This will not be a detailed review, but rather a general subjective evaluation following various high-difficulty "boundary" attempts during this period—purely subjective. It can be divided into several parts:
- Scenarios suitable for GPT-5, Claude-4, and Gemini-2.5;
- Web versions, mobile apps, and terminal tools of the three major models (Codex, Claude Code, Gemini Cli);
- My choice if I were to pick a domestic Chinese "alternative."
I. The Three Major Models: GPT-5 is the most comprehensive, Claude-4 is the most specialized and stable, Gemini-2.5 is the deepest
It has been a week since the release of GPT-5. My feelings and conclusions regarding these three haven't changed much from the "second impression" during the weekend following the launch. GPT-5's advantage lies in its thinking intensity, Agent calling, and willingness to invest "computing power." Overall, it comes down to two points: at the model level, it's the reinforcement learning capability; at the usage level, it's about being more "hardworking." In most scenarios—such as asking questions, conducting real-time searches, interacting with document corpora, or producing structured documents—GPT-5 provides excellent answers. The massive role that "thinking" plays is evident, and if you enable "ChatGPT-Agent" mode, there are often surprises. This is largely credited to reinforcement learning, whether in "thinking" or Agent (tool) invocation.
Of course, this comes at a cost: the process of thinking and Agent invocation is not always controllable. In most cases, when a user asks GPT-5 to put in more "effort"—whether by calling a higher-level model or providing a long, specific task list—GPT-5 "consumes" more computing power and delivers better results. I have a series of scheduled tasks implemented this way. However, more thinking and Agent effort often mean the process goes out of control. The screenshot above shows a daily task taking about 22 minutes; however, this number fluctuates wildly every day, ranging from under twenty minutes to over forty, and once it even lasted two hours (stopped by the server for timing out).
This isn't caused by network or system response speeds. Looking at the logs, there are a lot of invalid repetitions or incorrect paths. Although it doesn't seem fatal to the result—a continuous process usually finds its way back to the right track—minor flaws and missing tasks are visible at any time. There is also a risk: GPT has a notorious history of "intelligence degradation." Models usually become very useful after a period of running-in and fine-tuning post-launch, but after about three months, they start to worsen or "dumb down." Now, it seems likely this is due to "computing power reduction." Of course, for now, it remains the best fit for most users in most scenarios.
Claude-4's strengths and weaknesses are both prominent. It is undoubtedly still "the most outstanding in coding ability"; there is no need to describe this further. However, it also has the most severe "hallucinations" among the big three. While not a major issue in most code generation scenarios, it becomes one in daily use. This issue, which involves a critical and fatal problem for Anthropic (the developer of Claude), will be explored in the next section.
Gemini-2.5 is naturally at home in the Google ecosystem; it is the most stable core and the most extensible model. In fact, Gemini-2.5 likely ranks in the top two among the big three for every task and consistently first for tasks requiring depth. But the prerequisite is the "Google Ecosystem." Simply put, you'll find that while a search in the Gemini app might frequently yield errors, the factual results are incredibly accurate once Deep Research is enabled, and search results become "precise" when Grounding mode is on in AI Studio.
After long-term use, you'll find it can be cleverly lazy. Given a simple programming task—like building a website on a certain theme—both Gemini and Claude can finish it. The difference is that Claude might add a lot of mock content and adjust the page to what it considers "aesthetic." For instance, a C++ learning website. Recently, the founder of Tailwind clarified things, finally confirming my long-standing suspicion: that unique "purple taste" is definitely a result of "failing to learn" a certain CSS style correctly.
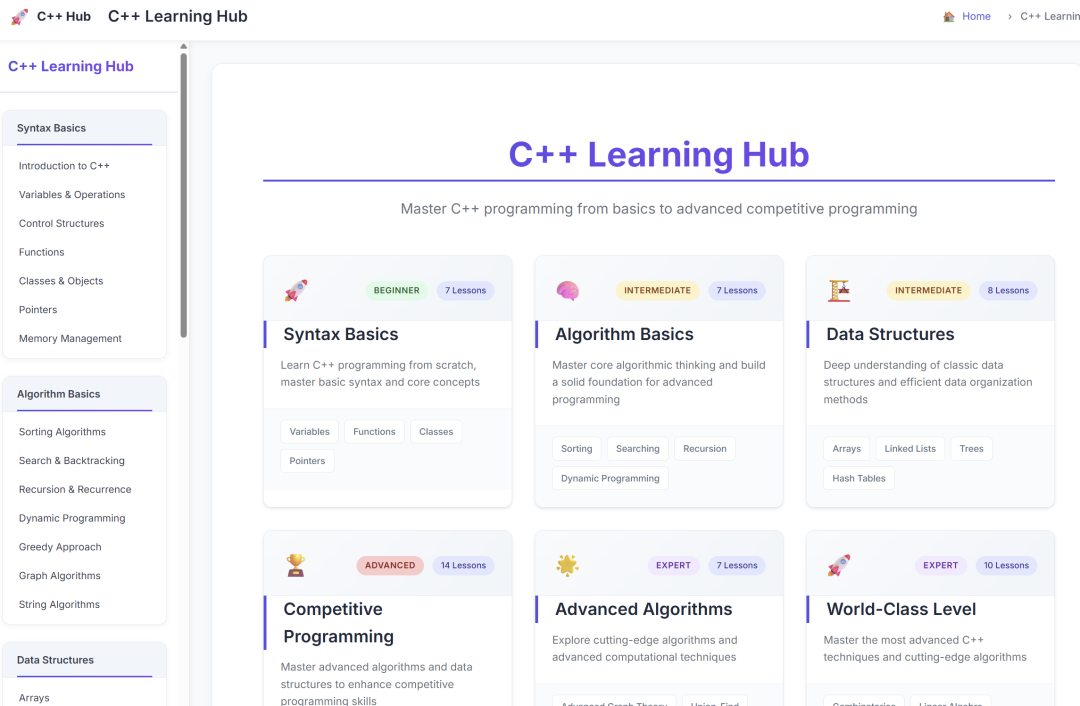
In contrast, Gemini-2.5 never does that unless the user gives specific requirements. Otherwise, it just completes the basic task. For the page mentioned above, the directory is there, the card mode might be there, but the cards might not be clickable because no specific content was generated. The CSS style will certainly be simplified, likely a basic black-and-white style. Gemini-2.5 completes the user's task but doesn't give extra. You might say its "ability is lacking," but for the same website, its basic architecture is more reasonable and concise than Claude-4's, and its code pass rate on the first try is much higher. Then, if you send it a screenshot like the one above and say, "Don't be lazy, make it look like this," it can actually generate the whole thing, often with slightly higher quality in structure, content, and aesthetics.
Often, I have a strange sense of déjà vu: facing Gemini-2.5 is like facing Demis—a gifted yet incredibly cunning straight-A student. You need to pit your wits against it to get better results; when you think you're being "smart," it actually doesn't care about you at all. By comparison, GPT lives like a person who has to put in massive effort to stay ahead, while Claude is more like a self-important opportunist. This is how most of us actually are.
II. Applications and Terminal Tools
After a cycle, all three have web versions, apps, and terminal tools (GPT's Codex, Claude Code, Gemini Cli), plus a bunch of other tools (Google has the most currently, followed by OpenAI).
A few days ago, I posted a question: if you had to delete one app from "ChatGPT, Gemini, Claude, Perplexity," which would it be? My answer was Claude. If I asked a different question today—if you could only keep one, which would it be? The answer is ChatGPT. Setting aside Perplexity, among the apps of the big three, Claude currently has the fewest usage scenarios because coding is not suitable for mobile; it needs a desktop, an IDE, or a terminal environment. Gemini, for reasons mentioned above, often works better in the web version and AI Studio. ChatGPT now represents nearly 90% of OpenAI's efforts and features.
Meanwhile, I almost never use the Claude web version on mobile (I use it on desktop occasionally, maybe once or twice every few days). I use the ChatGPT web version frequently on desktop, but I use the Gemini web version and AI Studio very frequently on mobile. Although I am increasing my "desk time," in mobile scenarios—subways, buses, or communicating with people outside—I access the web version via phone to discuss sudden inspirations or arrange offline tasks. Active user numbers reflect this: ChatGPT not only has a massive base, but its daily visits are growing fast; Gemini's daily visits have also grown rapidly over the past six months to match Google's status; Claude has been unremarkable (Similarweb detections include both mobile and web visits). Similarweb recently posted these statistics on X, which explains a lot.

However, the reasons behind the traffic difference are complex: for instance, ChatGPT captured user mindshare early and is more generous with free usage, while Claude is not friendly to "free users."
The battlefield is slowly expanding and shifting. A fully comparable new battlefield is terminal tools: Codex, Claude Code, and Gemini Cli. Regarding current forms, Claude Code was released first, followed by Codex Cli (OpenAI released Codex early, but the terminal tool form appeared in April) and Gemini Cli. Over the past period, my usage time for terminal tools has grown rapidly because they aren't just coding tools; they can be versatile interaction platforms. My OpenResearch project started late last month is a scenario based on terminal tools. For me, the biggest change is the significant reduction in the complexity of deploying automated tasks and the massive increase in daily output.
With Cursor becoming increasingly unfriendly (limiting usage quotas), I have basically shifted to Claude Code for coding. Daily tasks are handled in Gemini Cli or other Gemini-based tools I've written. After the release of GPT-5, I started trying Codex. Gemini Cli might be the most indispensable tool because it is powered by Google Web Search, or rather, the entire Google search engine. Aside from code generation, the two most important tasks are searching and local file generation/management.
I have a hunch—though it needs time to be proven—that in the AI era, the value of Google's search engine won't be weakened; it might even be strengthened. It's not just a matter of accuracy, but also the support of "sufficiently low search costs and sufficiently high search efficiency" accumulated by Google over a long time. In this regard, while Claude Code can also initiate searches, the accuracy is... (Claude's hallucinations are relatively high to begin with, and without search accumulation, the results are error-ridden).
Codex has surprised me in the last few days, for reasons similar to GPT-5. Specifically, yesterday I gave the same command to all three terminal tools: download all web link content from a pile of articles. Gemini Cli repeatedly "refused" me with various excuses. When it finally agreed to use web fetch after my "coaxing and deceiving," I stopped the session because it was clearly going to exhaust my daily request quota quickly. Claude Code basically failed to understand the task. Codex was straightforward: it read all articles, created a download list, used both curl and Python code to process them, and even wrote a failure log for retries. Though it worked slowly and hard, I got clear results after one night. I used to think Gemini-1.5 was the model worker; now, that title has changed hands.
However, while terminal tools may bring more model calls and revenue (user time equals revenue), and returning to the "terminal" era indeed fascinates many programmers, in an era where fewer people have deep Linux development experience, such users may have already been fully tapped. Github claimed that Copilot users reached 20 million in July, growing by 5 million from April to July. A reasonable assumption is that due to the penetration of AI coding, many professional users in other fields have become "Vibe Coders." As an aside, when confirming the Github Copilot user count, I asked Perplexity. I already knew the 20 million figure, but I had no memory of the 1.3 million subscribers because I looked at the summary first and didn't see the source there. After checking all provided sources, I finally found it—information from January 2024.
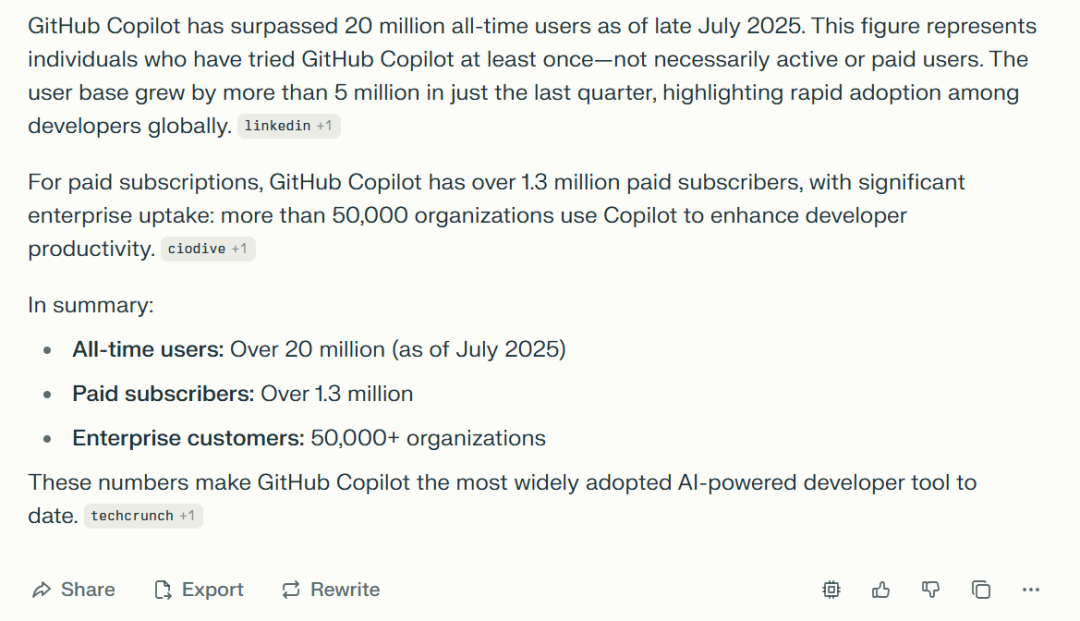
Given the same question, GPT-5 likely wouldn't be so easily "misled."
Back to the point: the field with a limited user base but high ARPU (like the terminal tools mentioned above) is naturally important. But it can't follow "internet logic"; it's purely a competition of product capability. In this field, because users use the tools for long periods, quality is clearly visible, and users have no stickiness. This is actually fatal for Anthropic; as mentioned, its app and web user growth is stagnant. Most scenarios exist within various IDEs like Cursor, VS Code, Cline, Trae, etc. The only reason is Claude's code generation capability; once a model surpasses it in the majority of programming tasks, it loses everything.
III. Domestic "Alternatives"
Not long ago, I wrote a long post: "GLM-4.5 is stunning, MiniMax Agent is good, Kimi-K2 is okay, DeepSeek needs an upgrade." They all have a vision of what they want to become, much like NBA rookies being assigned a comparison template. Clearly, GLM-4.5 is more like ChatGPT; MiniMax is a Claude deeply influenced by "Manus"; Kimi once wanted to be Gemini but now wants to be Claude; and Qwen-3 likely just wants to replace Llama...
I've never been used to using "alternatives," let alone becoming one, but I get asked many times. Indeed, for various reasons, domestic models are the more rational choice. I would choose GLM-4.5, primarily because it's more like ChatGPT. Its application is most willing to give "computing power," its thinking is hardworking, and its search is diligent. I just sometimes wonder: there are tens of millions of senior users globally increasing their payment rates for the big three models, but how many are willing to pay for a "domestic alternative"? Do we really have to rely on low prices or even free services to attract customers? In an era where tokens are revenue and also cost, is this really the right choice?
Of course, many will choose something like Doubao or DeepSeek—though the latter is half a year old and needs an update, it still has a huge user base. There are habits and so-called "user experiences," but those of us accustomed to "free and useful" experiences might be losing the ability to judge what is truly "good." We can be occupied by algorithmic feeds for most of the day but are rarely willing to actively search and acquire. AI is there, and the compressed human knowledge base is there; perhaps, what is free isn't worth taking the time to even glance at personally.