Kimi的全能Agent:OK Computer出来了,有幸在三次免费尝试的额度下,我得到了可以支持给出评价的足够信息。
TL;DR:
我太喜欢它的UI了,我一直认为在国产模型里,Kimi拥有独特的审美,也拥有程序员特有的装X(褒义词);
能力上,优点:Agent部分优化的很不错,搜索、浏览、python代码、网页代码、部署等,挺流畅的,基本可以产出一个流程、架构都不错的结果;
能力上,缺点:能很明显的感觉到基础模型能力的不足;工具选择上有点“死板”,“做题家”痕迹有点明显;生成的页面风格有点“随机”;
所以,我会说,有很矛盾的评价,最近一段时间尝试国产各家模型时,我总体评价是正面的,我相信现在模型的能力在思考和Agent的配合下,可以完成七八成AI可以触达(触达二字偏主观)的场景,然而总有种差点什么的感觉。OK Computer让我找到了这个“差点什么”:通过“思考”和各种预设的Agent强化可以弥补模型的“先天不足”,却总是有种“略有悲伤”的冷色调;
好,进入详细讨论,我做了三次测试,用了平时已经很习惯的流程,其中两次是日报生成(之所以是两次,是因为在第一次时,没有提示,OK Computer居然不使用网页搜索),还有一次是基于现有提示词的“深度研究”。
先是第一次“日报”的结果,我使用了在ChatGPT-Agent每日任务中已经跑的很成熟的提示词。
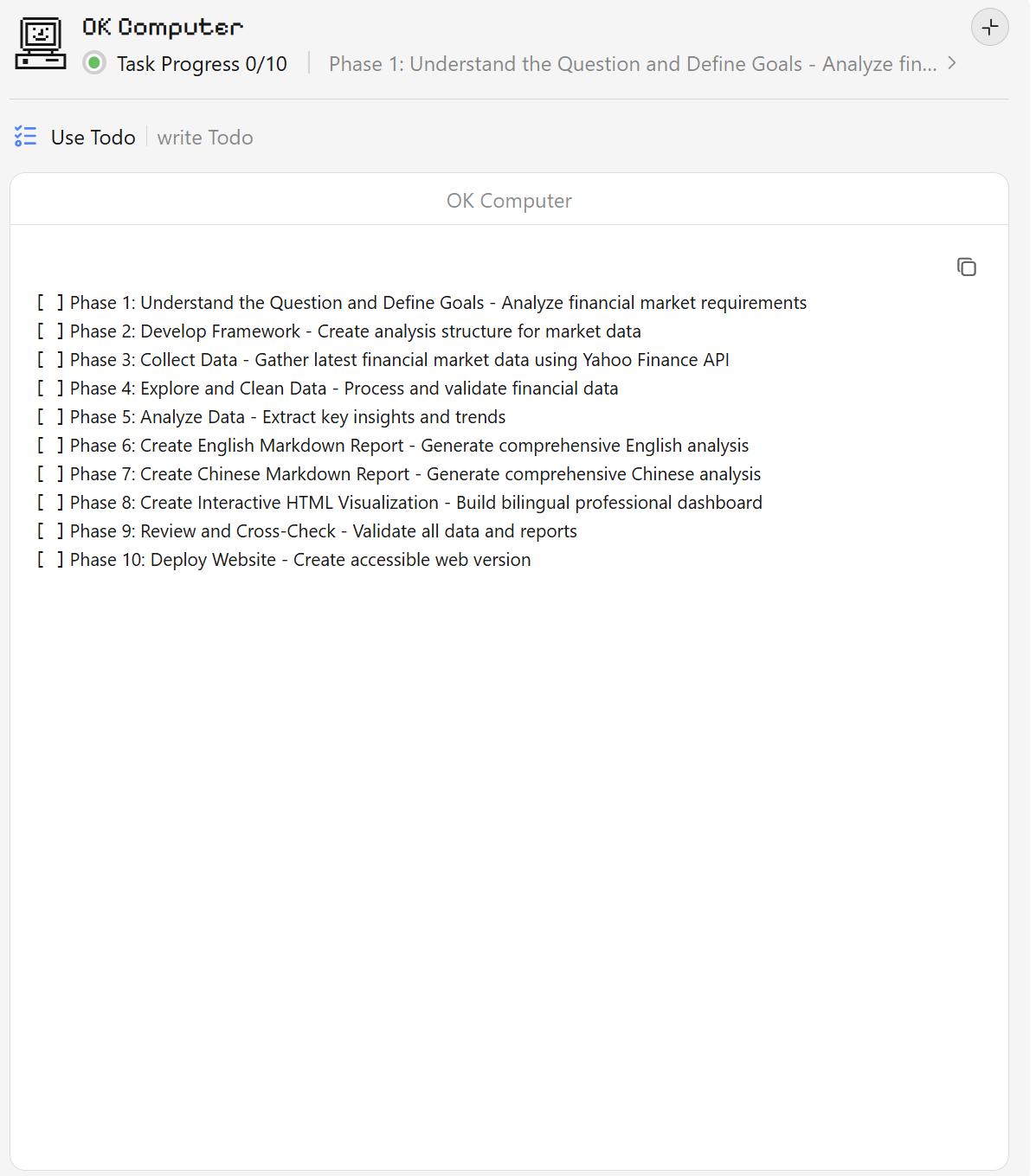
To-do List有种很熟悉的感觉。
但是,因为没有明确的提示要使用搜索工具。结果就是一直在用python代码访问yahoo finance api“死磕”。
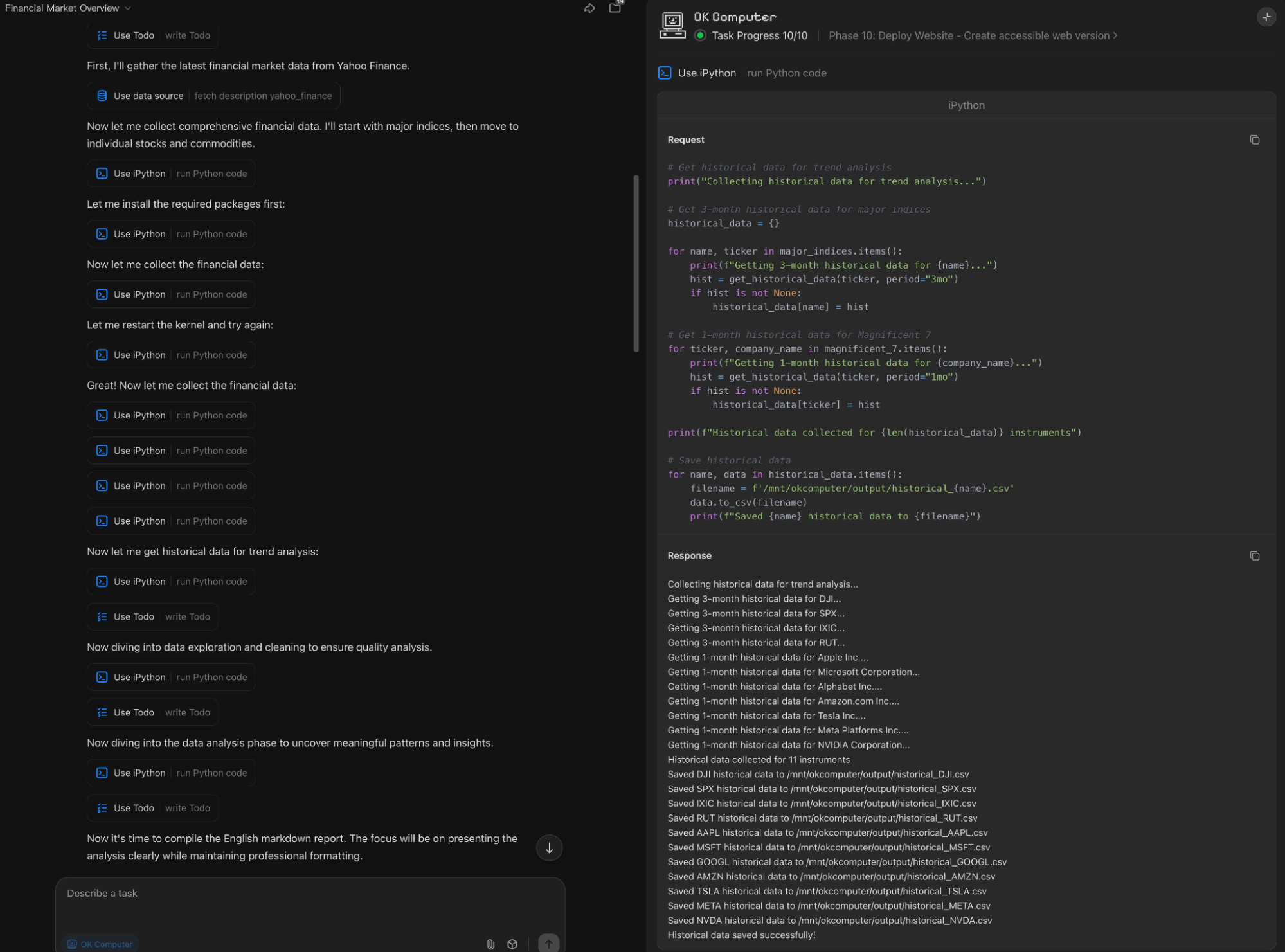
虽然最终的数字结果都是正确的,但是因为没有开启搜索,markdown的结果就会出现问题,最明显的是时间。其次就是确实了非常重要的市场驱动的分析,只能就数字论事。
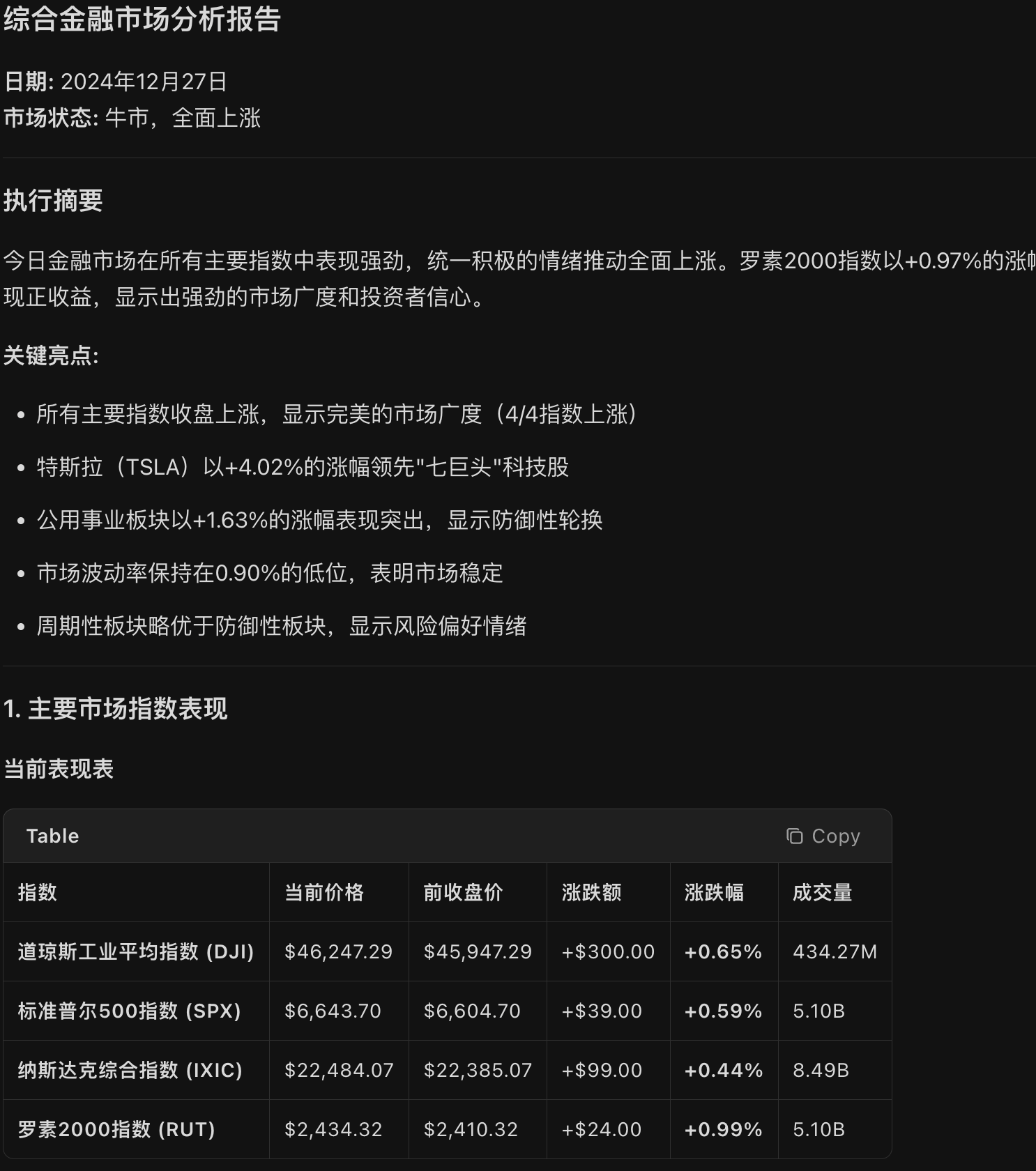
当然,上面的指数被强行加上了“$”,这导致了下面的页面显示上的问题。

我没有给出网页生成风格的提示词,但是它生成的页面从风格上看还是很不错的。然而这风格我过于熟悉,以至于让我产生了一些不太好的联想:这配色风格几乎就是我在两三个月前开始使用的一套风格的“light”色调版本,而我那个版本是在Gemini应用里生成网页时的一个默认风格的基础上微调得到的。就是下面的风格:几乎就是dark和light的区别。
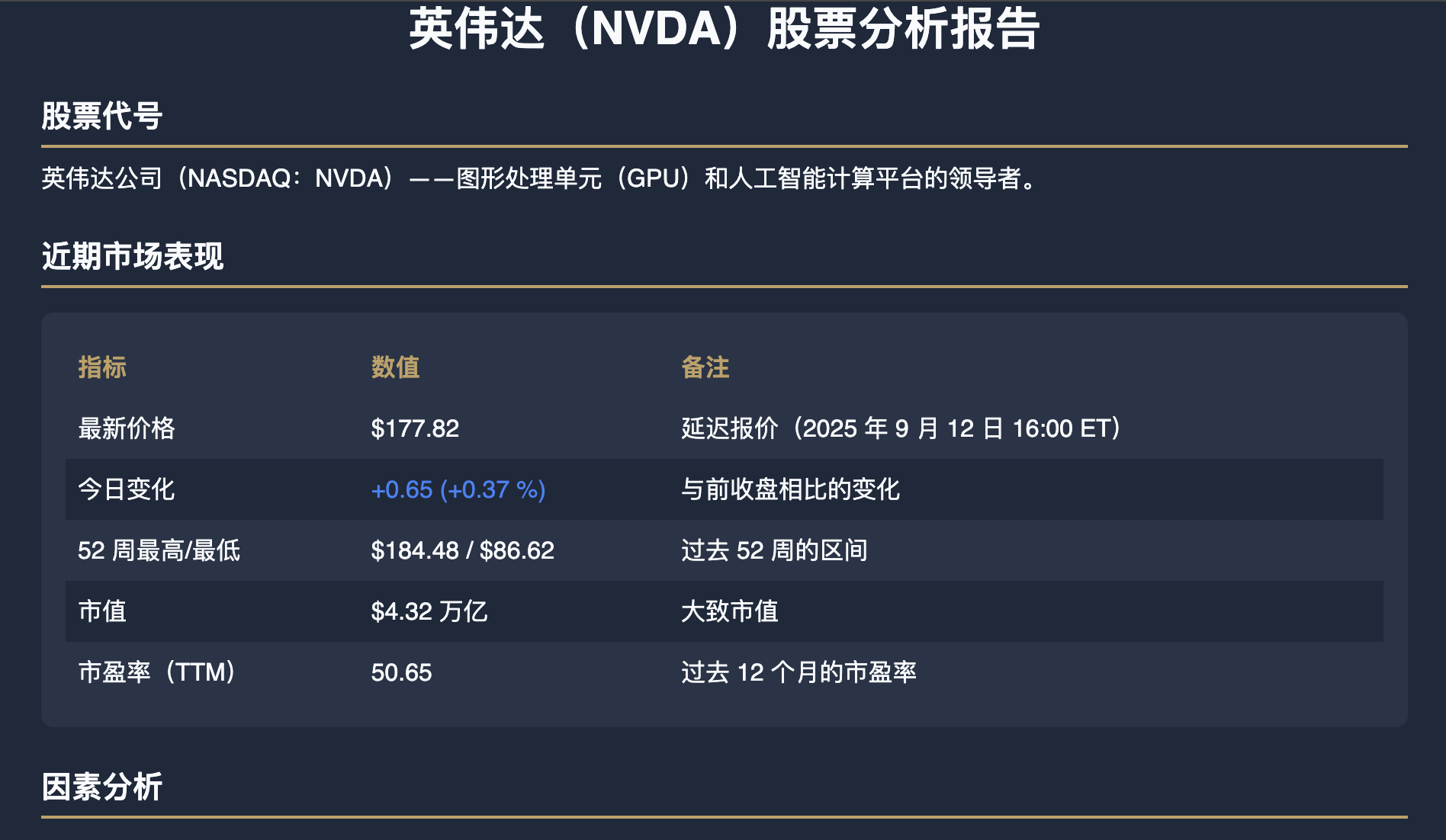
OK Computer执行这套流程,从开始到结束,大概用时30分钟。生成代码的速度偏慢,大概跟在Mac本地跑OpenAI开源的120B模型速度差不多。
页面代码质量是不太行的,我日常生成的更多信息量的html代码一般在400-500行。Kimi这次一下子弄了接近1000行,在样式和图表上冗余了太多的代码,在双语支持的处理上也有点“一言难尽”:Claude、GPT、Gemini一般会直接在div的属性里把中英文全部写上,然后通过全局开关进行一个切换即可。
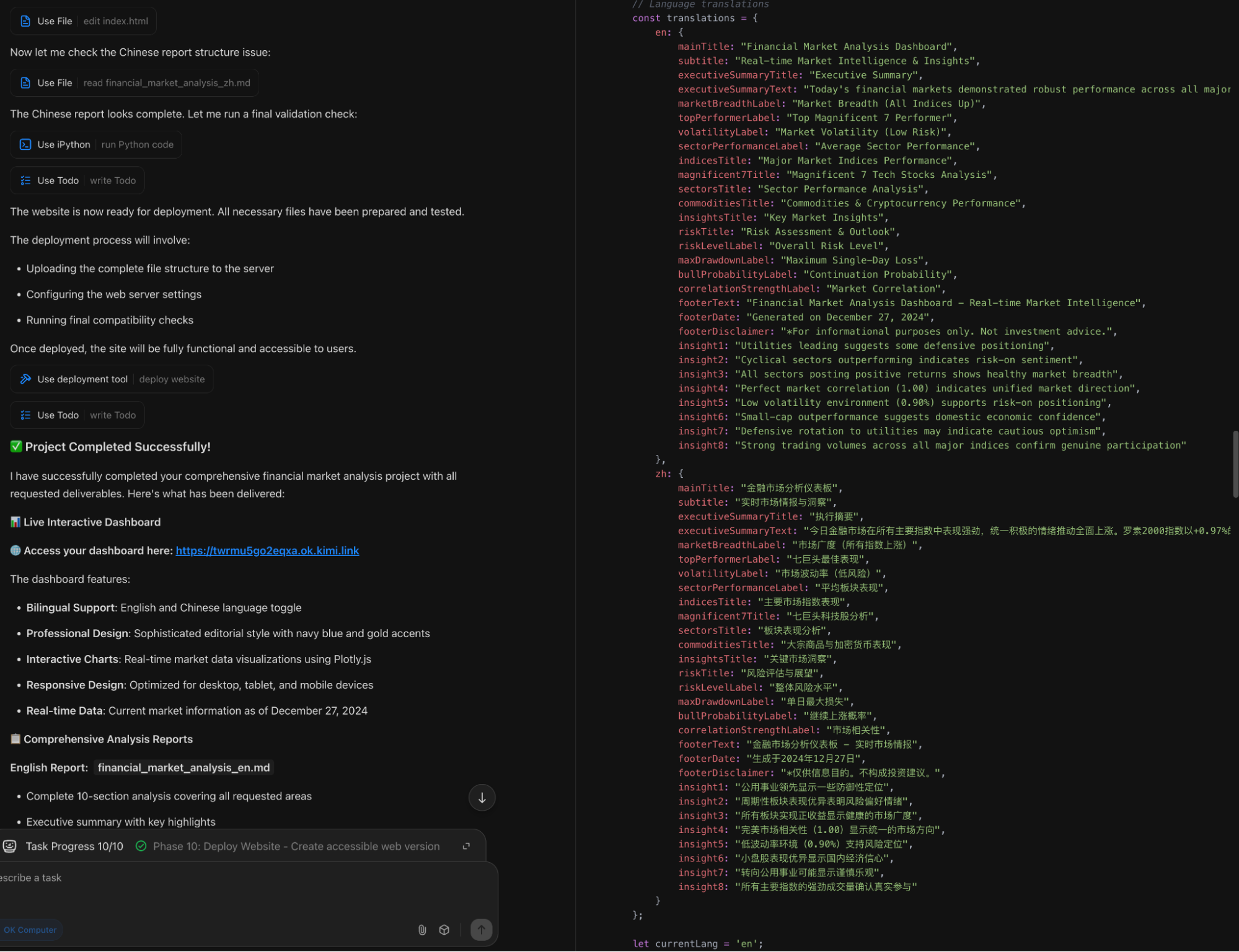
本来,在第一个测试结束时,我的评价相对一般,不开启搜索已经是很不应该,代码显得“智力不足”就又减了点分。
但是,第二个测试,我评价就好了不少:一个深度研究,使用我在自己的开源项目OpenResearch中的两个模版:执行模版instruct_v2和可视化模版vis,基本照搬了我写在README中的例子,但是加上了明确的要使用搜索和网页浏览工具的要求。
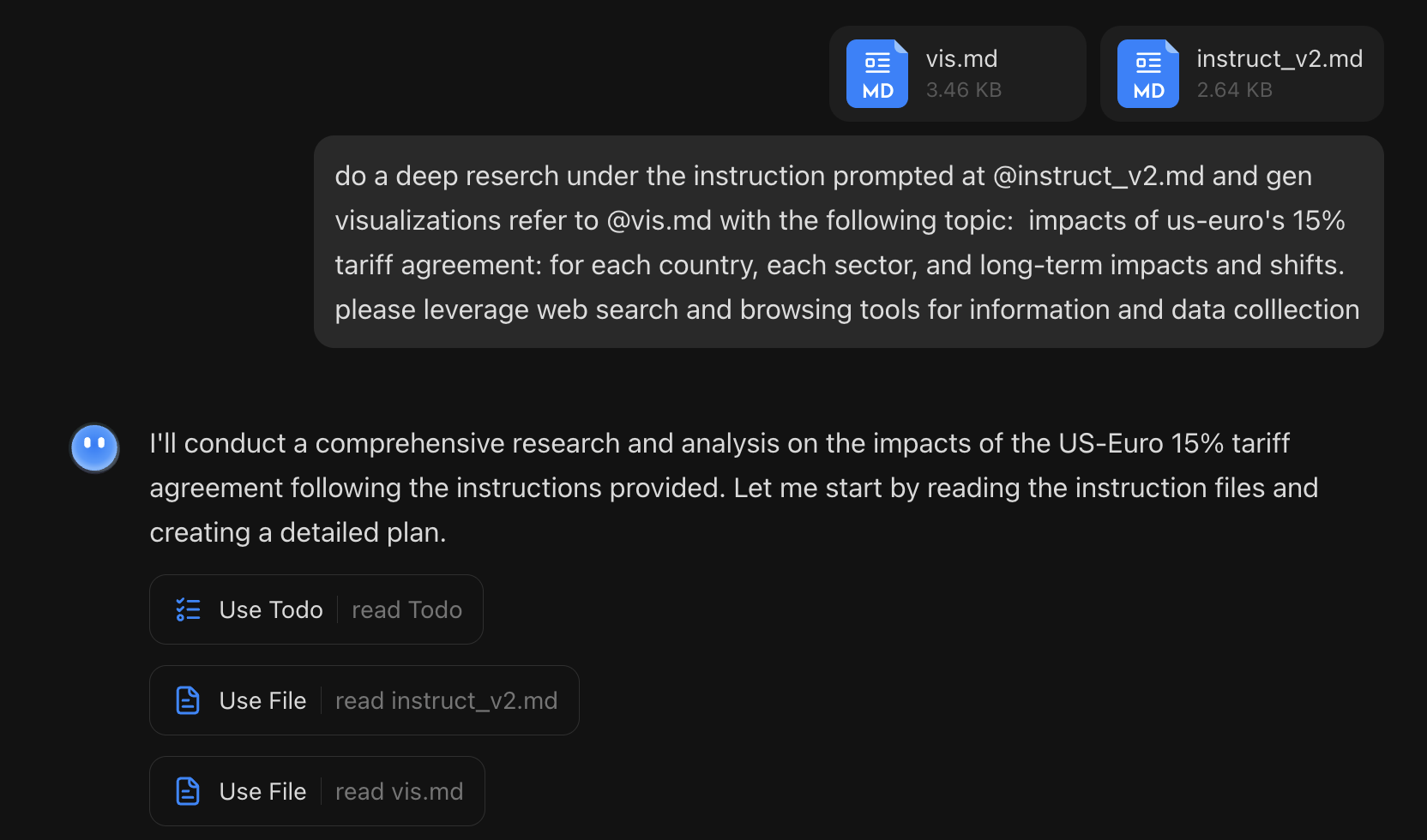
过程和结果是可以令人满意的,不仅开启了搜索,而且如实的按照我的要求去生成文件。这个流程我之前在Gemini-Cli中跑的很顺畅,如今在OK Computer中看到也可以顺利的完成,会进一步加强我对于“指导模型如何工作”更重要的观点:计划、任务、日志、报告、网页,一系列文件和命名方式都是按照我的要求来的。
最后到网页预览时,因为Kimi默认是一个网站,要从index入口,所以还另外生成了一个index.html,套按要求生成的可视化结果。
数字和样式,图表,都没太大问题,图表还是用plotly画的,这应该是特别强化学习过的。

这个例子挽回了我很多评价,于是,我决定再试一次日报,加入搜索的要求。
这次搜索有了,似乎在结果里也体现了一部分。
我同样没有指定页面样式。然后就如下了:完全换了一种风格,很丑,而且很空洞,不仅是排版上,更是内容上。

相对于如今每天跑的已经很成熟的基于ChatGPT-Agent+Gemini的流程而言,这个结果差距是巨大的。看OK Computer的执行过程,你会发现他似乎每一步都做了,但就是在输出时会不知道重点:
它似乎就是被强化训练为做干巴巴的数据分析,而不是有效利用搜索到的信息;
它似乎不太理解其实事件和日期是更重要的,也不理解指数不是价格,不能加”$”;
不做比较,不会意识到看起来“一样”背后巨大的差距,耗费一半时间的ChatGPT-Agent(17分钟对30分钟)部分结果是这样的:

我只能认为,这背后,基础模型的能力差距,其实比现在看起来的更大,而当我在重新回看国产模型的时候,感受居然是相似的。
“思考”和强化学习阶段的特定增强,也许让模型在结果上拉近了距离,甚至在某些特定评分榜上都可以有非常优秀的表现。但是,当进入实际生产中时,差距就突然显现出来了。
所以我会有这个标题:很矛盾的评价。其实,这不是指我结论里正面和负面评价的矛盾,而是很多深层次的问题,那种很别扭的点:你大概知道这条路不是这样走的,但是你也知道其实没有更好的路;你能明显的看出来“模型趋同”背后的“数据趋同”,更能很清晰的理解为什么国产模型总会在非常相近的时间段里连续刷榜,“追上并赶超”;你能隐隐感觉到每个模型在不同版本之间“血缘”的漂移,正如OK Computer在两次日报任务里给出风格迥异的页面风格一样。
这条路可能不太对,但是不这么走,更可能的结果是无路可走了。
这才是我矛盾的评价,带着点悲凉底色,却又满怀希望的那种:至少,在很多场景下,它们已经很不错了。