
I am still the same person who, when DeepSeek R1 was released and the market was full of voices saying "compute power is not important," insisted that "the demand for compute is limitless" and that "NVIDIA at 100-110 is very cheap." I am still the same person who wants to "do the math" and consider "physics."
In January this year, when Masayoshi Son, Larry Ellison, and Sam Altman stood next to the President at the White House to announce the "Stargate" project, the investment figure was $500 billion.
But unfortunately, the release of DeepSeek R1 and the subsequent "tariff shock" on April 2nd knocked "compute power" from its peak to a low point.
Eight months later, the figures are almost the same as before, but the sentiment is no longer the same.
As I have said for a long time: the shortage of compute power will be an ongoing topic.
However, the word "Physics" still flashes in my mind. This word was written in NVIDIA's PPT introducing CUDA before ChatGPT was even born, and it is the sentence that has influenced me the most in recent years.
Nvidia GTC 2022: How CUDA Programming Works.
So, this article is not about the sentiment of a "bubble" or about investment; it is only about some physics, and even more so about a series of viewpoints from this year. I am grateful to myself for constantly writing; although readership is an important metric, being able to constantly organize thoughts and leave a trail for review is much more important than views.
I liked NVIDIA before it skyrocketed because you could really find enough technical details in their various materials, and you could really feel that down-to-earth state of "solving problems."
I also liked OpenAI before ChatGPT was released. Similarly, they were solving problems one by one: when you use their open-source code to reproduce a "puppet" in a digital world from learning to stand, to walking, to running; when you can really train a very small-scale GPT model, you can still fully connect with that "purity" and gain strength from it.
Of course, as much as I dislike today's NVIDIA and OpenAI, I like Google just as much. As much as I dislike Jensen Huang and Sam Altman now, I like Demis Hassabis (perhaps simply because he wants AI to help him make an Open World game, or because he just wants more time to play Civilization).
When people detach from "physics," they exhibit many strange behaviors. A former colleague of mine called this "the world belongs to paranoids, madmen, and neurotics." I 100% agree with this conclusion, but I 100% disagree with the inference following it: that because those paranoids, madmen, and neurotics "changed" the world, it means being one is sufficient; meanwhile, the answer to whether those who rely on madness to achieve "success" can continue to succeed is obvious.
I have felt the illusion of "weightlessness," and I have seen too many cases of "because I was right in the past, I will continue to be right," only to see the tower collapse...
So, back to "physics," right?
"Physics" has two sides. In the future, I will spend more time adding more details. Today, I'll boil it down to some numbers and conclusions.
The first side of "physics" is supply:
If we follow the market consensus for the production of compute chips this year and next (excluding domestic chips and those sold to China), and account for servers, switches, networking, cooling, and other auxiliary equipment power consumption, the total power demand is roughly at a level of 25-30GW over two years. The global newly added data center capacity (excluding China) for this year and next is about 20GW. Keep in mind that hyperscale AI data centers are only a part of that, albeit a large part.
Many already know the reality: due to structural building issues, power, water supply, and heat dissipation, most advanced compute power needs to be installed in new hyperscale data centers. Therefore, we almost don't need to discuss the possibility of using existing data centers, phasing out legacy compute, and installing advanced chips. This situation exists, but its share is tiny compared to the gap.
Thus, we see more and more "Ghost Compute": it is recorded in some companies' revenue but has not been installed on data center racks to provide actual compute output.
We probably won't find a sufficiently accurate method or first-hand compliant information to calculate the amount of "Ghost Compute," but in an era where products update every 1.5 to 2 years, the buffer for it to keep increasing is not large.
Regarding supply, we can still calculate many things: power plants, fiber optics, copper cables, power equipment, PCBs, HBM memory, NAND storage, and even HDDs. These details may be closely related to "investment opportunities," but the "narrative" can only reside within the "big ledger" of the data center.
The other side of "physics" is revenue:
Theoretically, on a supply-demand balance sheet, demand should be opposite supply. But AI is a bit different; for a long time, it may not be possible to have the "wool come from the pig" (cross-subsidization). We can only focus demand into: Revenue.
Unlike the traffic era of the internet, in a digital world where "everything is computation," every token corresponds to a cost and revenue. We talk about the "Jevons Paradox": although prices are falling rapidly, as long as usage rises fast enough, total revenue still grows.
From 2025 to now, we've seen this trend: token prices have dropped to $2 or lower, a decline of at least 60-70% compared to last year. However, token usage is doubling every two to three months. Anthropic's ARR is growing rapidly; although OpenAI hasn't made public disclosures, its ARR growth rate must be very high. Other application companies, like Cursor, also have exaggerated ARR growth slopes.
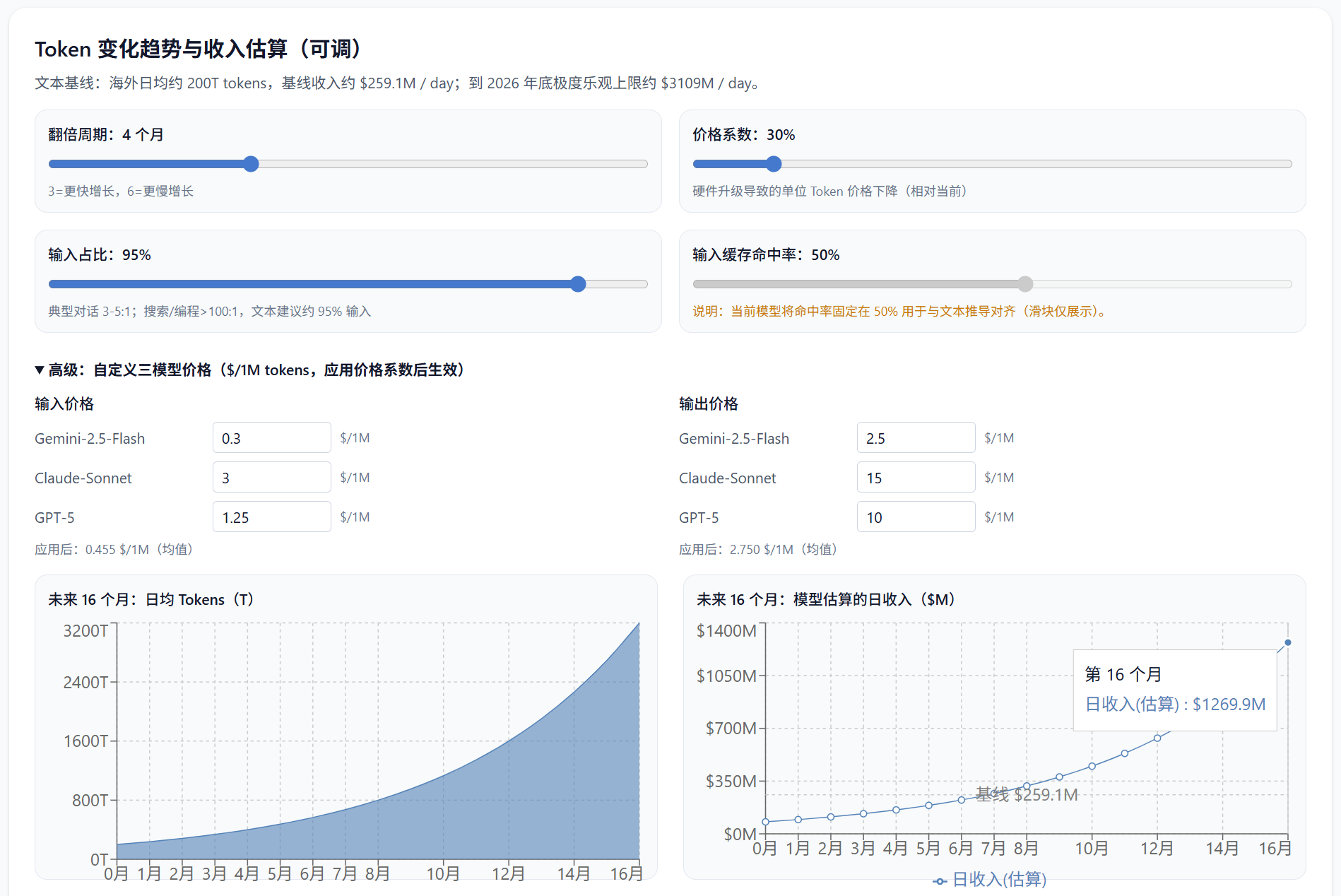
A few weeks ago, I did an elasticity calculation based on end-of-June public data and reasonable inferences for end-of-August figures (daily average of 200T tokens) as a baseline: If token usage doubles every four months on average and token costs drop 70% by the end of 2026, then by late 2026, daily token revenue in markets outside China would be approximately $1.27 billion, with an annualized rate exceeding $460 billion. However, this figure might be seriously overestimated because a large portion of current token usage might come from within model companies, and another significant portion, though from users, is free (e.g., Gemini has a very "generous" free allowance daily; I almost use it up to nearly 100M tokens. If there are a million people like me globally, that's 100T. Ten thousand people? 10T. This number is arbitrary; truth is, no one except the model companies knows.)
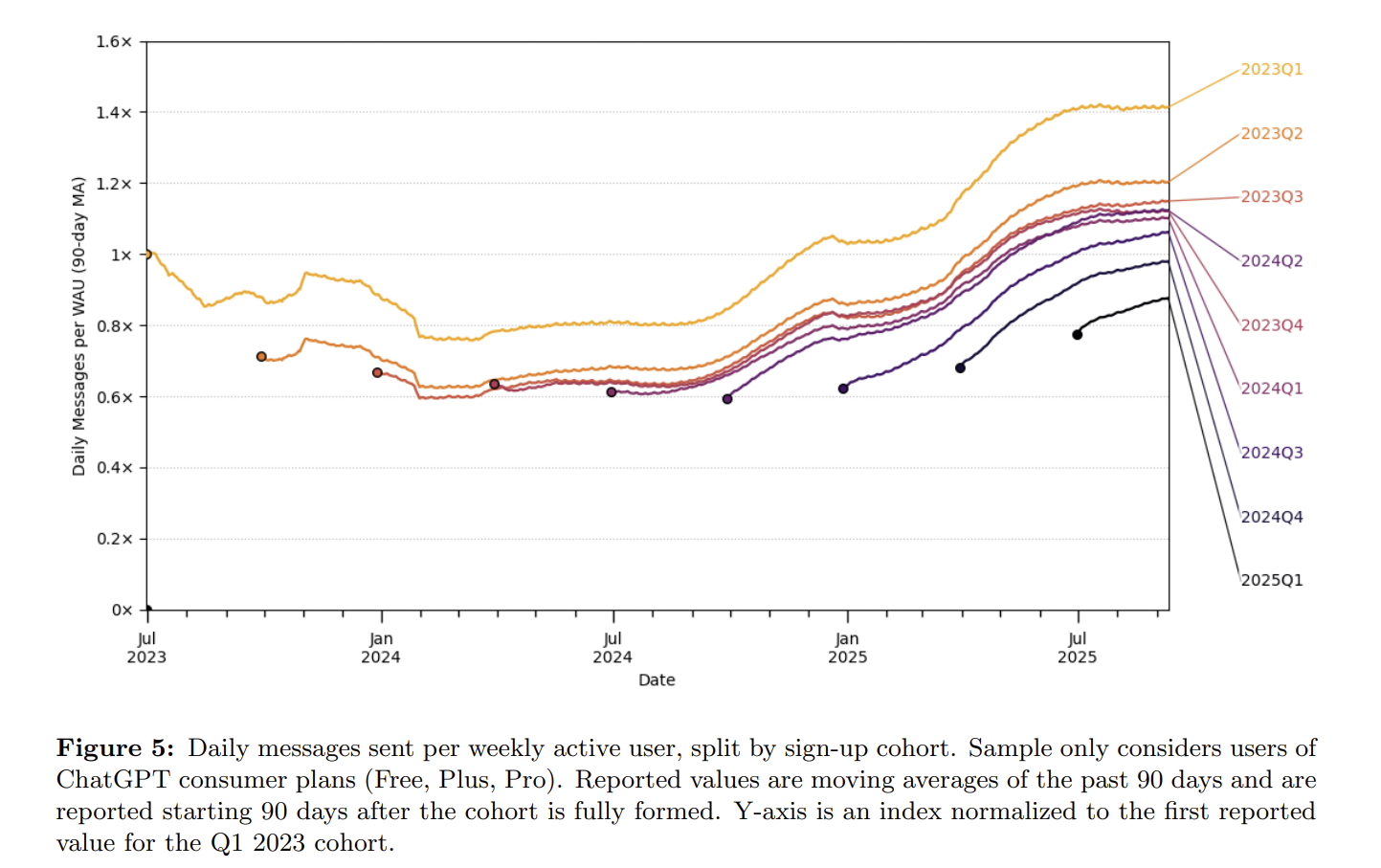
In fact, I might still be overestimating this growth and revenue trend. I will illustrate with three charts. The first is from OpenRouter's model call ranking data. Although the weekly call volume of less than 5T is small, its user base is representative. We see that without the addition of lower-priced or free Grok models, the month-over-month token growth has basically flattened. Claude, recognized for stronger coding capabilities, has seen stable call volume for a long time. I haven't calculated further, but considering Grok's lower price, from a revenue perspective, the trend we see is flat: token growth driven by search and code generation may have entered a bottleneck phase. Users remain extremely sensitive to token prices, and with no significant difference between models, the substitution effect of low-priced models is obvious.
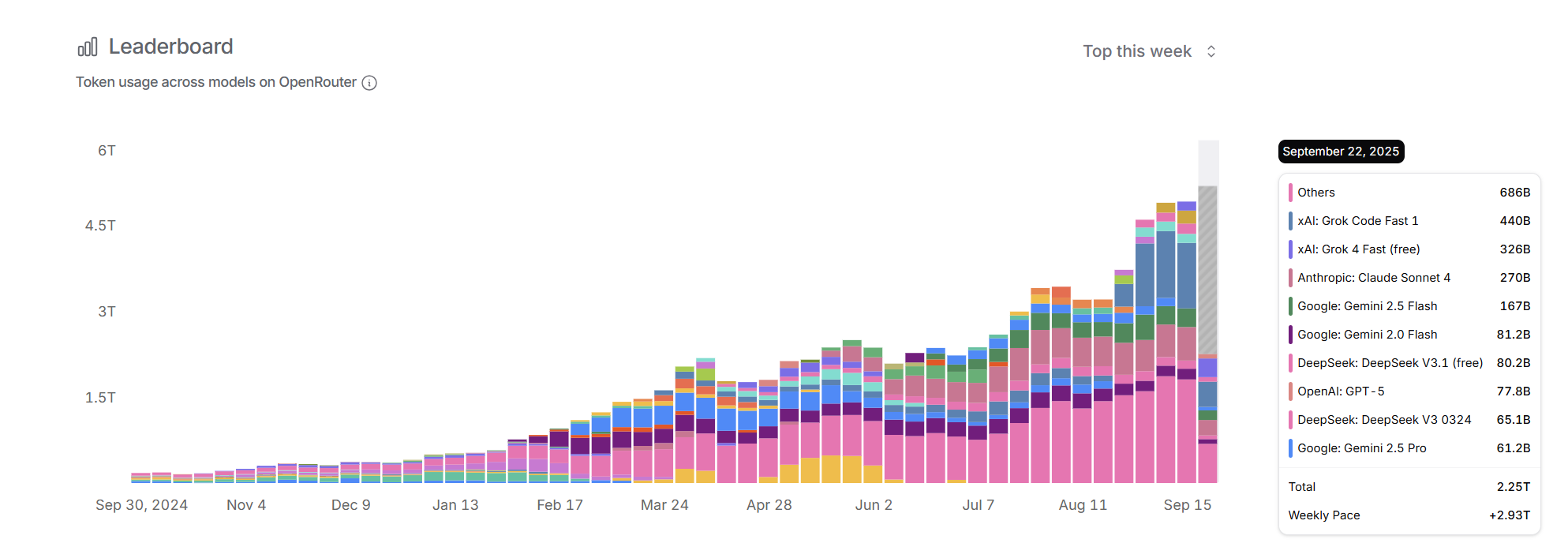
OpenRouter Rankings
OpenAI's GPT user persona data tells another story: a profile entirely within the ChatGPT app. Usage increases rely mainly on incremental users. In the app environment, the daily average usage frequency of existing users grows very slowly, far from doubling every few months. Some say with the release of reasoning models, they think longer and provide longer answers, so token volume will grow more. Of course. But if you are a user, would you be willing to pay 50% more for an app whose daily usage frequency only grew by 50% in a year? Some would, but the vast majority would not.
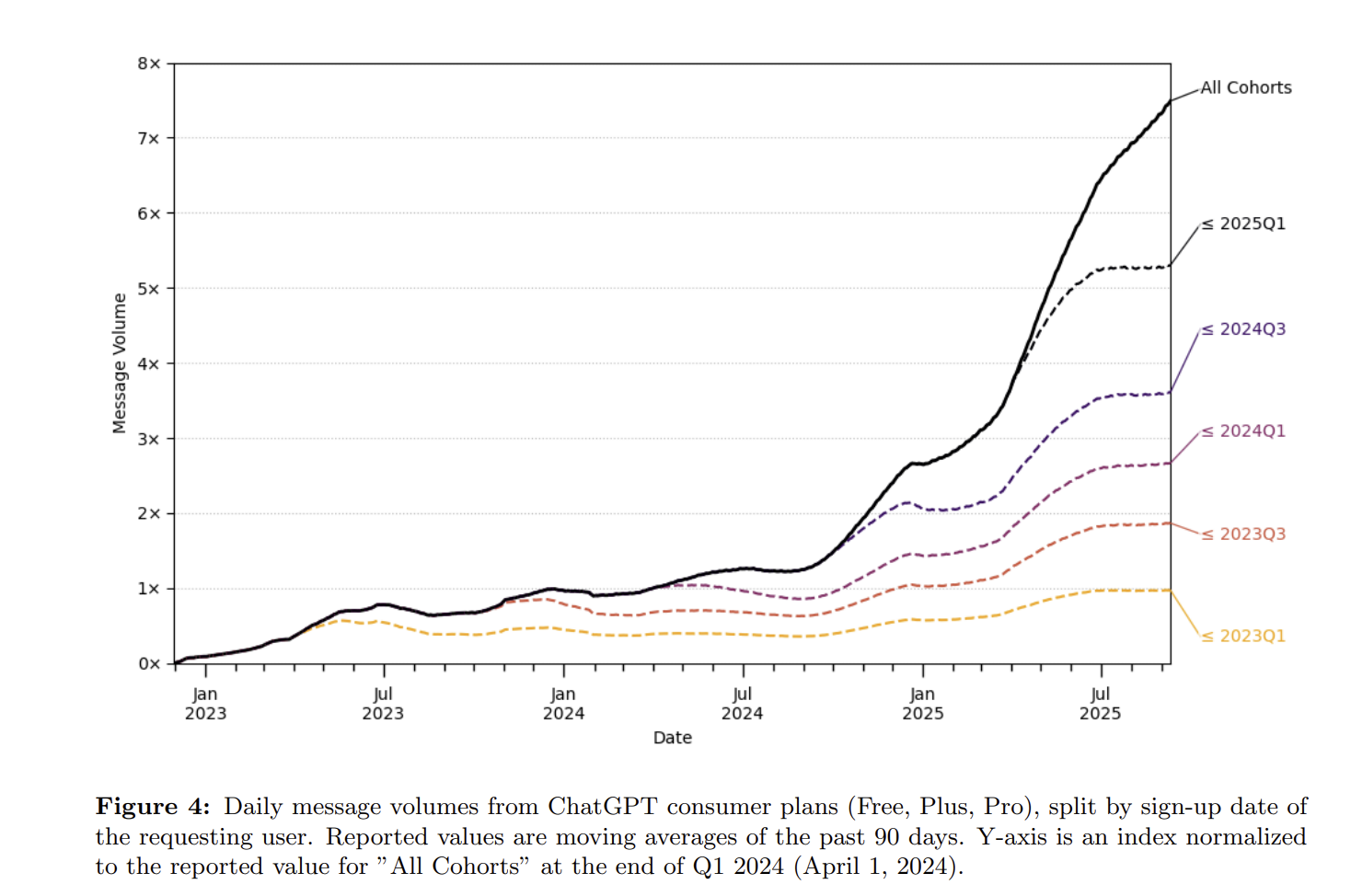
OpenAI: How people are using ChatGPT
We can almost conclude that what truly brings massive token growth is AI search and AI code generation. Since the beginning of this year, these two have driven growth far exceeding previous market expectations, but the growth decay might be faster than expected due to penetration ceilings (data from the Anthropic Economic Index) and the low-cost model substitution effect.
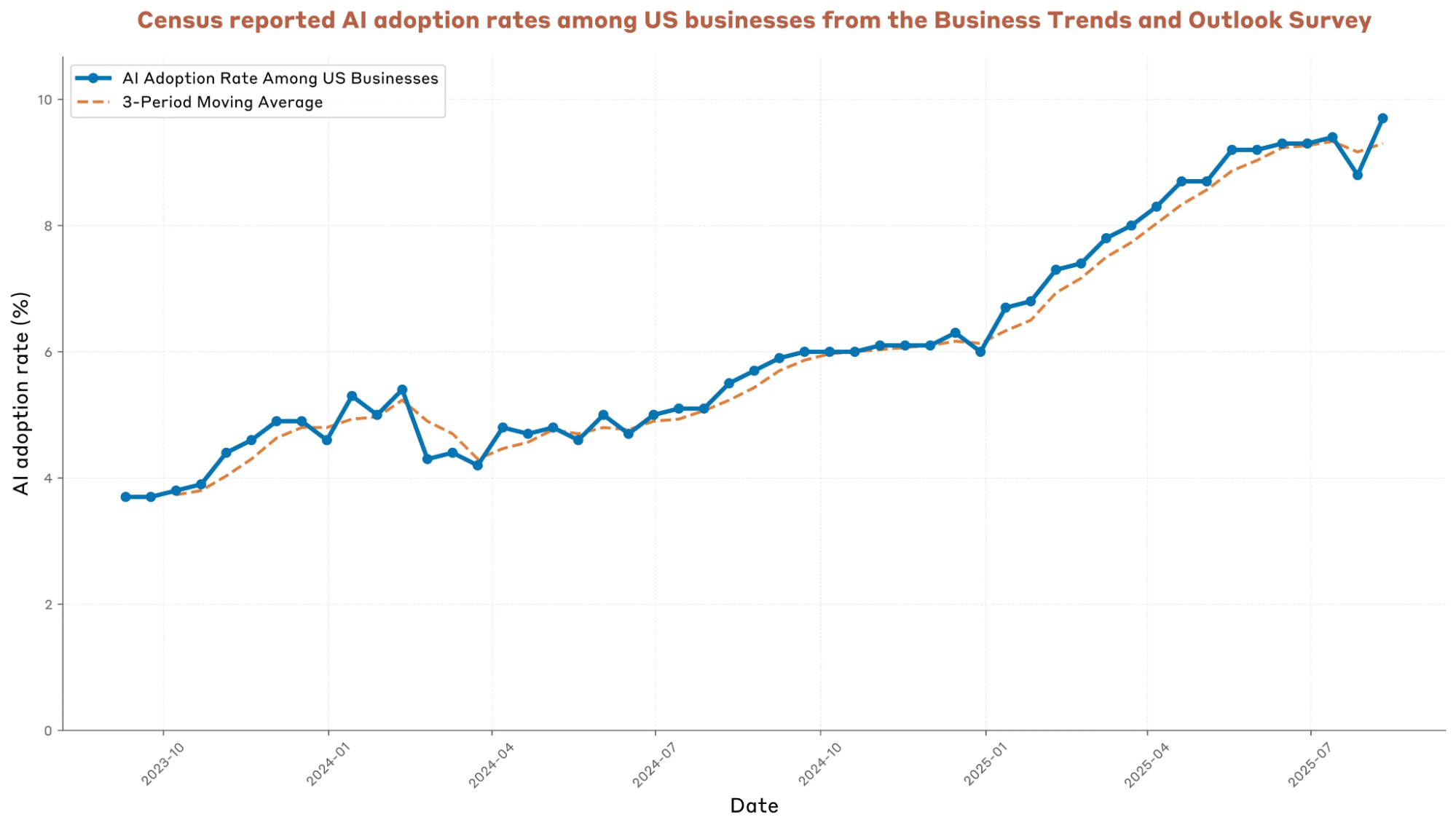
anthropic-economic-index-september-2025-report
At this point, we still have one unresolved question: models will still progress, and there is AGI or ASI—usage will definitely jump again then.
Yes, perhaps we won't even need to wait that long; multimodality could bring increased usage. Just look at how popular the Gemini-2.5-Flash-Image (nano banana) model was upon release and the staggering growth in Gemini app DAUs.
However, the scale of token usage brought by images alone cannot be compared to the scale of search and code development. One image is a few hundred tokens. The compute required to generate an image is actually smaller than imagined; look at Google's pricing. One million text token outputs correspond to about 70 images—that's exaggerated. Someone asks why image input costs $0.30? Think about it: an image is often several megabytes. Although it only corresponds to a few hundred tokens in a transformer, transmission, storage, and tokenization all have costs. It's just that transmission and storage don't use compute power.
Fine, looking further ahead to AGI or ASI, our assumption is that users will be willing to pay exaggerated prices. I agree, if it really happens.
But another implicit "physics" emerges: AI exists in the digital world, but everything supporting it exists in the physical world. Let's assume Jensen Huang and Sam Altman aren't boasting; let's assume five years from now, the market brought by computation is $3-4 trillion. But if we don't believe this will bring a 20% annual global GDP growth, we still believe world economic growth will be at a relatively normal rate: a $3-4 trillion market must correspond to at least an equivalent reallocation of labor.
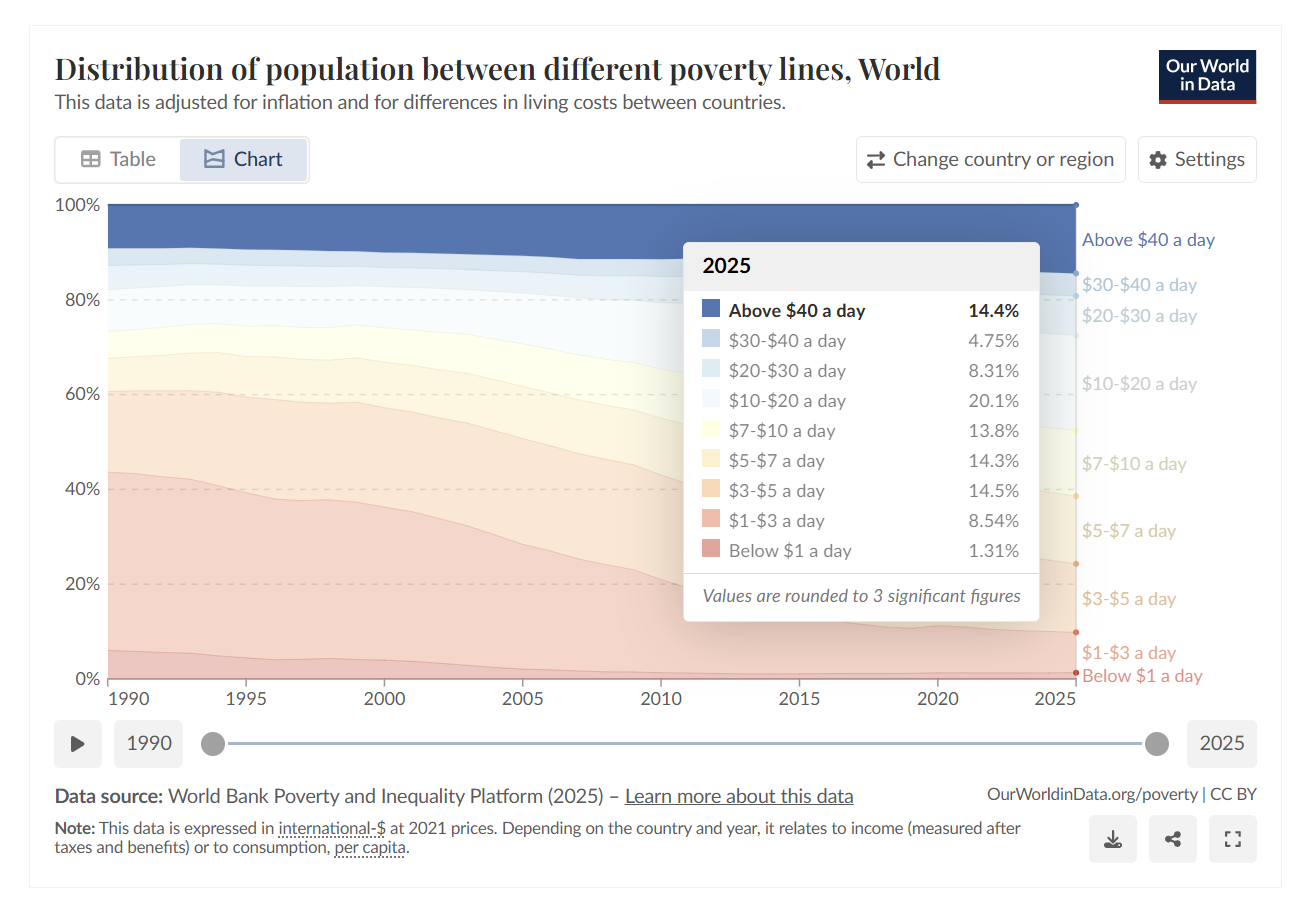
If we see that the efficiency gains from "computation" are precisely in the areas with the highest current penetration, physics appears again. According to World Bank income distribution statistics, we can easily do some math.
In closing, I know the above discussion won't change anyone's opinion. But I am not an extremist: I believe in the power of "computation." I spend most of my time every day interacting with models; I can feel even subtle changes. I believe in the future of "light."
I just prefer to believe in a reasonable calculation under the law of "Universal Gravitation."
I know that in the eyes of many, I am already paranoid and crazy, but I know I am not a paranoid, madman, or neurotic. I once tried, but failed.
I still believe that sometime between 2028 and 2030, in an extremely optimistic scenario (perhaps global GDP really has double-digit growth, perhaps cancer is cured, perhaps controlled nuclear fusion makes energy very cheap, perhaps the era of universal "wealth" arrives quickly), some model companies will indeed reach an annualized revenue of over $200 billion, making $500 billion in CAPEX look not expensive at all, even considering high depreciation.
But I prefer to believe in "physics" and the common-sense economic training I've received for twenty years.
One last sentence: on the one hand, a "bubble" clearly exists; on the other hand, the actual foundation is solid. It is just a matter of time and degree. However, I dislike the act of constantly "launching satellites" (overpromising) just to sell things, because the bet is not just on one or two companies, but on humanity itself.