges": GPT-4 becomes the "chatbot" and material provider for o1, while o1 becomes the thinker, organizer, and outputter.
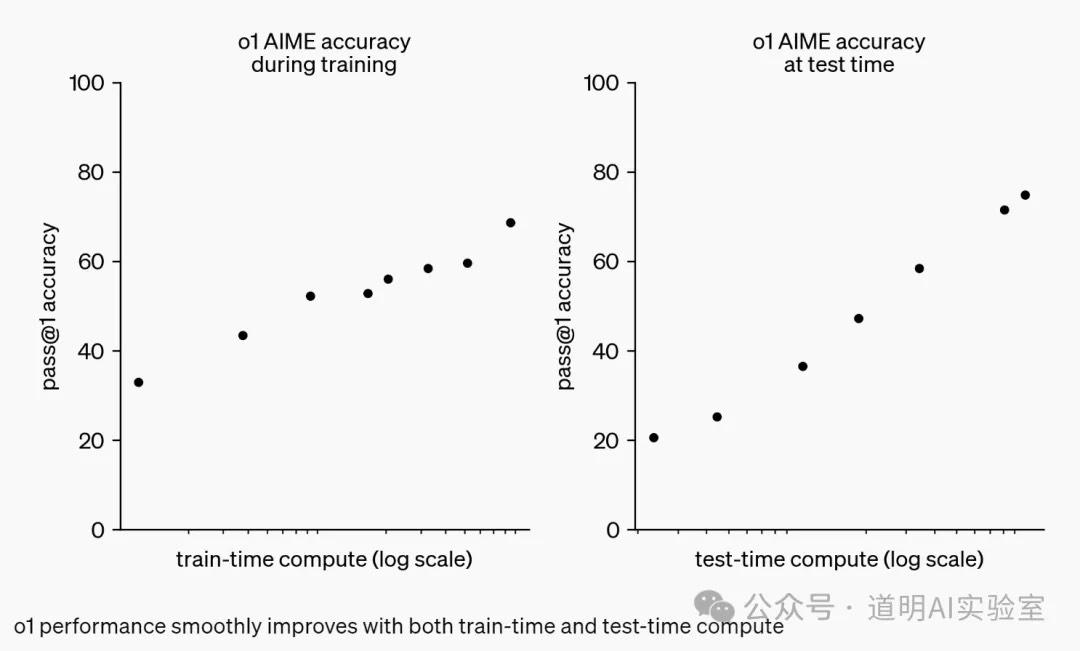
As shown in the chart below, the longer o1 trains itself, the better the output results: the scaling law in action.
As independent entities, both GPT (the pre-training part) and o1 have a long way to go. Pre-training needs to incorporate more modalities and "understand world models," while o1 needs more thinking, logic, and reasoning capabilities—essentially, the ability to train itself. o1 relies on the growing knowledge of GPT, while GPT's massive "knowledge reserves" and potential need o1 to be continuously excavated.
As a public account article, this would be a good place to wrap up. However, I still need to answer two questions for many friends (and industry peers). These answers are not based on "exclusive info" but on public information, my own experience, and my experiments—this time is no different:
Regarding the naming of GPT: Will there be a GPT-5? When? My answer: maybe, maybe not, but it really isn't that important anymore. OpenAI certainly didn't expect ChatGPT to be this explosive, so their progress on different problem-solving routes toward AGI has actually been relatively orderly. GPT has always been positioned more as an internal tool or a foundational tool for other developers—a "knowledge compressor," as mentioned. It just needs to compress more modalities like images, video, and 3D. Over time, it will be proven that transformers and scaling laws still work for these data types. The "independent" debut of o1 means that whether it's GPT-5 or GPT-6, the number is just a sequential code. In a sense, I personally think making o1 independent rather than releasing a model called "GPT-5" was a great choice.
Regarding computing power: By the first half of this year, a consensus was reached: the "tickets" for the large model race have been claimed. It's hard for new players to enter; instead, there will be eliminations. The threshold is too high—infrastructure, data, talent—it's all becoming astronomical. As for computing demand, I suggest looking at major clients of Oracle Cloud (claiming orders for over 130,000 B200 cards), AWS, Azure, Google Cloud, etc. A clear conclusion can be drawn there. I have always carefully verified and corrected my views based on public information and practice. This is far from mere "speculative writing."