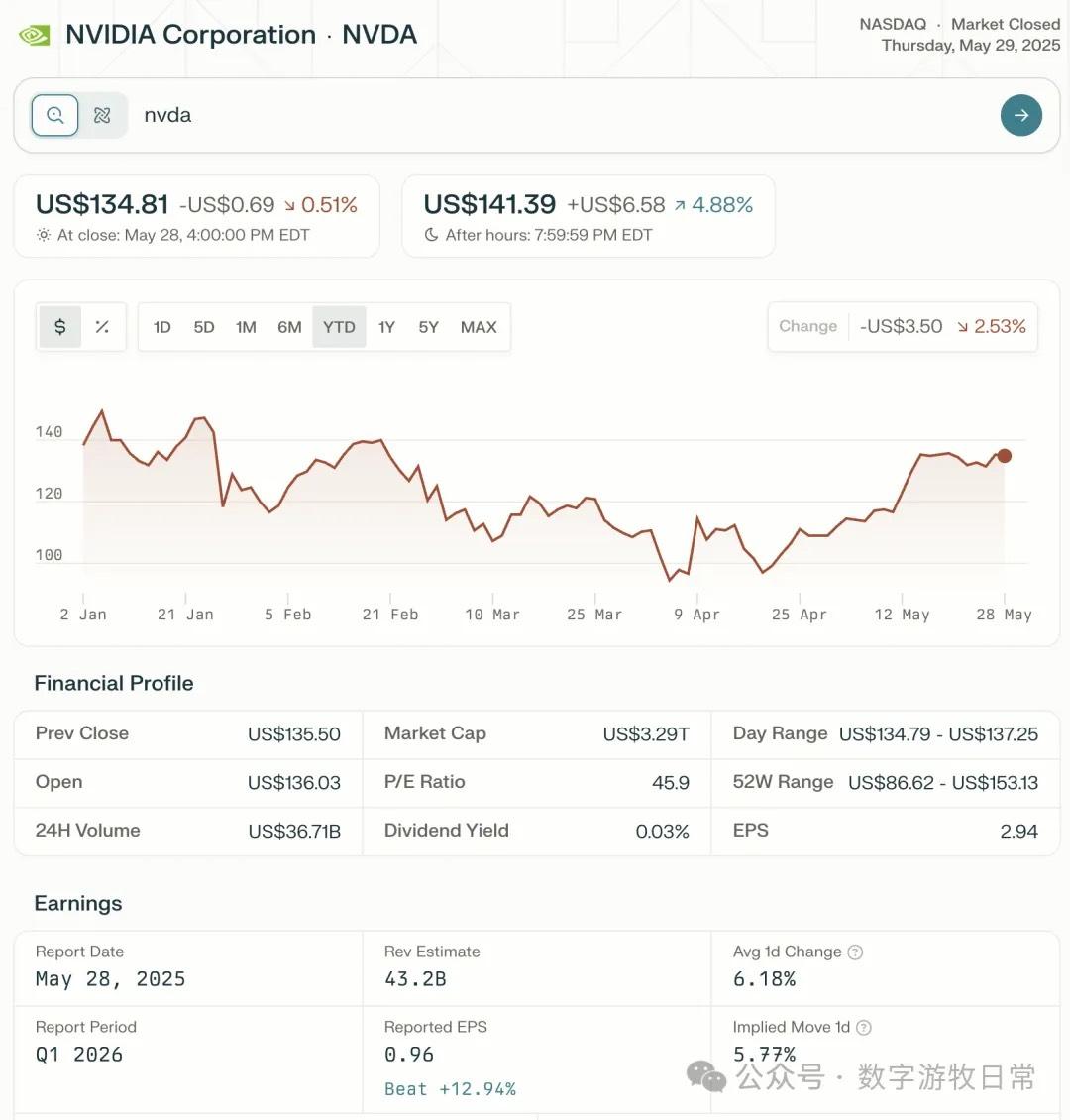
比较几个模型对英伟达的财报分析:这是为什么我更偏好 Gemini 2.5 和 Claude 3.7 的原因
全市场最重要的财报,英伟达 FY26Q1,终于发布了。
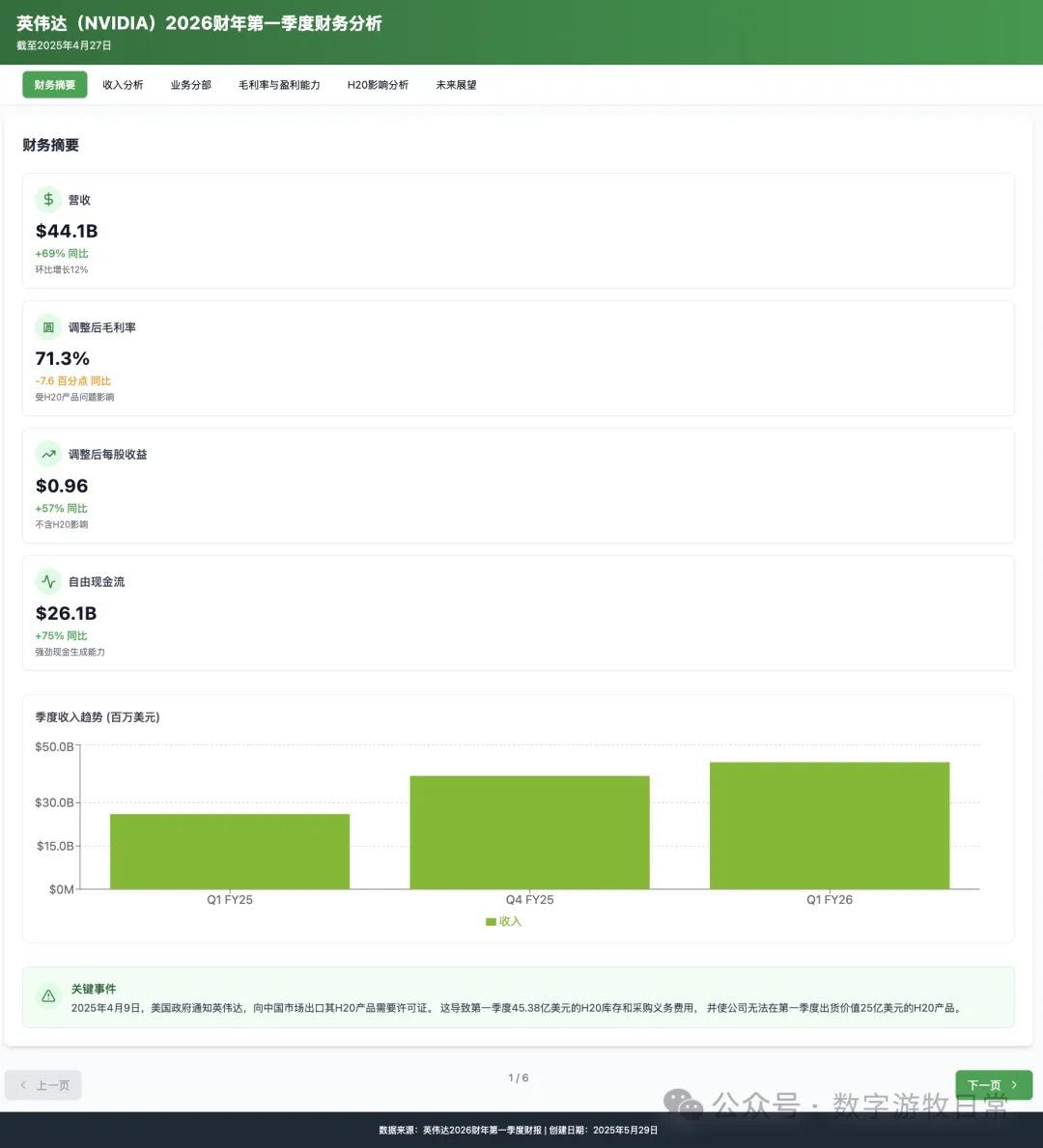
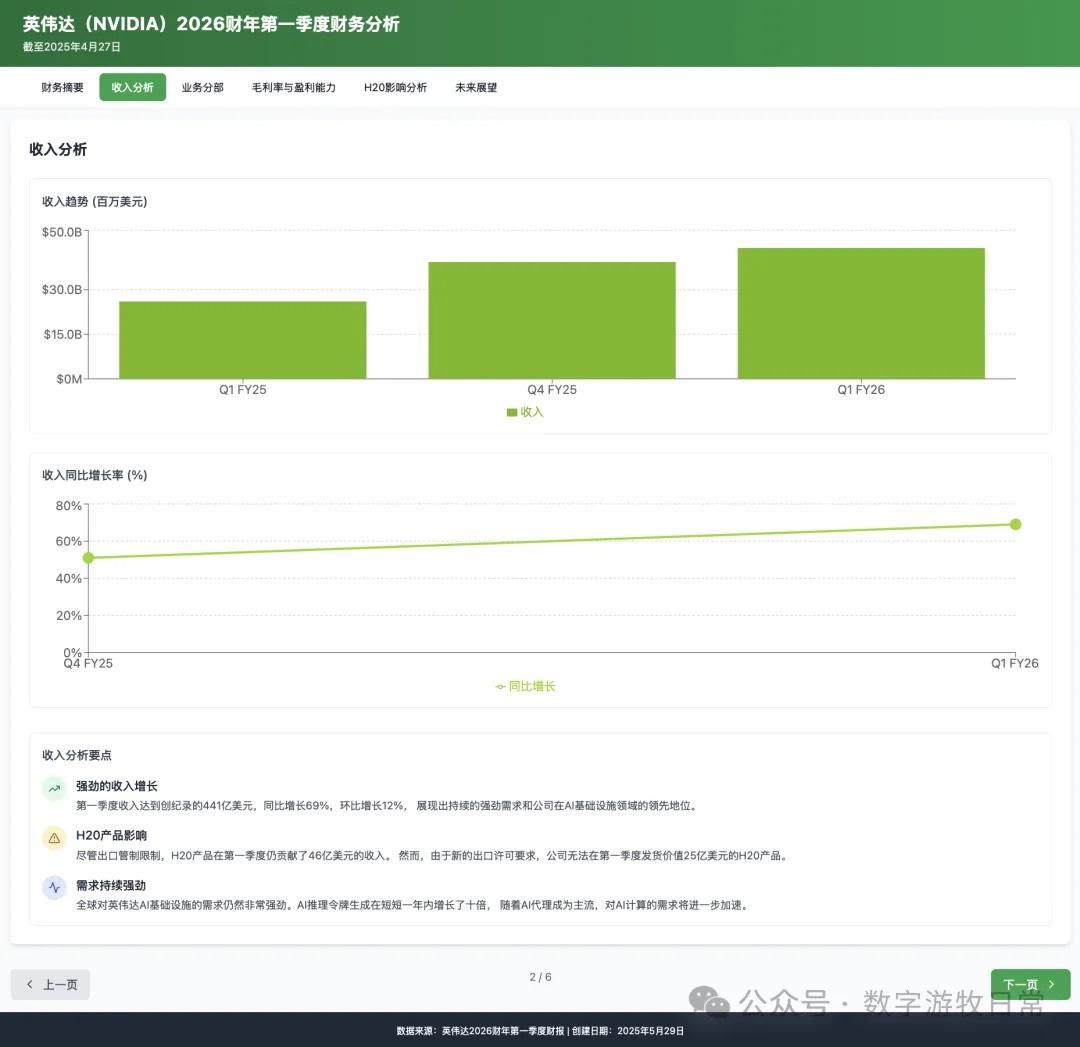
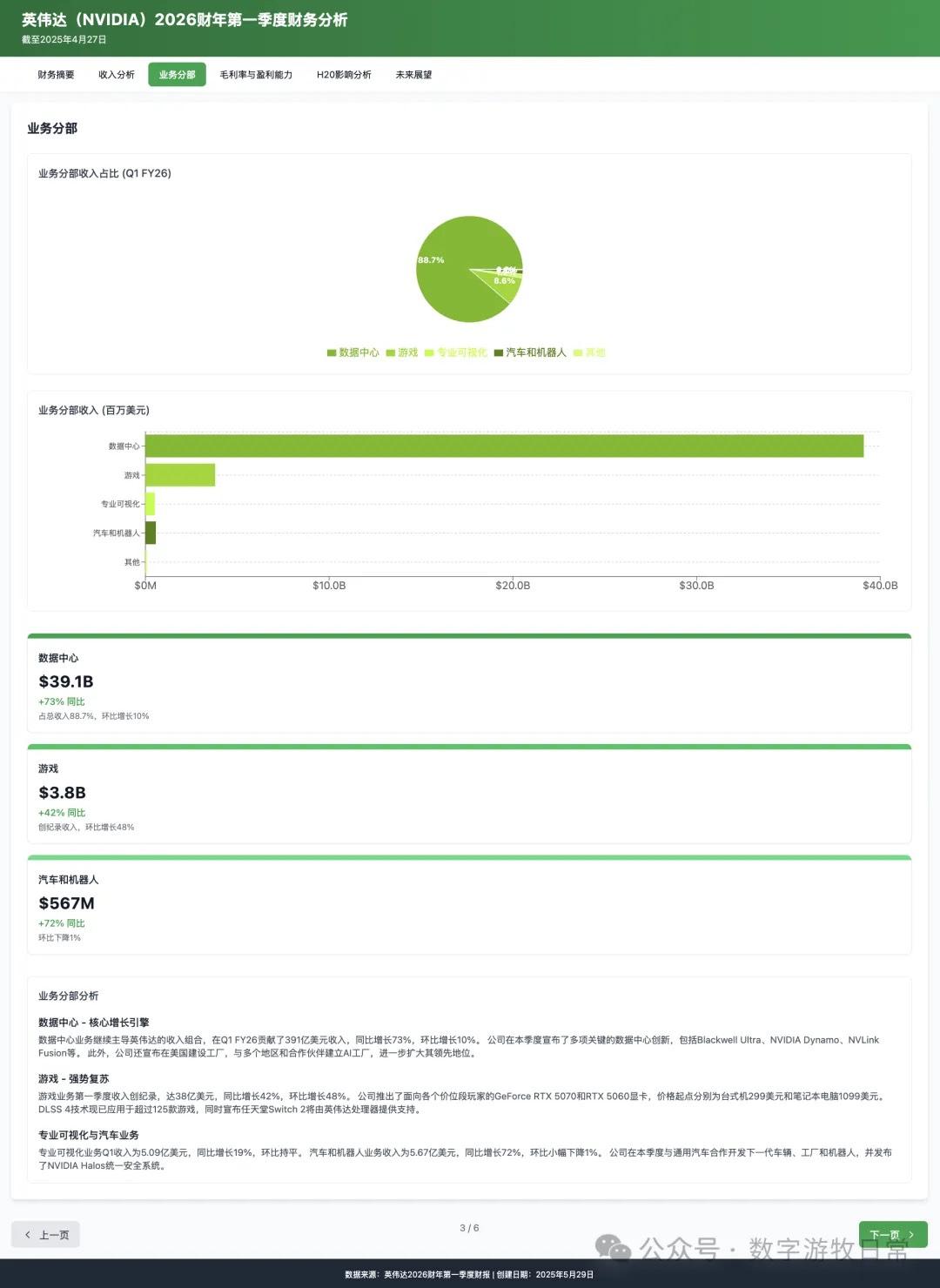
虽然有 H20 存货减值的影响,但在 NV 高超的存货与预期管理下,表现继续超预期了。市场就是这样,同样的超预期和“乐观指引”,有时候信,有时候就不信,关乎“情绪”。
这个时间点,信息过载的环境下,各种财报分析早就满天飞了:分析师们都会强调一句“超过市场预期,但是完全符合我们预期”。
在公众号里进行主观的投资分析,总是有“不合规”的嫌疑。时值一直在比较 Claude-4 和其他模型(实话说,总觉得 Claude-4 是一个有点奇怪的模型),索性就把财务分析交给这些模型了。
我用同样的提示词比较了 Claude-4-Opus,Claude-4-Sonnet,Claude-3.7-Sonnet,Gemini-2.5-Pro,GPT-o3。
提示词非常简单,就是基于英伟达的官方信息(https://nvidianews.nvidia.com/news/nvidia-announces-financial-results-for-first-quarter-fiscal-2026),生成一个富有细节的可交互的中文幻灯片。(评论区又会有声音,老是评价幻灯片生成能力,根本就是对模型的以偏概全。也许吧,但是生成幻灯片的过程,即考察模型的思考能力,又考察模型的幻觉率,当然还考察模型的代码能力,最重要的是能直接用。难道,我们真的敢让模型完全包办后端的代码吗?AI 代码改变软件工程的最重要基础不是超越多少程序员,而是它以一种“日抛型”的方式进入到各行各业的生产尤其是知识生产工作中。对了,AGI 和现在的生成式 AI,是两个东西,或许,生成式 AI 连 AGI 的必要条件都不是。所以,别低估更别神话如今的模型)。
先看 Claude-4-Opus 的截图结果(基于一些原因,我去掉了一些敏感内容,同时,基于“合规”考虑,去掉了投资建议里的评级)。


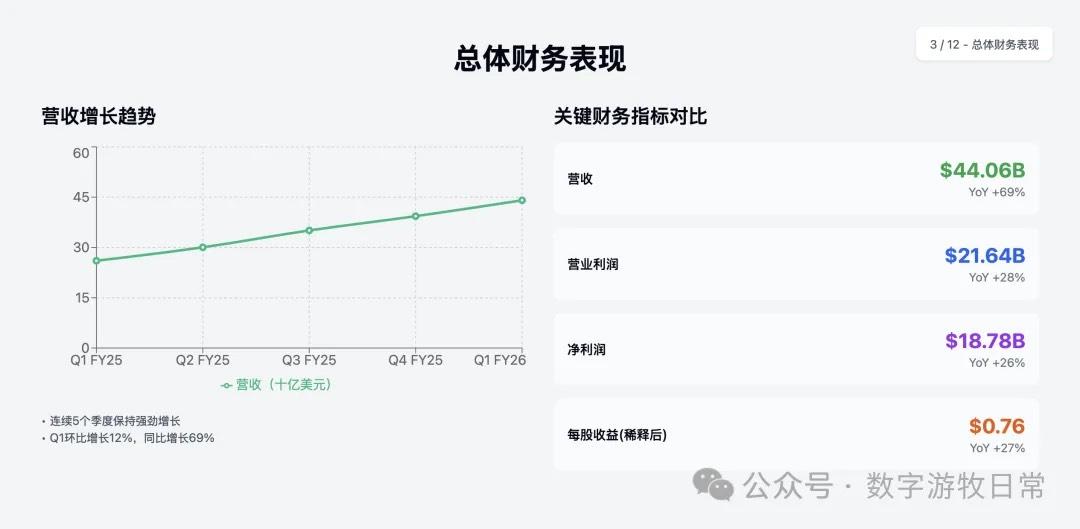
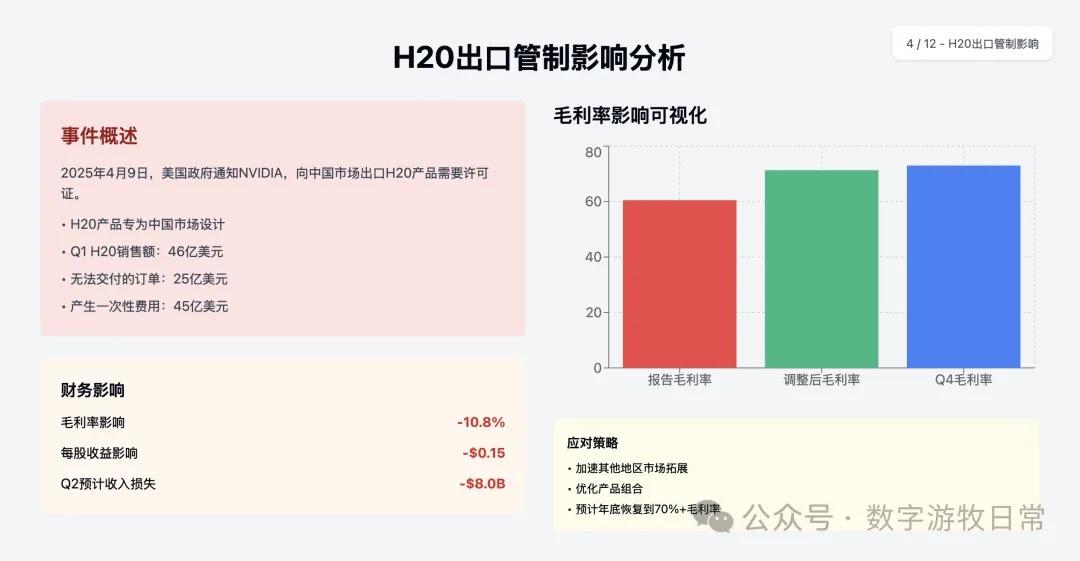
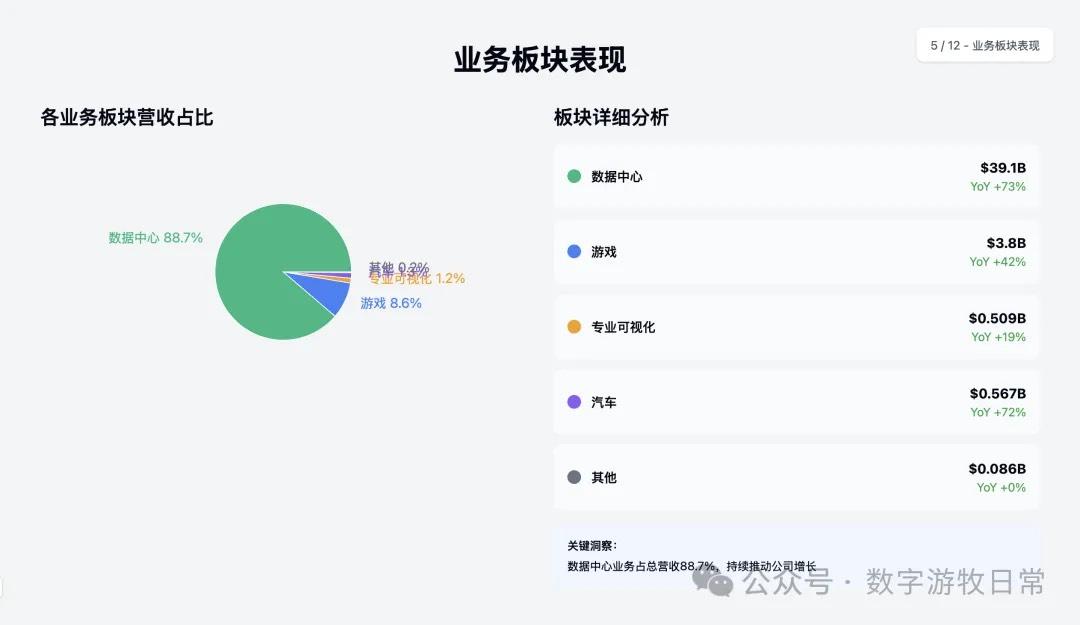





下面是 Claude-4-Sonnet 的结果(同样,我去掉了具体的投资建议部分)。
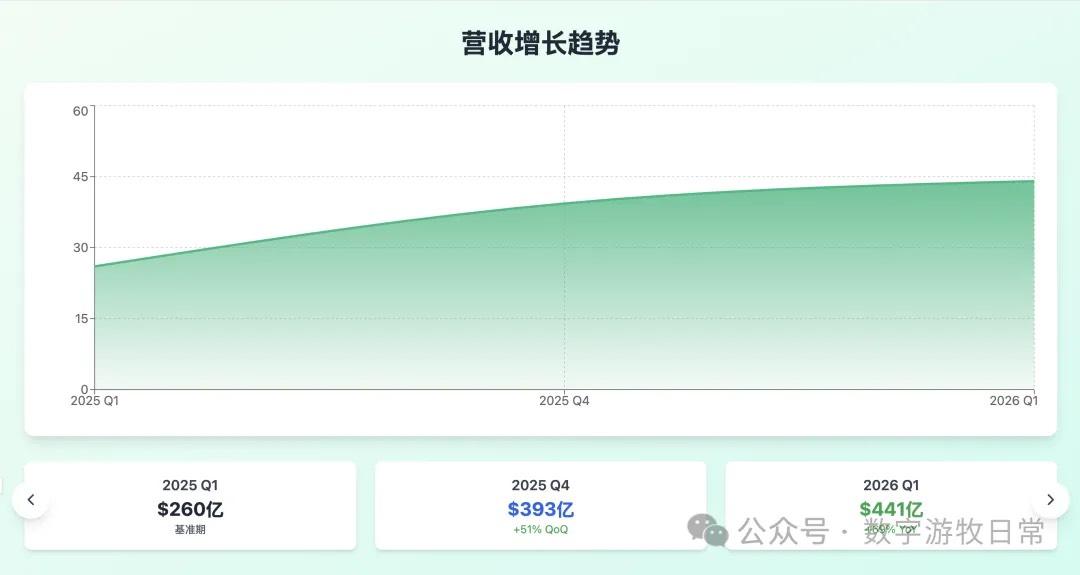
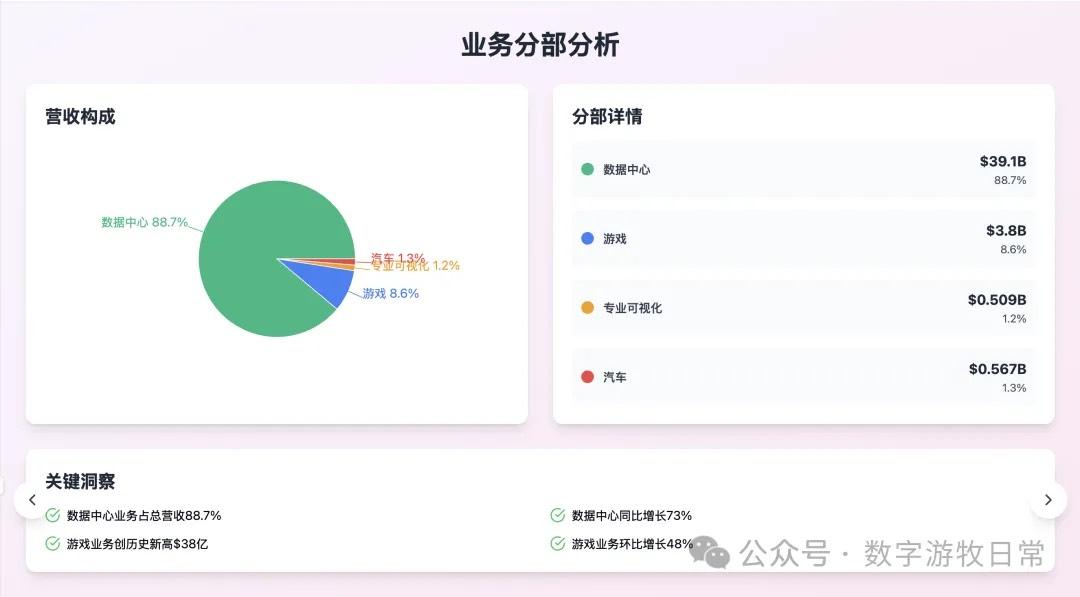

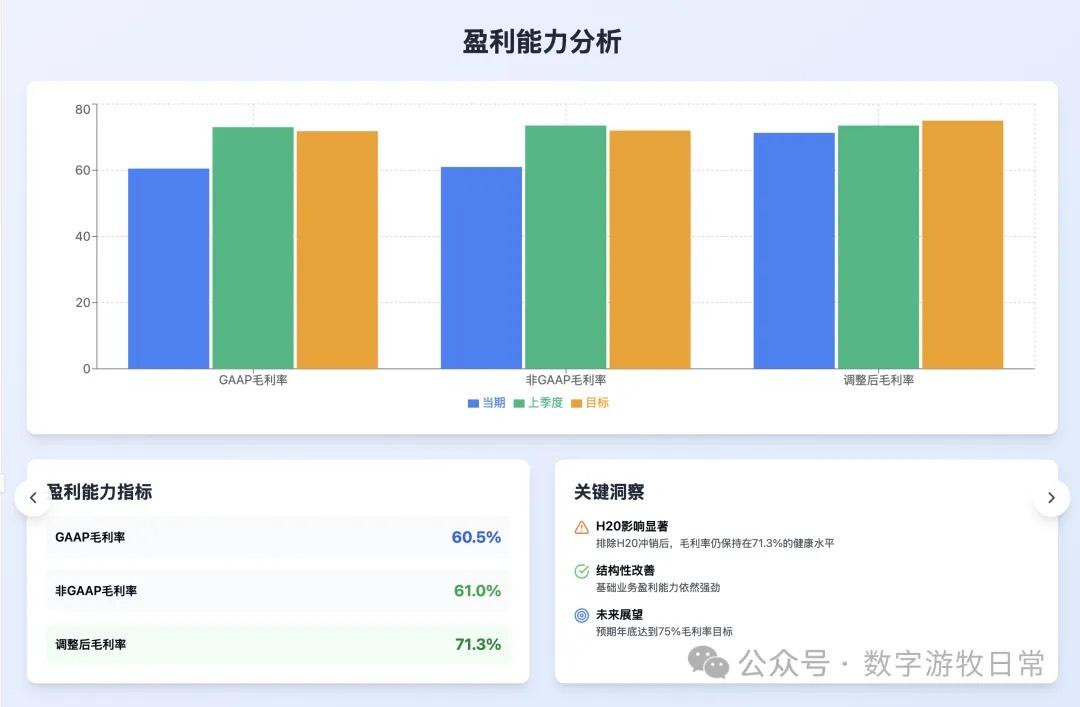

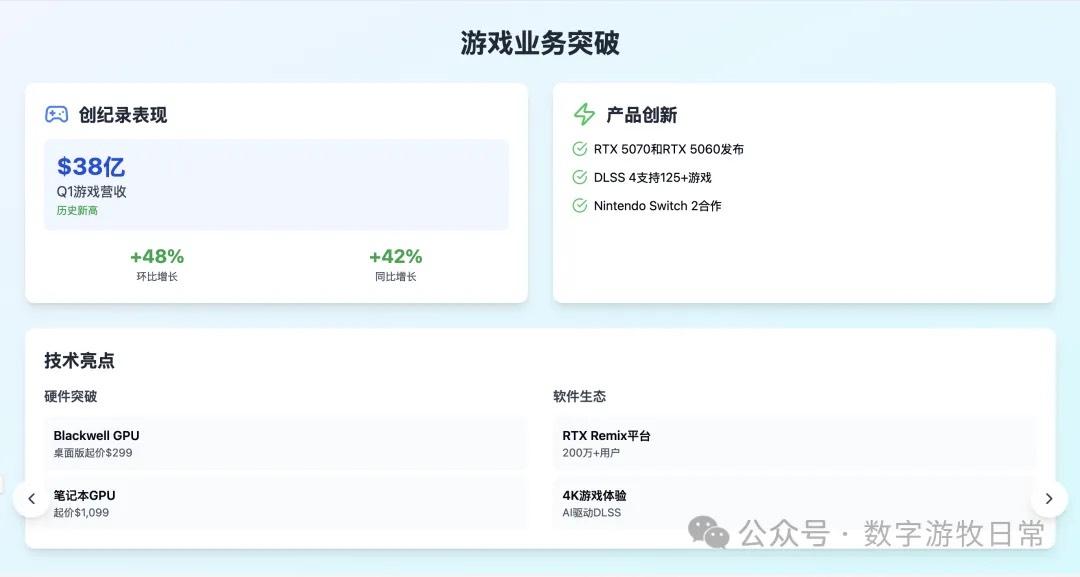



第三个模型是 Claude-3.7-Sonnet(去掉敏感内容一处)。
就 Claude 系列的三个模型对比:Claude-4-Sonnet 作为 Claude-4-Opus 的“低配版”,显然“风格一致,细节更少”。
重点要比较的是 Claude-4-Opus 和 Claude-3.7-Sonnet:
1、如果仅从幻灯片(Slides)这个指令要求的角度出发,Claude-4-Opus 会更贴近:大小、内容和布局更符合 PPT 的要求,Claude-3.7-Sonnet 更像网页。在一些线下交流中,确实有朋友反映 Claude-3.7-Sonnet 生成的内容在投影时候看不清楚。所以,形式上的用户体验,Claude-4 确实更好;
2、但是从内容而言,Claude-3.7-Sonnet 显然包含的信息量更多,更忠实于原始素材;
3、在这个例子中,我并不喜欢 Claude-4 在最后给出了投资建议,是的,一方面可以表明它“聪明”,毕竟财务分析主要目的就是为了产生投资建议。但如果说在幻灯片的布局上 Claude-4 是“克制”的,那么这个多出来的投资建议就是“不克制”的;
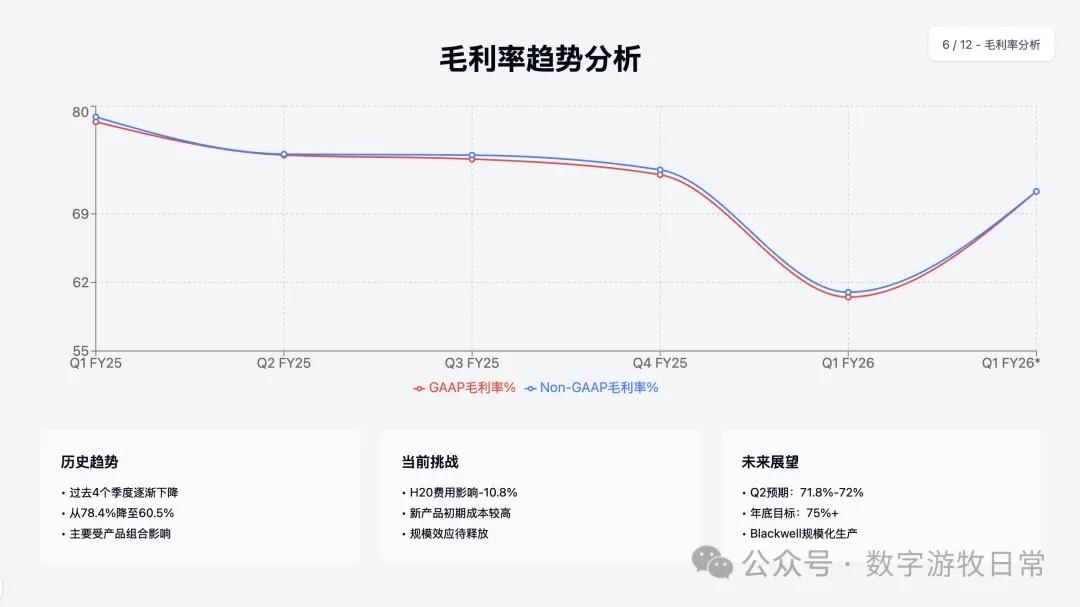
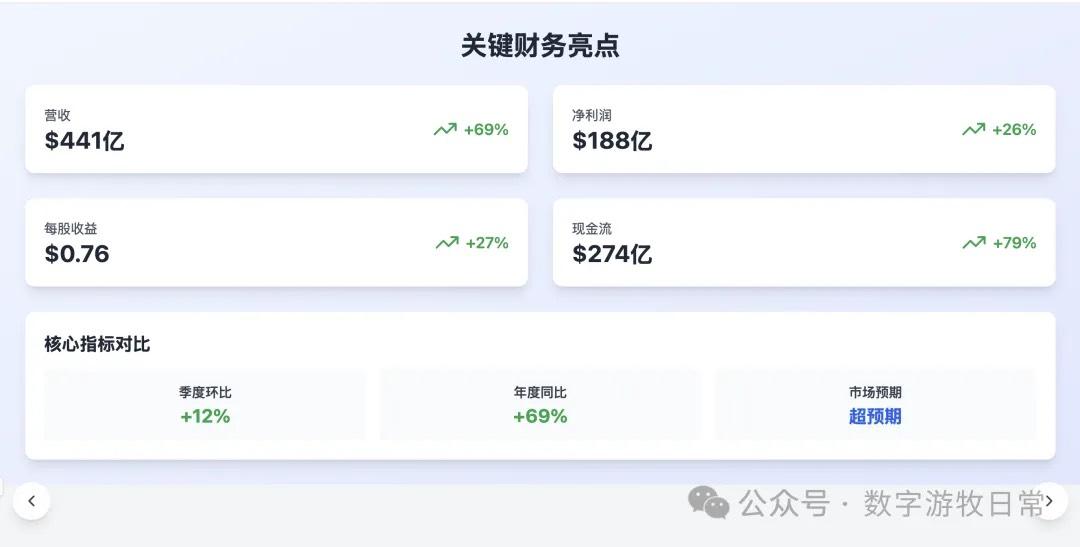
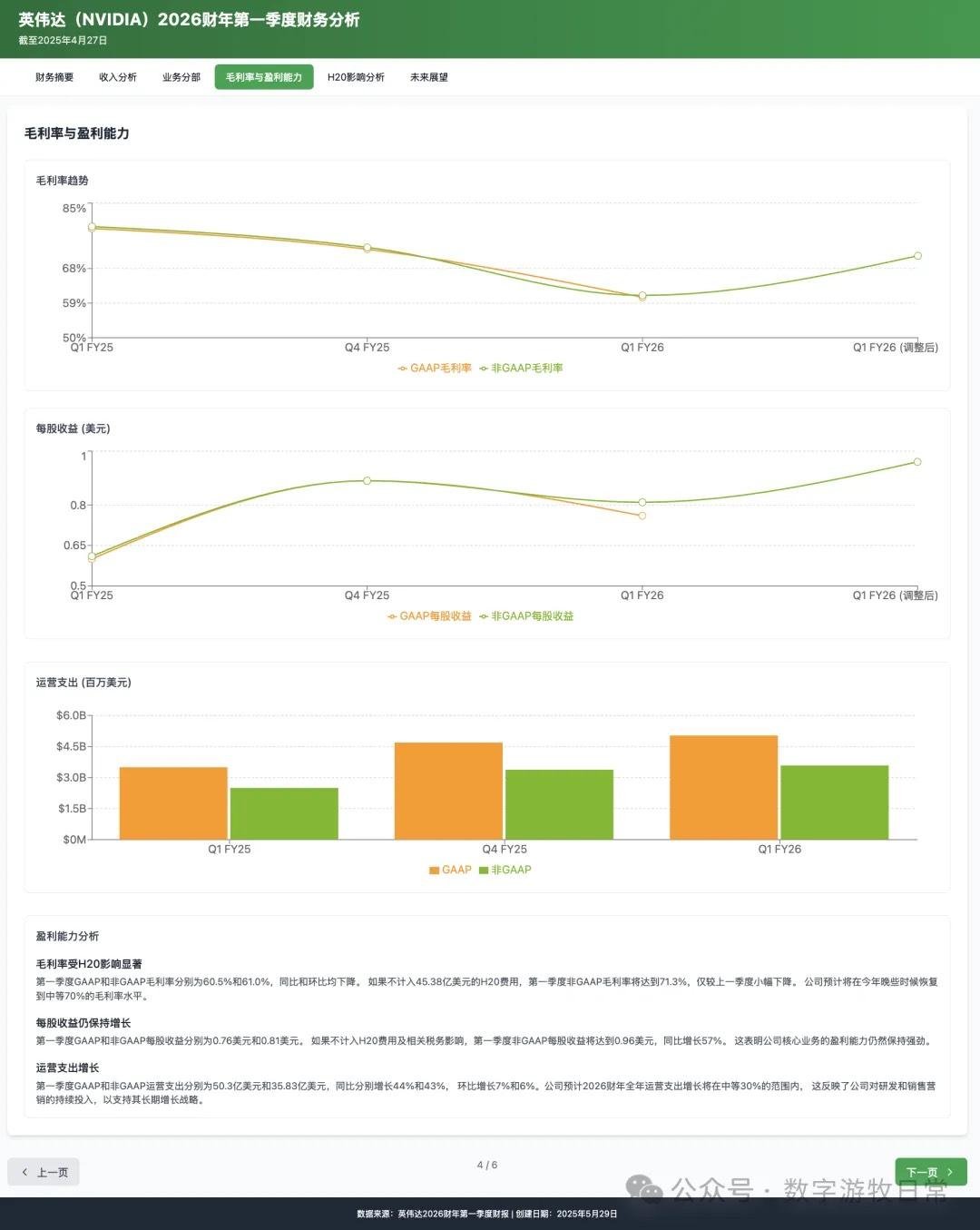
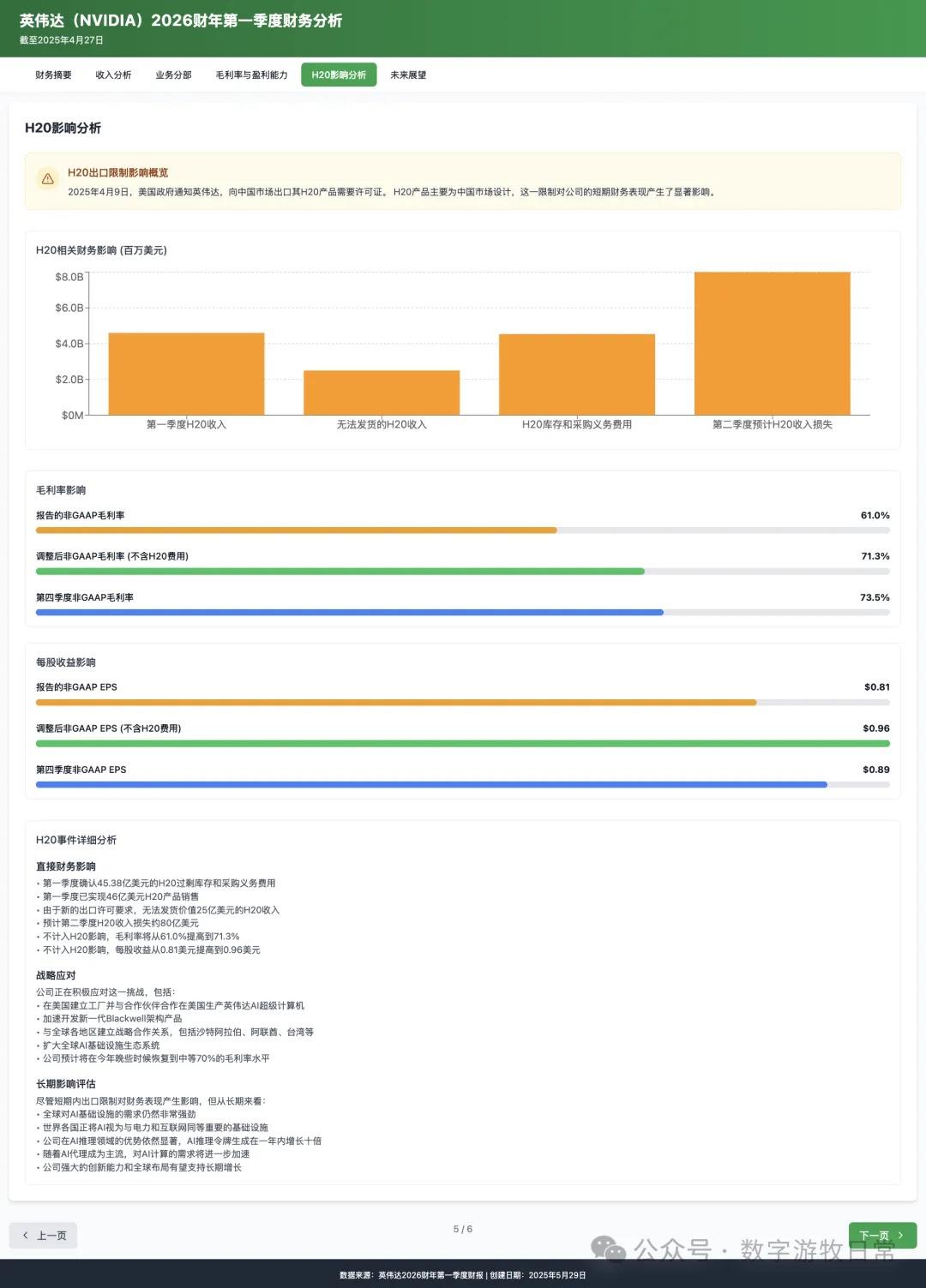
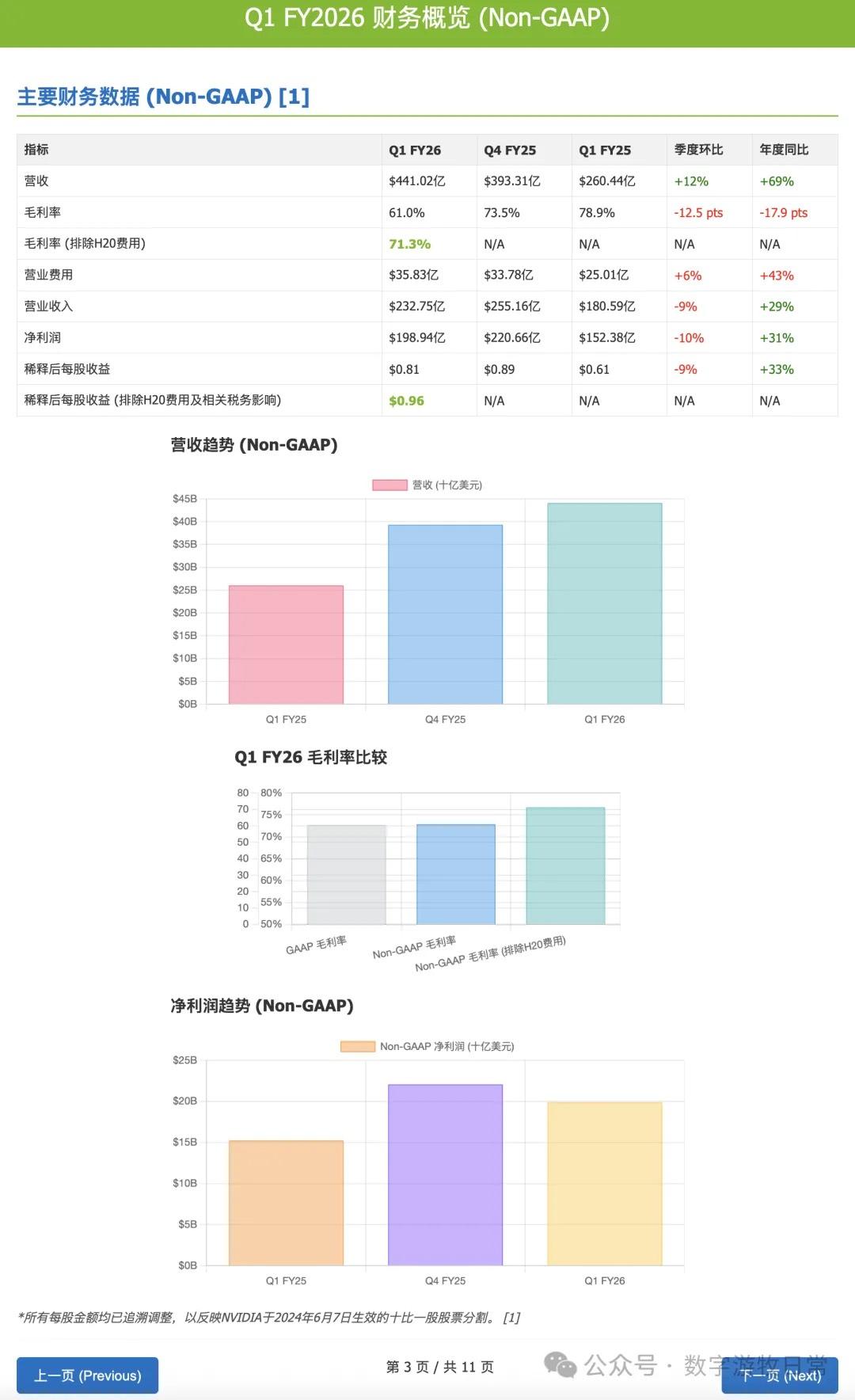
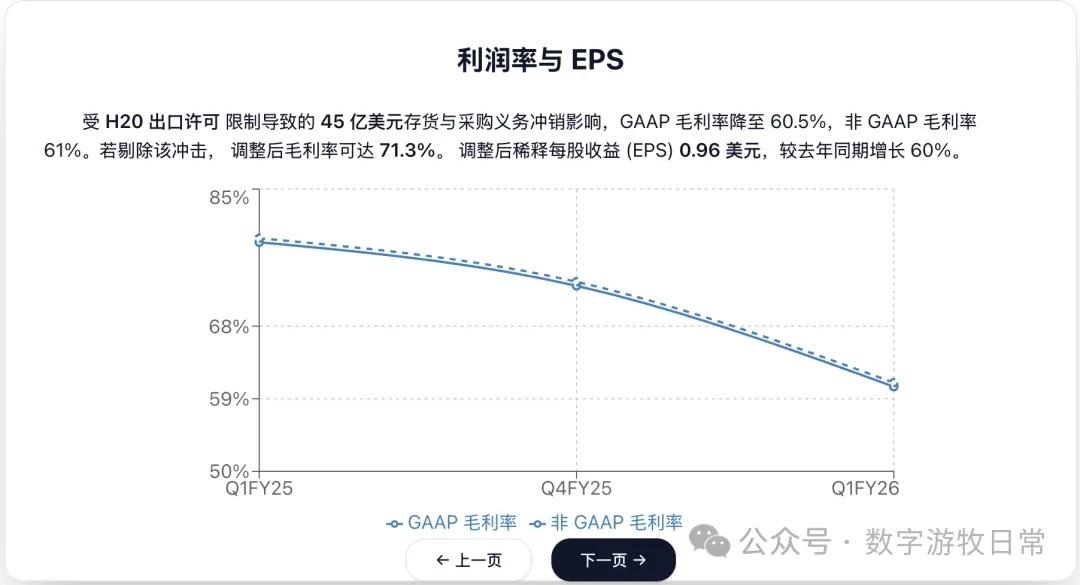
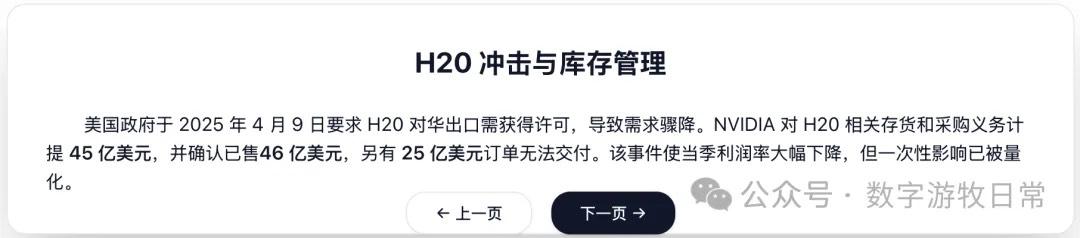
4、如果再看更多的具体内容,只有 Claude-3.7-Sonnet 能把原文中关于 H20 带来的影响分析的清清楚楚:尤其是 EPS 影响,在英伟达官方信息里,给出了三个 EPS,GAAP 是 0.76,Non-GAAP 是 0.81,去除 H20 影响后的 Non-GAAP 是 0.96。作为财报里最重要的讨论因素之一,只有 Claude-3.7 进行了严格的区分和说明;
5、当然,我准备再给 Claude-4 一次机会,区分是不是因为“extended thinking”影响了模型的倾向性(其实,Claude-3.7-sonnet 也开启了 extended-thinking)。我尝试关掉这个选项再来一遍,可惜,又一次超出 limit 了。但是,我从昨天到今天仅开启了三个对话,就是上面三个,也许 Anthropic 的限制是 token 数?

这种体验,不会让我重回 Max 订阅,而会促使我结束 Pro 订阅。
更多的主观结论留待文章最后。先快速过完另外两个模型的结果,首先是 Gemini-2.5-Pro。




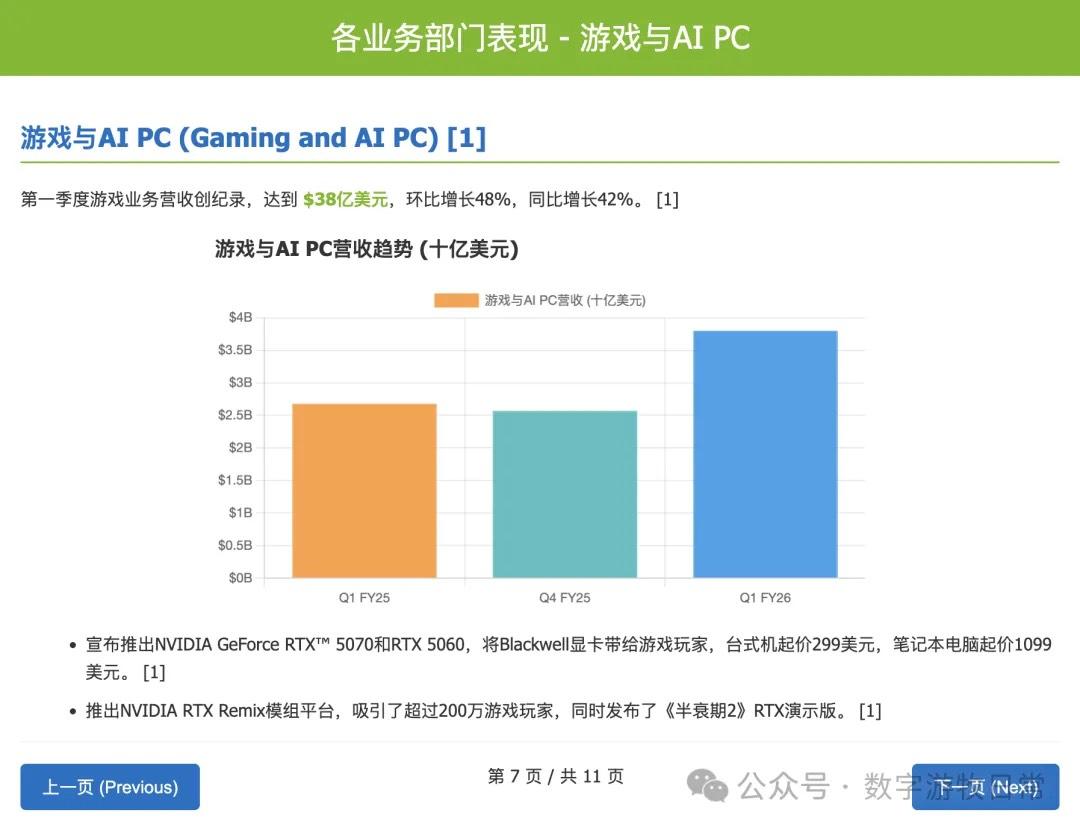
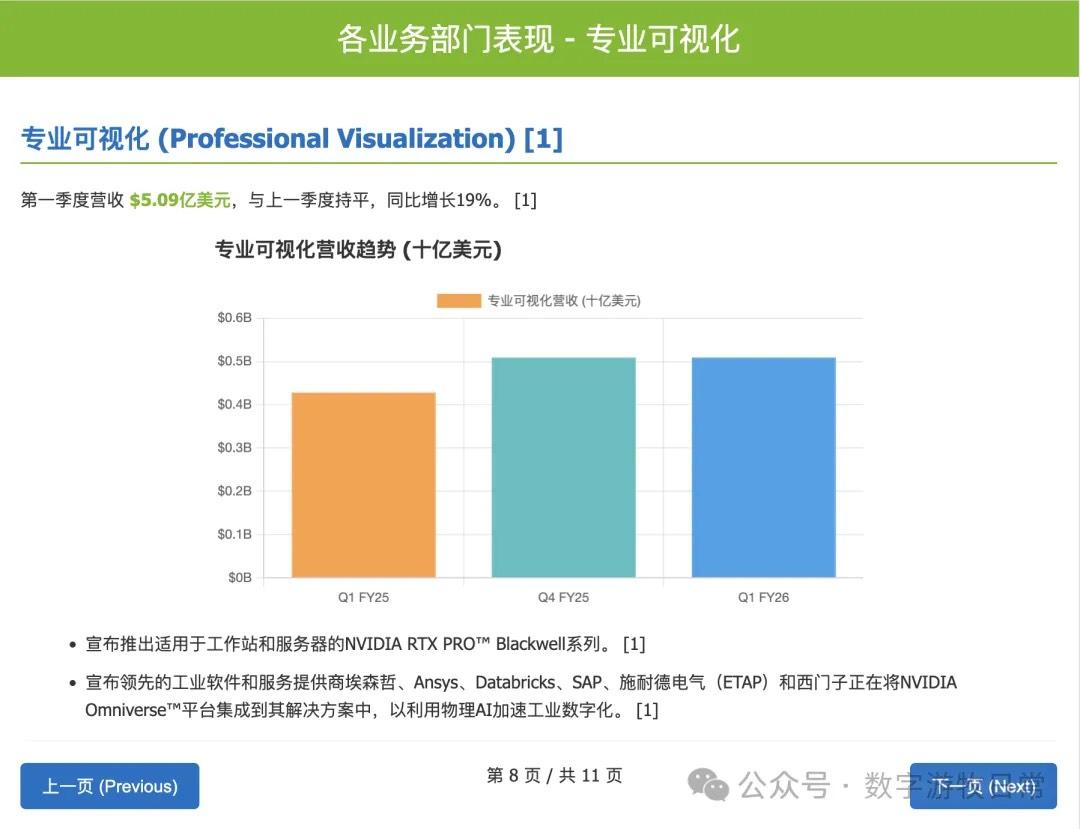
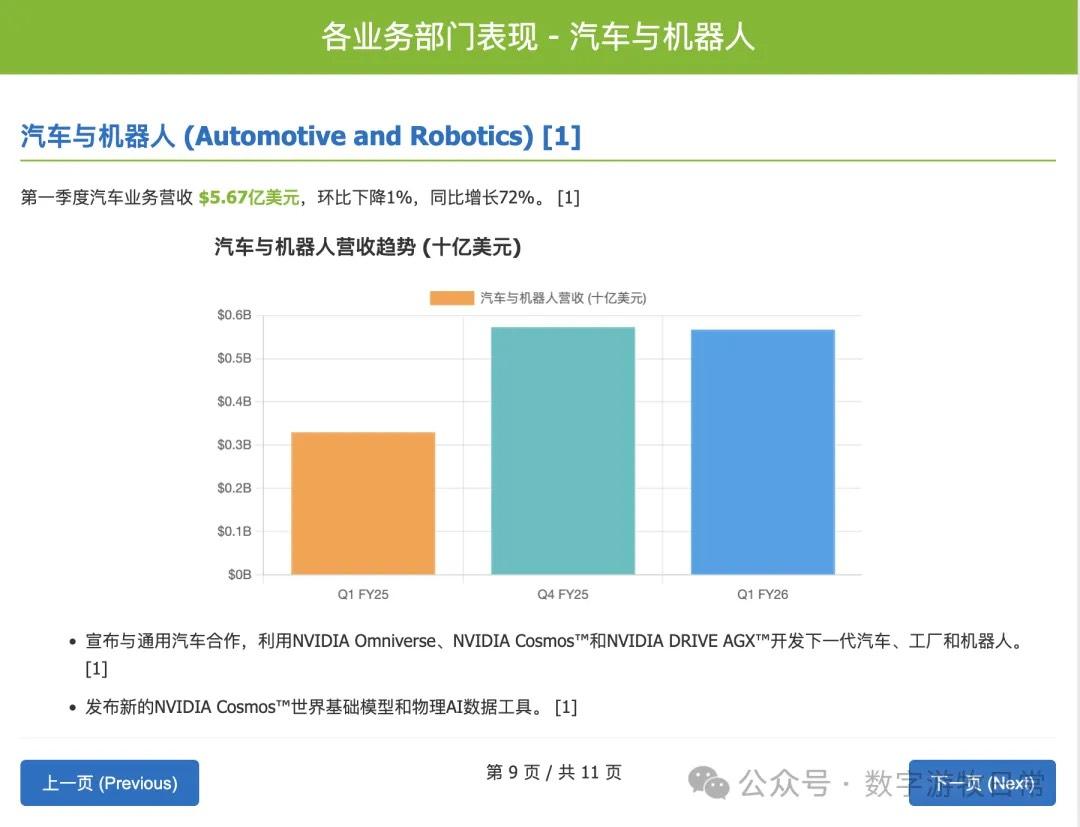
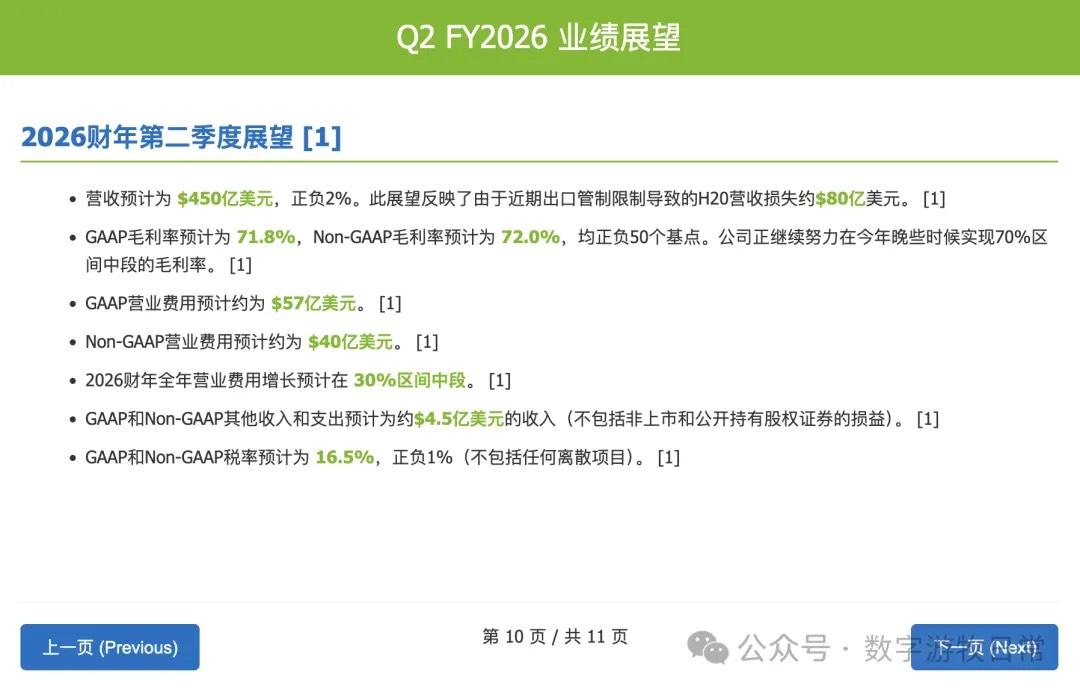
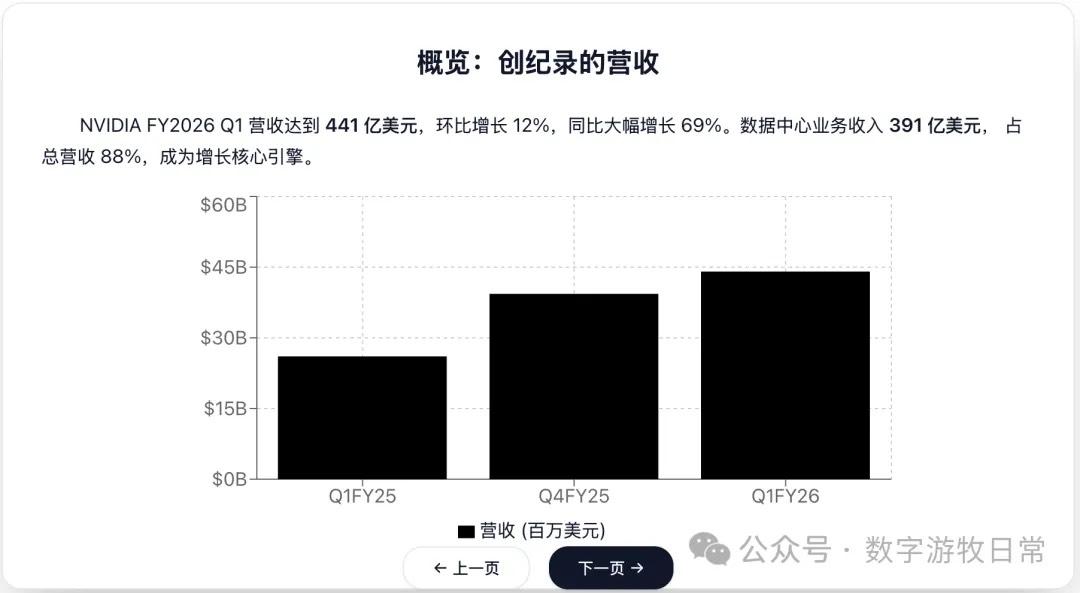
然后是 OpenAI 的 GPT-o3。



嗯,结束了,总有种“山寨感”。
以上是五个模型的输出结果,是的,生成幻灯片只能是一个很小的测试,但如我之前所说,它其实考察了模型的多方面能力,而且很“实战”。当然“山寨感”可能更多来自于不同模型对于输出信息量倾向性的设定,至少不能作为最重要的评判指标。
谈主观感受。
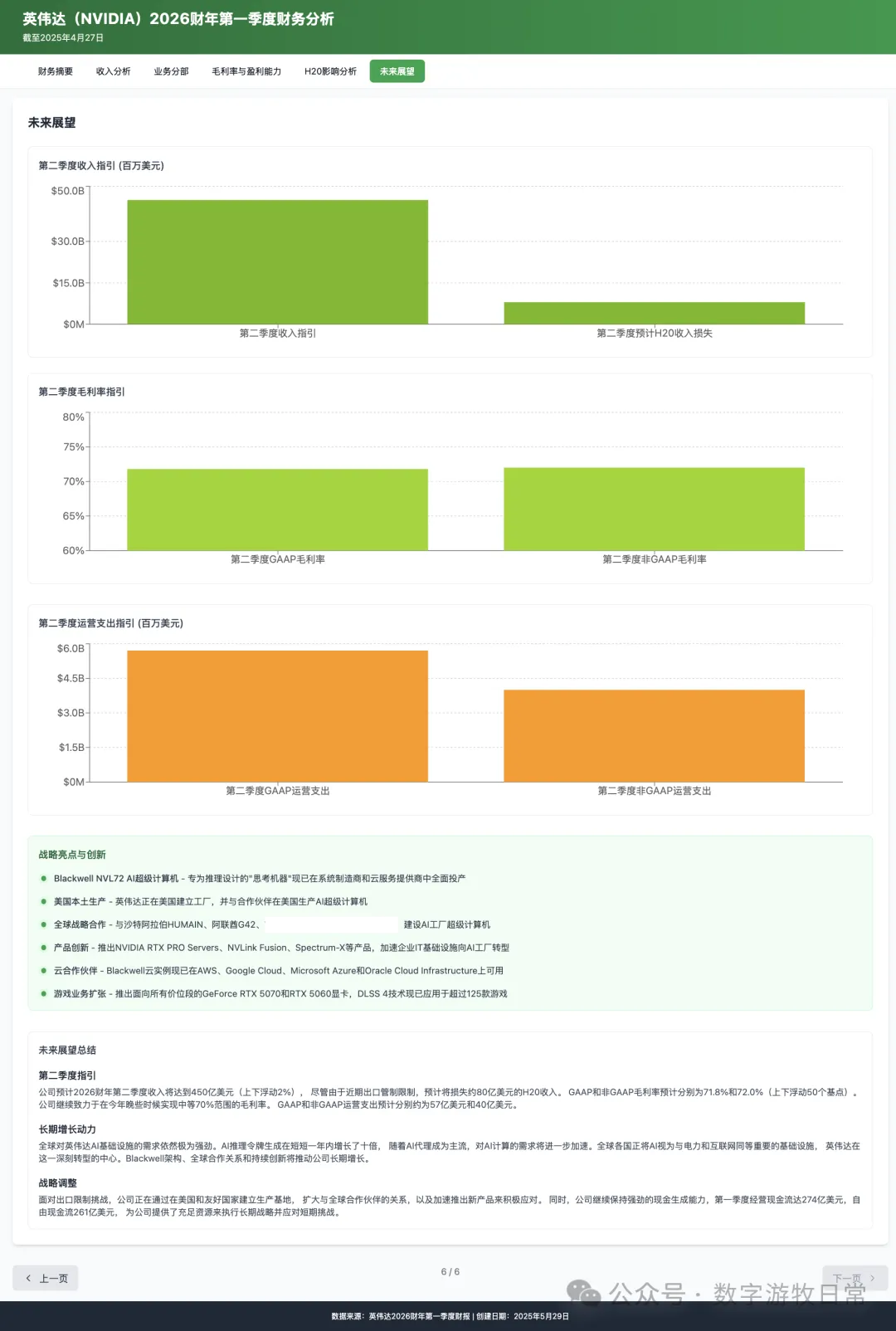
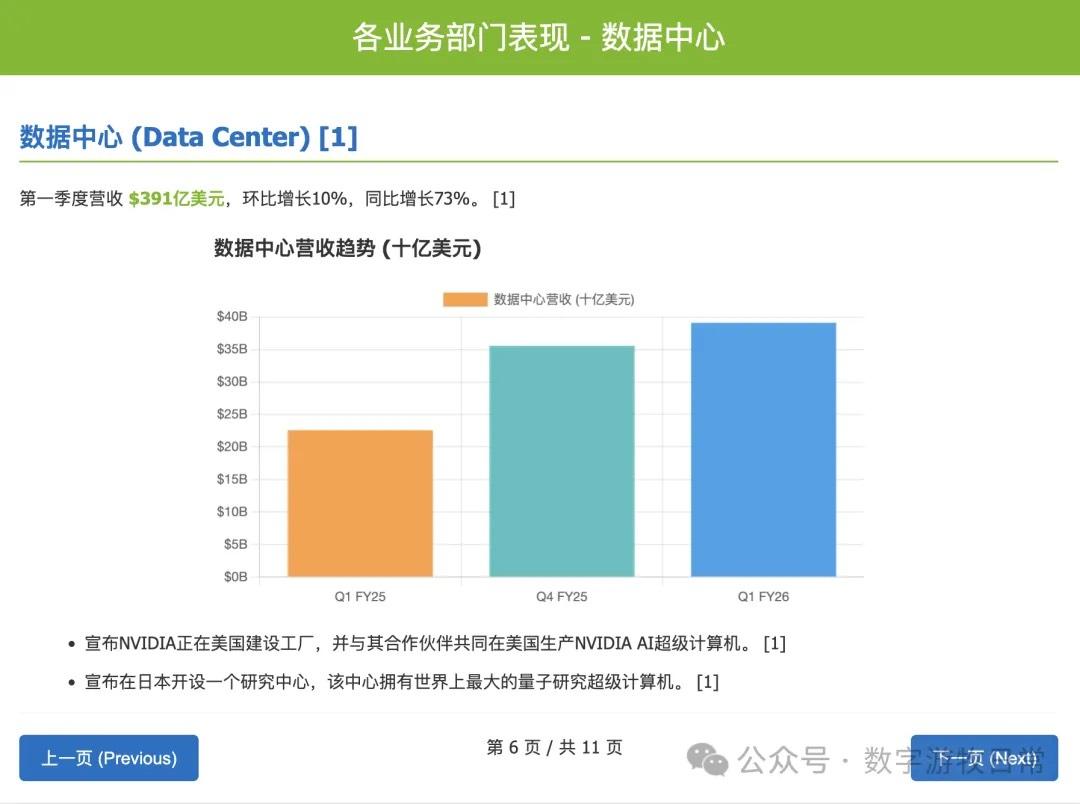
个人偏好而言,我依然更喜欢 Gemini-2.5-Pro 的输出,其次是 Claude-3.7-Sonnet:Gemini-2.5-Pro 输出了表格,虽然这个表格其实在官方发布里就有了。但也正是因为这一点,更加表明了 Gemini-2.5-Pro 对用户输入的“背景材料”的“忠实度”。
Gemini-2.5-Pro 很好的控制了输出的“度”:思考就是为了更好的理解用户输入的背景材料,而不是放任自己过多的给出主观判断。虽然这个问题依然见仁见智,但是我想说,Claude-4 对我而言,是“越线”了(我们可以另外开一篇文章讨论思考的度的问题);
Claude-3.7-Sonnet 也很好的控制了“度”,甚至除了没有输出表格外,相对于 Gemini 而言,包含了更多来自于“背景材料”的信息细节,例如一些战略合作等等。
相比之下,目前 OpenAI 于我而言,剩下的唯一价值,就是 Deep Research 了。相对于 Gemini 的 Deep Research, OpenAI 目前的结果稳定性还是要好一点点。
以上模型的结果,也基本符合我这段时间尝试与 Claude-4 模型磨合过程中的体会:有些地方确实体现出 Claude-4-Sonnet 的一次代码生成的准确率更高,但是相比 Claude-3.7-Sonnet,就是会有更多说不出的“不流畅感”。也许,就在于边界吧。
最后,确定的知道会有很多人批评:做 PPT 根本体现不了模型能力,Claude-4 明显在编码能力上更胜一筹。
首先,我们先排除受到评分表影响“纸上谈兵”的结果。
其次,可能需要思考一个问题:PPT 生成可以用于实战,直接用于一线业务环节,其他的代码生成多少是可以直接产生一线业务需要的结果的?如果答案,是为一线业务需求“造轮子”,那么, AI 时代,我们到底需要多少“造轮子”的场景?
生产力(大概率)是可以改变生产关系的。