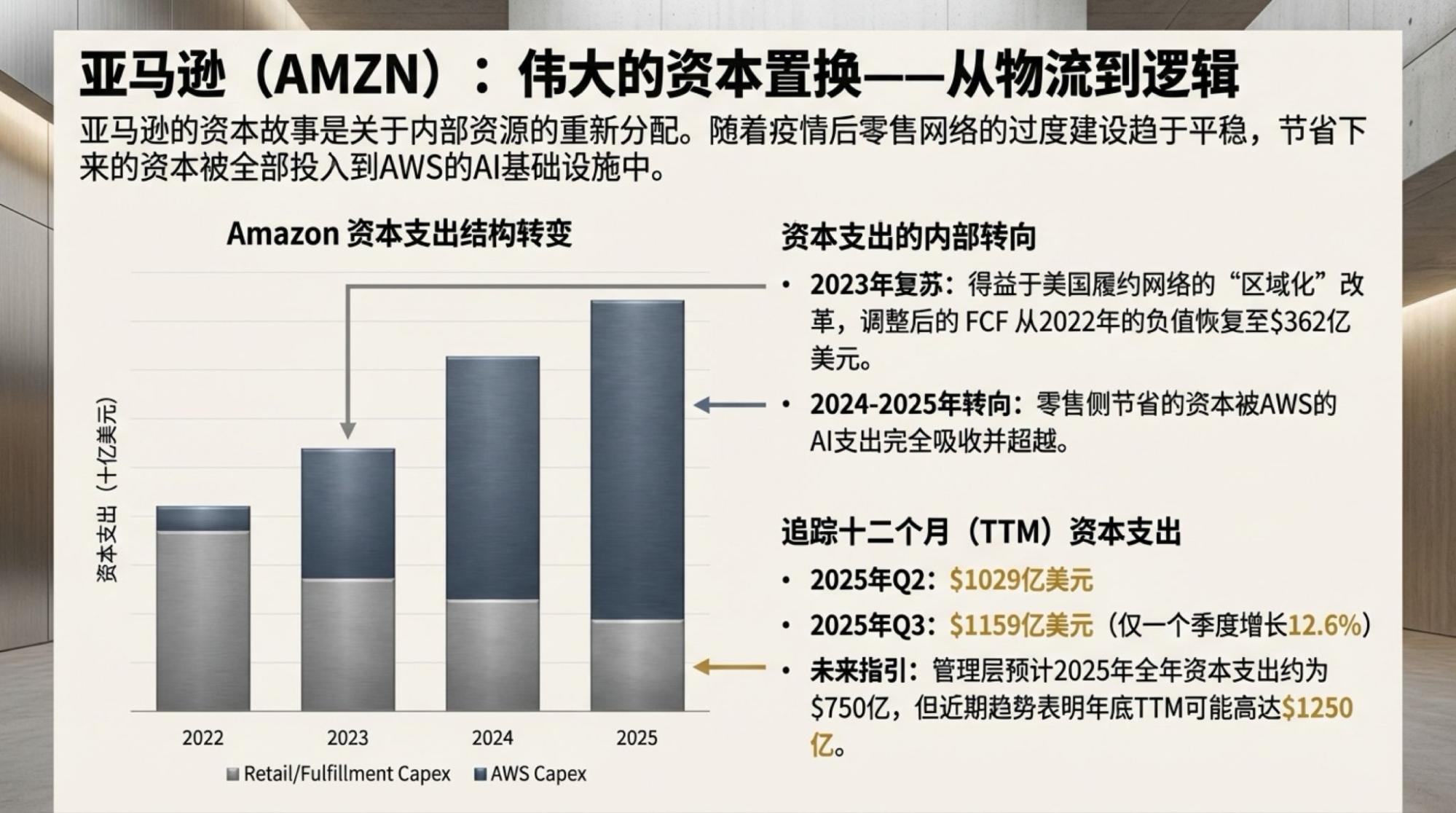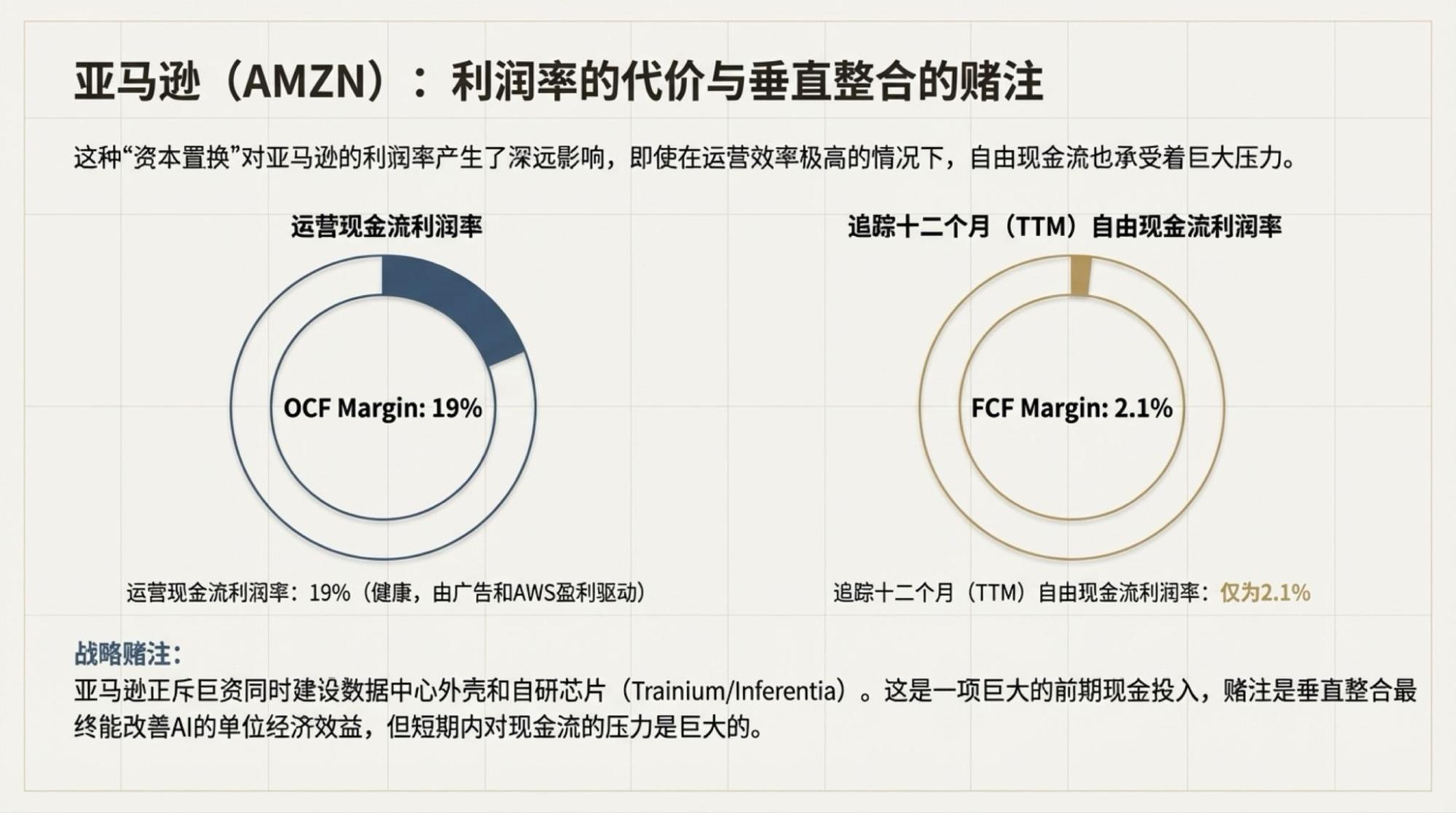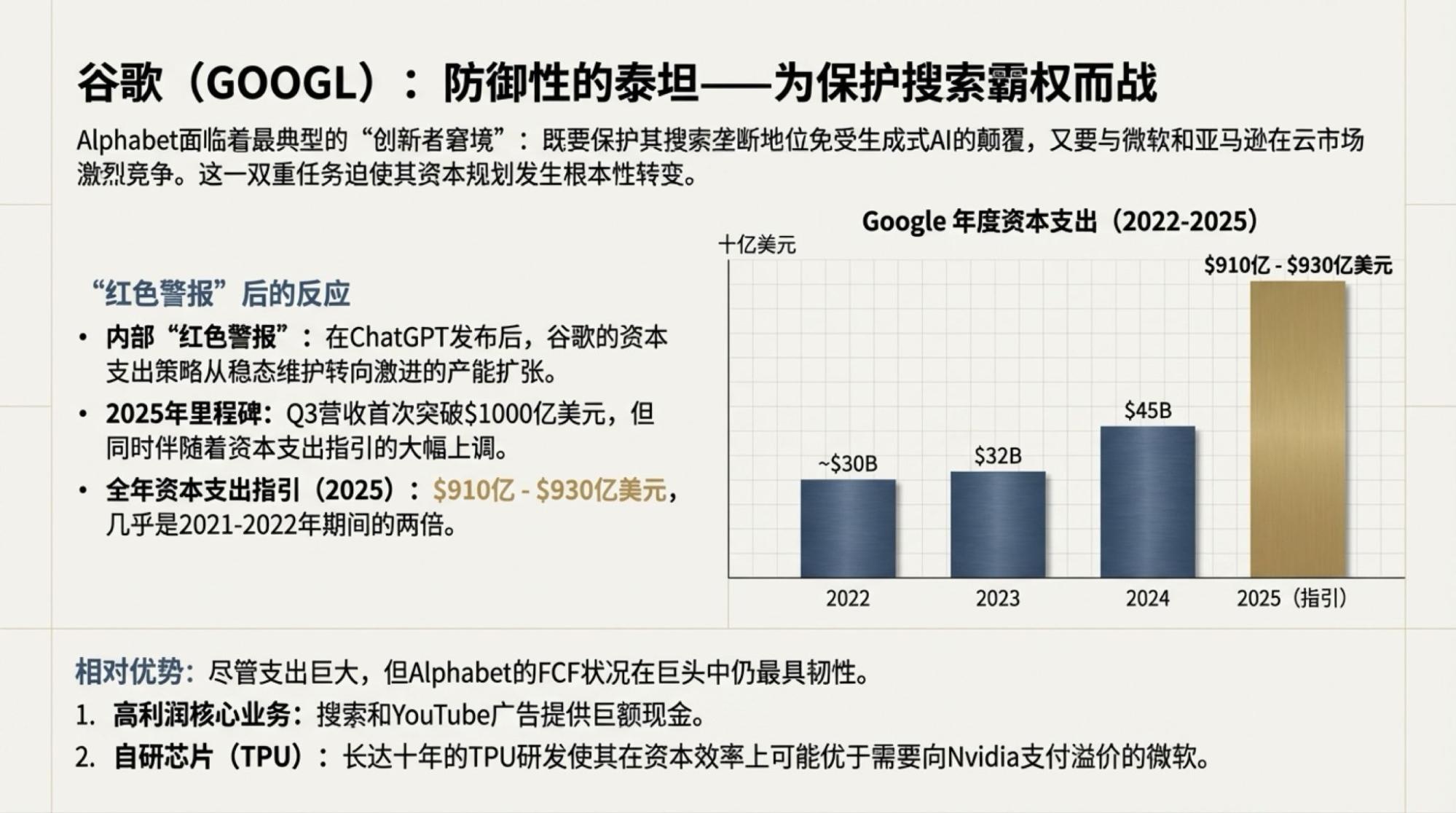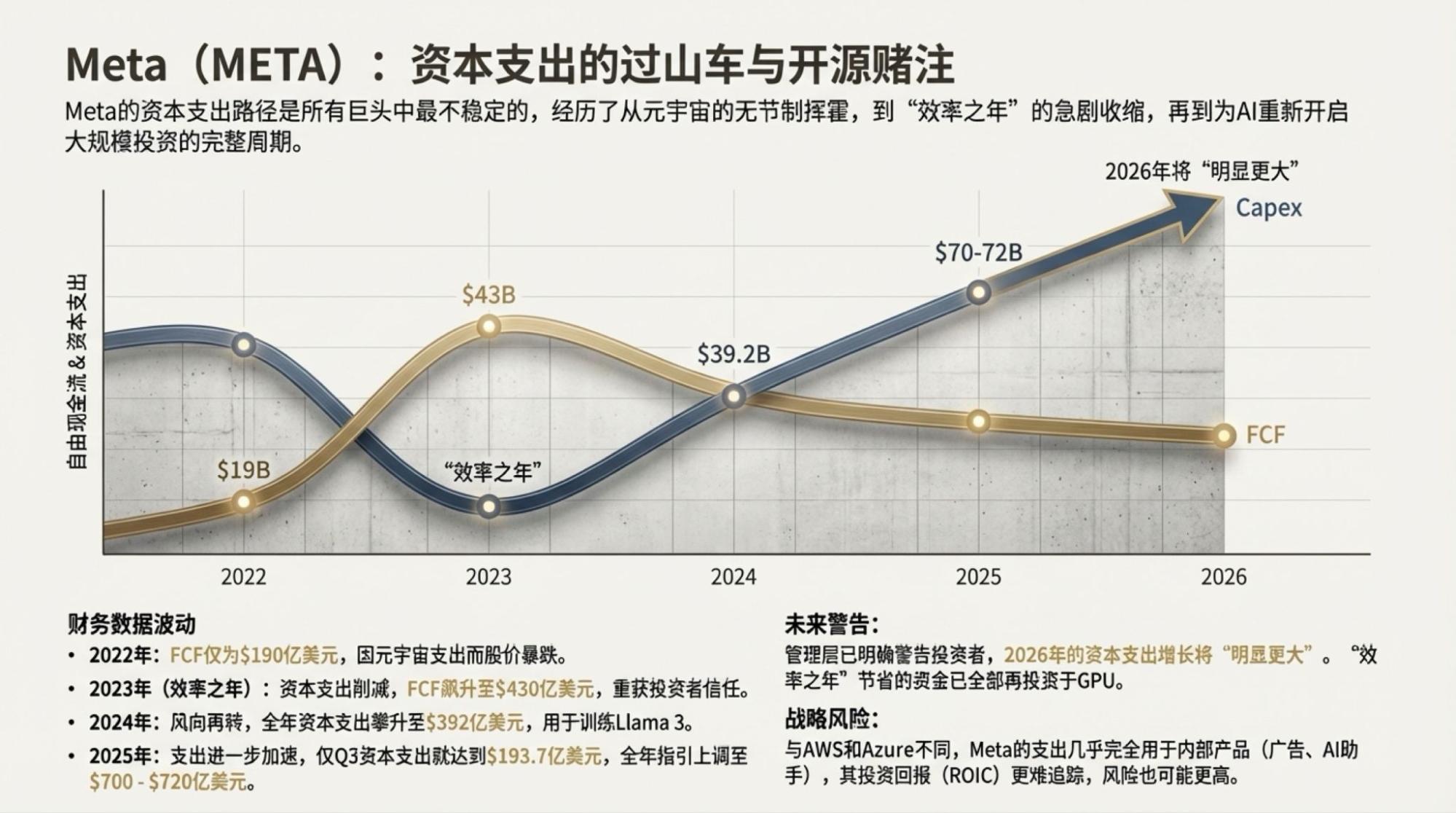
用了一天GPT-5.2,当然也不排除做些比较,特别是重做一些以前经常用来测试的案例。
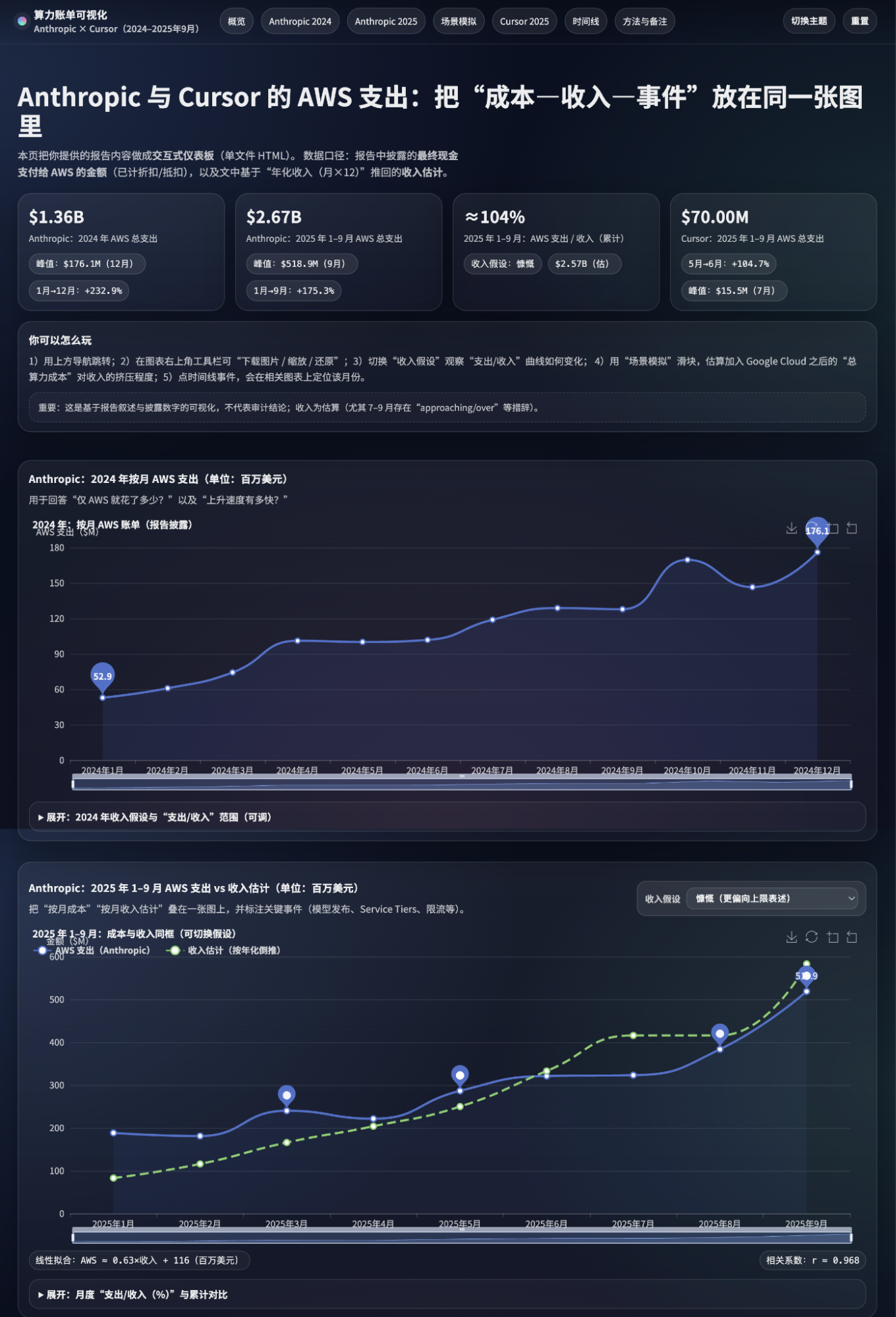
比如,下面这张应该在GPT-5.1时就比较过。显然,显然,比5.1进步是明显的,不过风格还是比较一致的,当然,花哨也是明显更花哨了,特别是图表控件的使用,真的很顶了。
当然,做个陆家嘴的three js模型,效果也进步了很多,而且还会有影子的变化。唯一缺点,代码高估了Chrome的能力,动态效果速度太慢了。
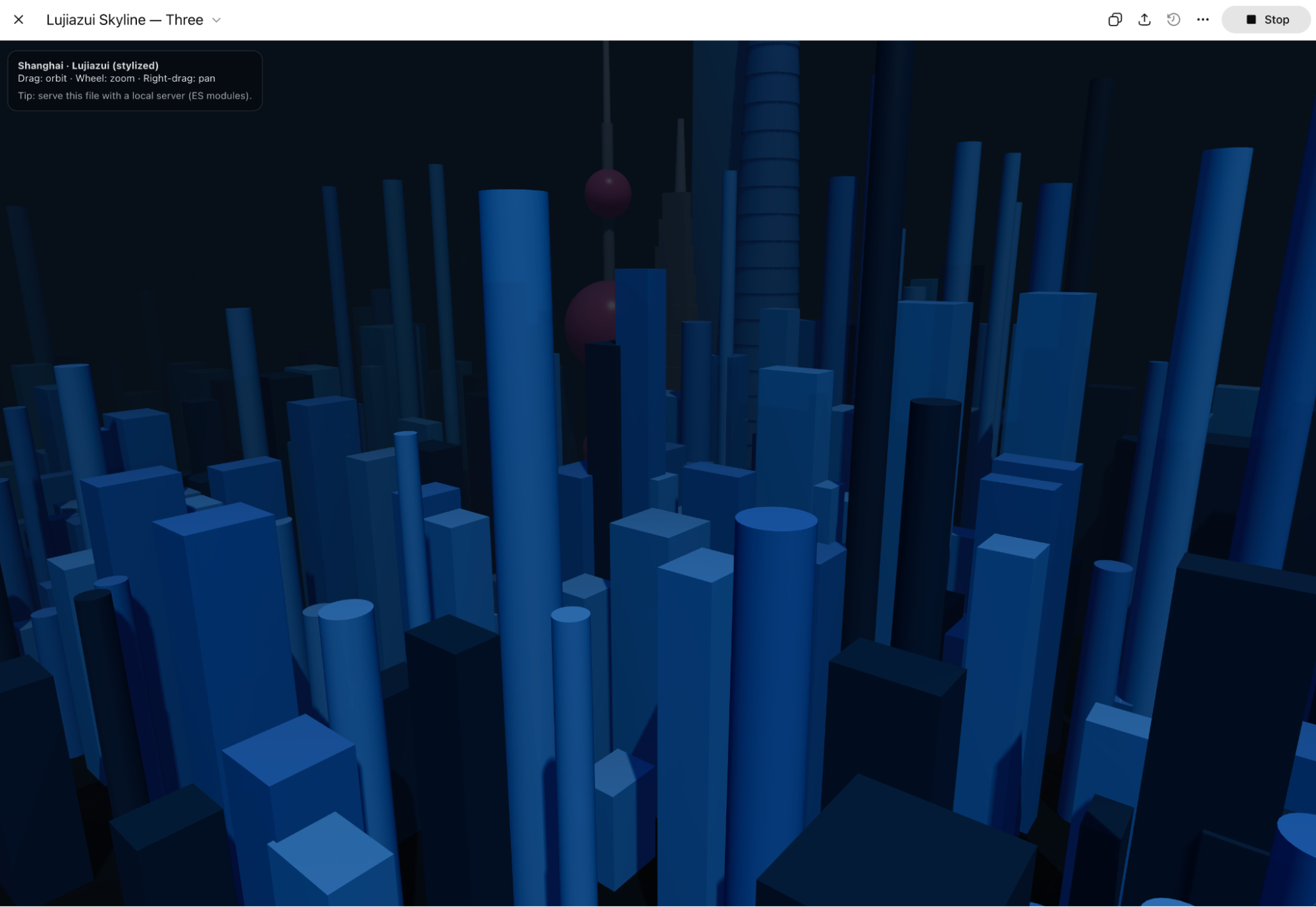
而在Codex中的表现,感觉速度快了不少,不,应该叫做执行效率高了不少。
OpenAI的宣传并没有太过夸张,效果进步是明显的,可是,总觉得哪里不对劲。
相比Gemini体系,GPT真的太单薄了,如今的Gemini可以很轻易的完成一份高质量的深度研究(最新发布的Deep Research Agent更是有了显著提升),然后,无论是在Gemini里直接输出Slides,再到Vids里一键生成视频,还是在NotebookLM里利用Nano Banana Pro生成图片式Slides,都能完成效果很好的产品闭环。当然,也可以跟我一样,在AI Studio的Build应用里快速的将Gemini-3-Pro, Nano Banana, TTS等模型整合,完成一键自动化的视频输出。
多模态到最终产品级的输出,才是更有意义的面向用户的实用性模型➕工具组合,曾经,用户体验更好是GPT系列模型的最大优势,但是当它被迫面向Coding做优化,而且只注重这一单项能力的提升时,它已经开始逐渐在“放弃”更大的用户群:要知道,虽然代码生成就是可以解决大量的问题,但更大的用户群是不会习惯于代码生成的,对于绝大多数缺乏代码能力和经验的用户而言,网站也不是一个可以较好驾驭的形式。
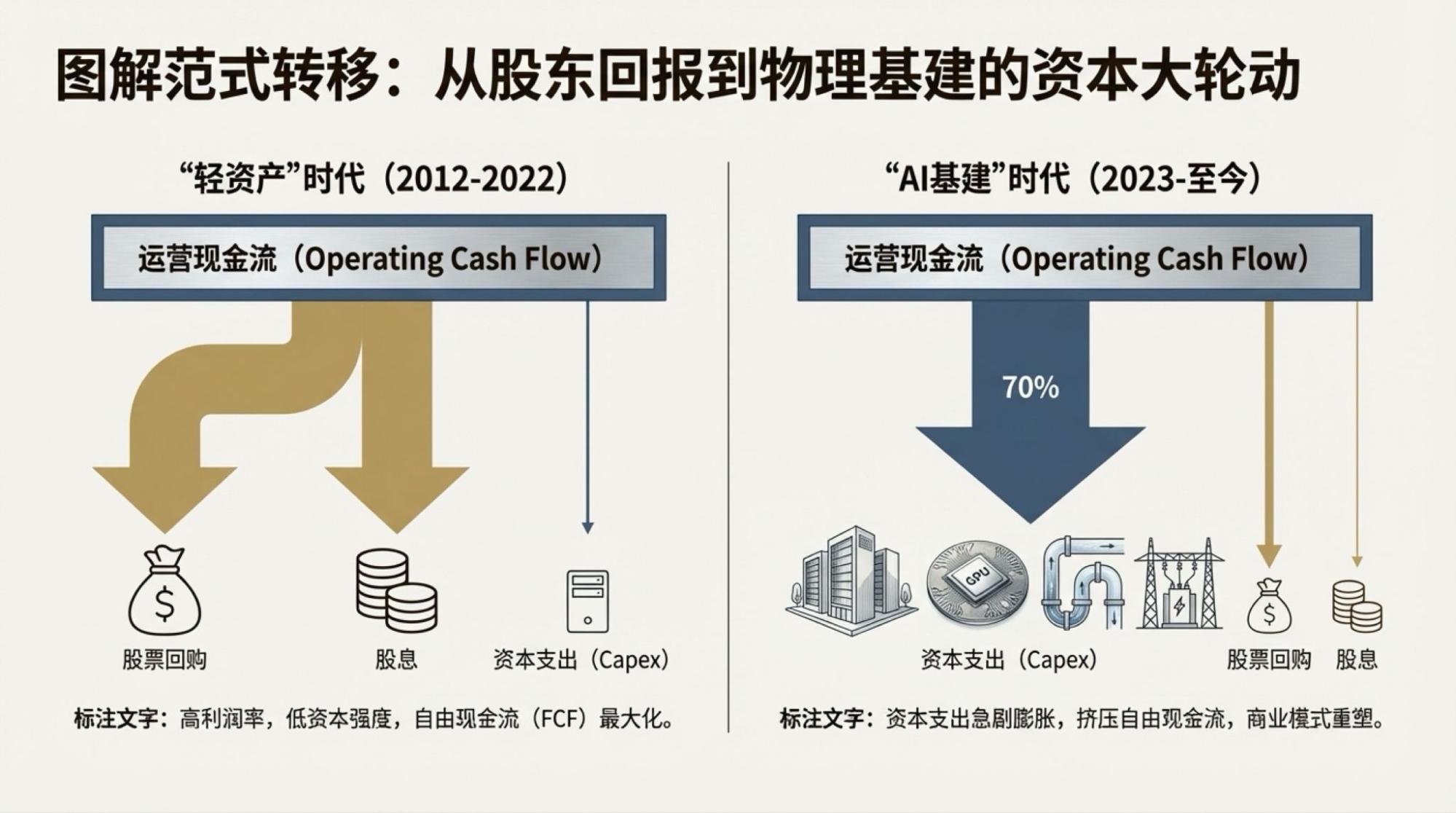
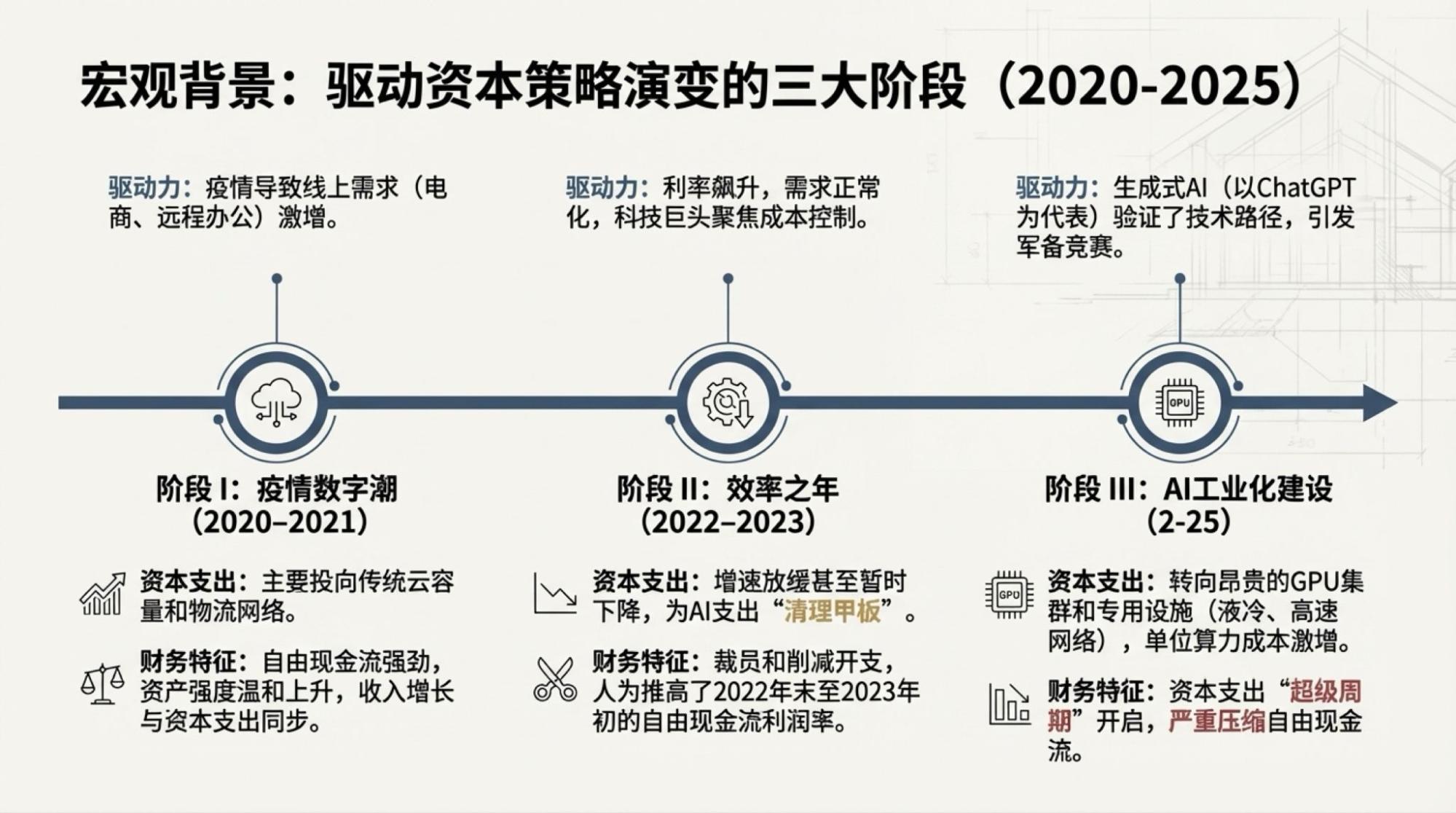
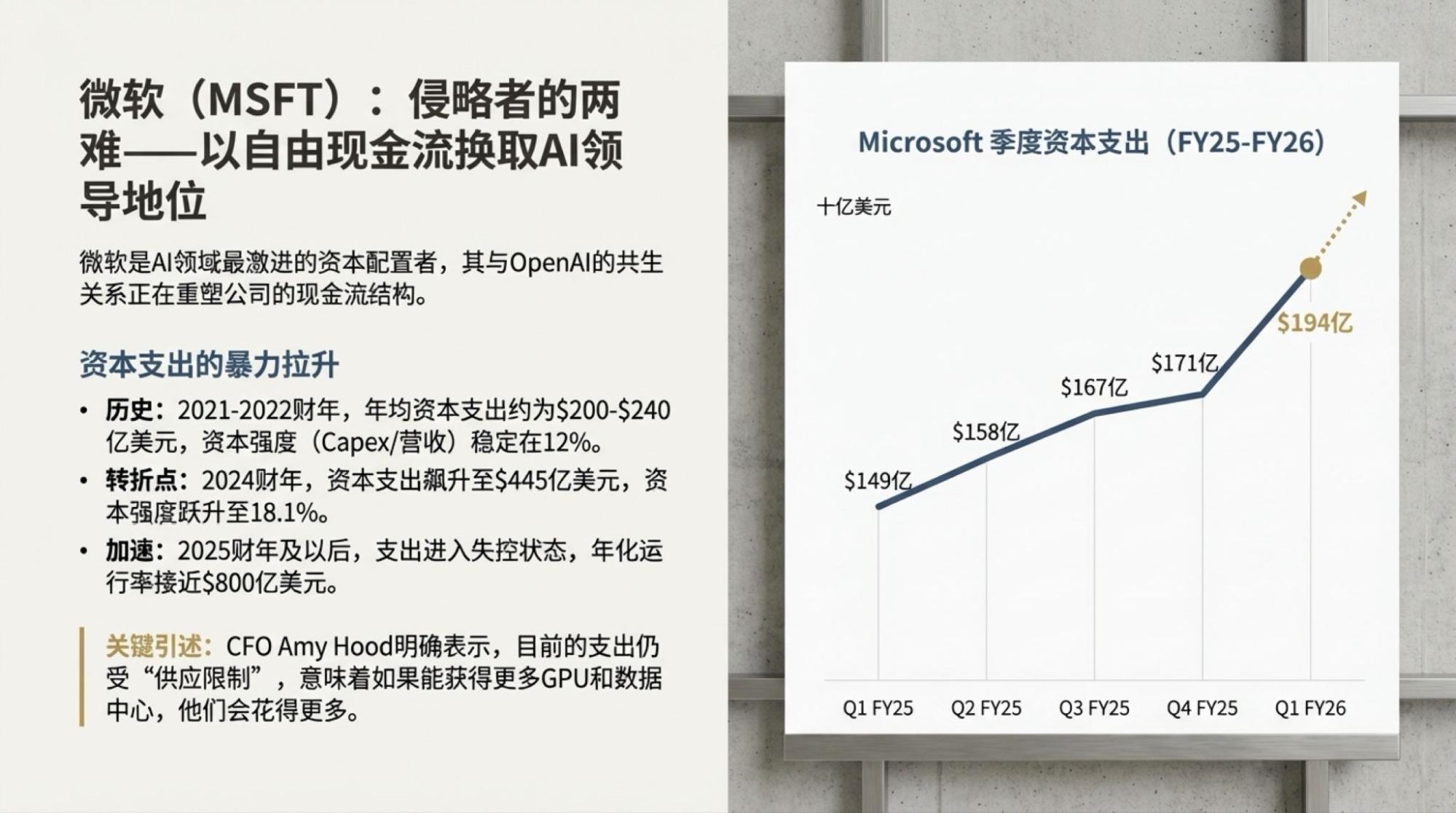
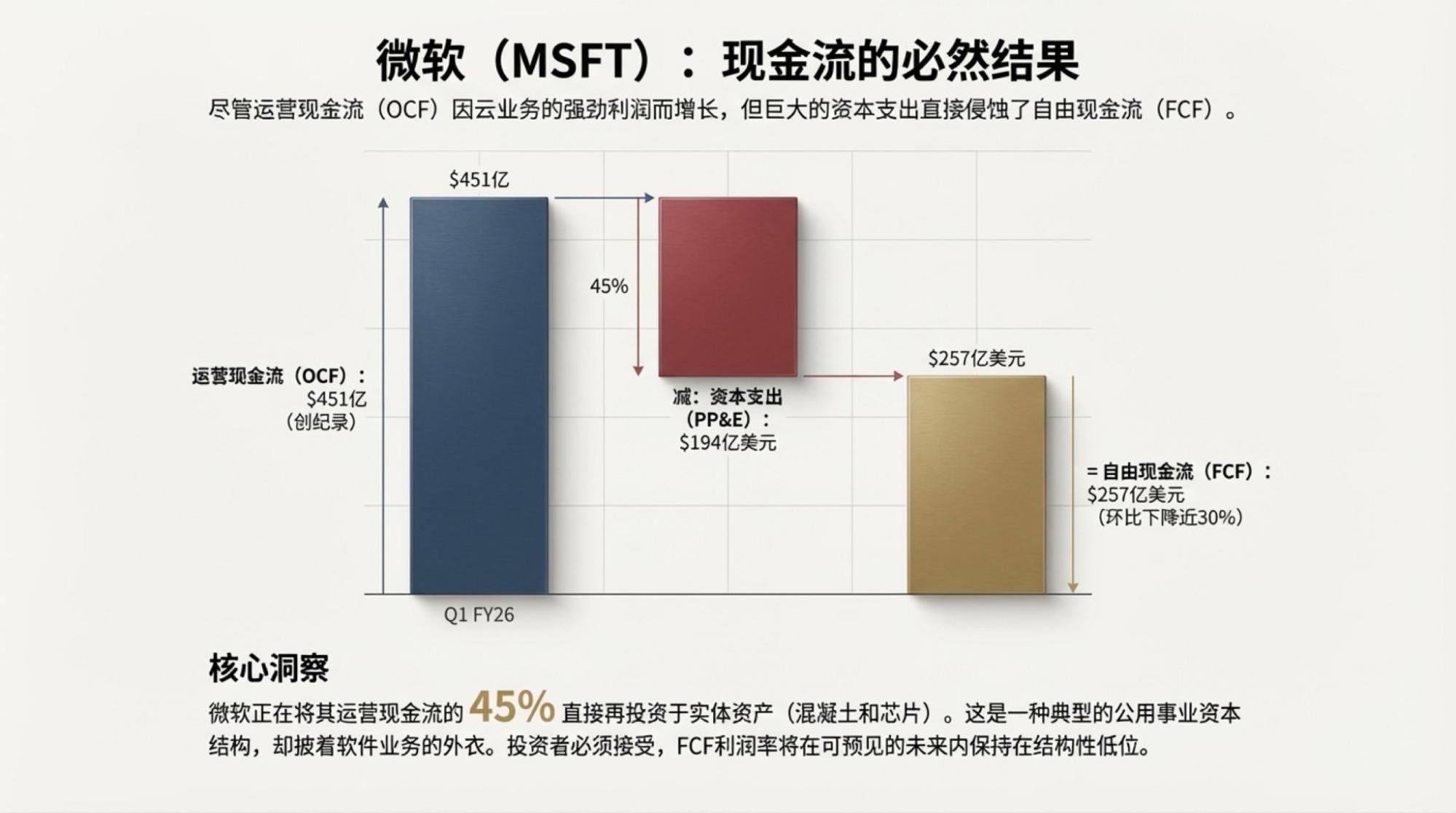
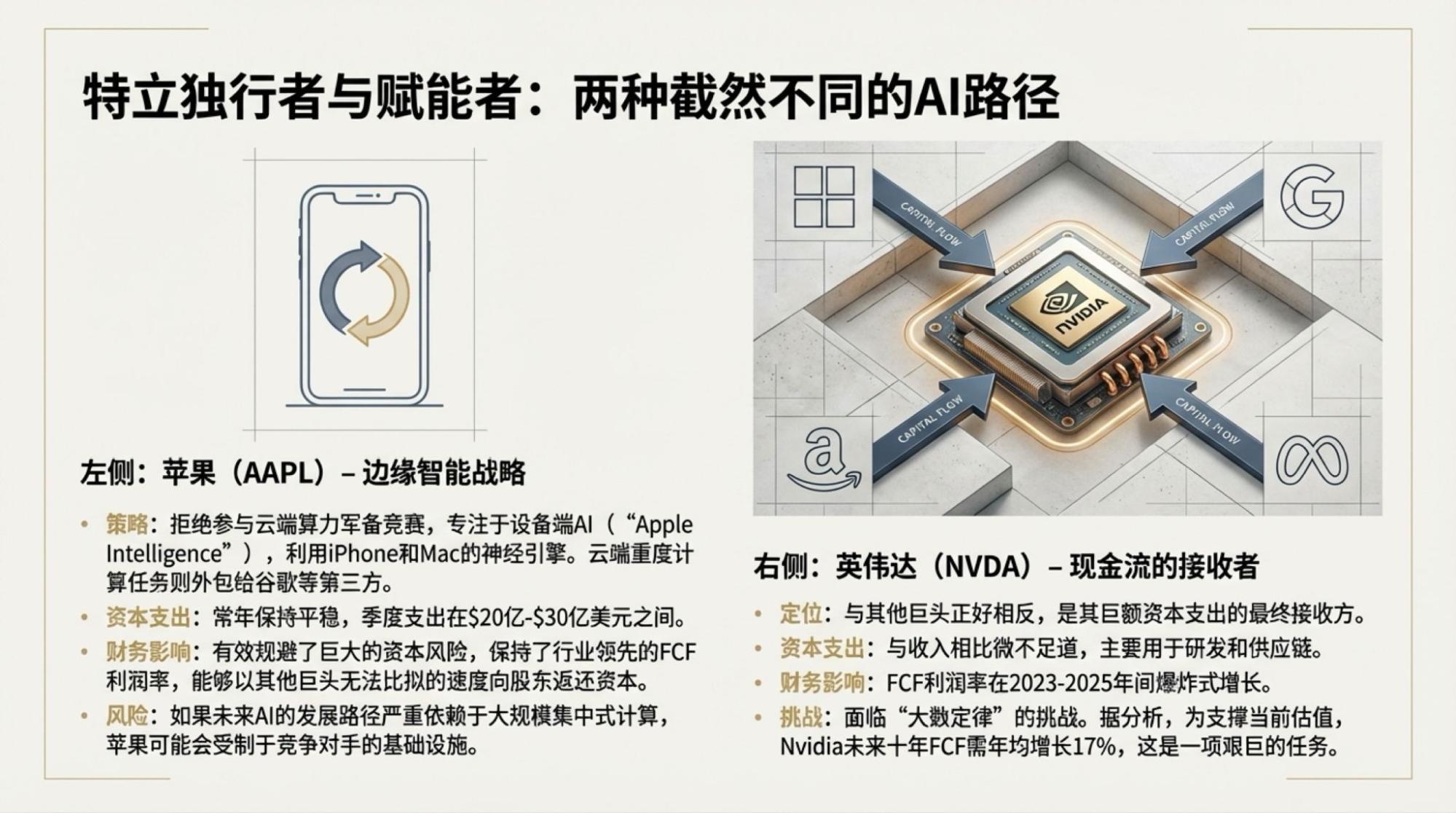
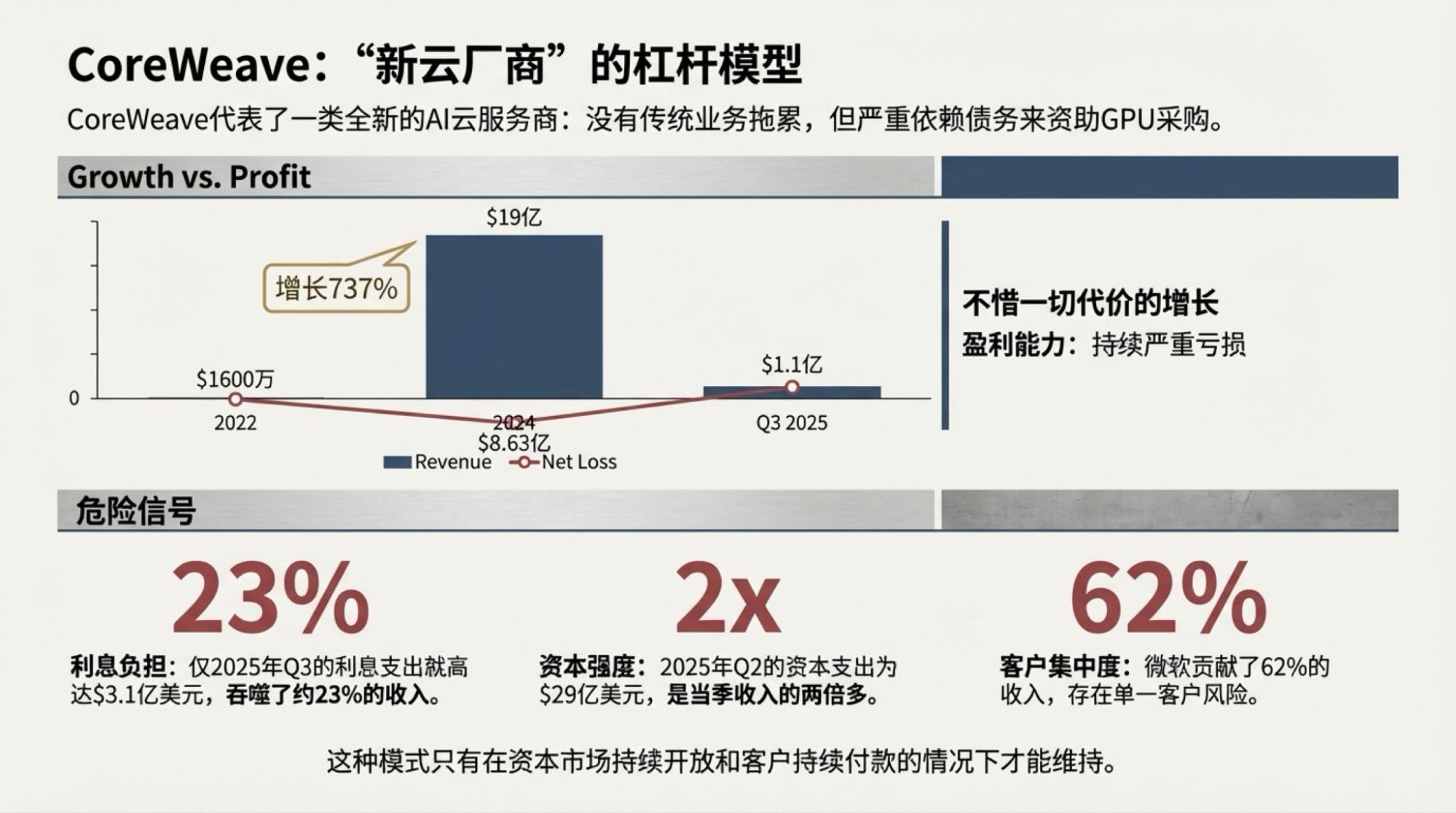
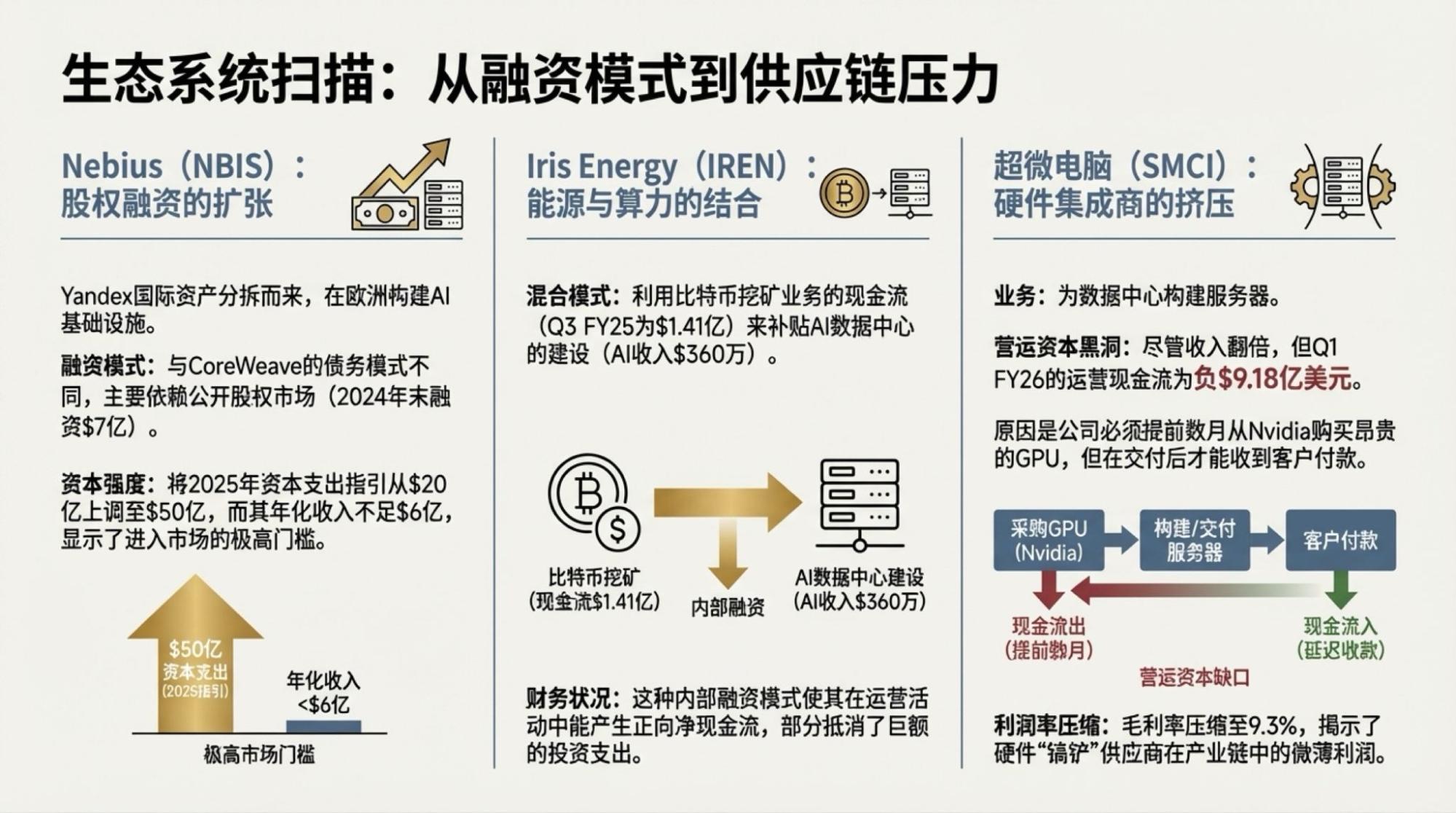
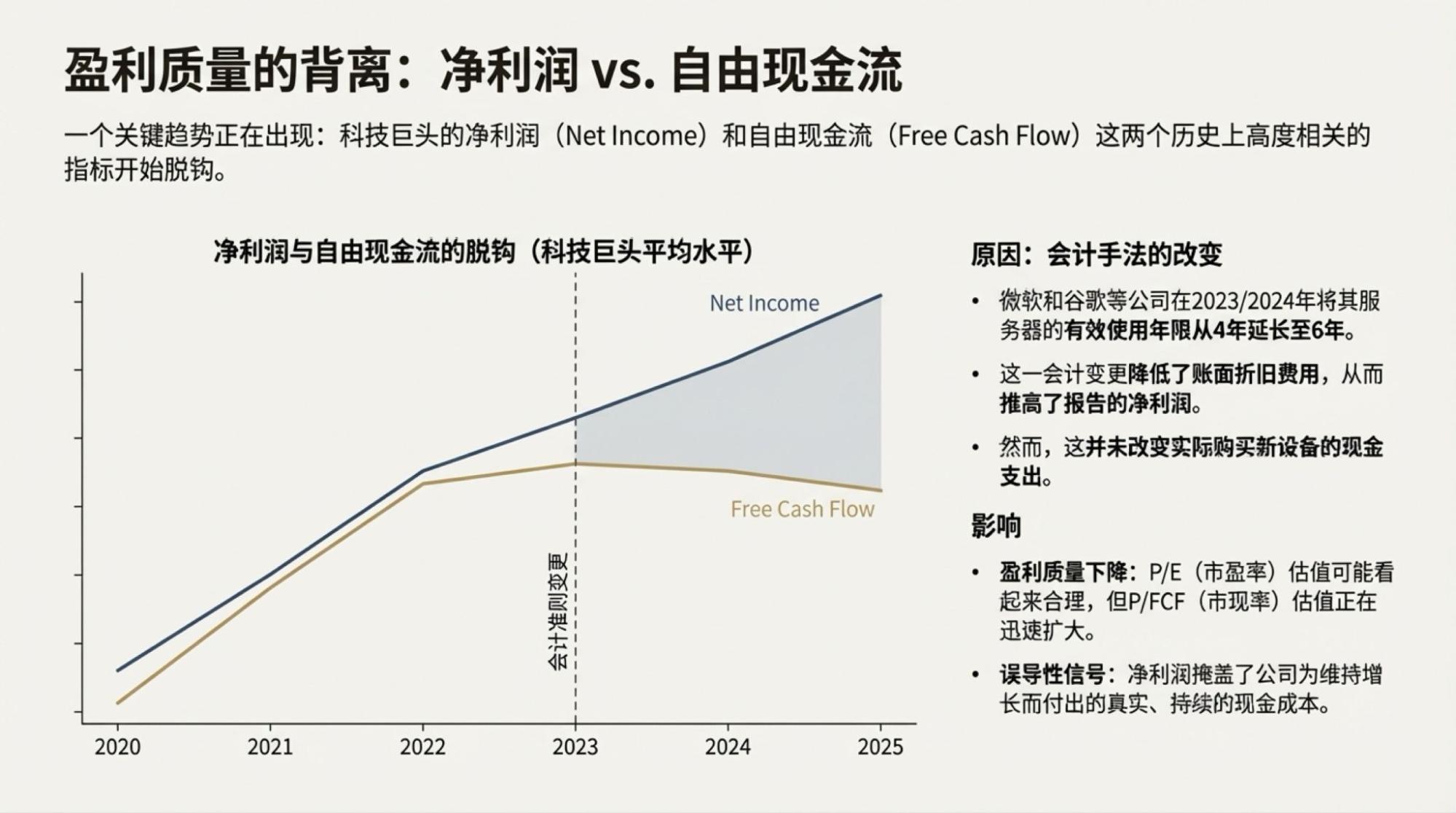
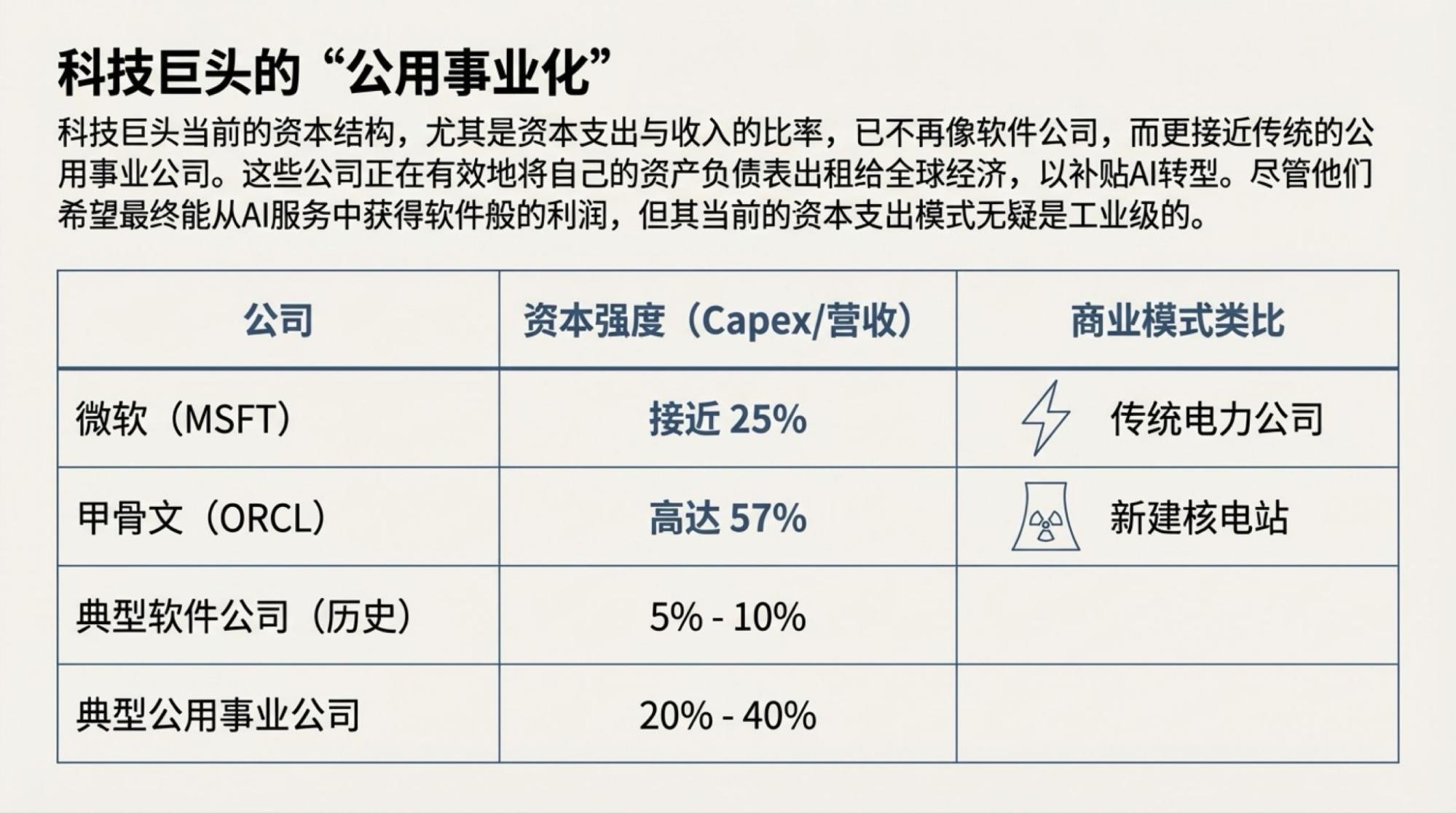
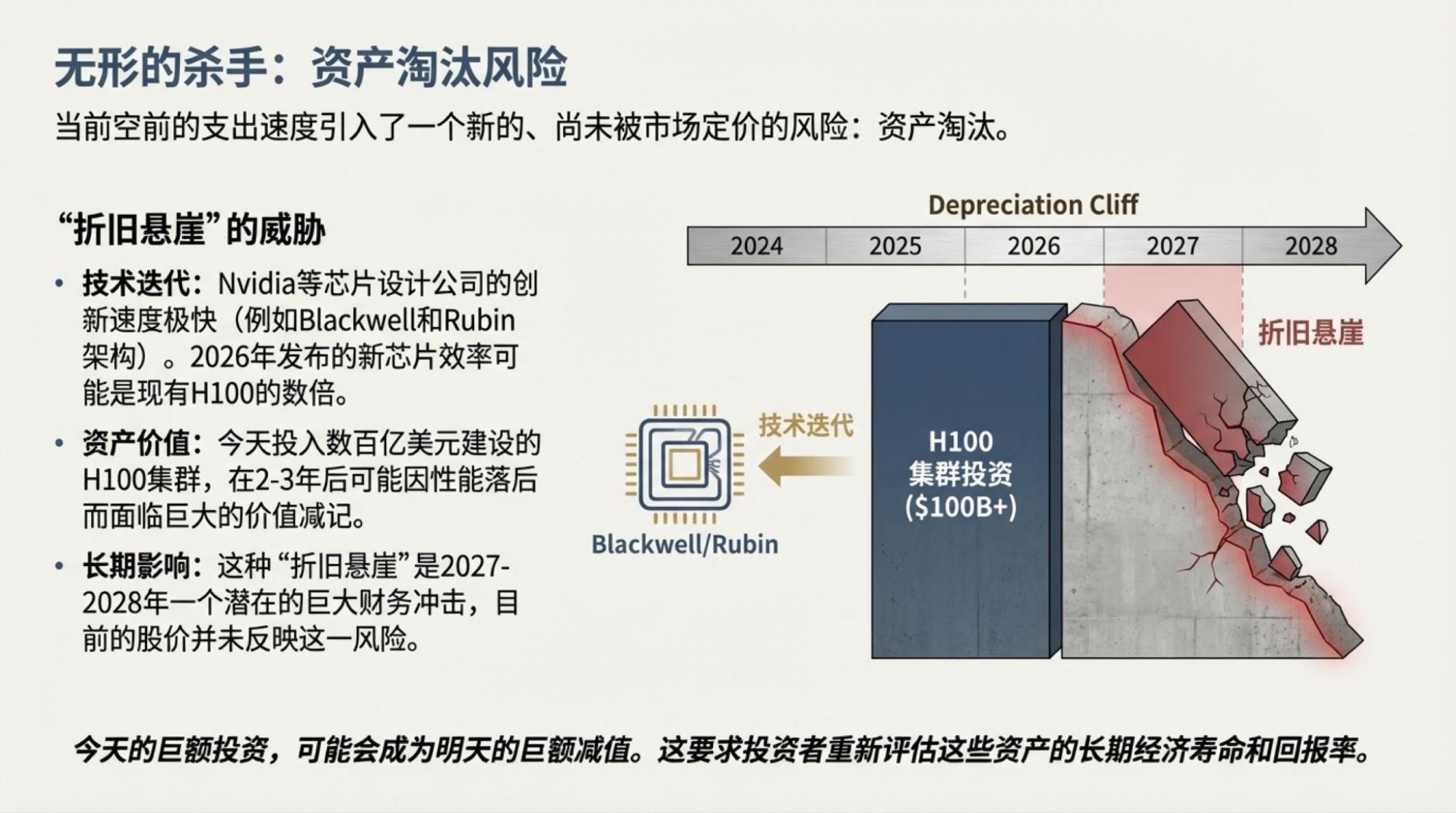
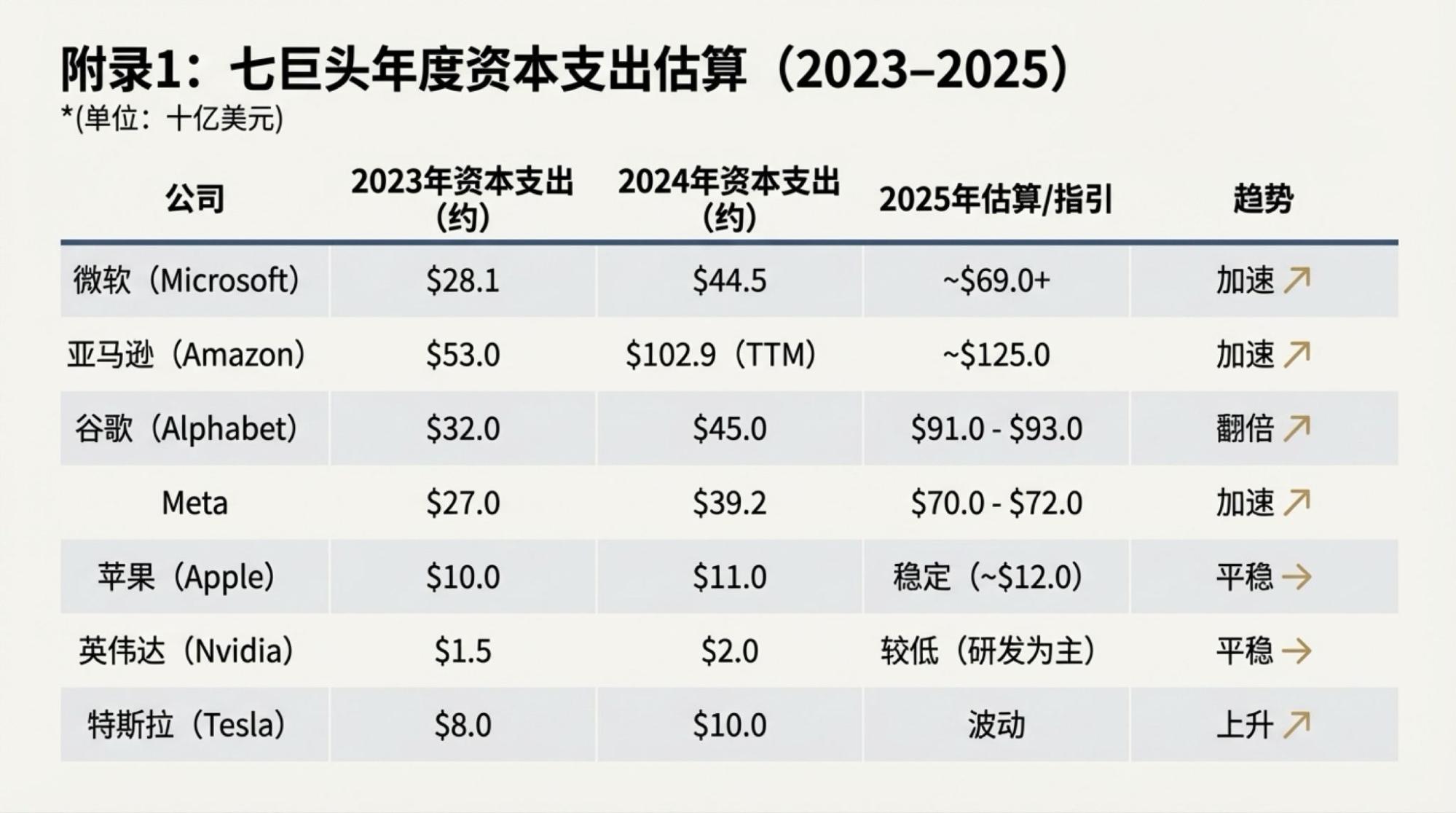
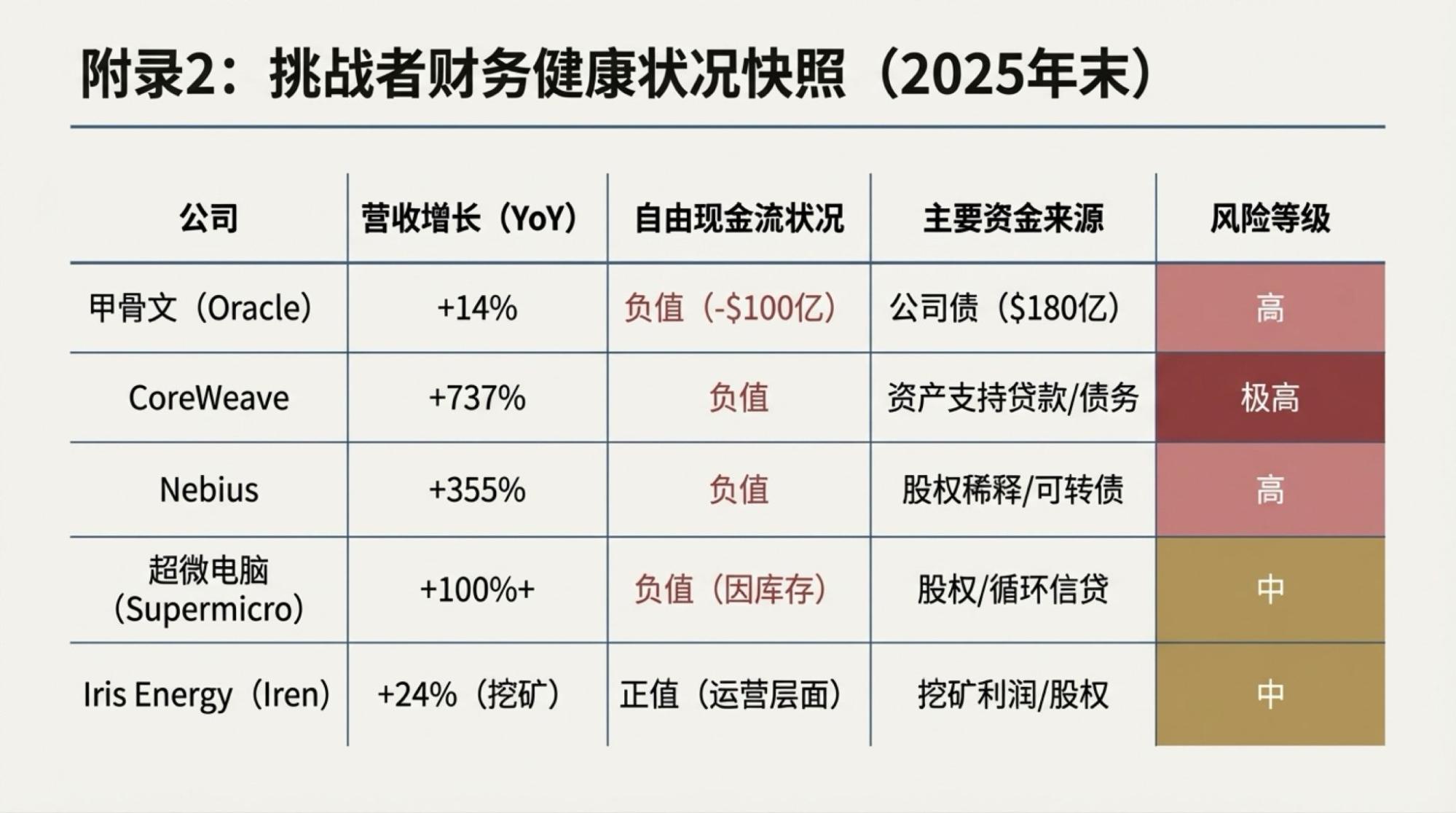
为了说明这一点,对于市场越来越关注的“现金流”问题发起了一次Deep Research,提示词很简单。
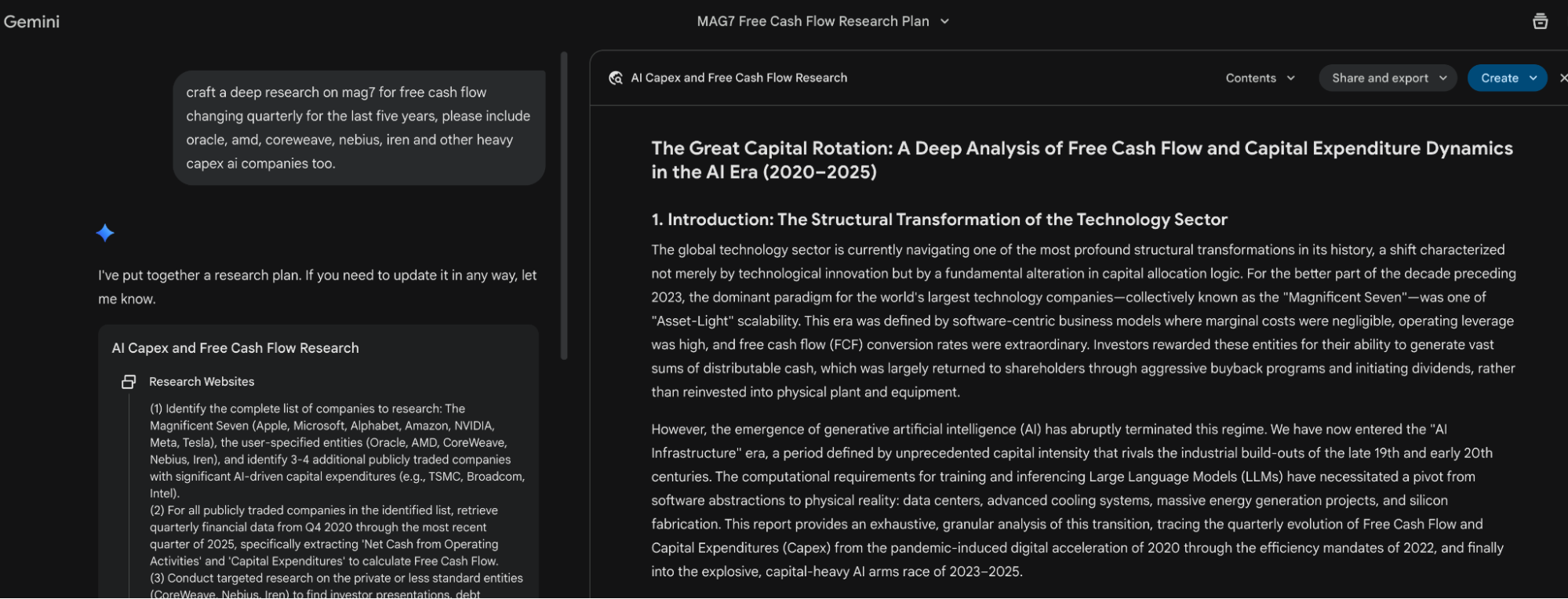
当然,我们都知道,结果报告可以导出为google doc,存放在google drive中,然后在notebooklm里直接导入,然后,就是可以出音频博客,视频博客,信息图,或者,slides。
当我今天尝试的时候,slides的long模式又回来了。
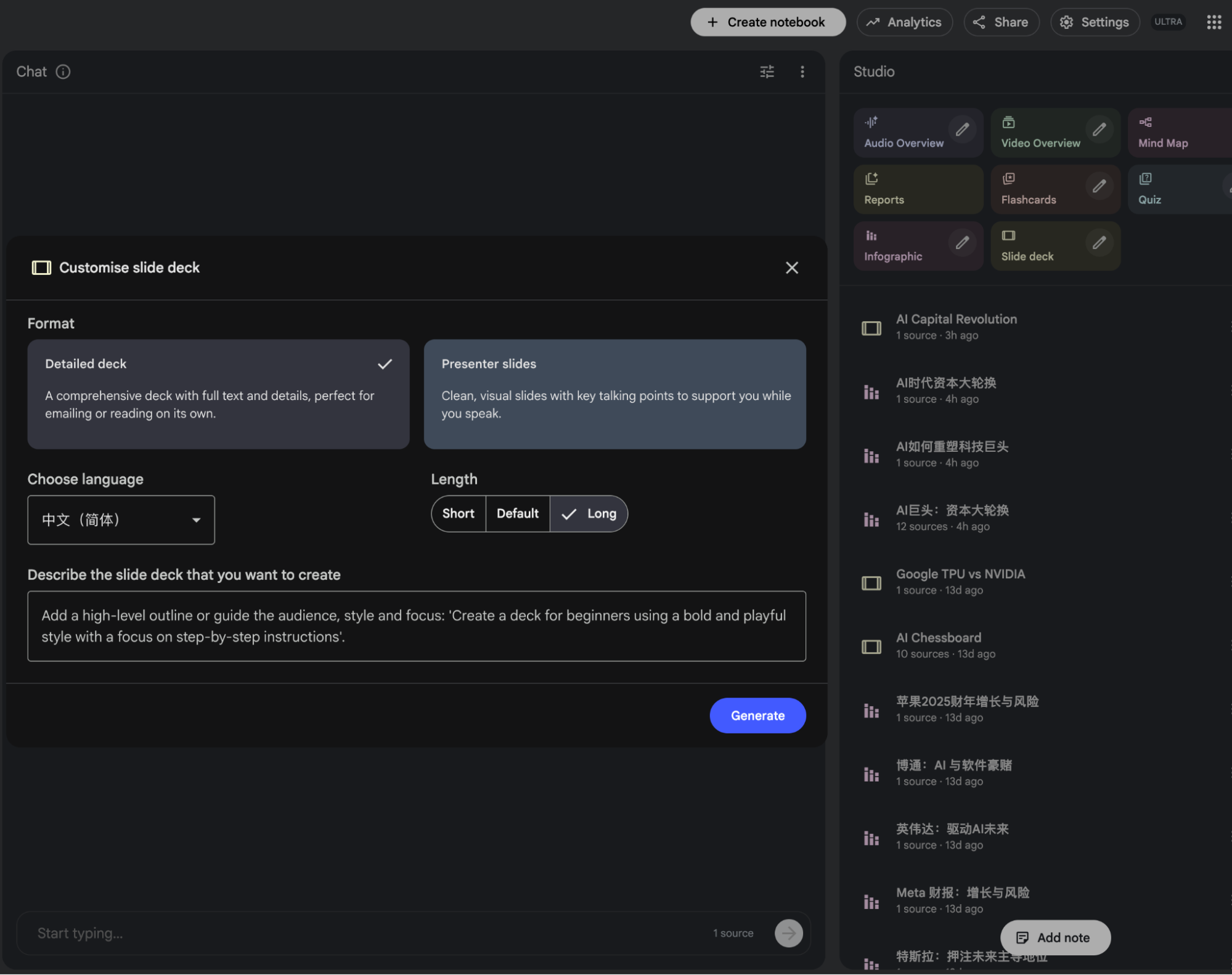
然后,25页的slides就可以生成了。
逐页附于文章最后。
当然,GPT-5.2的能力,可以做一个很好的交互式网站,比如,
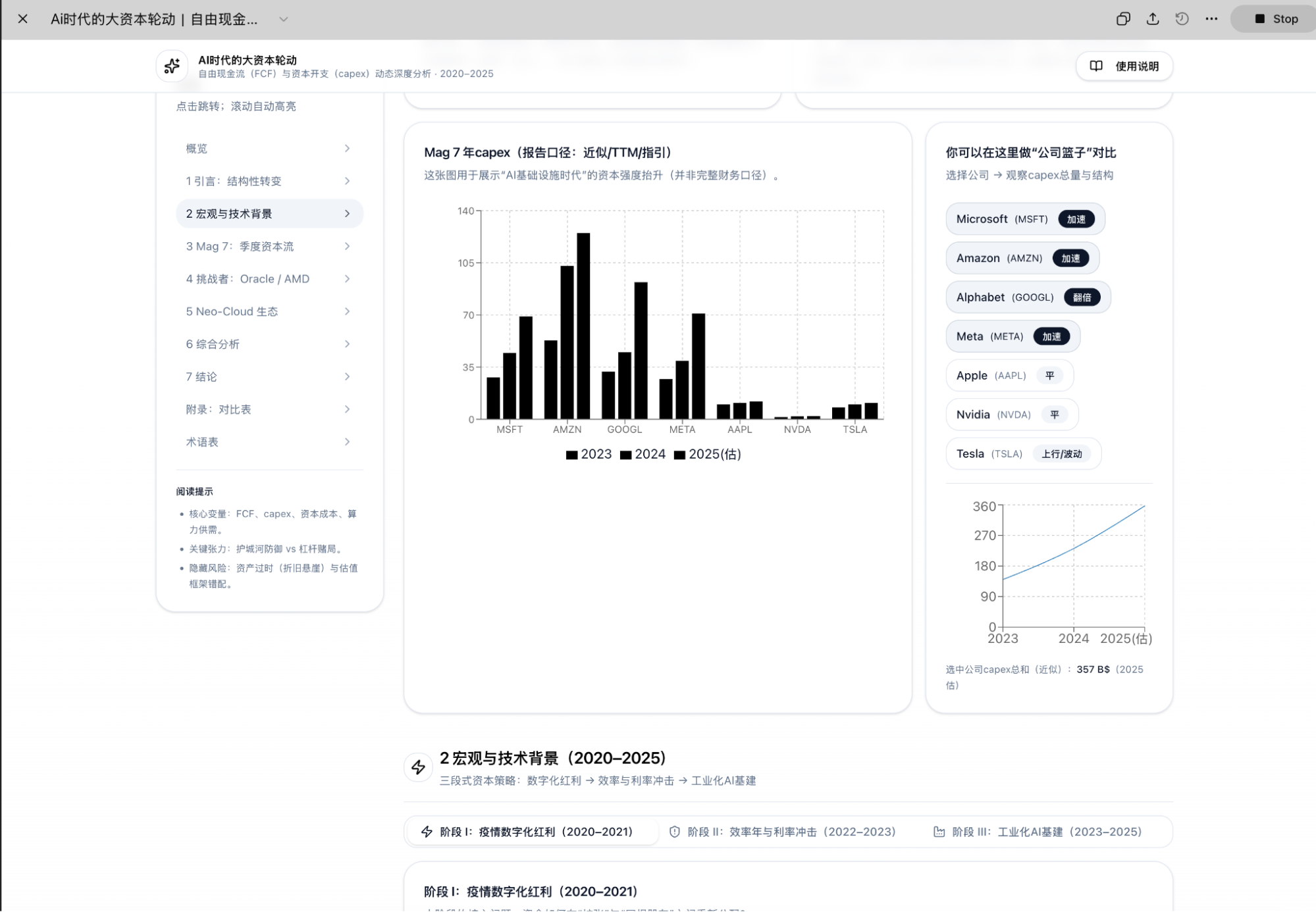
可这,跟Gemini相比,真不是一个维度的东西。
利用Nano Banana Pro,可以很轻易的将这些内容压缩到一张信息图里。
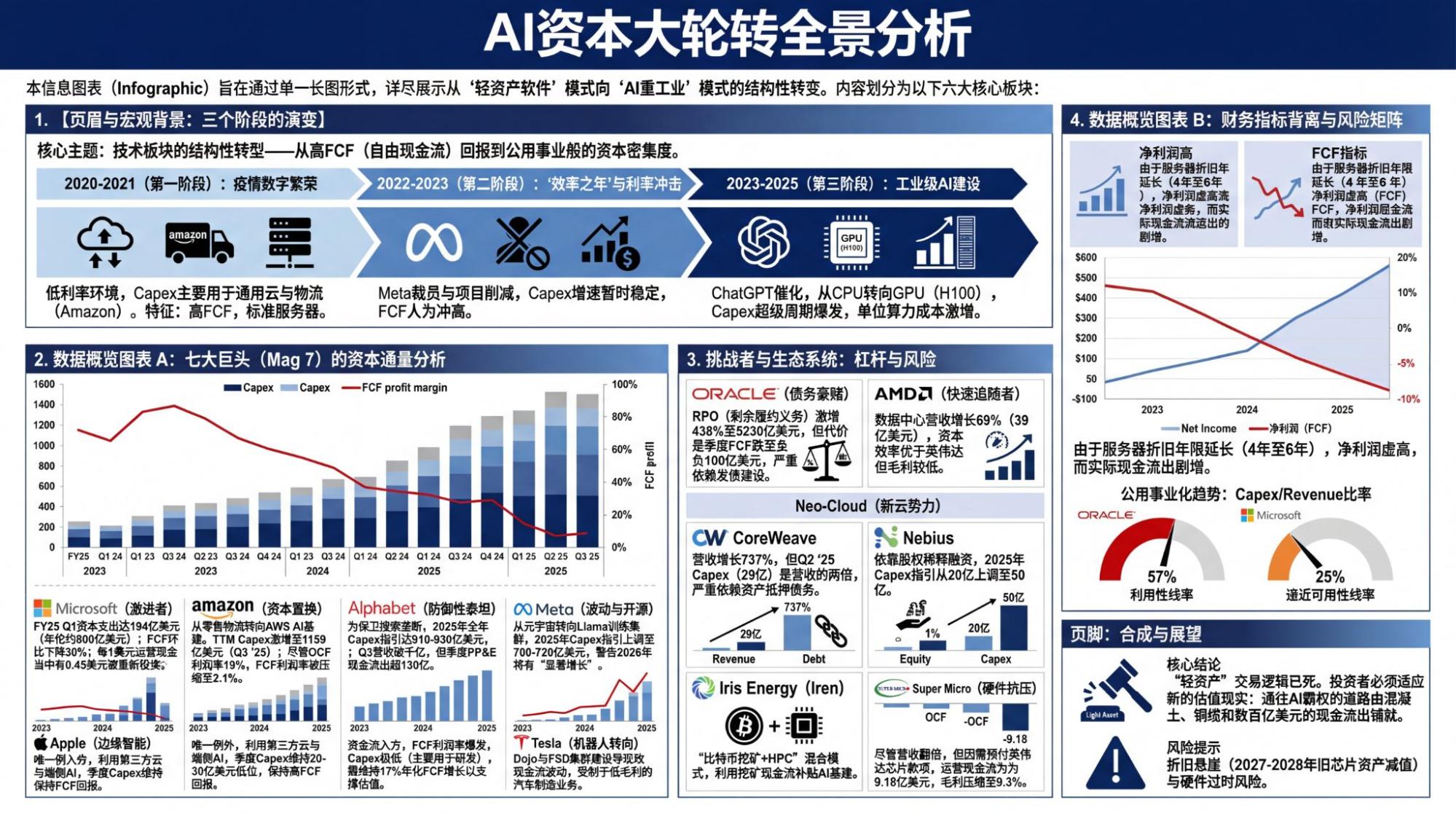
时至今日,GPT步了Claude的后尘,离普通用户越来越远了。这就是那个不对劲的地方:GPT最早做了实时语音对话模型,Whisper依然是语音开源模型里的第一选择,去年的GPT依靠生图模型出圈,GPT最早将ChatGPT-Agent集成,配合Schedule,可以完成很多流程复杂但结果友好的workflow。在模型层面,OpenAI拥有所有可以达到Gemini系列惊艳且实用的产品效果的模型能力和储备。
可是,也许Google的生态太强了,也许OpenAI根本没有足够的资源去实现对绝大多数用户更有价值的产出工具集。
然而,AI的竞争早就在更高维度展开了,至今这个维度里只有一个玩家,Google,从Gemini-2.0开始。