Doing something unconventional for once, I'm discussing this issue "openly" on this account—but as always, it remains a purely technical discussion.
First is the inference service yield of R1, especially that eye-popping "545%." I have written about this before; I believe the numbers are correct, but the constraints to achieve this figure are numerous:
- Revenue must be based entirely on R1 model fees, with no free web version or app—only API calls, all R1;
- The hardware must be at least all H800s, specifically eight-card servers with intra-node NVLink and inter-node IB networking. For those interested, you can look up what the rental costs for such setups are;
- A minimal optimization unit consists of 22 nodes (4 prefill, 18 decode), totaling 200 cards;
- On the demand side, customers must always be in a queue, meaning all servers are at full capacity at all times with no "idle" periods;
- Looking at the minimal 22-node setup, load imbalance between expert models will still exist, significantly affecting output. Thus, significant extra redundancy is needed to allow room for dynamic adjustment of expert model deployment (every 10-15 minutes). Therefore, 1,000 H800s might be a more reasonable threshold.
A soul-searching question: Who has that many cards? And for those who do, would they choose to continue training models or completely give up to provide inference services with ever-decreasing profit margins?
The second issue stems from the change in inference performance from V2 to V3.
The image above comes from a V2 pull request on GitHub regarding V2's inference performance, showing single-node output at 50,000 tokens/sec (likely decode). According to data released by DeepSeek (DS) last Saturday, the average output for decode nodes is 14.8k—just under 15,000. Even if we assume the actual peak exceeds this, considering DS is still in short supply, a peak output capacity ceiling of 20,000 tokens/sec seems reasonable.
As both use the MoE architecture, V2 has 21B active parameters, while V3 has 37B. As scale increases, a decline in performance is inevitable. However, a drop from 50k to 20k is more than 50% (of course, it's not a direct comparison because DS data shows R1 has higher overhead for reasoning, but since the base model is V3, the throughput difference between V3 and R1 shouldn't be massive). The biggest factor is likely that V3's MoE architecture has started hitting the HBM capacity constraint of a single H800 (80GB).
If there is a V4 and it's still MoE, we can imagine what the situation will be.
The advantage of MoE is low resource overhead and high training/inference efficiency. But everything has a limit. If the hardware is stuck at H800, the future may not look so bright.
Some might say, can't everyone just give DS cards? Of course it helps, but as mentioned, the memory capacity limit of a single card is fixed, and the memory footprint and batch size under FP8 are set in stone.
The title on the first page of NVIDIA's CUDA introductory materials before the advent of ChatGPT was: Physics.
Can domestic compute power keep up? In the long run, certainly. But for the short term, please look at reality, and look at DS's suggestions for chip design in the V3 paper before discussing further.
Again: Physics.
Therefore, the rhetoric claiming "compute power is no longer important" is ultimately harmful to domestic model development (this is my primary motivation for writing this unconventional piece).
The third issue: MaaS (Model as a Service).
We previously discussed the threshold for replicating DS's theoretical yield: 200 and 1,000 H800s. I have long believed this might be the best hardware China can possess at scale for the foreseeable future.
The biggest driver for reducing model service costs will definitely be hardware upgrades.
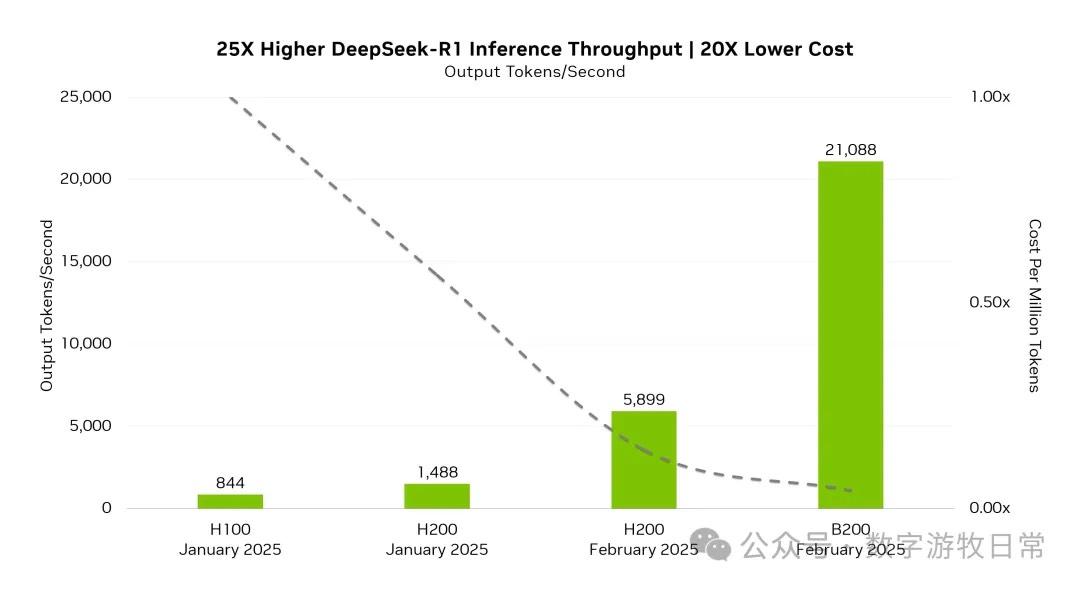
The image above shows the performance changes when NV optimized R1 inference, covering different times and hardware. I don't think the actual gap is that exaggerated, and Blackwell likely uses FP4 optimization. However, the generational gap is clearly visible. If this hardware base were given to the DS team for optimization, it could likely be improved several times over.
However, DS is unlikely to get high-spec Blackwell clusters for training, and domestic providers are unlikely to deploy such clusters for inference services (MaaS).
Today's "low prices" are likely at rock bottom. Unless H800s are continuously depreciated accounting-wise, inference costs might drop in a "financial sense." But who would be "bold" enough to use the best hardware for inference instead of training?
Nevertheless, compared to local deployment, MaaS services remain highly attractive: faster inference speed and lower overall costs. Currently, one should take full advantage of these subsidized services ("fleece the wool").
There will be many reasons given for local deployment, mainly data security. Perhaps what needs planning is the business process—actually sorting out which local data strictly requires a model instead of a simple program, and which "local data" is actually just internet data.
Technically, MaaS should be used whenever possible. Commercially, what is the flip side of "fleecing the wool"?
Finally, applications. We went through "Internet+", "AI+", and now "R1+". I wouldn't dare say much in the face of a major trend. I only have this personal experience: in the past two years, every time AI improved my efficiency, it was because the best model got better, or a better-than-best model appeared—like Claude 3.5 to 3.7, Gemini 2.0, or Deep Research.
However, I have a very basic observation: if no new applications were created based on the "best," can it be done based on the "catch-up"?
AI applications certainly have a broad future, but at this moment, a reverse filter can be applied: I will stay as far away as possible from those claiming their capabilities improved "so much just because of R1 integration."