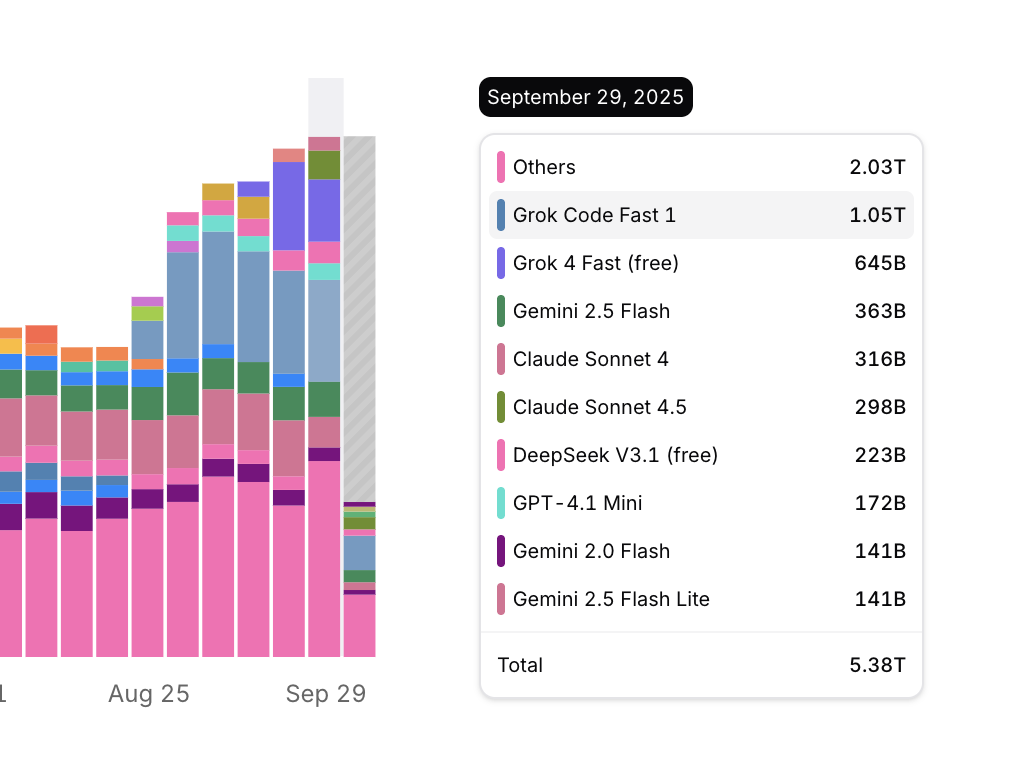
The holiday has ended. Here is a brief report on the news from the period and my own experiments and reflections, serving as my holiday assignment.
I. Model Release Pace
Anthropic updated Claude Sonnet-4.5. It shows a significant improvement in coding capabilities compared to 4.1. However, it's unclear if it's a model issue or an application development problem, but several friends and I have experienced Claude Code crashing. Preliminary analysis suggests it might be due to excessive memory and CPU consumption by background processes.
Gemini-3 is about to be released. Objectively speaking, GPT-5 as a whole will at best be on par with Gemini-2.5 and Claude-4. Claude possesses stronger coding abilities, while Gemini offers complete multimodal capabilities. With Gemini-3 imminent, OpenAI has fallen behind.
This is likely why they are so desperate to lock in "future compute": following their roadmap, they are naturally starving for computing power. They are eager to make the narrative massive, otherwise, they can't keep playing; they are also trying to restrict other potential competitors.
Grok-4 has also been updated with even cheaper pricing. Currently, it has entered my list of models to watch closely. In fact, GPT's biggest potential competitor might be Grok.
II. Sora-2 and Multimodality
In terms of video capabilities, Sora-2 is at least not noticeably superior to Veo-3. Regarding audio-visual synchronization, voice-to-lip matching, and physical realism, Google's Veo-3 has been leading for several months. Even with the current Sora-2, if we set aside the social media aspect (which mostly features single or double characters in simple scenes), Sora-2 might even lag behind Veo-3 in terms of information density.
Tencent's Hunyuan 3.0 was released, and its text-to-image model now supports Chinese rendering. The overall effect is quite good, but there is still a clear gap compared to Google's nano-banana in terms of texture and information density.
One can clearly see the massive advantage of the Gemini series models in training data.
(Under the same complex prompt, the degree of fit with real scenes directly reflects the volume of training data).


Returning to Sora-2, even ignoring copyright controversies, the claims by many that it will "disrupt Hollywood" or "disrupt TikTok" might not be impossible in the future, but there is still a long way to go.
As for whether this type of multimodality will generate massive demand for model calls and significant revenue, the answer lies in everyone's heart: are you willing to pay for the current quality? For me, as a supplement included in a subscription package, it's great, but the usage volume can't possibly compare to search and code generation.
I truly believe, as I have repeatedly stated, that what will bring massive usage later is multimodality, but not this kind. It will be the multimodality based on Gemini that integrates text, code (frontend visualization), images, video, voice, and even music. For example, the videos I post every trading day: they change daily workflows, and because of the introduction of multimodality, they enhance or at least enrich the product form. Simultaneously, they offer a massive information compression rate for the audience (information searched across the web eventually converges into one image, one audio clip, one video), with a very strong logic for scaling up and standardized mass production behind it.
Video generation models are still far from this; they can provide assets but cannot yet function as an independent product without human intervention.
III. OpenAI and Compute Investment
When considering OpenAI's various partnerships and massive "future investment amounts," it boils down to two numbers. One is from Google's own paper stating that an average Gemini request consumes 0.24Wh (https://cloud.google.com/blog/products/infrastructure/measuring-the-environmental-impact-of-ai-inference). The other number is that if all high-end chips produced by Nvidia this year are deployed next year, they will require over 10GW of power. Assuming half is used for "dreaming of AGI" and the other half for model inference at 80% utilization (4GW), that’s 96GWh per day. Divided by 0.24Wh, that equals 400 billion Gemini requests. We can assume future requests will become more complex and consume more than 0.24Wh (though this contradicts the laws of technological progress), or that usage will increase dramatically. However, looking at the SimilarWeb screenshot I just took, the total visits for the top twenty sites in August don't seem to exceed 200B, averaging 7B per day. (https://www.similarweb.com/blog/research/market-research/most-visited-websites/)
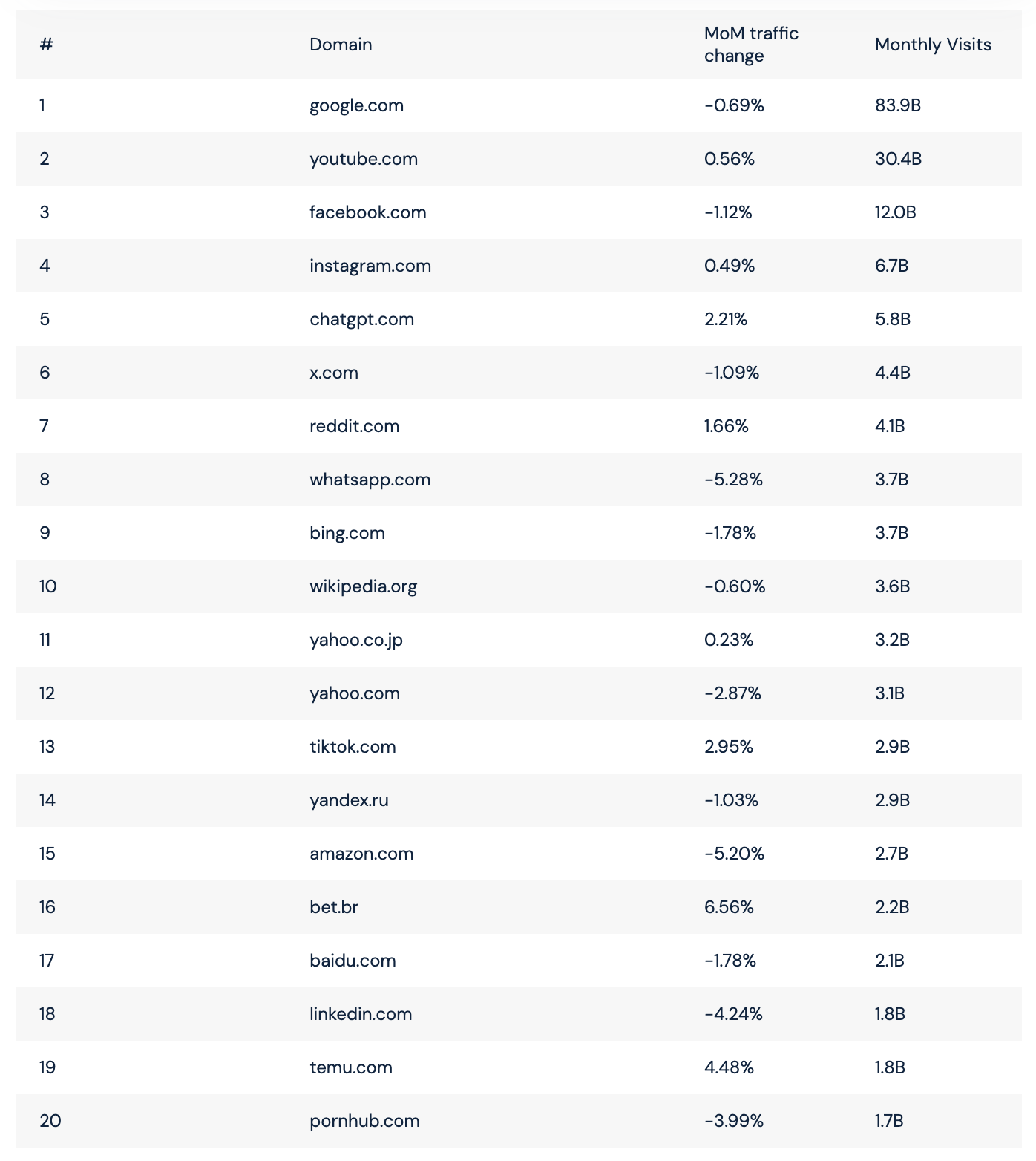
If we further consider the narrative pushed by model manufacturers that inference energy consumption will decrease over time, can we still conclude there is a "compute shortage"?
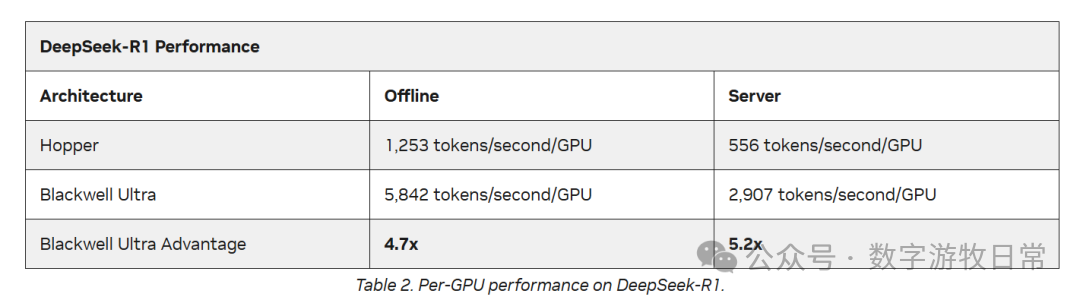
Public research has finally started discussing the decline in gross margins for Oracle Cloud (OCI), which the market almost unanimously agreed upon months ago. While I have no clear conclusion on whether Blackwell leads to lower gross margins, I am concerned about something I mentioned in previous articles: when Nvidia released the NVL-72, it claimed inference performance would be 20x higher than Hopper, but the latest MLPerf tests show an improvement of less than 10x. If this is the reality, I worry that the advantage of large clusters is being rapidly eroded by the gravity of "Moore's Law."
IV. Domestic Models
During the holiday, I tried many domestic models and agents and wrote a series of articles. I must admit there is a gap in the models, but with the support of Agents, they can handle many scenarios (many of which don't require extremely high standards). Interestingly, domestic models always launch roughly the same generation of products about six months behind overseas models, achieving similar capability enhancements in areas like reasoning, code generation, and agentic workflows. There are certain reasons behind this, but I'll leave it at that.
However, MiniMax and Kimi are generally better than I expected. Generating content websites with one click is possible, though they are almost impossible to extend. For example:

https://heuhrk3m7qjs2.ok.kimi.link

https://emcqvix47v7b4.ok.kimi.link
https://vxfismw2bmmss.ok.kimi.link
One surprise during the holiday was the Hunyuan series. Although I mentioned their image generation model still lags behind nano-banana, the strategic intent of Hunyuan's multimodal layout is very clear and distinct. At least from now on, the market will gradually demand that model companies, like Google, have solid reserves across all modalities to produce entirely new product forms through ecological integration.
Regarding ecosystems, some self-media outlets claim ChatGPT has an ecosystem. I think this severely underestimates the word "ecosystem." Microsoft, Apple, Google, Meta, TikTok, and Tencent have ecosystems. ChatGPT is just an application with a first-mover advantage. What would happen if it didn't update its model for a year while competitors updated two generations?
In my view, no pure model company is qualified to talk about ecosystems.
V. One Final Question: What if AI Models are just Software?
No matter how much "hype-men" talk, whether they are text models or image/video models, they possess none of what we humans consider "intelligence." Current models are just "optimization functions" for achieving specific goals that occasionally malfunction. To me, it looks more like highly automated software and lacks "IQ," let alone the wisdom of a PhD.
Perhaps it will happen in the future, but not in the foreseeable few years.
So, before that "intelligent" AGI emerges (if it ever does, there would be nothing left to discuss), this advanced software that can produce software itself is still just software.
Specifically, it is a type of software that will rapidly lose its market if it stops leading. It has the following characteristics: 1. It must rely on constant updates to stay ahead; 2. Each update is extremely costly; 3. It seems no single player can achieve a total monopoly, meaning there is little room for gross margin improvement.
Thirty years ago, when I was a child, programming languages made me feel like everything was possible. Today, I still feel models can do anything, but I believe all changes are happening incrementally, albeit at a fast pace.
I just don't really believe in "ghost stories."