Anthropic has finally released its new model—the one that was supposed to come out before last November. Perhaps it was delayed for technical reasons, or maybe they’ve been holding back since OpenAI's o3 release. Of course, it’s also possible that the release of DeepSeek R1 gave Anthropic an "epiphany" moment, leading to the creation of its own reasoning model.
Diligent friends have been messaging me to ask: Is it below expectations?
After waking up this morning and quickly trying a few examples I had on hand, my answer is: Calling the version number 3.7 is certainly below expectations, as the market was expecting "Claude 4." However, the actual improvement in performance is very obvious.
Two versions of 3.7 were released: Claude 3.7 Sonnet, the base model, and Claude 3.7 Sonnet (64K Extended Thinking), the reasoning model.
It’s the perfect time to showcase the "Predict the Next Token" animation I was preparing a few days ago.
The prompt was as follows:
compile an animation to illustrate why llm's secret is just to predict the next token, please include transformer, multiple attentions, using a professional theme
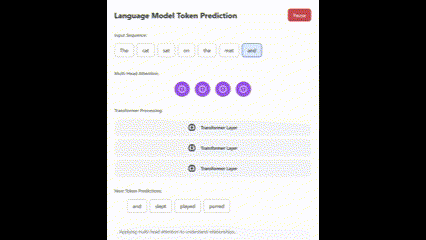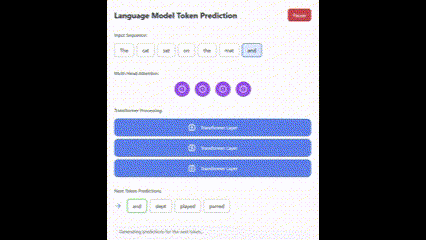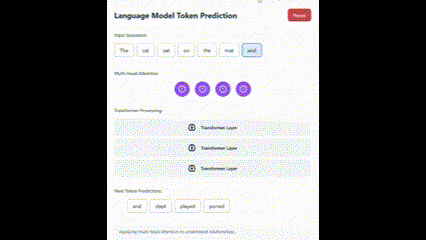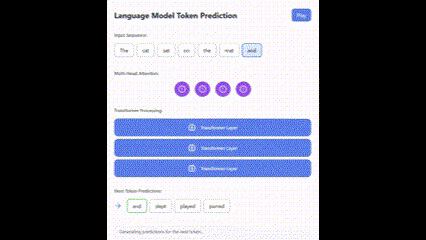
Here is the result from version 3.5:
And here is the result from version 3.7:
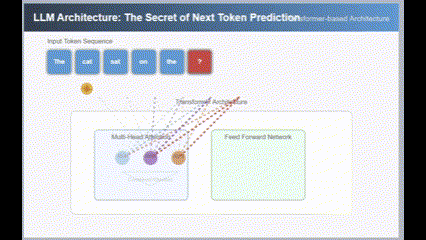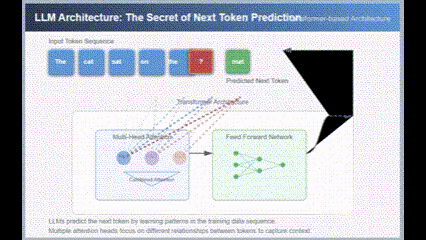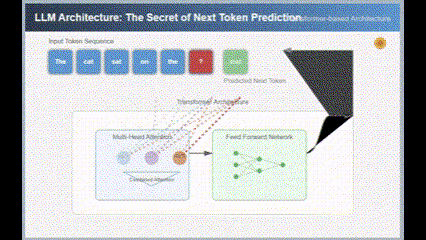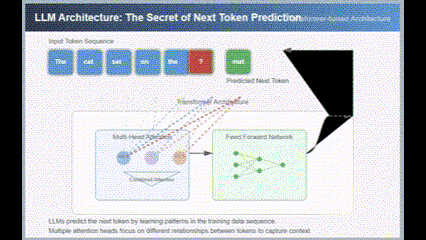
Both were first-attempt results, and the gap is evident.
Some might ask, what about Grok-3? Others might say this example isn't representative.
Regarding the first question, Grok-3 does not support real-time code execution; it can generate code, but the user must run it themselves.
In this instance, Grok-3 (the version available on release day) generated three files: standard HTML, JS, and CSS.

I saved them and opened index.html in a browser, but... nothing happened.
I then threw the code into Claude 3.5 (since this was a test from the day Grok-3 launched). After two revisions:
The result is as follows: this code essentially realizes what Grok-3 intended. By the way, this was the result after I turned on the "Thinking" mode.

As for the second question regarding representativeness: if version 3.7 can provide significantly more information density in an instance generating an animation from a simple prompt, doesn't that speak for itself?
Furthermore, Claude's Artifacts feature has been out for a long time. OpenAI added Canvas, and Gemini supports code execution in AI Studio.
Why shouldn't the "world's strongest" model do the same? Models are meant to be used, and the goal of AI applications is to be "user-friendly and lower the barrier to entry," right? If a product launches with a bunch of bugs and incomplete features, more time should be spent on genuine UX improvements. Don't let being "too obsessed with games" (perhaps add "finding a booster" before obsession) affect bringing your "high taste" to important products.
I have always admired Anthropic's style: they build and release products seriously and realistically, without throwing around claims like "strongest in history."
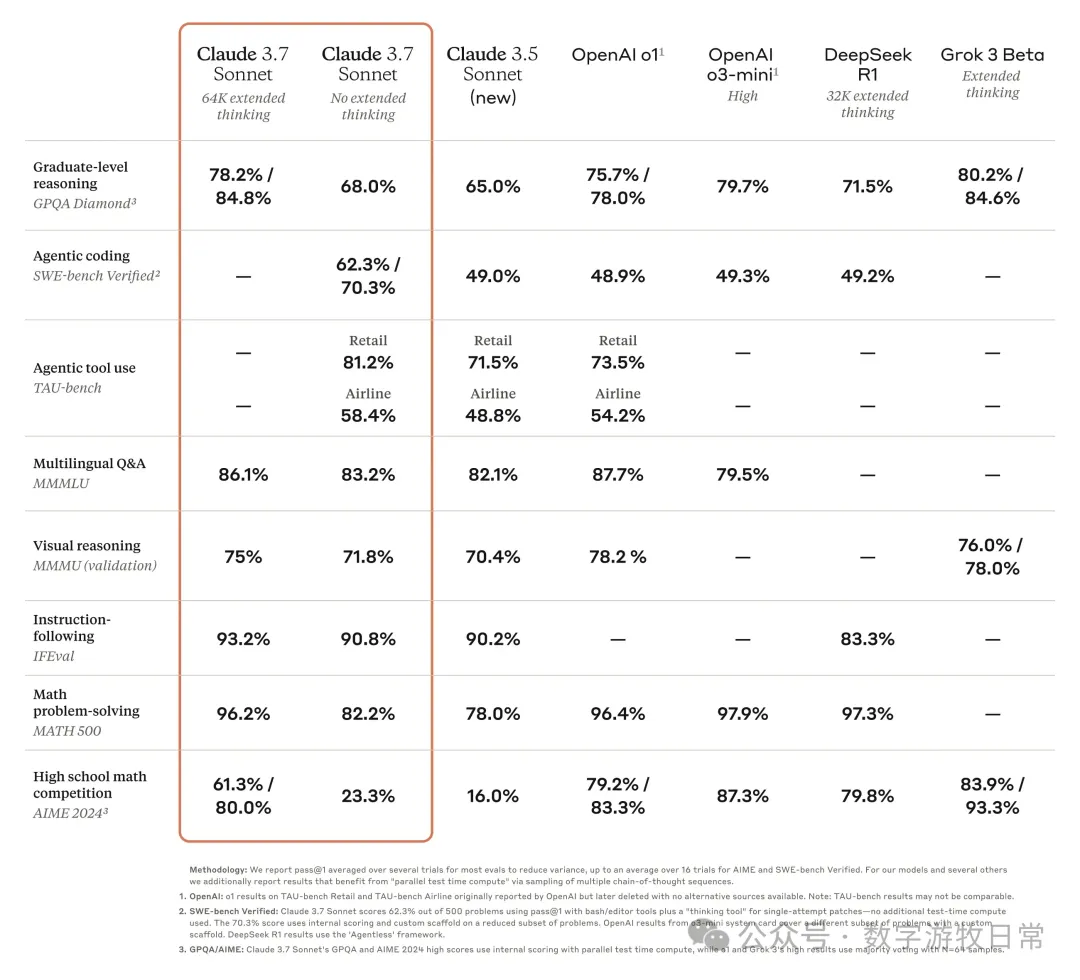
Their evaluation comparisons are clear and transparent. They didn't over-hype that "thinking" is just better across the board. Instead, they realistically stated that the "reasoning model" enhances math and coding capabilities, while in Agentic coding and Agentic tool use, the reasoning model scored zero.
The reason is simple: reasoning models conflict with Agents. This can be optimized later, similar to OpenAI, but the current version likely doesn't support function calling, or at least it's not recommended to use the reasoning model for it.
Of course, Anthropic played a little trick: they didn't include OpenAI's new GPT-4o in the comparison.
There were two other highlights in Anthropic's release, one being Claude Code.
Claude's biggest strength is coding, so the Claude Code application is very timely. I haven't had a chance to try it yet, but my initial feeling is that a real competitor to Cursor has arrived—though Cursor will surely support the 3.7 model immediately.
The other highlight is the future roadmap, where we can see Anthropic's "ambitions."

These are the kinds of things only hardcore "STEM geeks" could pull off.
By the way, Anthropic's contribution to the AI community isn't just about releasing models; they have made massive contributions to Interpretable AI and publicly shared their findings.
The seat of the "strongest" model was only occupied for a few days. I believe OpenAI won't be able to sit still—where is GPT-4.5? A favorite quote of mine applies here: in this world, there are no miracles.
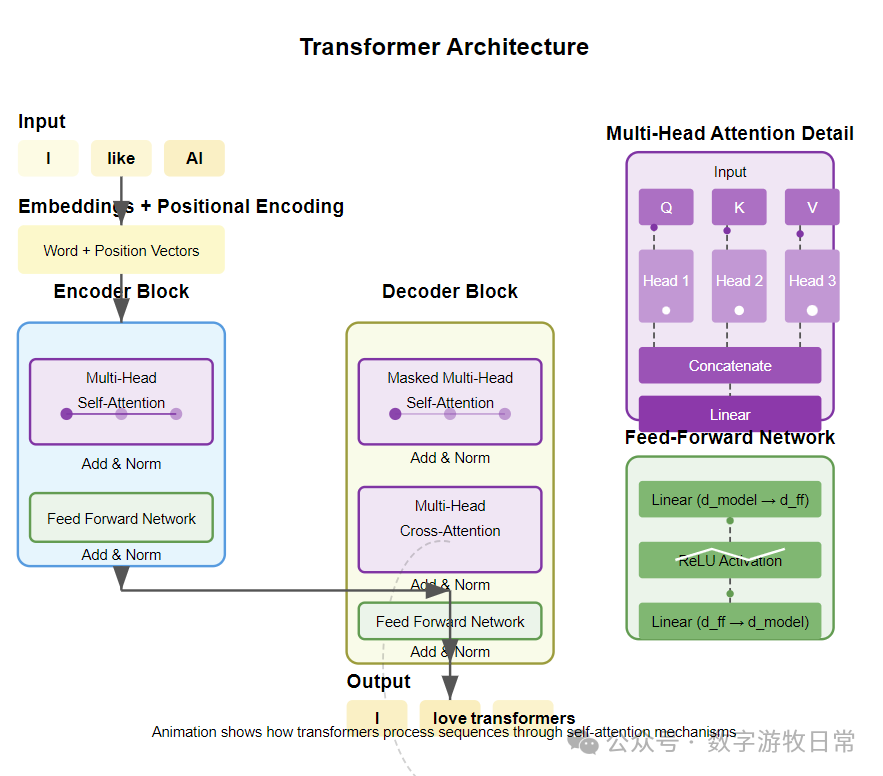
Here is a screenshot of one frame from the 3.7 SVG animation demonstrating a Transformer.
And take a look at the 4-second thinking process for the code generated in one go.

Again, some might say DeepSeek can do this too. I won't argue with that.
But as of now, we can objectively say DeepSeek's greatest significance lies in three things: 1. Showing everyone that "thinking" can be achieved in a different way; 2. Making huge strides in training efficiency and cost reduction; 3. Finally letting the Chinese public realize that current AI has already reached this level.
As for open source, AI should have been open source all along.
Ultimately, there are no miracles. Anthropic and Google Deepmind (and OpenAI, if they stop bragging) who invest massive compute, data, and human effort into down-to-earth work, likely have more of a say.
The version number 3.7 is certainly far below expectations, but perhaps in the current competitive landscape, Anthropic feels 3.7 is enough. Or perhaps they feel that the product they are ready to show doesn't yet deserve the generational leap signified by the number "4."
PS: If Deep Research represents the progress of AI search, then Claude 3.7 has once again raised the ceiling for AI programmers. These trends align with my outlook at the end of last year.