英伟达又发了一个期货:号称专门针对长上下文(百万tokens)推理的Rubin CPX芯片,以及加入该芯片的Rubin NVL144 CPX。
下图为Rubin CPX芯片,使用128GB GDDR7显存。
下图为Rubin NVL144 CPX:一个机架18个Tray,一个Tray有四颗Rubin GPU,再加八颗Rubin CPX。

所以会有一堆新的天花板指标:8 exaflops(NVFP4),100TB内存(HBM+GDDR7),号称性能是GB300 NVL72的7.5倍。
反正英伟达又赢了:“每1亿美金投资,可以有50亿美金回报。”

最主要原因当然是应对潜在的竞争压力,AMD已经发布了NVL的竞品,基于MI400的Rack:Helios。有更强的CPU,可以提供更好的推理性价比。虽然AMD产品节奏比英伟达要延迟至少半代时间,但其实社区里对这款产品还是很看好的,加上对标CUDA的生态ROCm成熟了不少,竞品对英伟达构成的压力是不小的。当然,还有被Google的TPU带火的XPU。

竞争压力之外,确实在实际应用中,面向长上下文的推理场景增长太快了,去年开始的token调用量快速提升,主要贡献者就是长上下文场景(搜索,代码生成,以及接下来的图片视频生成)。长上下文场景跟传统的AI对话式场景区别其实很大。
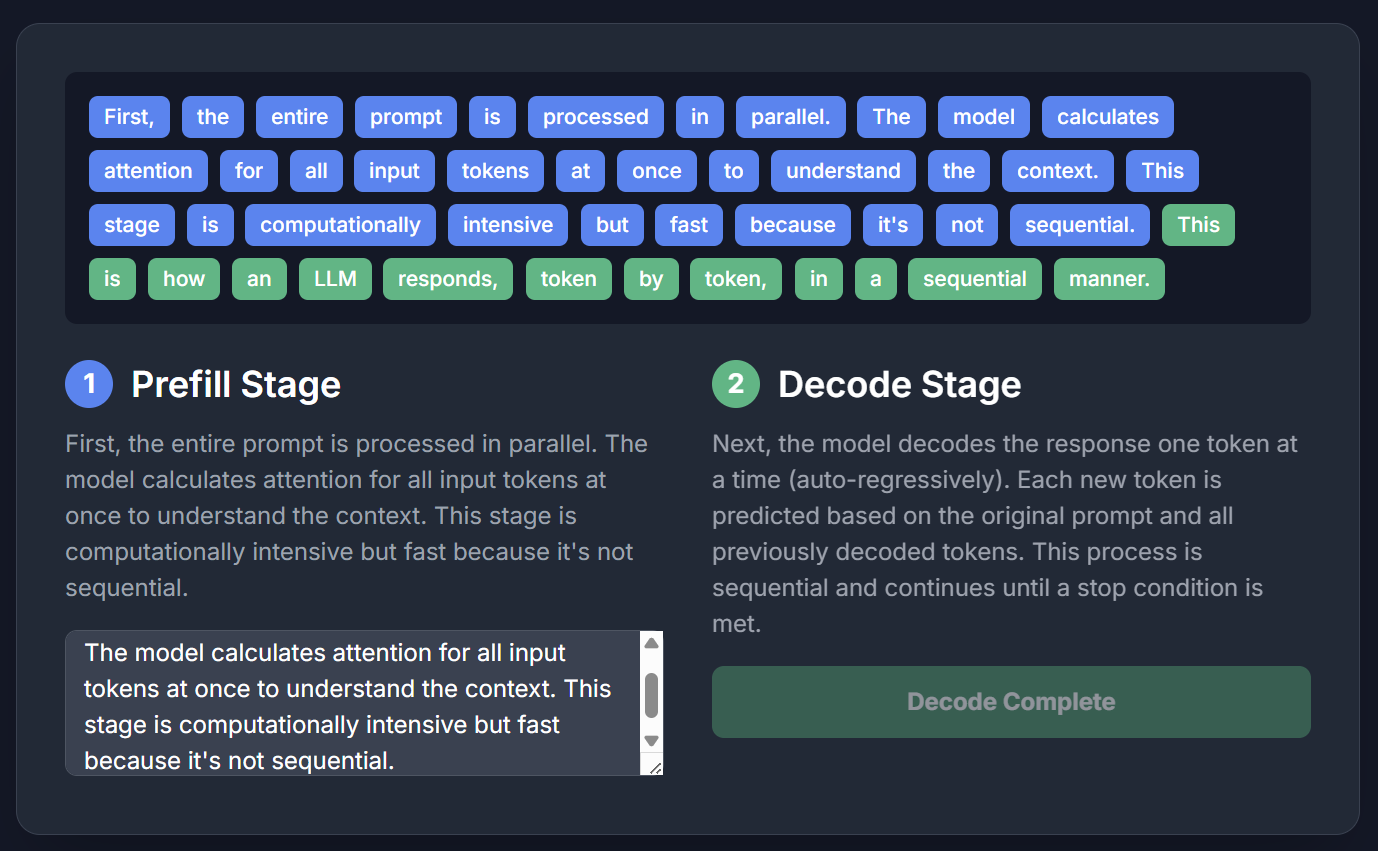
我们知道,一次推理分为两个阶段:prefill(预填充)和decode(生成),我让Gemini简单生成了一个动态演示:蓝色部分就是prefill,即将用户输入(上下文填充到模型中),绿色部分是生成,即“猜下一词”。
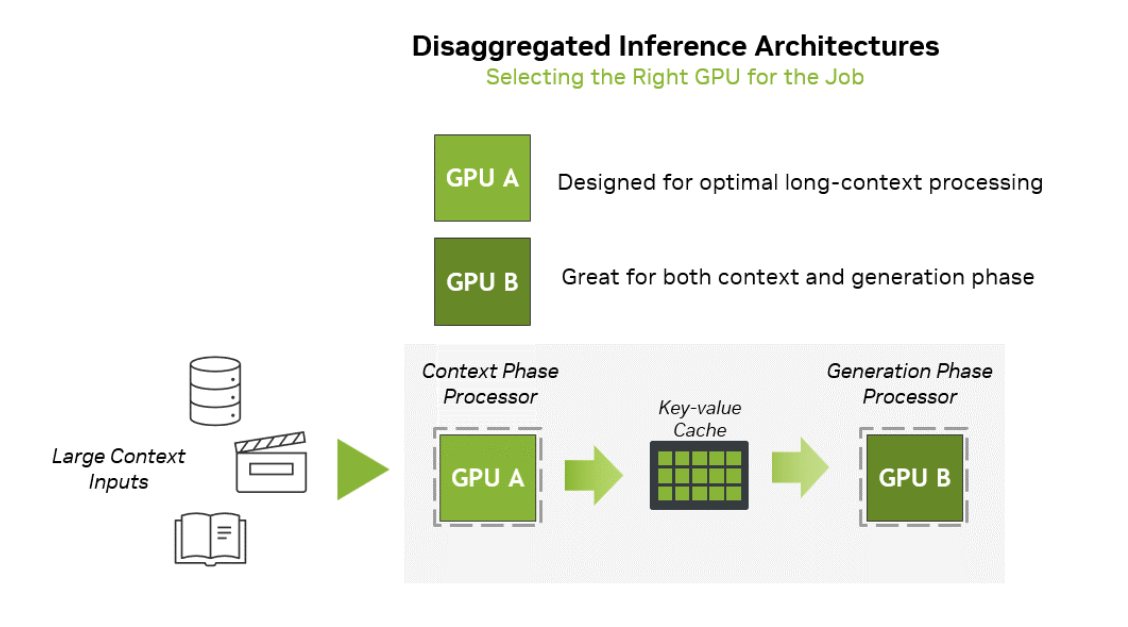
两个阶段对硬件性能的要求不太一样,相对复杂的解释看下图,简单解释就是:prefill更多需要算力,decode更多需要内存带宽,而KV-Cache(注意力缓存,是提高性能的一个关键架构,通常需要容量更大)。

所以,当输入的上下文越长,对prefill的需求就越大,也就是对芯片的计算能力要求就越高,但是对内存带宽要求就相对较小。当应用场景更多是AI对话时,这个区别不太明显,比如按照年初DeepSeek发表在知乎上的R1模型优化的文章里就有相关信息披露:全天输入token(上下文prefill)是680B的tokens,输出(decode)为168B的tokens,其中有342B的输入命中缓存。我们基本上可以认为在AI对话的场景下,输入和输出的比例是3-4:1,硬件优化的空间不大。
但是,当进入到搜索和代码生成阶段,有了Agent’的加入,情况就发生了非常大的区别了,首先,比例就变化很大了。
我在之前的文章里贴过下面的图,当更多是搜索任务时,输入token可以是输出token的几百倍。
在代码生成类的任务中,输入token和输出的比例也可以达到100:1。
另一方面,因为长上下文需要更长的prefill时间(其实是二次方增长的,但因为长上下文是基于让模型分段处理实现的,所以上下文越长,时间消耗接近越线性增长)。就意味着在prefill过程中,显存实际上是不工作的,或者负载很小。站在硬件折旧(HBM很贵,它的空闲时间就是钱)的角度考虑,虽然prefill每秒处理的token数量可以是decode的几倍甚至几十倍(按照前面说的DeepSeek的数据,prefill是73.7k/s,decode是14.8k/s),但是考虑到长上下文场景下,输入是输出的的百倍以上的量,那么HBM的高带宽至少有超过一半时间是浪费的,不经济的。
好了,这就是英伟达对市场高度敏感(行业统治地位带来的)的表现:我就配上一个算力一样,但是显存便宜的多的芯片,专攻prefill。
以上就是这款芯片和这个硬件架构存在的价值,也是英伟达官网下面这张图要表示的含义。