
After adjusting for a day or two, I've returned to the rhythm of desk work.
To be honest, Gemini 2.5-Pro has been out for a while, but I hadn't seriously tested it in a "production environment." Instead, I've been using the new GPT-4o for a lot of "image generation" tasks.
In a mobile context, ChatGPT and Claude are indeed more useful—one for Deep Research and "entertainment," the other for "visualization."
Of course, linking these models together can be quite interesting. For instance, using Gemini to analyze search history, then using Claude for visualization, or directly using the new GPT-4o for "image generation" yields varied results.
Take Claude 3.7's visualization effect, for example—it's a definitive productivity tool.
However, if you use the new GPT-4o, it's a completely different style.
Clearly, in terms of style, I naturally prefer the output of the new GPT-4o. Even if there are minor flaws due to token limits, one must admit that this quality is infinitely close to "professional-grade" entertainment needs.
Indeed, ChatGPT remains the model with the highest daily active users and the most comprehensive capabilities:
- In almost any scenario, ChatGPT provides respectable results. It's a curious phenomenon: every time OpenAI releases a new model or a competitor tries to "dethrone" them, ChatGPT sees an even faster increase in daily active users.
- Whether OpenAI's Deep Research is a relatively independent model or not, it still provides the most comprehensive and complete answers to every question. Relatively speaking, due to search "bottlenecks," its source citations and "freshness" are not as strong as Deep Research powered by Gemini 2.0 (though Gemini's Deep Research output can be a bit short and long prompts can cause attention drift).
- The new GPT-4o's terrifying image generation capability isn't just about Ghibli styles; it can be a powerhouse for poster creation. Honestly, I believe it outperforms 99% of people.

- OpenAI's next secret weapon might be the "World Model" hidden behind the scenes. While the process of generating bit by bit from top to bottom feels a bit "deliberate," the increased demand for computing power is likely a reality. I'm just curious: which requires more tokens—text expressed as images, or text expressed as text?
- Going heavy on "memes" isn't just for fun; "Model as Application" is the ambition that is now being displayed without reservation.
In productivity, image generation is just a small part. Document processing is a very important high-frequency scenario. Since Gemini 1.5 introduced million-token context support, the Gemini series has been my most important document processing tool—a diligent workhorse.
However, while the input context is a million tokens, the output context is still limited to 8K. So, to fully summarize a several-hundred-page book, the best way is to go chapter by chapter. Gemini's status as a "workhorse" is proven by the fact it actually can handle this chapter-by-chapter work diligently.
Now, with the release of Gemini 2.5-Pro, what attracts me isn't some reasoning model, but the 64K output context—a major upgrade for a productivity tool.
For example, when processing CATL's 2024 annual report (over 200 pages).
The reasoning process looks like this:
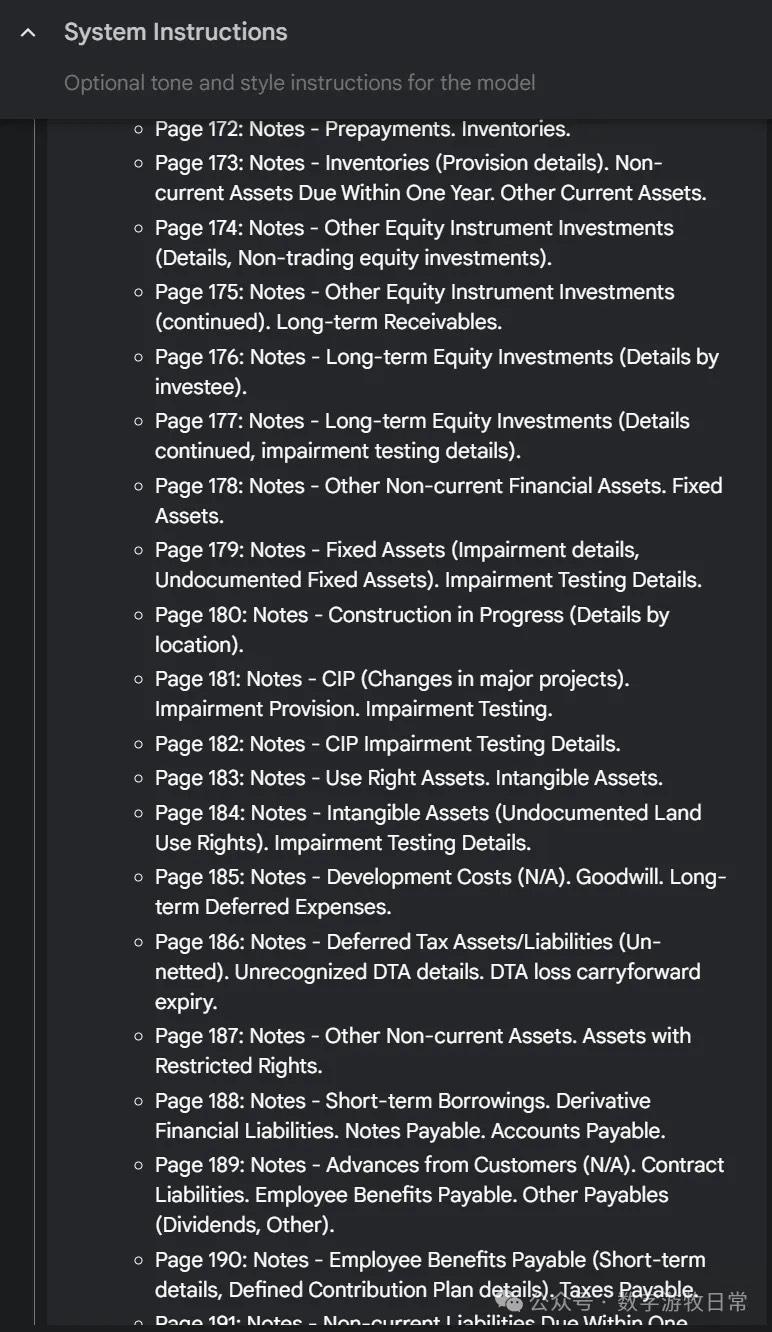
It truly processes page by page, "thinking" its way through.
And the results can reach this level of granularity:
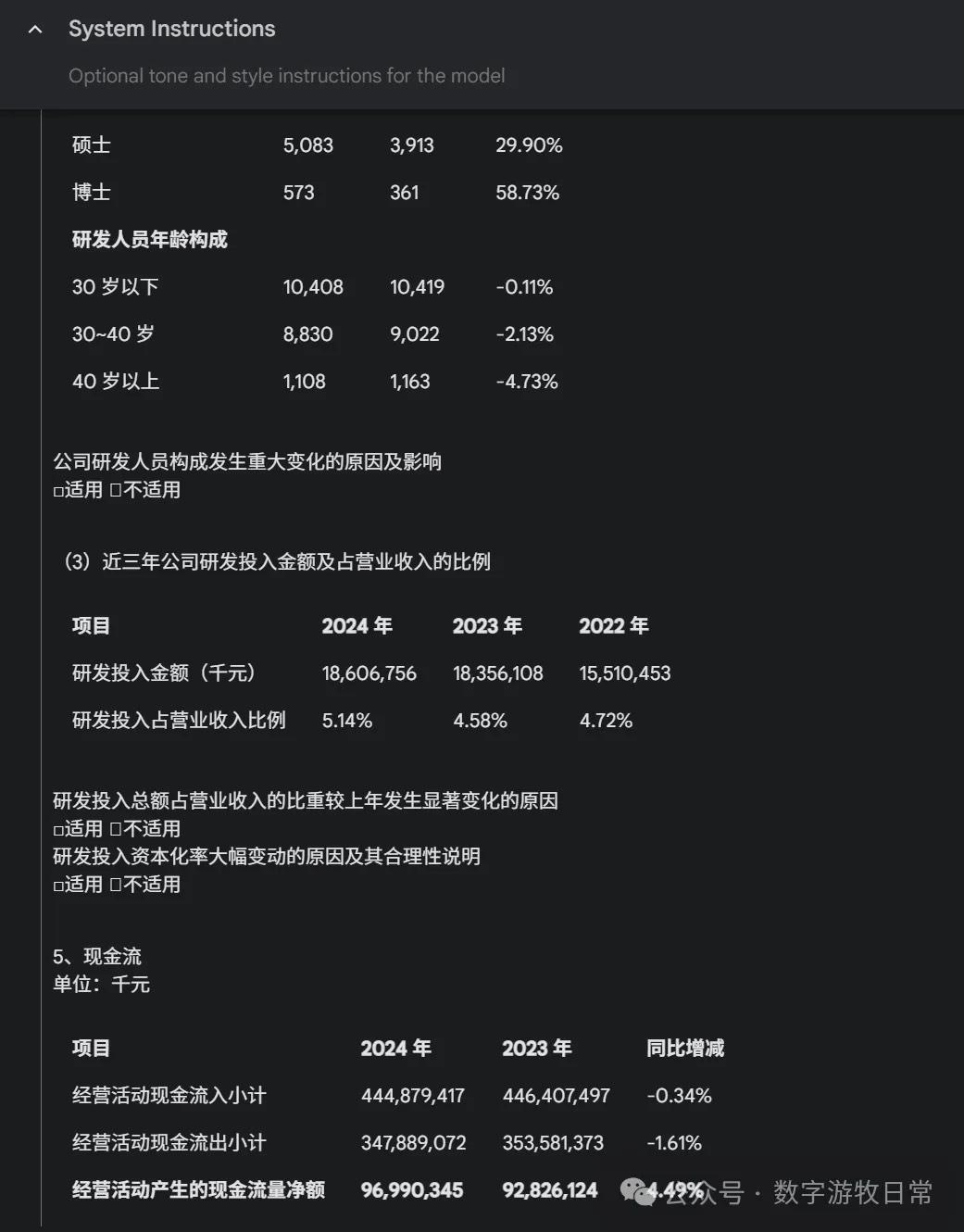
The full output exceeded 25K tokens.
Yes, it is that powerful—uniquely powerful.
Of course, you can generate an interactive analysis report in a single conversation, with a cover as shown below.

However, I still habitually used my established Claude 3.7 workflow to finish it.
Yet, even with a very mature workflow template, the generated results failed: if we go by the chart units (hundred million CNY), was CATL's 2022 revenue only 329 million CNY?
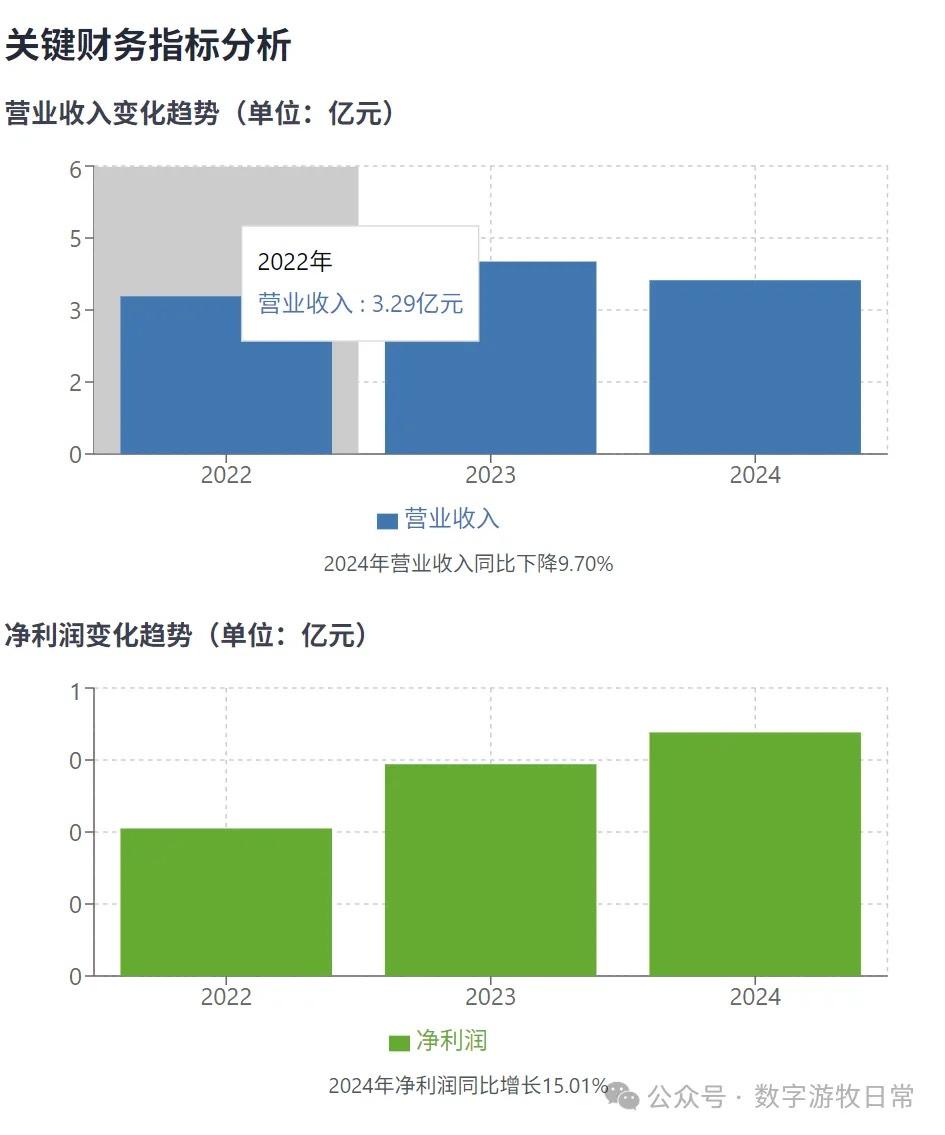
The problem was the scale. The unit in the financial report is "thousand CNY," so the numbers in the code data were written in thousands—meaning the 2022 revenue should be 328.6 billion CNY.
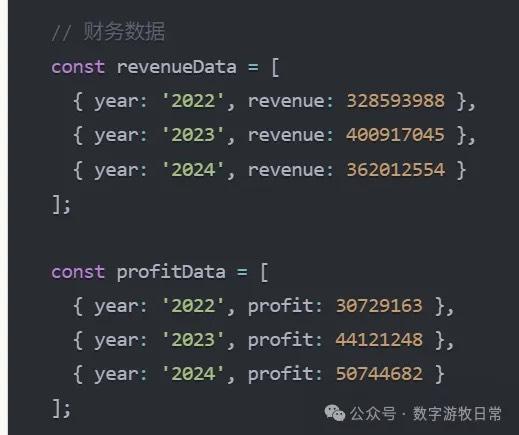
The model missed the scale and then, in the chart code, processed it as if it were in hundred millions.
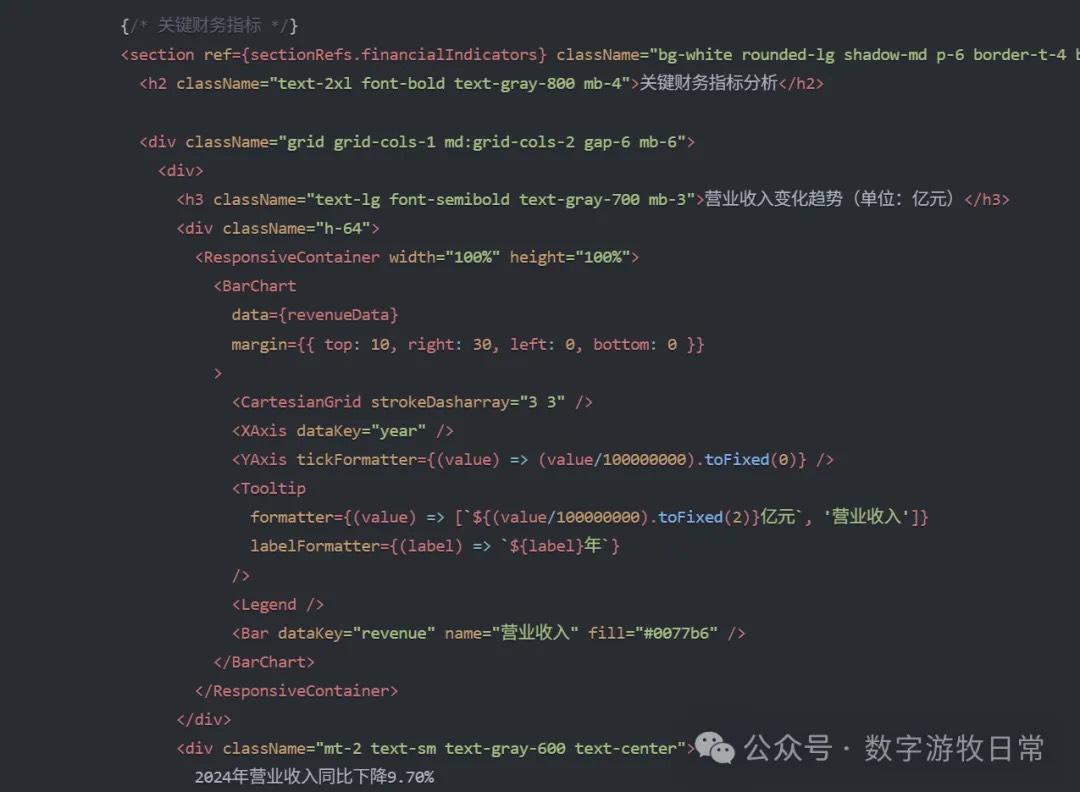
It's a scary error. Whether this qualifies as a "hallucination" is debatable; it's more likely due to Claude 3.7's limited context length.
However, this means that even Claude 3.7, which is so outstanding in coding ability, can still make very low-level mistakes at any time.
In my previous applications, Claude has made other low-level errors as well. It seems that, for now, "human-in-the-loop" remains a crucial process.
Yes, the models are getting better every day. Every discovery of a model's error or shortcoming is actually because we have taken another step forward.
Indeed, the foundation of a world where "everything is computation" is rapidly becoming solid.