During the domestic holidays, the focus of anxiety has shifted to how to "rest." I've managed to force myself out to take photos every day, but trying to force myself to read a book hit a snag: it seems difficult to settle down and read long-form books now.
So, I remembered something I did before—generating a website to read books.
Let's put Kimi's OK Computer to work.
The source material is a history of the Holy Roman Empire, spanning over a thousand pages.
The process went smoothly, taking about half an hour, but the immediate result was quite stunning. Here is the link: https://i2b4fdmxctjaw.ok.kimi.link
Below are some screenshots. The aesthetics are fantastic; it feels more like a game website than a book guide.
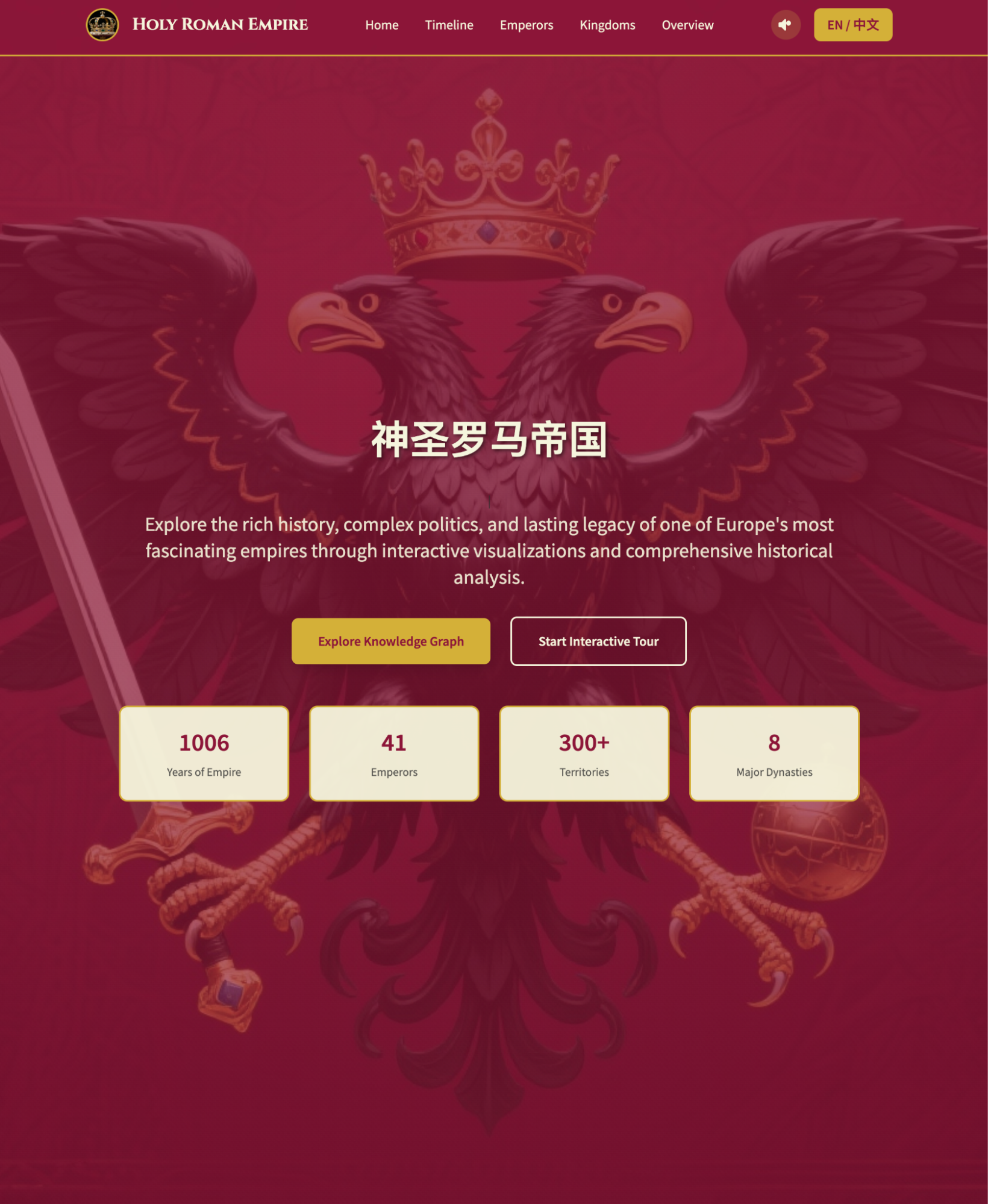


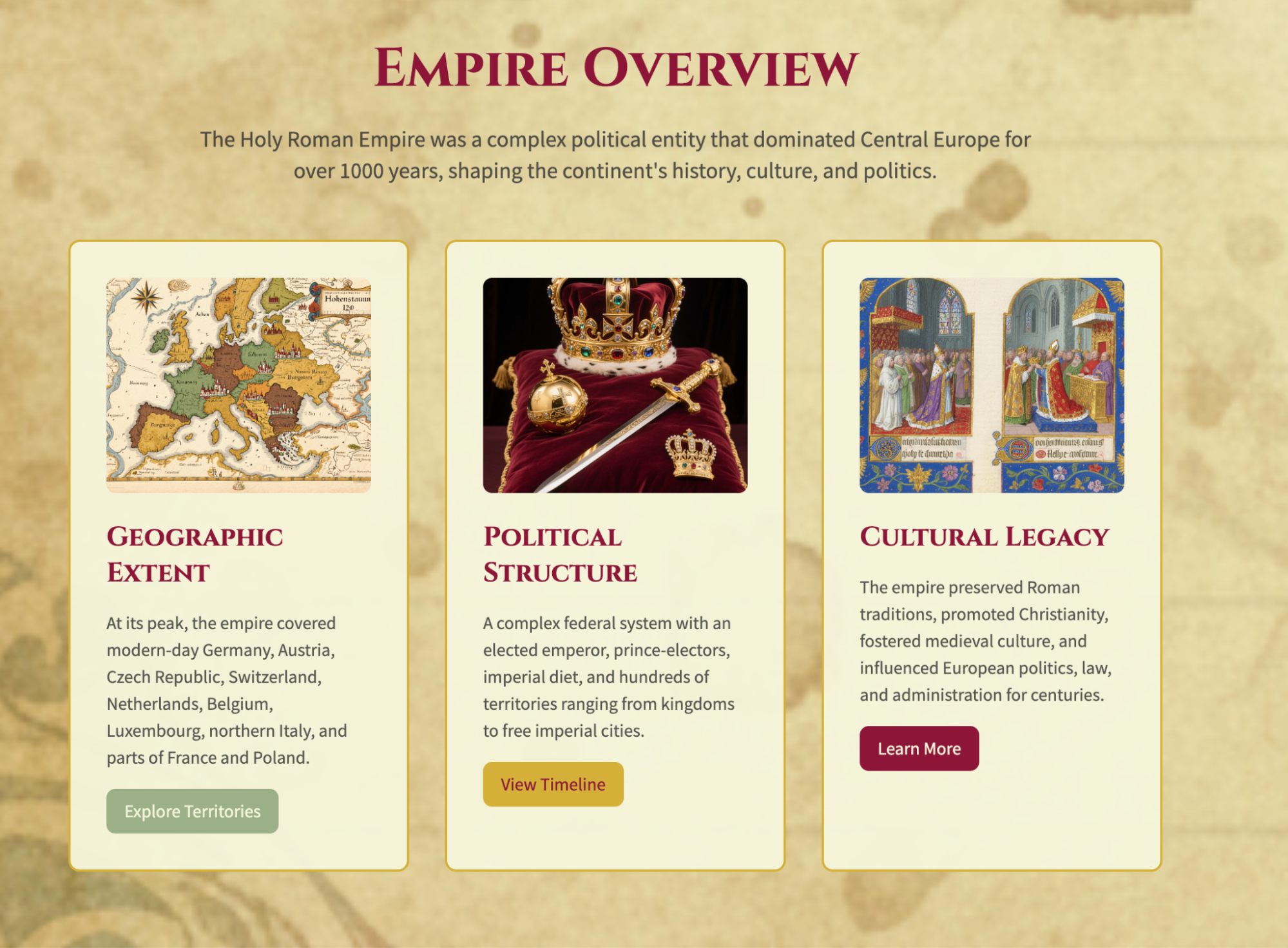
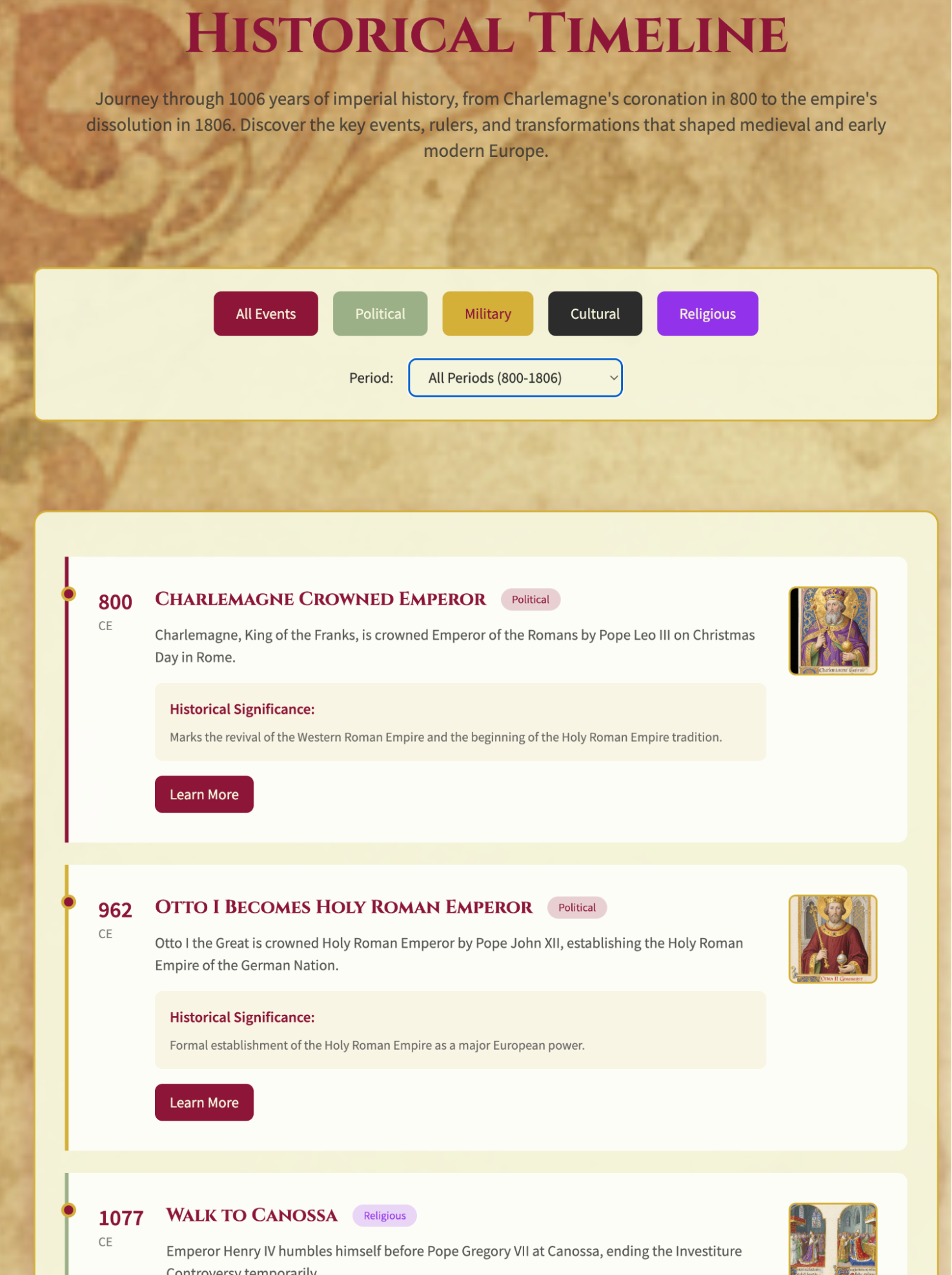
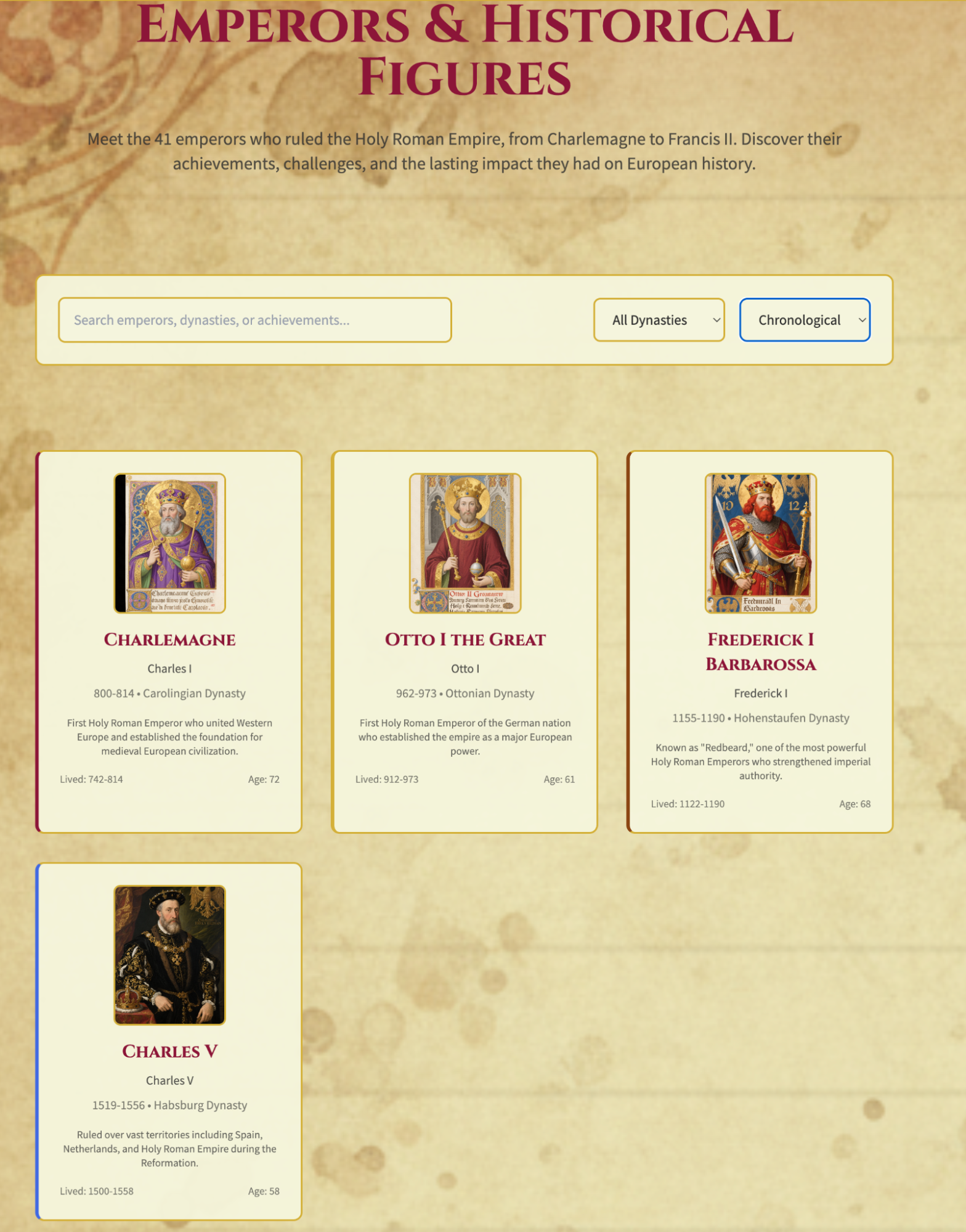
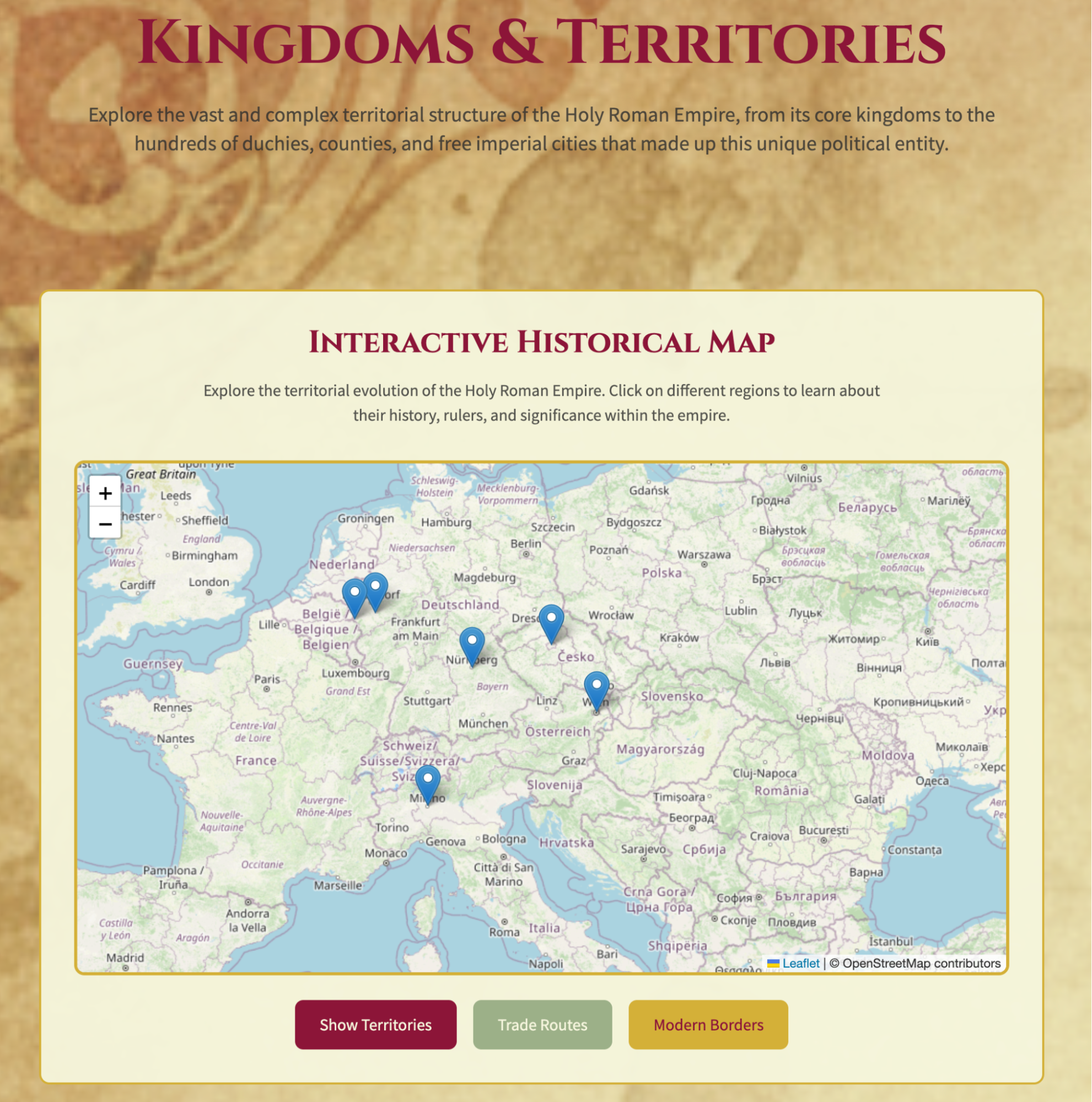
First, high praise: Honestly, the completeness, relevance, and aesthetics completely exceeded my expectations. I think this might be the best use case for OK Computer.
Now for the critiques: As you can see, based on my requirements, the interpretive audio and the illustrated audiobook content are mostly there. However, the code files are mysteriously truncated in various places. It's possible the context is simply too long, exceeding the model's capabilities.
Moreover, as I have mentioned before, every input request consumes one call quota. In this instance, I got results on the first try, but to have it fix the code truncation issues, I spent ten more attempts. Sometimes one page file would look complete while others would break; those ten chances were quickly consumed in this "infinite loop."
Combined with other previous attempts, my basic subscription quota for the month has been exhausted.
To be fair, I don't feel too negative about these "bugs." Instead, I've found the advantage of the "diligence" I've been contemplating lately. As for such bugs, I believe they will be resolved in the future.