对于Scaling Law遭遇瓶颈的质疑迅速升温,既有所谓OpenAI的内部爆料,也有来自Ilya的“一锤定音”。
同时,越来越多的自媒体也开始爆料:Gemini和Claude都遇到瓶颈。似乎一下子“AI寒冬”再次到来。
可是看看本周美国市场的几大巨头,虽然没有什么“势如破竹”,但同样没有“一泻千里”。按理说,如果真的市场认为寒冬来临,会是夏天那种暴跌至少十个点的景象。
所以,问题在哪里?是真的撞到了“数据墙”:缺乏高质量的数据吗?
首先,缺数据从去年开始就已经是最大的问题了。但是相比起预训练数据,可能更缺的是精调数据和评估数据。其实,就是缺“人力”。
尽管“生成式数据”已经越来越多的应用到精调数据和评估数据的生产过程中,极大地减少人力“监督”的工作量。但是两个原因依然导致这两类数据需要天量级的人力开销:1、预训练数据因为可获得性增加而规模快速增长(十倍以上),对强化学习需要的数据量需求急剧增加,必须使用大量人工确保较高的数据质量;2、随着模型涉及的范围越来越广,评估数据也显得远远不足,新领域的拓展和更多“corner case”的引入都需要人工的大量参与,而且这种人力更多的应该是足够了解应用场景的“熟手”。
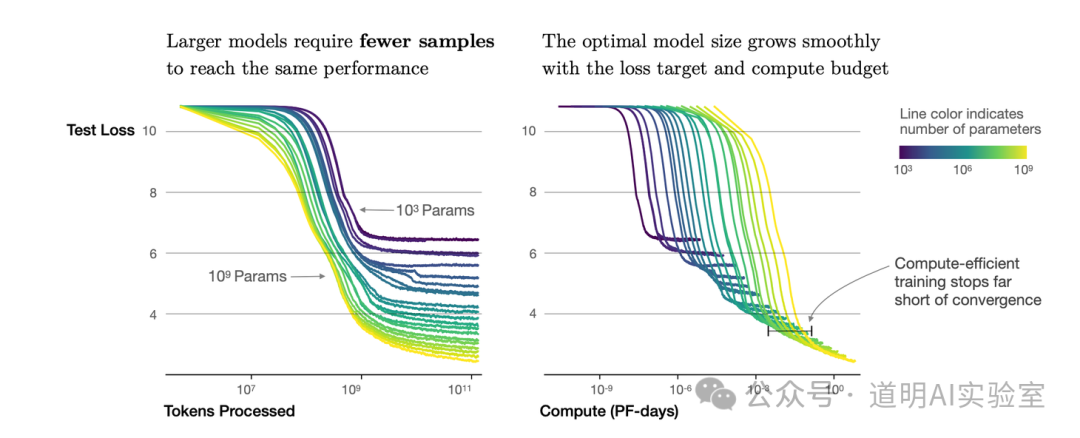
同时,如果没有足够的后面两类数据的配合,在目前能够获得的算力约束下,单独增加预训练数据,对模型能力的边际效用已经快速降低了。
所以,故事的真相或许更像我在二季度提出的观察:1、单集群能力在Blackwell正式部署前成为Scaling Law的天花板;2、高质量精调和评估数据缺口可能是十倍以上,即使再缺“人力”,也无法通过大幅增加“人力”资源实现(熟手并不容易获得),找到有效且成本可控的“高质量生成数据”成为后面最重要的方向。
模型可能确实“撞墙”了,一面“数据墙”,但是打破墙的方法却需要依靠算力集群提升和数据生成方法的改造。这或许是OpenAI的Sam Altman,Anthropic的Dario Amodei和Ilya共同表达的真实含义。
从ChatGPT问世到现在的两年时间里,模型能力的飞速进步有目共睹,越来越多人在日常学习工作中也已经离不开这些模型的帮助了,也更能清晰的知道模型的擅长领域和能力边界了。
从芯片制程墙,芯片互联墙,内存墙,网络墙,到数据墙,应用墙,科技进步就是不断破墙的过程。
尽管惯常的破墙方式还是“曲线救国”,但是在这一次依靠数据获得的“智能”时代,数据,依然是最大的挑战,也是唯一重要的资产。