Time is flying by, and another year is coming to a close. Yet, in the two years since ChatGPT was introduced, every day has felt fulfilling and high-pressure: even without a complete tally, one can confidently say based on subjective feeling alone that "new models or products are released almost every single day."
Last week, I completed an AI outlook for 2025:
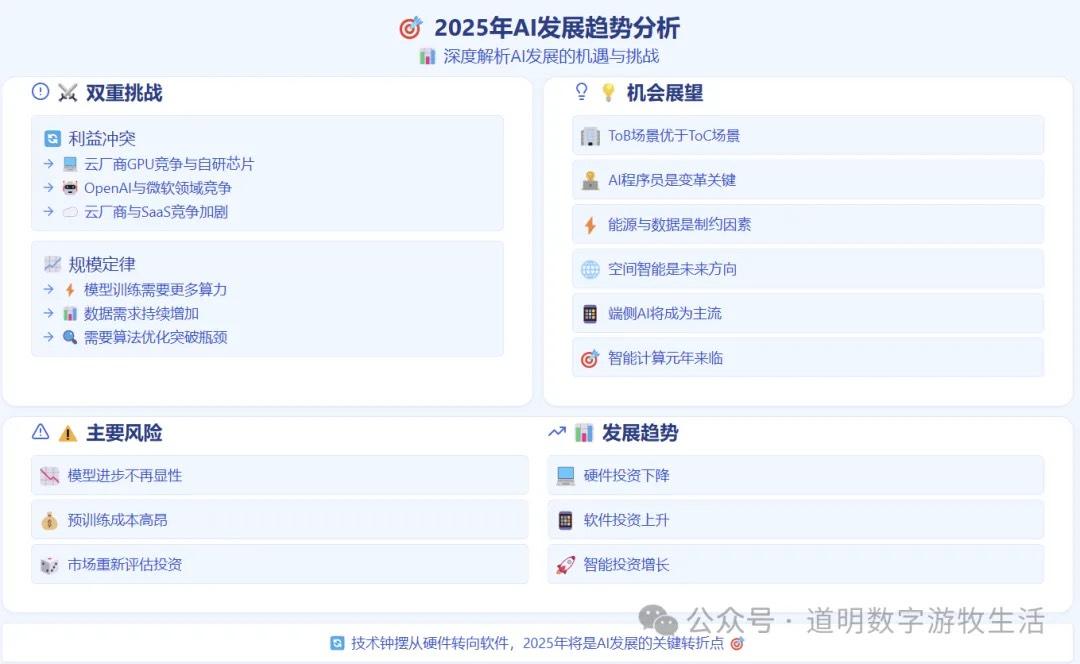
2025 AI Outlook
Daoming, Public Account: Daoming Digital Nomad Life
It’s time again to write the AI outlook for 2025—two keywords, several predictions, and one potential risk.
The main conclusions are shown in the image below:
Some points have reached consensus, some are emerging, and others remain to be seen.
However, for the more complex year of 2025, we might need to discuss certain issues from a different dimension—ones that are more long-term. Three questions I can think of: 1. AI's mid-to-long-term drivers and constraints: Energy and Data; 2. Changes following large-scale AI application: Efficiency gains and organizational restructuring; 3. A smarter future: Products and "User Experience."
Expanding on each point may require more time for verification or falsification. Below, I will simply outline some key points.
I. AI's Mid-to-Long-Term Drivers and Constraints: Energy and Data
If we set the scale of a large cluster required for pre-training next year at 100,000 Nvidia Blackwell GPUs in a single cluster, using a density similar to NVL72, the math is simple: one cabinet has 120KW of power and 72 GPUs, requiring a total of 1,389 cabinets and 167MW of power. Including other equipment, this is essentially the level of at least one 200MW power station. Don't forget, backup power is also needed. Even if the backup UPS is designed to "maintain half an hour after power failure," it is a huge volume for backup generators and energy storage. Moreover, the number of such clusters globally is likely not in the single digits.
Many people mention the failure of the Scaling Law, but no one can deny that the root cause is actually a limitation in compute cluster scale, data volume, and quality. Since experiments cannot be conducted yet, no one has a definitive answer to whether "increasing data volume tenfold will lead to the failure of the Scaling Law." The problem is that high-quality human data is difficult to increase tenfold in a short time. Synthetic data can be used, but the current "model inference cost" remains high. Tenfold data volume is about 100T-200T tokens; even at $10 per million (M) tokens, the cost of generating data starts in the hundreds of millions of dollars. This is just for text generation; the cost of generating image data is at least an order of magnitude higher (otherwise, Sora wouldn't be so stingy).
The massive demand for energy and data exists not only in the training phase but even more so in the application phase: the "liquid gold" of the new era—this metaphor is not an exaggeration.
II. Changes Following Large-Scale AI Application: Efficiency Gains and Organizational Restructuring
An increasing number of models and products are focusing on "programming capabilities": One of the AI challenges for 2025—AI programmers, inspired by bolt.new. So-called Agents actually rely on "code generation" capabilities. Code generation is a very comprehensive capability; basic programming is only one part, more important is task understanding and modeling capabilities. It is meaningless to talk about an Agent's "understanding" in isolation from its programming capabilities.
Significantly improving productivity in various aspects through code generation is a goal that this generation of AI, at its current level, can already achieve.
In my high-frequency exchanges over the past two years, a change in perspective has been interesting: in 2023, many thought this was a major revolution, but in 2024, a large portion of people changed their minds, believing it is merely a "change in productivity" rather than a "change in production relations." But doesn't productivity determine production relations? 2025 may be the beginning of the "revolution" we envisioned two years ago.
Around Christmas, large U.S. tech companies started another round of layoffs. The basis was efficiency evaluation, and the result was: reducing management positions.
In scenarios where we can already see large-scale AI applications, the demand for pure management positions is significantly decreasing. These pure management roles are not just about "managing people" but include a series of process management, resource management, and so on. Most importantly, it involves a large number of so-called front-line positions in various enterprises that cannot produce results starting from the most basic work. The "window of opportunity" for major organizational adjustments in large enterprises has arrived once again.
III. Products and "User Experience"
What kind of consumer products do we need: Cloud-based large models? AI phones? AI PCs? AI glasses and hardware? Self-driving cars? Robots?
Is it possible that neither users nor manufacturers have clearly figured out what kind of "product" we actually want?
Generally, however, we all hope AI products can satisfy one of our two basic needs: "lazy nature" or "emotional sustenance."
Therefore, the requirements for "user experience" have changed: the ultimate form of laziness is "models or machines working for us," making our interaction process with machines very simple—a few inputs and outputs (very direct: text, voice, or image and video). The Internet's "funnel model" will gradually cease to exist. "Emotional sustenance" is expected to be built on sufficient personalization, but whether it will truly look like something out of a sci-fi movie is still unknown.
For a long time, many users subjectively believed that "Apple phones are easier to use than Android phones." However, over time, more and more users have come to believe that "Android is easier to use." The reason behind this is that as hardware and operating systems become more standardized (e.g., Qualcomm SoCs standardizing and fixing hardware platforms), software optimization becomes easier.
However, in the era of AI products, products with good "user experience" will require more "software-defined hardware." This is why ecosystem and hardware-software integration capabilities have become more important, and why "All-in-One" is needed—though this also involves "antitrust" issues, which is interesting.
The most significant ultimate application we can think of for this round of AI is "humanoid robots," which also emphasizes "user experience" the most. Perhaps the consumer-end "experience" focuses on "personalized intelligence," while the business-end "experience" might do the opposite, focusing on lower total lifecycle costs.
It feels like we have returned to a "starting point," the same one from the beginning of 2023. What’s exciting is that after two years of an "arms race," we have more and smarter models, and we seem to see the future a bit more clearly.