
从一道经典的数学或者算法题说起:
如果我们恰好对自己的数学能力有自信,我们本能的反应应该是某种数学公式的“抽象”。如果恰好我们会写一些简单的程序,但是又没受过相对长时间的程序算法训练,可能会很快想到一种解法:
- 用排列组合方法列出将n个数分成M组的所有可能性:在n个球中间加(m-1)块隔板问题;
- 循环C(N-1,M-1)次,求出m组和里的最大值;
- 得出所有最大值里最小的一个;
这是一个指数级上升复杂度(准确的说是: O(C(n−1, m−1)·n),也有个名词叫做“组合爆炸”),我用Gemini生成了一段动画进行演示。
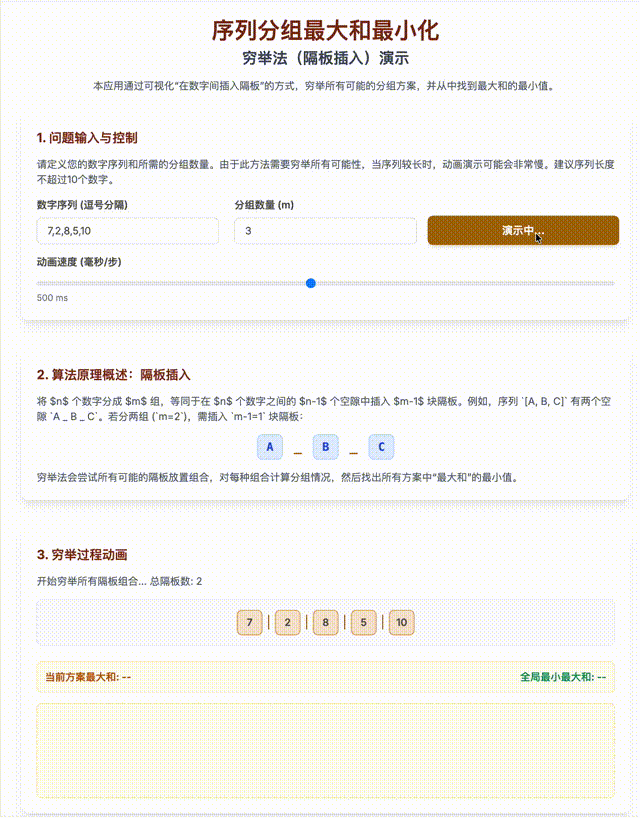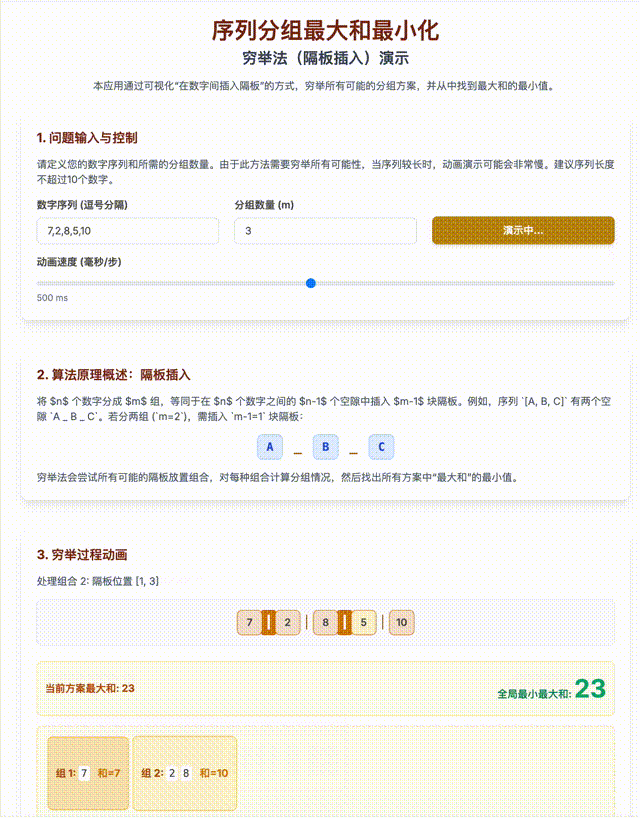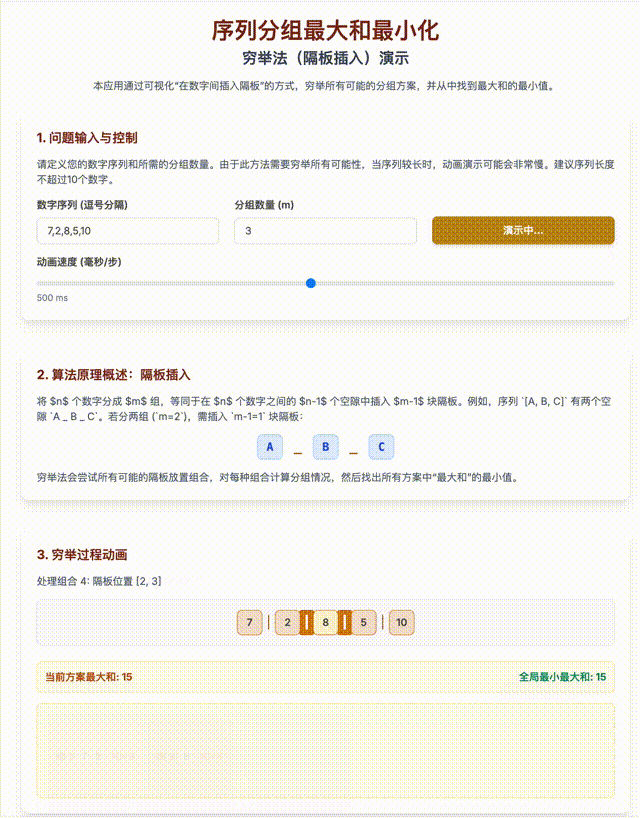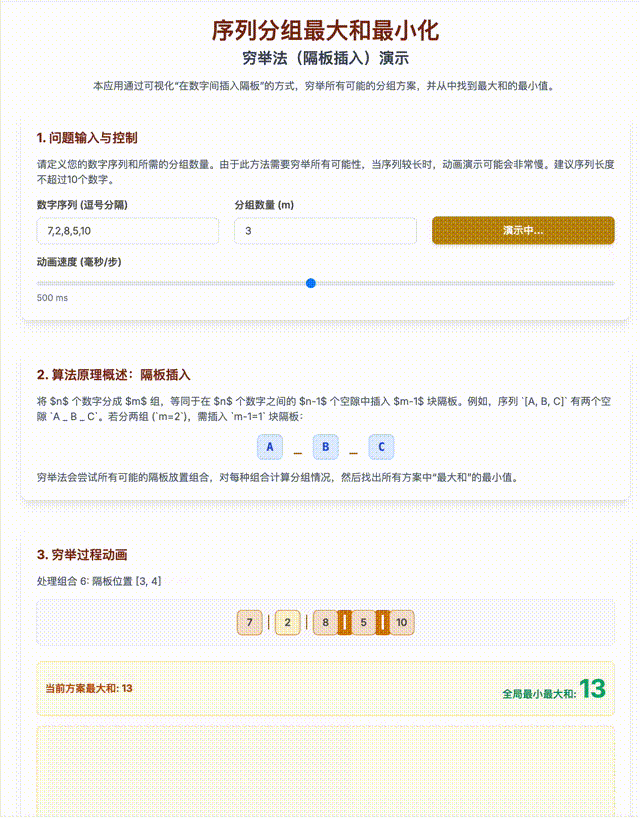
即使不考虑算法复杂度,要解决上面的问题,还是需要不错的数学知识和不错的编程基础。
但是这个解决过程符合人的本能反应或者理解和思考问题的方式。
那是不是有更好的解法呢?自然,答案是二分查找。
首先,我们知道这个值一定存在,而且介于n个数中的最大值和n个数的和之间。那么,我们就尝试这中间的每个可能答案是否是最终答案就可以了。



如果也用一段动画来表示这个过程,是这样的。
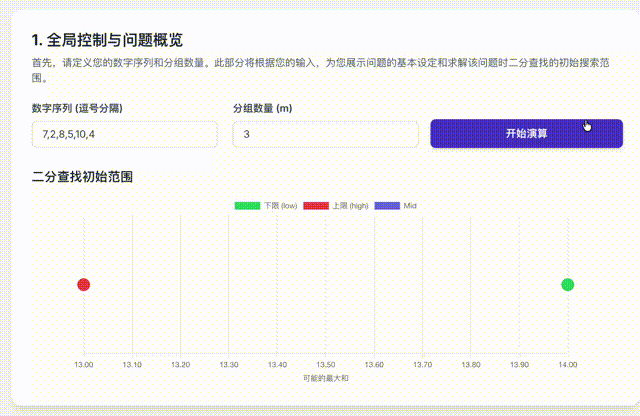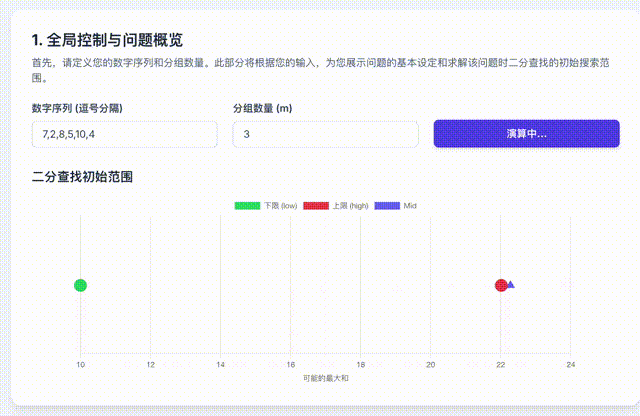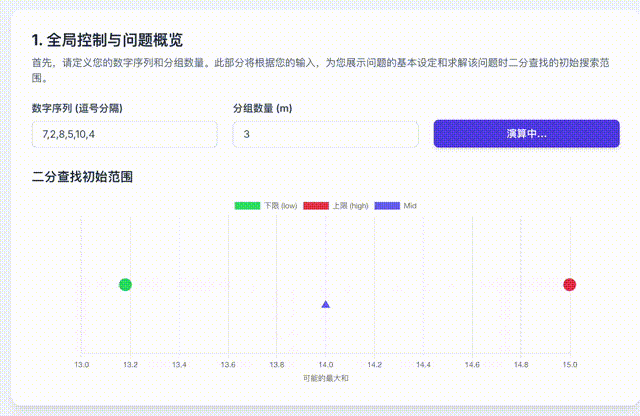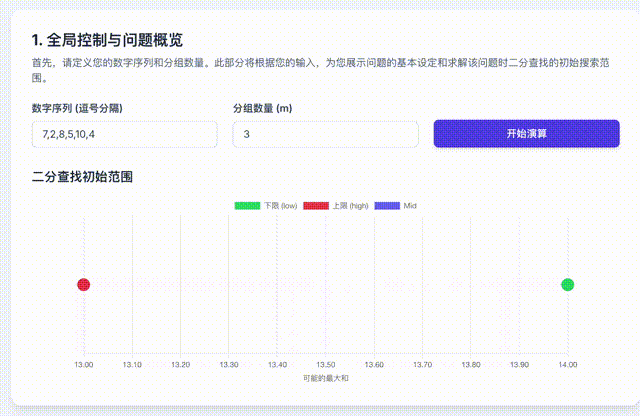
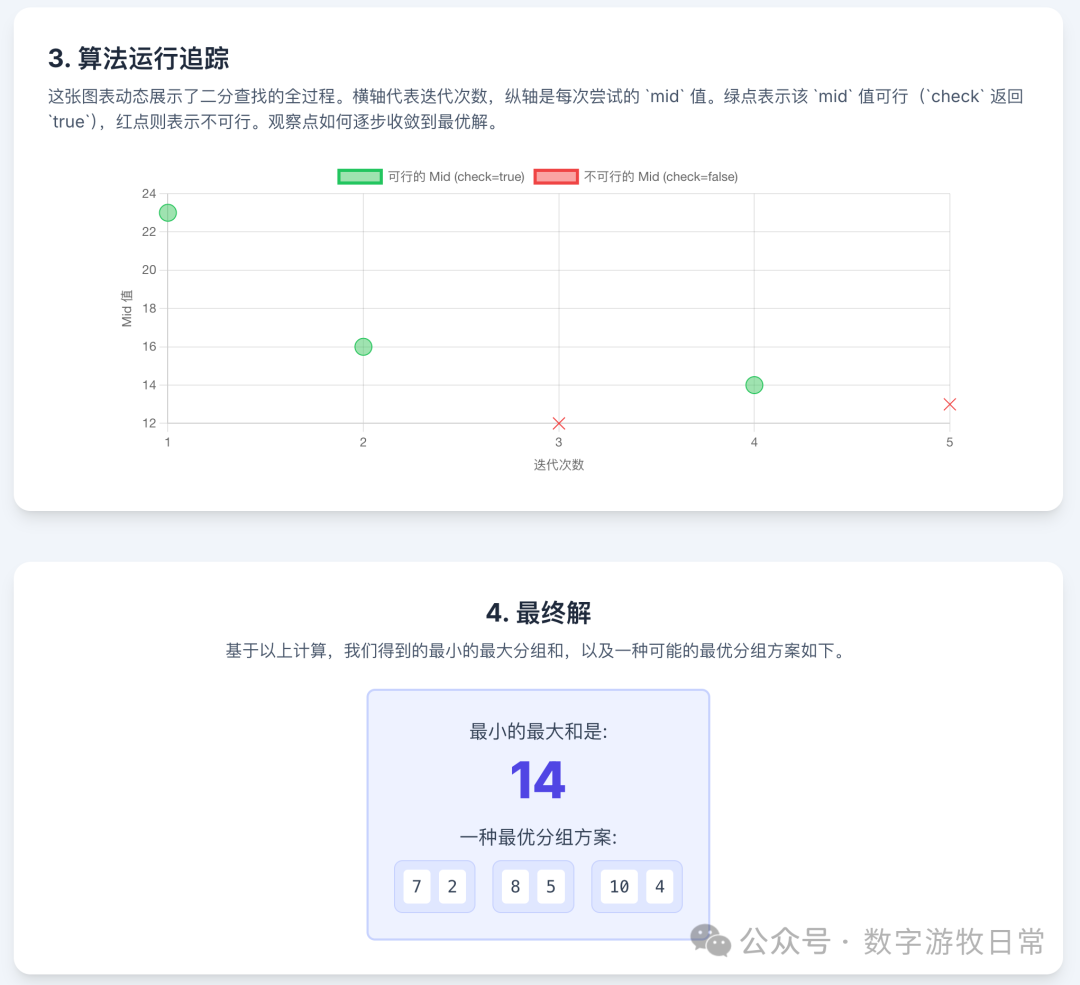
挺抽象的,但是它的算法复杂度很低。

- 很多时候,人脑“直觉”的解决问题的方法跟计算机的算法是不同的;
- 在上面两种解决方案中,第一种需要我们先建立一个基础的数学模型(排列组合问题),然后是虽然计算量大但是过程直观可控,第二种方案根本不需要我们建立什么数学模型(只需要相信一定有解),然后就是“抽象”的程序实现;
- 虽然从计算次数而言,第二种方案明显消耗更低,但是我相信如果由人脑完成的话,在一定次数范围里,一定是第二种方案更“烧脑”,为什么是一定次数范围,因为当n和m足够大的时候,列举所有可能性也将耗费巨大的脑力;
尽管第一种方案更直观,但是在实际场景中,一个典型的程序员可能就是愿意花费一个小时写代码+一个小时调试,也不愿意多花一分钟在前期的所谓数学建模上(排列组合问题?),尽管很可能这多花的一分钟可以使得解决眼下问题的时间只需要十几分钟,而且大概率这类问题在未来不会频繁出现。
第一种方案是遍历(穷举),直观但是很“蠢”(其实排列组合一点都不蠢,但你知道我说的意思,对吗?),第二种方案是迭代(递归),抽象但是很“美”(因为你在看着程序干一些复杂的活,而不是简单的循环,what?你大概也能知道我说的意思,对吗?)。
好了,这大概是我最近一段时间最长也可能是最“烧脑”的开场白。起因很简单:当我用了很长的一段时间(其实是我陪伴模型的时间,这过程中我一点都不烧脑,还可以同步干其他活),终于在“不写一行代码,不做任何内容干预或提示”的前提下,完成了一个对于任何模型而言都“很大”的项目后。
看着自己(其实是模型)产出的一堆“垃圾”(我刚在不久前公司内部答辩面试时对一位“同事候选人”的报告说过这个评语,虽然我觉得这是个中性词,但这样的评价显然还是不对的,所以,如果有幸被看到,这是我的道歉),我突然冒出了三个想法,对应今天标题的三句话:1)我们这个世界是个迭代器;2)总是在不断的“二分查找迭代”中找寻需要的答案;3)抽象的“迭代”就是模型不断取代人脑的方式。
简单阐述一下我“指导”模型经过艰苦卓绝的努力,生产出一堆“垃圾”的过程:
- 对于每一家需要研究的公司,全网搜索,提炼个性化的提示词,为Deep Research所用;
- 迭代进Deep Research,生成初步的报告;
- 迭代,筛选“最优”的报告;
- 迭代,对每一篇报告,参考“最优报告”进行优化;
- 再迭代,对每一篇优化过后的报告,再进行“搜索+优化”;
- 迭代,提炼出知识图谱;
- 再将知识图谱转化为日常更新的提示词;
- 还没想好……
其实,还可以不断迭代下去,但是模型的能力不支持:
- 上下文长度远远不够;
- 记忆能力太差,还是因为上下文长度不够;
- 输出的稳定性和一致性不足;
这些使得我必须不断小心的控制迭代步数,在发现输出结果“劣化”的时候,及时设定checkpoint,再开始。
这些让我终于得到了一批公司的“日常搜索词”(“垃圾”的第一处:这些搜索词或者提示词都不能说错,也可以抓住重点,但就是不如人类研究员手工产出的。大概估算了一下,如果“聘用”五个平均水平的人类研究员,在比较轻松的工作强度下工作三天,可以超过这个水平)。
当然,即使是“垃圾进,垃圾出”,也要看一下后面的流程是否跑通(模型总会进步,但迭代流程相对固定)。
把生成的模版交给Perplexity Labs,结果如下:
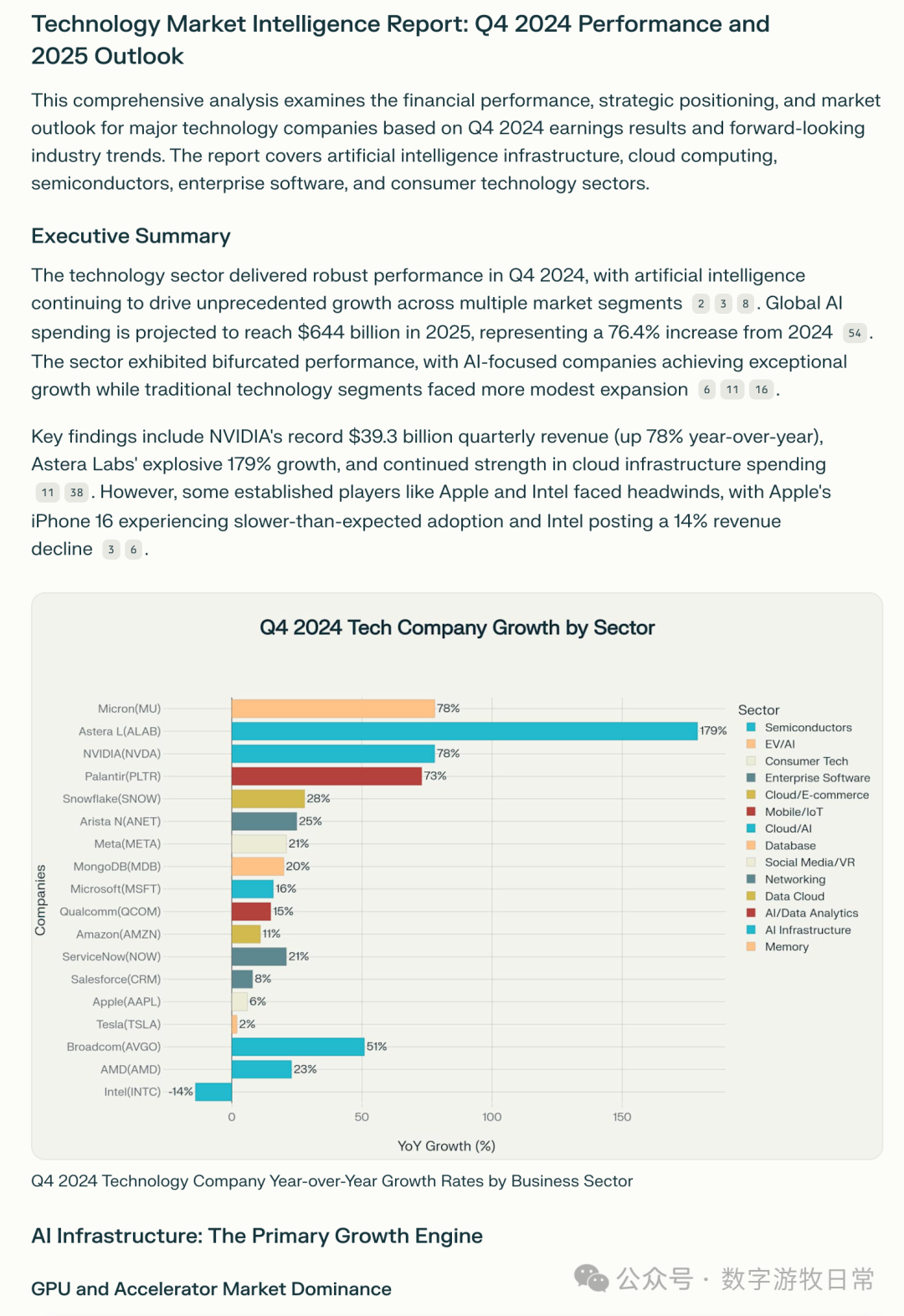
当然,Perplexity后台做了更多工作:
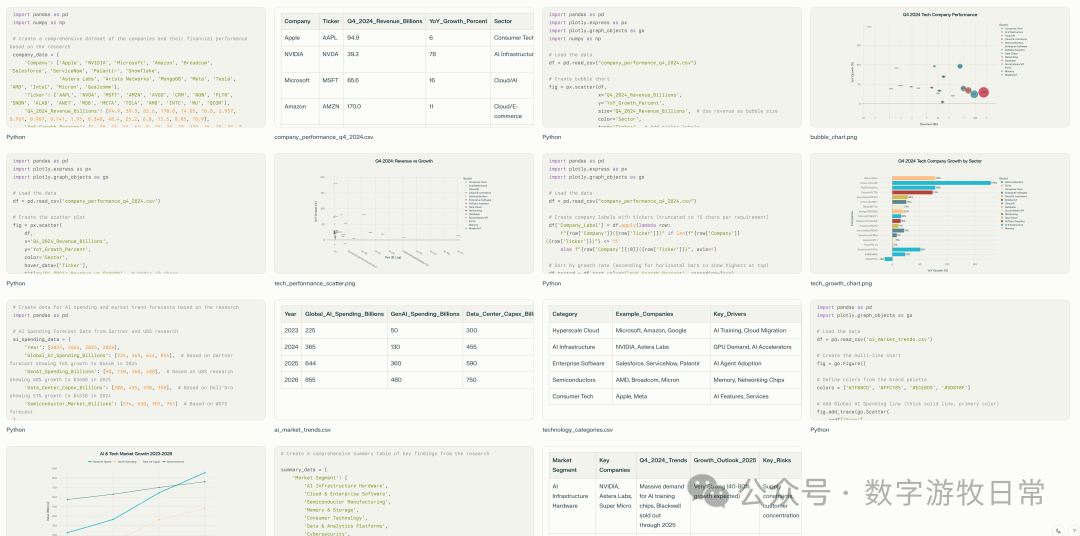
在输入中,给出了大几十家公司的模版,实际返回了18家,从绝对标准看,当然还不够,但是从发展速度的纵向看,这样的结果,已经进步的够快了。
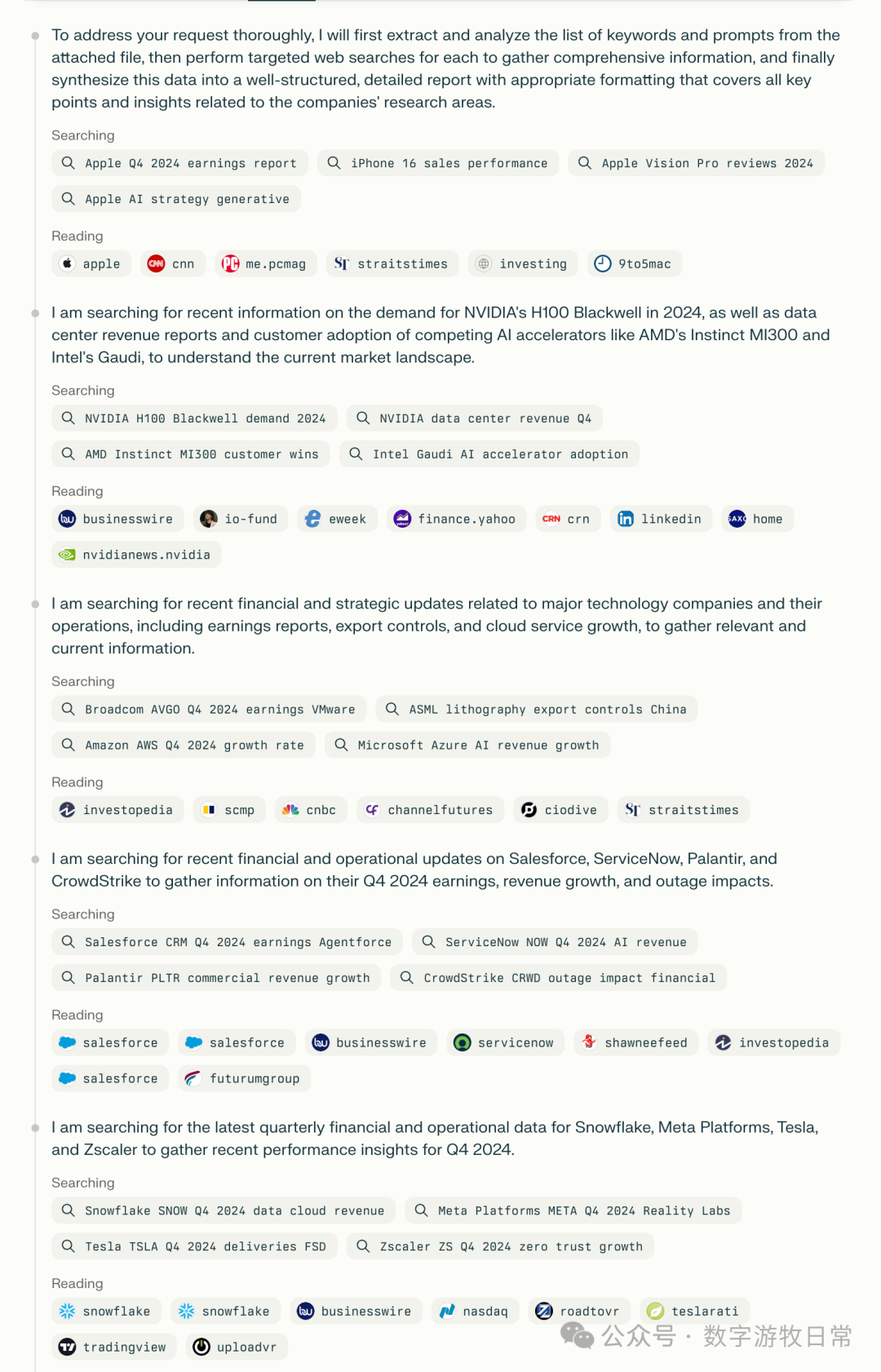
虽然,虽然,这是个Agent,上面的这项工作是遍历(遍历提示词模版),而不是迭代(抠字眼有意思吗?有,而且很重要)。
时值OpenAI又把o3-Pro吹上了天,号称模型可以直接整合思考、搜索、工具调用,Python代码,那就试试它的结果吧。
一批可以回三四个公司,其中关于苹果的长下面的样子:
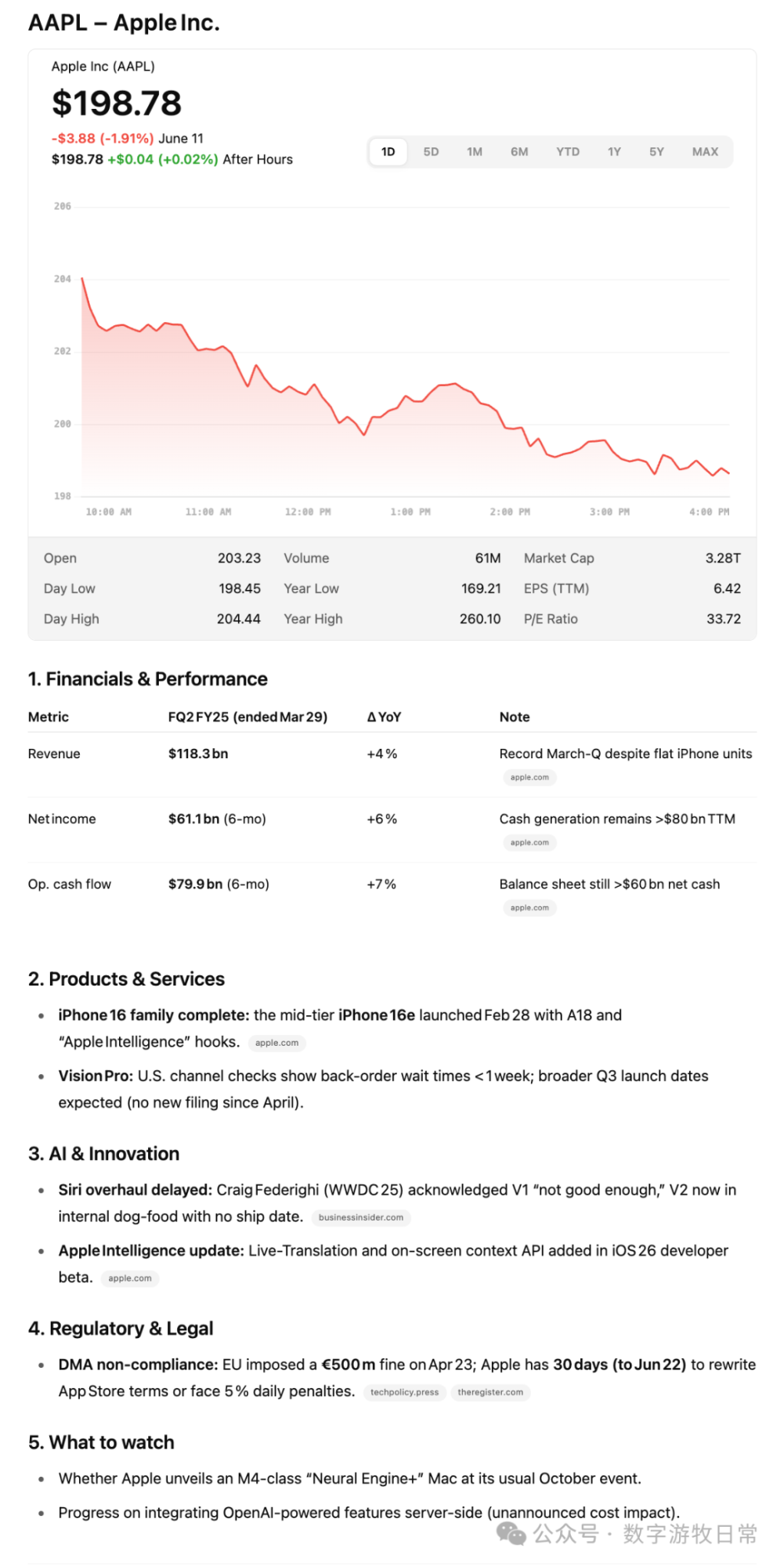
还有一些公司就不一一列出了。
受限于上下文长度,o3-pro给出了用户可以要求继续的方案。

我挺喜欢这段总结的,也确实干了这些事情,然后我像用Gemini一样,输入了:Go on。

偷工减料的“一坨”就又来了,这才是ChatGPT一贯的风格:当然,在五月底初次更新的Advanced Voice Model里,用户要求“它”念两百次“A”,它真的会不折不扣的完成,但是在最新的更新里,它会礼貌的拒绝。
礼貌的拒绝。让人不知道是模型真的干不了,还是真的干不了。
玩笑归玩笑,o3-pro输出,总体还是可以令人满意的,结果自然比Perplexity的Labs有用,关键是,“迭代”,一种理论上只需要用户无脑“go on”就可以持续的迭代。
在我即将完成这篇文章的同时,o3-pro还在“迭代”着。
我享受这种人脑被AI“取代”的感觉,因为,从一开始,我们就是用不同的方式去解决问题的:
一种是抽象后的具象遍历,
一种是具象后的抽象迭代。
写完后,发现,这篇也有点,抽象。