The past week has been busy with both personal and professional matters, which has affected the frequency of updates (the frequency is expected to remain relatively low next week). However, many things did happen over the past week, so here is a quick overview.
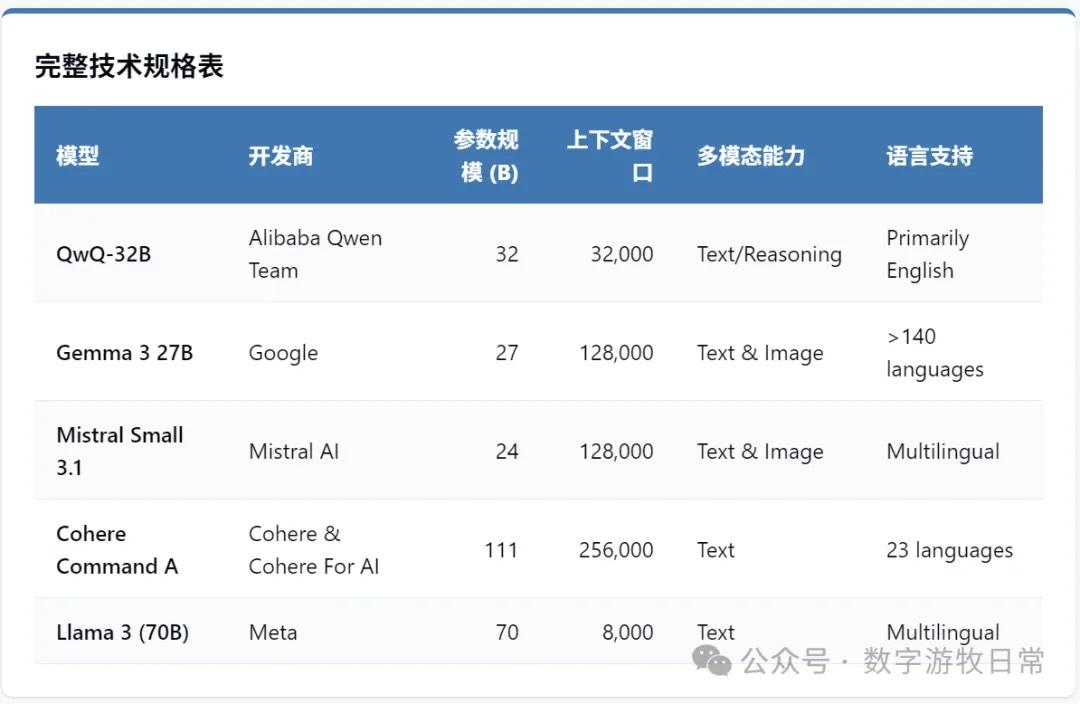
Model Level: Mainly two multi-modal models: Google's Gemma-3, Mistral's Mistral-Small 3.1, and an enterprise-facing one: Cohere's Command A. Their maximum parameter scales are 27B, 24B, and 111B, respectively. While evaluation results don't necessarily surpass GPT-4o or DeepSeek-R1 across the board, they definitely outperform Llama-3.1 405B. Furthermore, Gemma-3 and Mistral-Small 3.1 can be deployed on a single GPU.
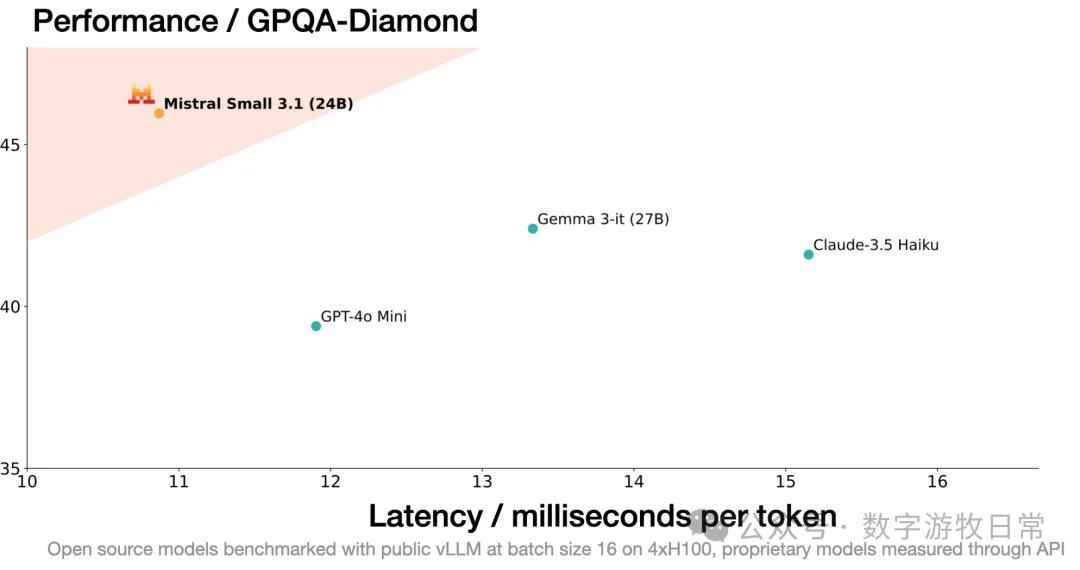
For these types of models, the greatest advancements are multi-modality and long context (128K or even 256K), which can create more local application scenarios. Regarding model capabilities, as I've said before, benchmarks are just for reference; the true capability of a model needs to be evaluated and adapted within continuous production environments.
Regarding NVIDIA's GTC 2025: in a nutshell, in the short term, it naturally fell short of expectations, but in the medium to long term, it is a positive development. I wrote part of this in my previous post: "When will the 'singularities' arrive? Written as NVIDIA GTC releases a new roadmap."
However, that piece was mixed with many other thoughts, primarily for clarifying my own ideas. If we were to simply summarize GTC:
Future product progress will likely fall short of market expectations and the more aggressive timeline NVIDIA provided last year.
However, against the backdrop of Blackwell's continuous delays due to a series of issues, such a roadmap might be more achievable, to some extent eliminating future uncertainty.
Regarding the so-called "computing power equality," top cloud providers are "voting with their actions," and I don't want to discuss it further. My "caution" regarding NVIDIA since the second half of last year stemmed more from its overly aggressive timeline and the market's excessively high expectations. Now that market expectations have cooled and the timeline has become more reasonable, it's a good thing.
NVIDIA's ambition is to be the "sole general infrastructure for AI computing," and they aren't hiding it at all anymore.
As for other software ecosystems beyond CUDA, we'll have to see. Many things are being built alongside downstream companies and cannot be considered entirely their own.
Finally, Gemini 2.0 has actually undergone a series of updates:
The viral Gemini-2.0-Flash now includes image and text capabilities: it seems I wasn't wrong three months ago when I said Gemini 2 would establish Google's dominance in 2025.
Secondly, the underlying model for Deep Research has been upgraded from 1.5 to 2.0. In many scenarios tested by my colleagues and me, it actually surpasses OpenAI's Deep Research.
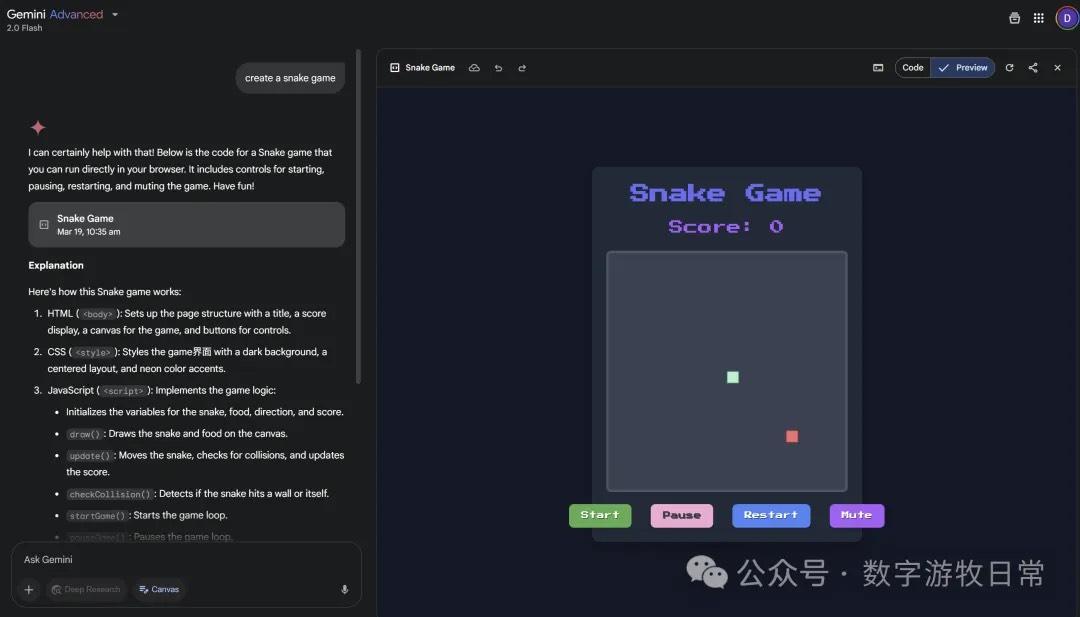
Canvas support has been added. The art style of the "Snake" game is quite good; the interactive PPT style is clean, though its effectiveness is still not quite as good as Claude 3.7.
Also, the voice blog feature from the hit product NotebookLM, AI Overview, has been added to the Gemini app.
Additionally, the aforementioned NotebookLM now includes a mind-mapping feature. I tried it out and it feels pretty good.
In summary: by now, the logic has become quite clear:
The true value of open-source models lies in localized scenarios, where the most important factors are data and business workflow transformation rather than the model itself, as open-source models primarily offer efficiency gains rather than quality breakthroughs.
Those with computing power (NVIDIA, Google) can act as they please.
Those with cutting-edge models (OpenAI, Google, Anthropic/Claude) are increasingly moving toward all-in-one direct productivity tools. The ultimate goal for "wrappers" might just be to get acquired.
All improvements in output quality boil down to two points: people and data—specifically "private data."