
Recently, my personal search behavior has undergone some changes: more and more searches are returning to Google, though "gossip" and "word lookups" still happen within Perplexity.
For some reason, the quality of Perplexity has declined at a startlingly perceptible rate. In contrast, Google Search, with the addition of "AI Overview," has seen a significant improvement in experience. The model remains the most important factor—not just its raw capability, but the balance between capability and cost.
Search was the first AI application area where I predicted a massive explosion in demand during my outlook at the end of last year. This has indeed proven true. However, my perspective was not based on "human use," but on "AI automated calls." The ceiling for the former is roughly several times the current average daily Google search volume (perhaps 2-3 times?), which is currently under 2 billion. The latter, however, is virtually limitless. In an extreme scenario, AI could perform numerous information retrievals and summaries for every person every day, eventually compressing them into a simple infographic, a single page, a voice snippet, or even a short video.
Therefore, to have an unlimited ceiling, two requirements must be met, which I summarize as "Iteration" and "Compression." Iteration means giving the model an initial task that it can evolve on its own—whether through step-by-step searching to exhaust information or continuous experimentation to exhaust possibilities. As long as computing power is sufficient, it can execute until all results converge.
Clearly, in theory, AI programming also meets these two requirements.
Many people talk about Agents. As I've said many times, the essence of an Agent is programming and searching, which also includes the generation of other modalities (voice, images, video).
Simply put, while AI still requires the human species, its goal is to "show results to people," and its method is "calculation."
As tokens replace traffic as the most important baseline metric of the AI era, the volume of iteration determines the token quantity, while the compression rate (the volume of tokens processed versus the human time spent receiving the result—e.g., seconds to view an image, words read per minute, or a one-minute video) determines the multiplier of the ceiling.
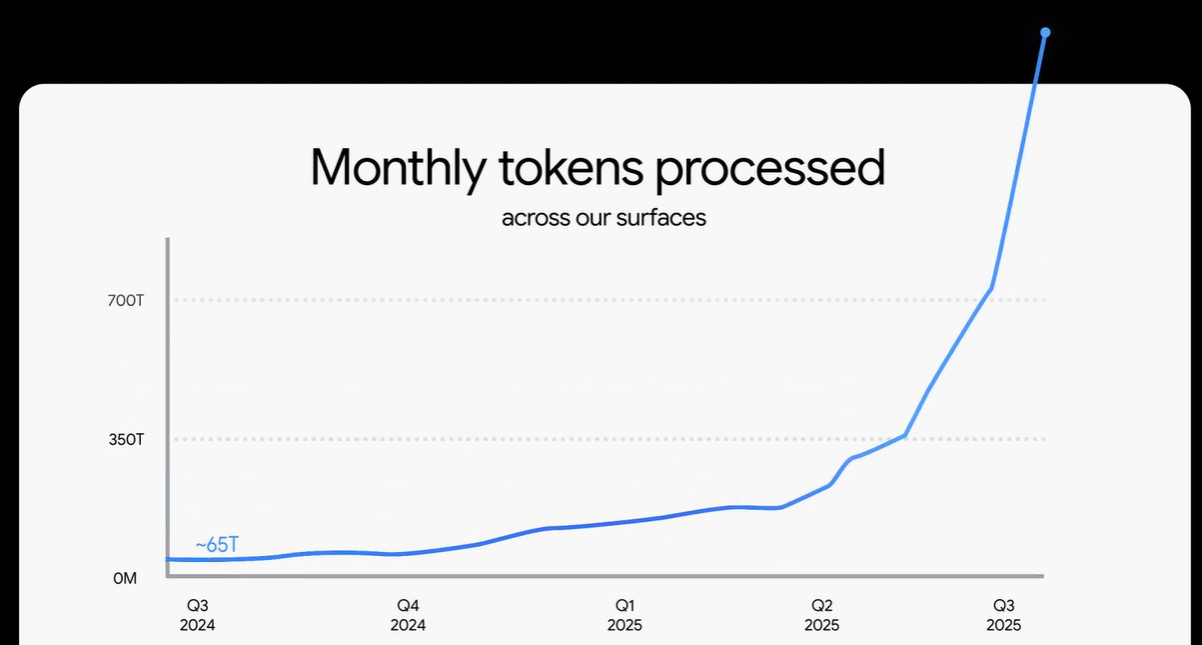
Relying solely on search and AI Coding (mostly search), Gemini has "drawn" an exponential growth curve in token usage. Based on AI coding alone, Anthropic (the parent company of the Claude model) raises its annual ARR expectations every month, recently even dangling a "carrot" of $20-26 billion ARR for 2026.
The above serves as a prelude to the two topics for today: 1. Who will carry the banner for the next explosion in token usage? 2. Theoretically, even without new modalities, search and coding alone have infinite space—so what does the reality look like?
Regarding the first topic, many people, including myself, have focused on multimodality, especially after the release of Sora 2, which showed many the huge potential of AI video.
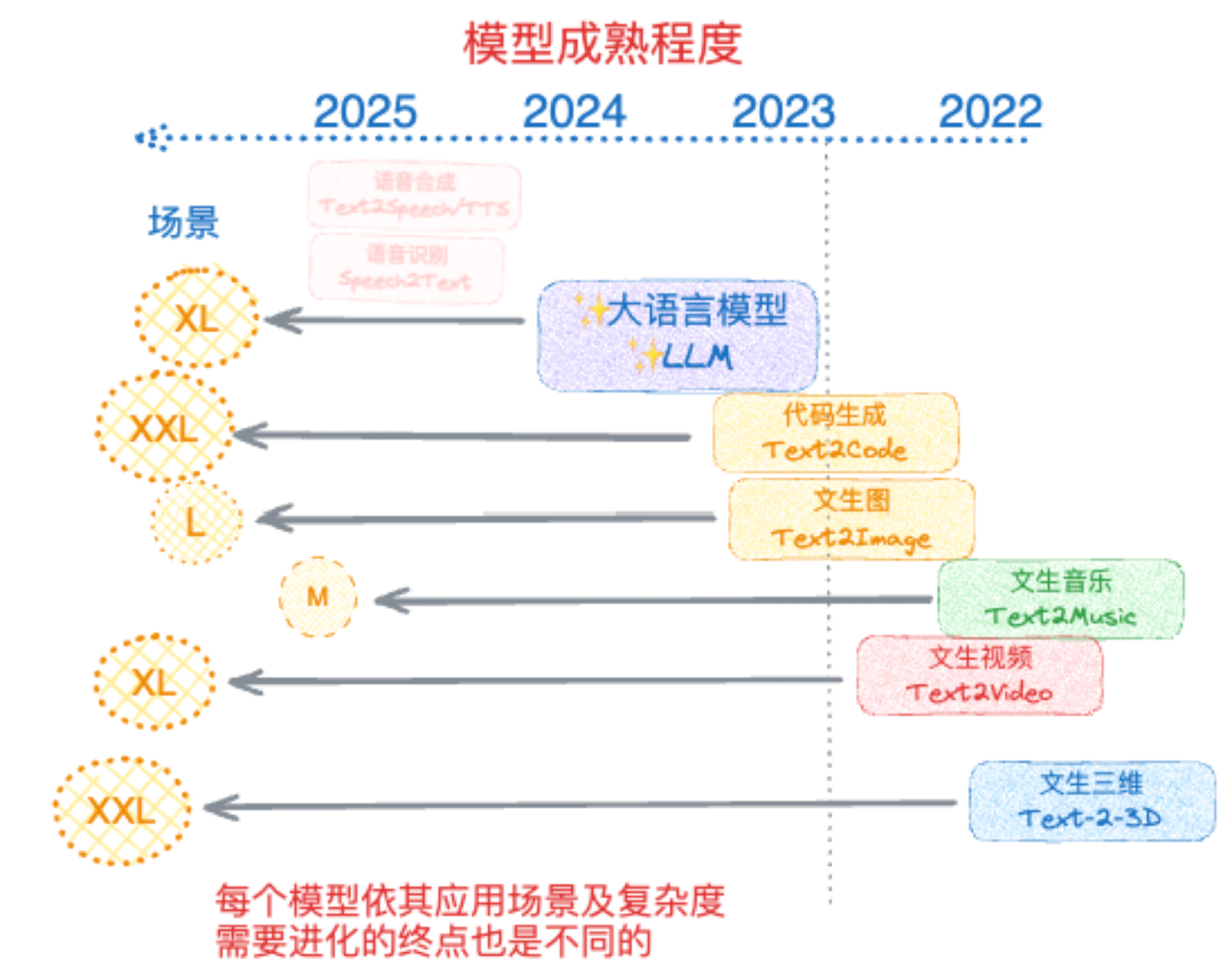
The chart above was one I drew at the end of 2023. The vertical dashed line represents the "ChatGPT moment" or the "GPT-3.5" moment at the end of 2022. The positions of different modalities represent where they stood relative to the "GPT-3.5" moment at that time (second half of 2023). For example, LLMs had clearly advanced with the appearance of GPT-4; text-to-image and code generation were actually usable. The oval circles on the left represent a qualitative comparison of potential market sizes for various scenarios.
Of course, I used the terminology of that time, as everyone liked to call models "Text-to-XX," meaning generation via text—which is both correct and incorrect.
At the time, search was categorized under LLM, as it was essentially an LLM calling search tools and processing results. This, too, is both correct and incorrect.
Looking back now, coding capability clearly crossed the "GPT-3.5 moment" long ago. With the start of GPT-4o's image generation model, that too can be considered to have crossed over. Now, nano-banana has gone further, and Sora 2 should at least be considered to have arrived.
So, these modalities indeed have the potential to "explode."
However, considering two aspects, images and video might not reach or exceed the current token usage of AI Search and AI Coding as we imagined.
First is the current volume. In my previous article, I calculated the token volume for images and videos, based on Google data.
The conclusion is this: Google Cloud has processed 13 billion images and 230 million videos (assuming 8 seconds each) to date. The total token volume for these images is 20T, and the video volume is about half that. This is the total cumulative processing to date, yet compared to Gemini's monthly volume of 1.3Q tokens, it represents only about 3%.
Of course, many would argue this is just the beginning and there is massive future space. But if we return to the second requirement of the ceiling calculation—compression rate—the judgment might differ.
First, why do we produce images and videos? It is for "humans" to see (some will disagree, asking if training autonomous driving and robots requires generating many images/videos. The difficulty in writing articles is having to constantly fill "logic holes." Ask yourself: why show images to "robots"? Is it not ultimately because humans see the results? Furthermore, even with more models being trained, they cannot compare in scale to eight billion humans). This point alone creates a massive difference.
Secondly, while one could say processing a lot of information is required to generate images and videos, they are ultimately restricted to the medium of images and videos as the human-machine interface. They will also face intense inertial competition from the "real world." Even before AI generation, we admitted on social media that there was too much content and information overload, not a lack of it.
I'll post a Gemini Deep Research result image below:
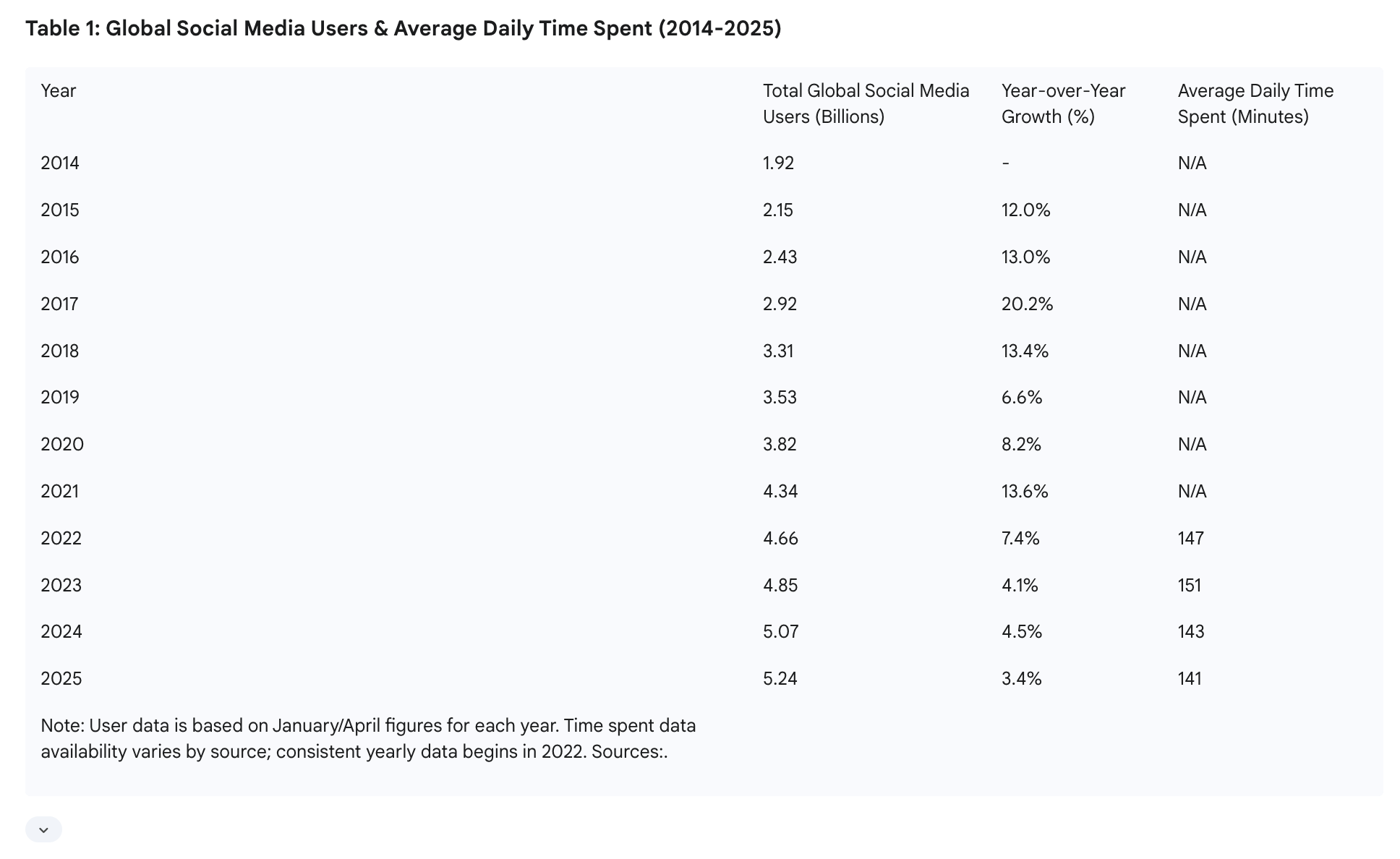
This shows all social media users and their average usage time. If we convert 141 minutes into seconds and multiply by the number of people, we get 44.3T seconds. Assuming all modalities were video, 44.3T is the total daily seconds of video watched across the network. Video consumes roughly 15k tokens per second. So, total viewing is less than 700Q tokens, but viewing does not equal generation.
Data from https://influencermarketinghub.com/how-much-content-does-tiktok-generate-in-just-one-day-study/ shows the average TikTok video has 2,500 views. If we assume the average duration of long and short videos combined is 15 seconds, the calculation results in 17.7T tokens. I still lean toward this being an overestimation, but let's assume there is room for growth.
If we assume all social media content (human attention) becomes AI-generated video, accounting for growth, a rough ceiling is about 20T tokens per day, or 600T per month—less than half of Gemini's token volume last month.
Of course, one could challenge these conclusions: why post to social media? Can't one generate videos just for oneself? Of course, anything is possible.
One could also say video will replace Hollywood movies. Conveniently, I had Gemini research movie box office data.
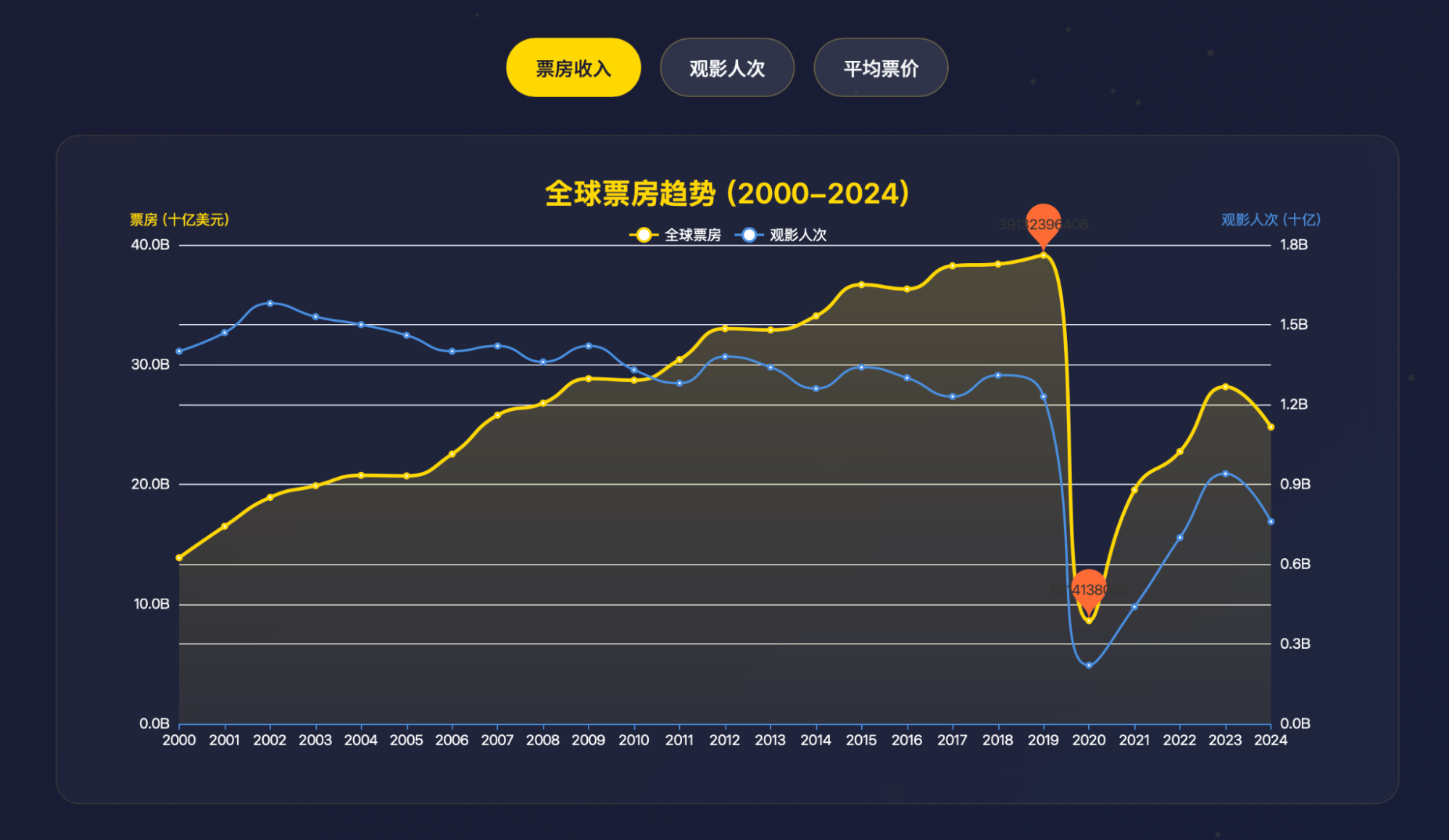
There are also comparisons with streaming. I won't go into detail; those interested can analyze it themselves.
Naturally, we could question if these Gemini deep research figures are "wrong" or "hallucinations," which leads into my second discussion topic. One moment.
In summary, I do not believe that in the next 2-3 years, images and video will become the main drivers of token consumption. This is because, as human-machine interfaces, they are subject to human physical constraints.
So, what about another interface: voice? Interestingly, I believe this might be an overlooked area. Although the total volume might not exceed video, expectations might be surpassed simply because people's imaginations for it are small. A person can work or chat with an AI for a long time. Speech is a modality 5-10 times more efficient than text, meaning the upper limit for voice usage time is quite high. However, before it truly lands well, there are several pain points: first is output efficiency—how AI should synthesize voice, text, images, and video responses to truly improve communication efficiency; second is environmental adaptability—current voice models perform well in quiet environments, but once there are crowds or heavy background noise, they become unusable. This isn't a model problem but an audio processing hardware/software problem that needs to be solved together.
And then there is 3D, which is clearly too early.
In fact, the reason for raising the question about the token-consuming power of new modalities, rather than assuming AI search and coding can maintain momentum and drive high sequential growth in token usage, brings us to the second topic.
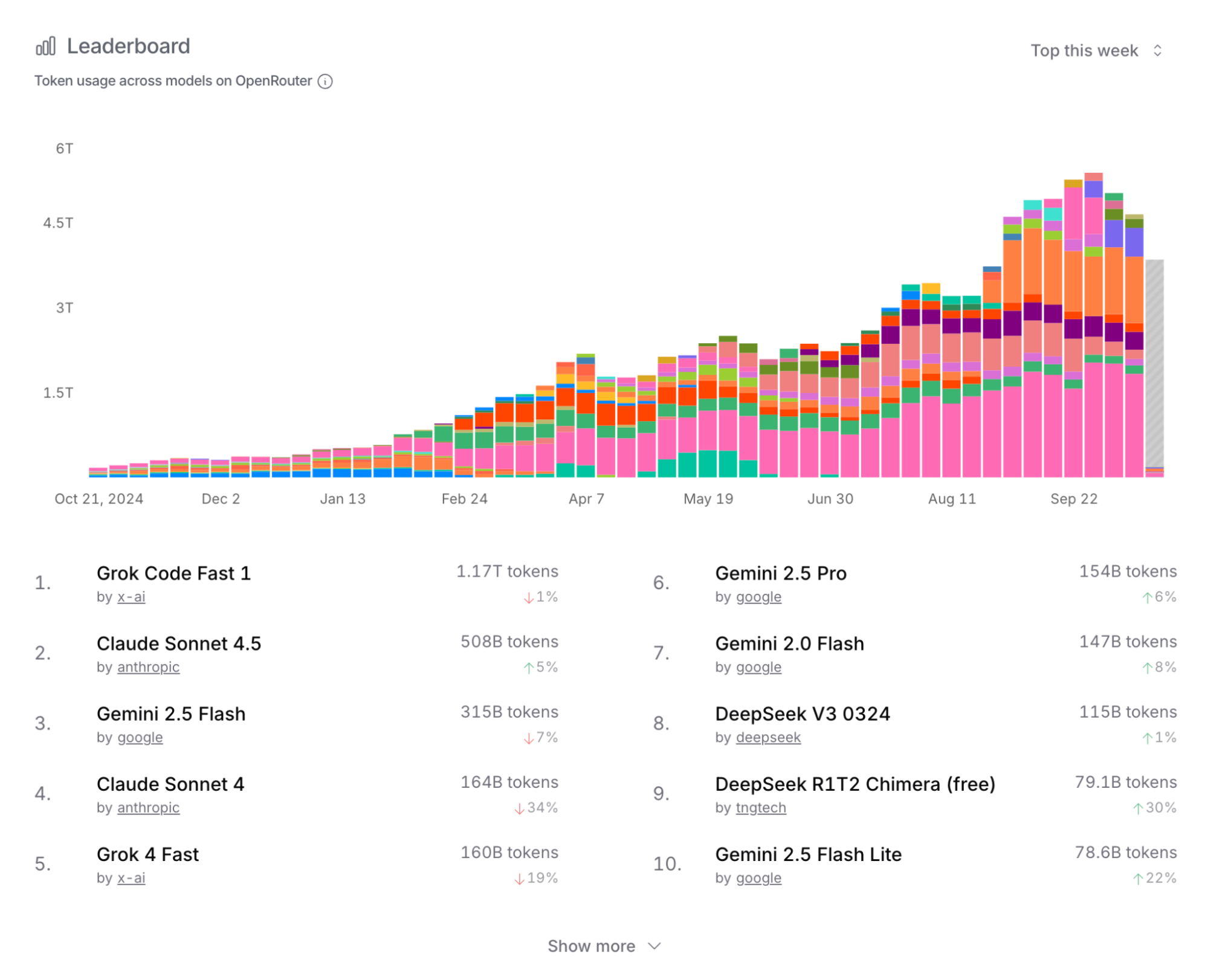
First, despite the heavy promotion from all sides, as analyzed in my previous articles, even Gemini's 1.3Q monthly usage has seen a marked decline in growth rate. Additionally, the OpenRouter data I frequently cite, while not huge in total volume, has a representative user base. The latest situation is as follows. Many signs suggest that token usage growth has likely slowed significantly.
Secondly, some will point to the upwardly revised ARR for Anthropic mentioned at the start. This is indeed strong evidence of robust AI Coding demand, which I will discuss in a moment.
There are also views, which I support, that after the release of GPT-5—especially the update to Codex—results have been excellent, and token usage should have increased significantly.
Discussing this from the perspective of personal experience, community interaction, and AI capability boundaries results in objective observations leading to subjective conclusions; thus, they can be questioned, but I cannot find more persuasive data.
The prerequisite mentioned earlier—compression rate—remains a constraint I consider vital. While compression rates in AI Coding are extremely high, for various reasons, myself and many friends I've spoken with lately share a very personal realization: individual token usage is essentially no longer increasing. There are two reasons: first, given current AI capabilities, humans still need to monitor AI progress constantly, interrupting and adjusting as needed—especially as more projects move toward production, the human participation ratio increases; second, the limits of human physiology and psychology—long-term human-machine collaboration leads to fatigue, mental depletion, and slower reactions. These two points have not changed with the so-called improvement in model capabilities (e.g., Claude 3.7 to 4 to 4.5); in fact, they have worsened.
Since we are writing code, the first consideration is how to achieve better results at a controllable cost. This has gradually become a "game" between users and providers. Users who use models well are exactly the group that can maximize usage and want to "squeeze every drop of value from providers." Consequently, we see that when providers can't handle high inference costs and introduce rate limits, users leave in significant numbers. First it was Cursor—I stopped my subscription about three months ago and switched entirely to Claude Code. Now, everyone clearly sees Cursor's user data sliding. The latest development is that even though Claude Code and the Claude model might still be the best coding models, I have basically migrated to the GPT-5-driven Codex. So, is it possible that without a monopoly, this market has prematurely entered a zero-sum phase?
Continuing the point, I am not the only one switching from Claude Code to Codex; it has become a representative trend. Accordingly, I am highly skeptical of Anthropic's future revenue expectations, though it will take time to manifest. They responded with Claude-Haiku-4.5, but I've already integrated well with Codex, and I know the capabilities of Sonnet (which is better than Haiku), so I have almost no desire to try Haiku.
Ultimately, usage increases require model capabilities as a guarantee. However, we have overlooked another factor: ROI (Return on Investment). Indeed, I see many "veterans" like myself either returning to the "front lines" or becoming more involved in execution. With AI assistance, I've heard the same view from many teams: fewer people are needed, more content can be produced, things are busier, but business revenue remains normal.
I originally wanted to discuss where the AI capability boundary lies, but then I thought, why bother? There is a more realistic constraint: income.
Usage can still grow rapidly, but the cost reduction brought by technological progress is also fast. We need to compare the speed of usage increase with the speed of cost reduction. I am fairly confident that next year the cost per token generated will drop by two-thirds. Therefore, we likely need a minimum expectation of usage growing more than threefold.
I am also fairly confident that no single company will monopolize the models; in a competitive market, users always have more choice.
Finally, as always, I will not underestimate the huge changes AI has brought to me and the potential changes it brings to society. But I also know this remains a triangle of constraints involving human limits, model capability limits, and cost-income limits. While it isn't an impossible trinity, progress happens only within their mutual pull, not overnight.