Which LLMs Can Distinguish Between "9.9" and "9.11"?
Which large language models can correctly answer the question: "Which is larger, 9.9 or 9.11?"
The answers are: GPT-4o (post-o1 release), Gemini (post-Gemini-Thinking release), DeepSeek-V3 and R1, Qwen2.5, and potentially a few others.
Which models get it wrong?
GPT-4o and Gemini from the first half of last year, Llama-3, and the recently released "world's strongest" model: Grok-3, among others.
However, if you change the question to: "Which is larger, 9.90 or 9.11?", almost all the models mentioned above can answer correctly.
What is the reason?
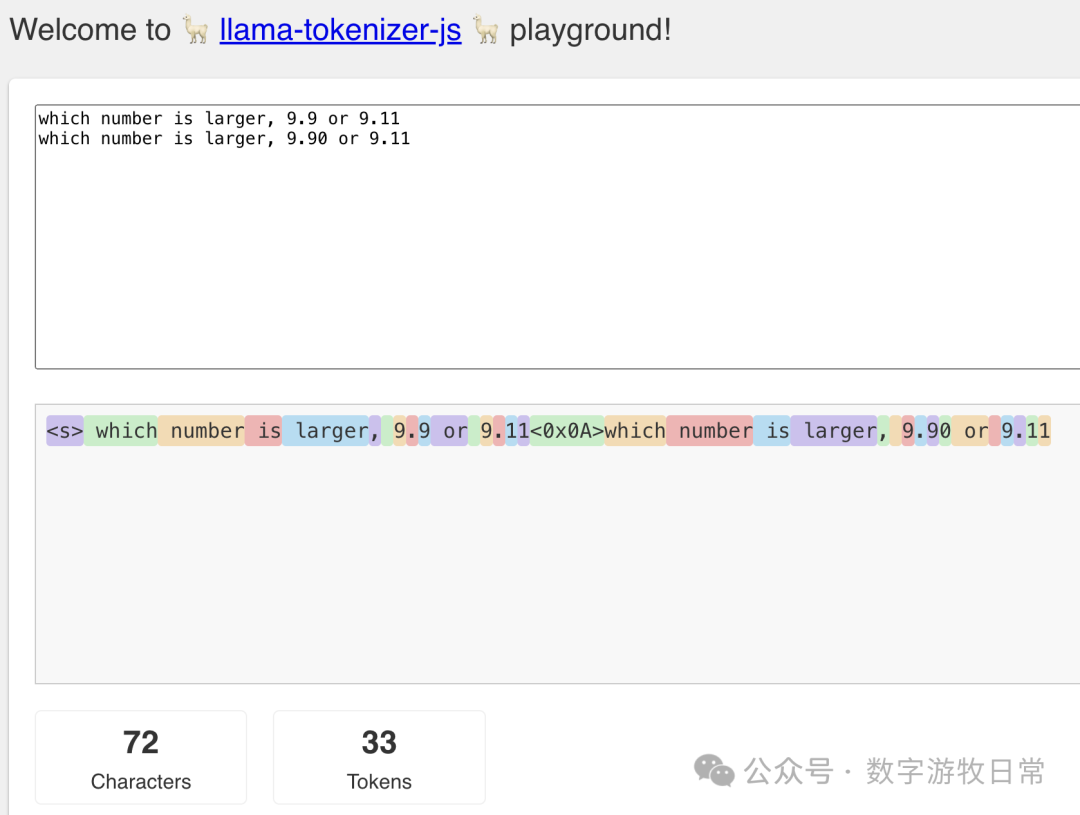
The fundamental principle of large language models is predicting the next token. Through tokenizer visualization, we can clearly see that each digit and character occupies a token; thus, 9.9 consists of three tokens: '9', '.', and '9'.
While "9.11" becomes four tokens, current pre-training causes the model to truncate before and after the '.'. The model "understands" the problem as comparing the '9's before the decimal and then comparing '9' vs '11' after the decimal. Without correction, the result is "9.11 > 9.9". As for why a probability-based model knows to compare integers and decimals or why it knows to combine the two '1's in the decimal part, that is the multi-head attention mechanism—when you match keywords like "number" and "larger" alongside digits, the probability distribution of the training data drives the model to output tokens related to size comparison.
This issue was quite clear when ChatGPT first emerged in 2023. However, the rise of DeepSeek, which "crushed" GPT, has brought this question back into the spotlight.
Actually, solving this is simple. As mentioned, you can ask the model to compare "9.90" and "9.11," or use a prompt to instruct the model to align the decimal places first. (Reference: DeepSeek Deep Research (1): Classic Case Tests Prove "Cracking the Base Model is More Important").
Therefore, the purpose of a prompt is to make the output distribution "favorable" to the user's desired result.
Beyond prompting, techniques like RLHF (Reinforcement Learning from Human Feedback) and the "reasoning capabilities" gained through "Reinforcement Learning + SFT" (like in R1) can "standardize" model outputs to solve such problems.
Deep Analysis of Model Performance:
- Why did GPT-4o fail before? Because it wasn't specifically trained on such problems via reinforcement.
- Why does o1 succeed? Because o1 was "taught" distributed calculation and "decimal alignment" during training.
- Why does GPT-4o succeed now? Because after o1 was released, its outputs were likely used as data to "reinforce" GPT-4o.
- Why did Grok-3 fail? For the same reason as the old GPT-4o.
- Why do V3 and Qwen (non-reasoning models) succeed? For the same reason as the current GPT-4o.
- Why is R1 correct? Why did Llama succeed after R1 distillation? For the same reason as o1.
Reportedly, Grok-3's reasoning model performs correctly on this task.
The Debate Over "Model Boundaries"
In the past 24 hours, the two most common comments have been:
- 100x the cost for a 30% improvement.
- We have reached the boundary of large models.
Both are clearly incorrect.
In an exam, cramming might get you an 80, but reaching 95+ might take dozens of times more effort. No one would say you "only improved by 20%." Grok-3 has, at most, hit the boundary of existing text data.
"AI" might be the most misleading word of recent years. The term "intelligence" creates unrealistic expectations. In reality, a Transformer is a compressor, whether the modality is text, image, audio, or video. Currently, algorithm optimization focuses on how to more efficiently and accurately compress and reconstruct the data (knowledge) the model was trained on.
Prompts, RLHF, and even "reasoning models" all explore how to guide the compressor along an effective path (token by token) to reach the desired answer.
Does the model "understand" its output? By human definitions of understanding, the answer is "no." We can view model errors as "hallucinations." These occur because: 1. Relevant knowledge wasn't trained; 2. Training data was incorrect; 3. There are too many distractors with similar probabilities.
From Text to Multimodality
Models have a limited information processing capacity; exceeding this limit significantly increases the error rate. While text hallucinations are hard to spot, image and video hallucinations are often obvious. For tools like Sora, providing more detail can significantly reduce hallucinations. However, Sora cannot exhaust all existing videos or store every pixel during pre-training, leading to visible hallucinations in complex scenes or object movements.
While solving movement hallucinations might require other methods, for details, the solution is definitely more data and higher pre-training resolution.
Conclusion: The future of large models is multimodality. Even if "pure language" hits a wall, the limits of image, video, audio, and spatial data are far off. Furthermore, has the model really exhausted all data?
DeepSeek-V3's technical report shows it used massive amounts of reasoning process data from a V2-based R1 model. Additionally, V3 and R1 leveraged high-quality "synthetic" data in math, physics, and programming. Even the simple question at the start of this article was answered correctly due to the addition of such synthetic data. Chain-of-Thought (CoT) data works by stimulating the vast "compressed" knowledge already within the base model.
All leaderboards are merely references; no single chart can fully evaluate a model's capability. Grok-3's performance does not indicate the failure of the Scaling Law. We know too little about xAI's data center usage or Grok-3's specific architecture (Dense vs. MoE).
I believe human progress is achieved through successive steps of the Scaling Law. Until it is proven that "models surpassing human intelligence will never appear," data and computing power will never be "enough."
References:
- Hinton's Views (Public Account: Daoming Lab)
- Geoffrey Hinton's Latest Speech: Digital Intelligence Will Surpass Biological Intelligence