Physical Constraints
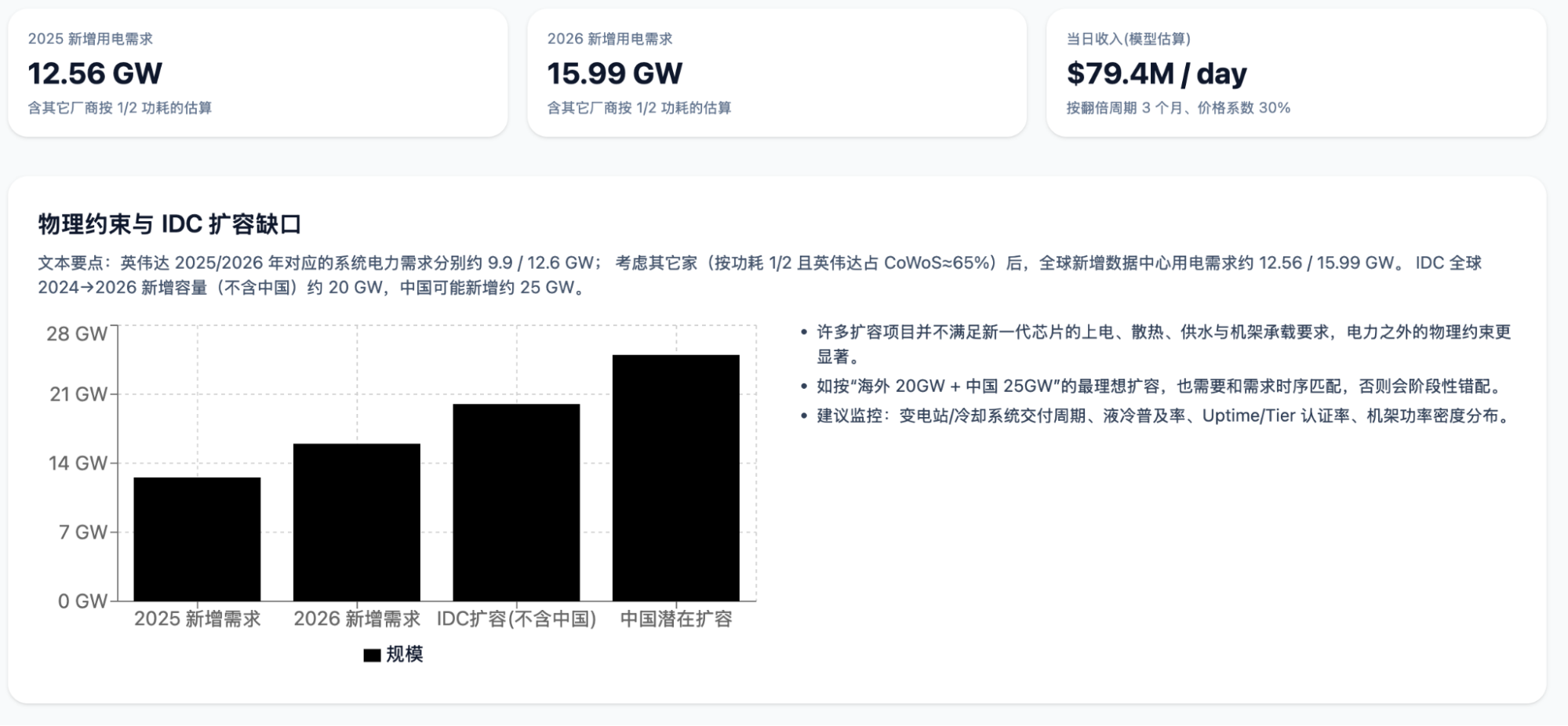
NVIDIA will ship 7.2 million cards this year. Among them, Hopper accounts for about 450,000. Subtracting H20 and B30 (about 1.4 million), the chip power consumption is approximately 5,500K * 1.2KW = 6,600MW * 1.5 (for server, network, and other systems) = 9,900MW.
By 2026, the equivalent Blackwell count will be 7 million (3.9 million Blackwell, 2.1 million Rubin; each CoWoS interposer can yield 15 and 10 cards, respectively). Power consumption will be 7,000K * 1.2KW = 8,400MW * 1.5 = 12,600MW.
NVIDIA accounts for about 65% of CoWoS capacity for accelerator chips. Assuming other chips (ASIC, AMD) have lower system power consumption than NVIDIA—even if calculated at half the power—the new data center power demand for 2025 and 2026 would be 9,900MW * (1 + 35%/2/65%) = 12,565MW and 12,600MW * (1 + 35%/2/65%) = 15,992MW, respectively.
According to IDC data, the new global data center capacity by 2026 compared to 2024 (excluding China, which can add about 25GW) is about 20GW, which is already insufficient to meet demand. Moreover, this covers all data centers; many expansion projects do not meet the requirements for next-generation chips.
In reality, after power, physical constraints like racks, cooling, and water supply will be even more significant.
Token Trends
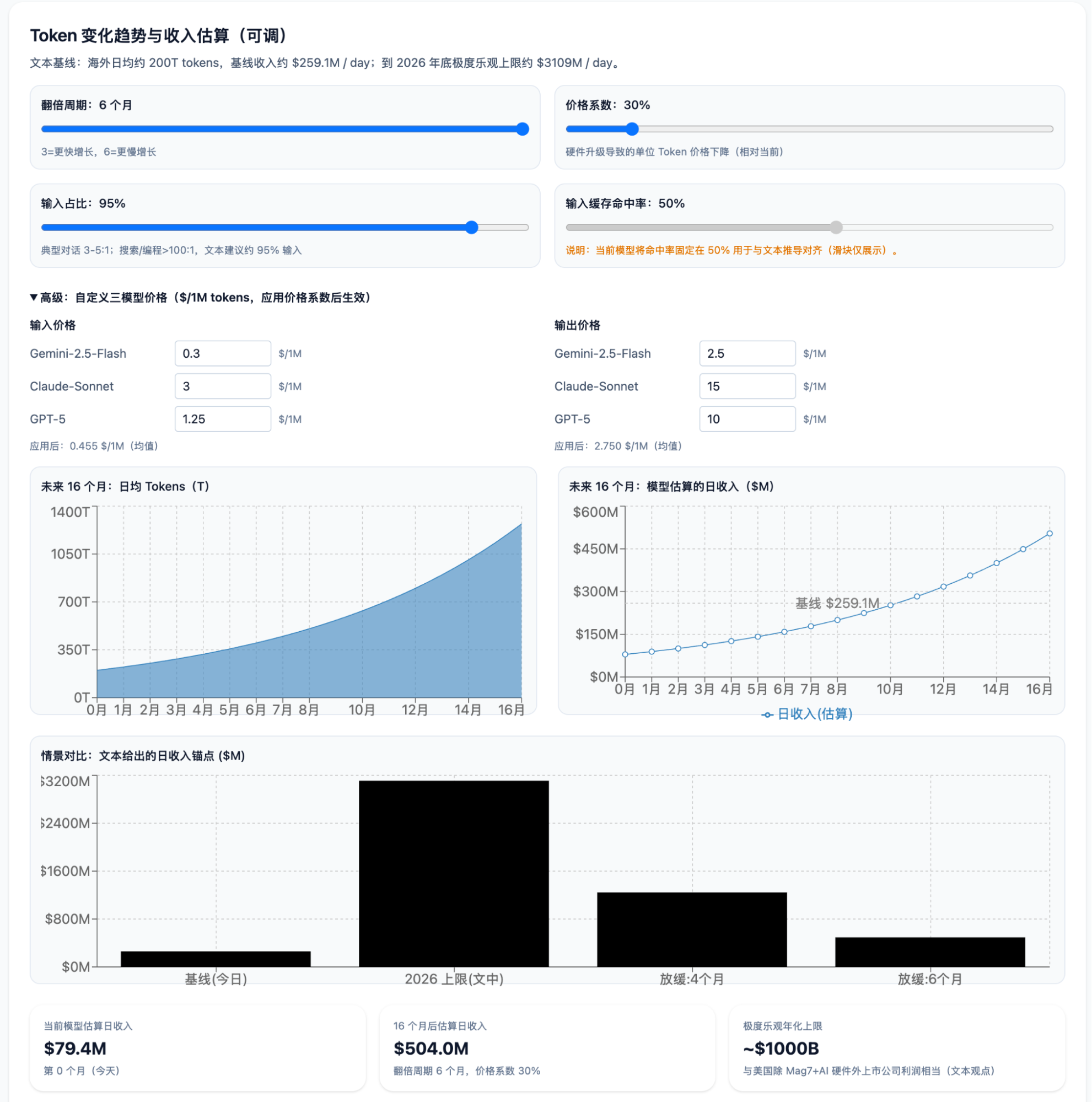
Token growth primarily comes from search and coding. Google continues to see call volume double every two months, and OpenRouter shows the same trend. However, a zero-sum situation is emerging; the doubling rate is expected to slow down to three or four months.
Google's Gemini had an average daily volume of 30T in June, surpassing Claude. Since GPT models have weaker coding capabilities, Gemini's token volume likely exceeds GPT's as well. Considering Grok and some cloud-based open-source model deployments, Gemini might account for 30% of the market outside China. By the end of August (doubling from June), the daily token volume for the market outside China would be approximately 30T * 2 / 30% = 200T.
Considering token distribution, in a typical conversation, the ratio of input tokens to output tokens is about 3-5:1. In AI Search and AI Coding, the ratio exceeds 100:1. Thus, assuming 95% input tokens and 5% output tokens is a very optimistic assumption from a revenue perspective. Furthermore, over 50% of input tokens will hit the cache.
Pricing: Gemini-1.5-Flash input is $0.3, output is $2.5; Claude-Sonnet input is $3-6, output is $15-22.5; GPT-5 (est.) is $1.25 and $10. Cache hits are priced at one-fifth (one-tenth for Claude and GPT).
Daily AI revenue = 200T / 1M * 5% * (2.5 + 15 + 10) / 3 + 200T / 1M * 95% * (0.3 + 3 + 1.25) / 3 * (0.5 + 0.5 / 5) = $91.7M + $167.4M = $259.1M.
Under an extremely optimistic scenario, by the end of next year, token volume doubles every three months while token prices drop to 30% due to hardware upgrades. Over the remaining 16 months, token volume grows 40x, and daily token revenue increases 12x. The daily revenue ceiling by the end of 2026 would be $259.1M * 12 = $3,109M.
The above calculation is an extremely optimistic case. The key variable is token growth rate. If it slows to an average of four months, revenue becomes $1,244M; if it slows to half a year, $493.6M.
Based on the extremely optimistic assumption, annualized revenue is about $1 trillion, which is roughly equal to the total annual profit of all US public companies (excluding the Mag7 and AI hardware companies).