NVIDIA has announced another "future-ware" product: the Rubin CPX chip, specifically designed for long-context (million-token) inference, and the Rubin NVL144 CPX which integrates this chip.
Below is the Rubin CPX chip, utilizing 128GB of GDDR7 memory.
Below is the Rubin NVL144 CPX: a rack with 18 trays, where each tray houses four Rubin GPUs and eight Rubin CPX chips.

This leads to a series of record-breaking metrics: 8 exaflops (NVFP4), 100TB of memory (HBM + GDDR7), with performance claimed to be 7.5 times that of the GB300 NVL72.
In any case, NVIDIA wins again: "For every $100 million invested, there is a $5 billion return."

The primary reason is, of course, to counter potential competitive pressure. AMD has already released a competitor to NVL—the MI400-based rack, Helios. It features more powerful CPUs and offers better inference price-performance. Although AMD's product cycle lags behind NVIDIA's by at least half a generation, the community is quite optimistic about this product. Combined with the maturing ROCm ecosystem (targeting CUDA), the pressure from competitors is significant. Additionally, there are XPUs, popularized by Google's TPU.

Beyond competitive pressure, real-world application scenarios for long-context inference are growing rapidly. The massive increase in token volume since last year is primarily driven by long-context scenarios (search, code generation, and upcoming image/video generation). Long-context scenarios differ significantly from traditional conversational AI.
As we know, an inference cycle consists of two stages: prefill and decode. I asked Gemini to generate a simple dynamic demonstration: the blue part is prefill (filling user input/context into the model), and the green part is decode (the "guess the next word" generation).
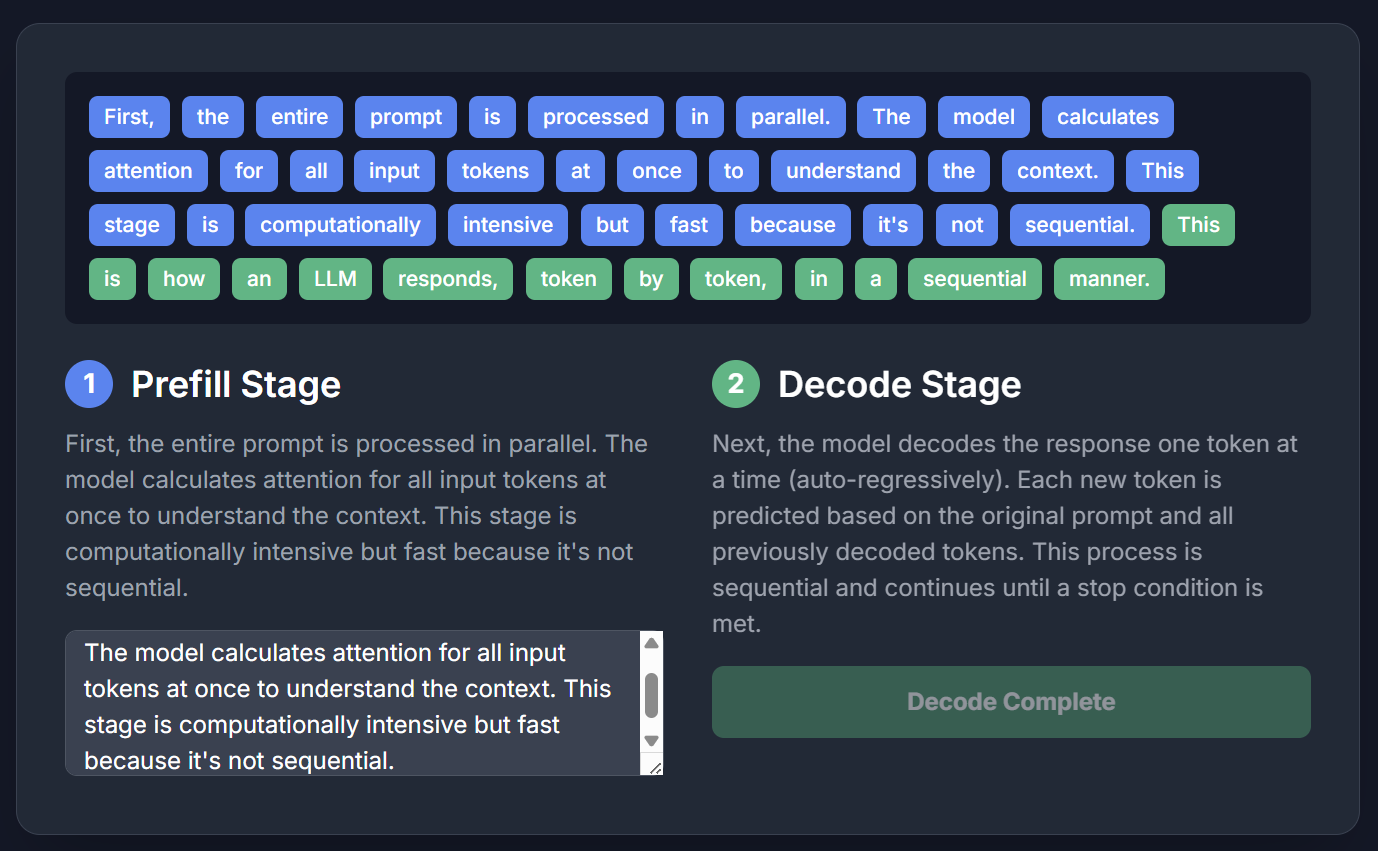
Hardware requirements for these two stages differ. For a more detailed explanation, see the image below. Simply put: prefill requires more compute power, while decode requires more memory bandwidth. Meanwhile, the KV-Cache (attention cache, a key architecture for performance) generally requires higher capacity.

Consequently, longer input contexts lead to higher demands for prefill, requiring greater compute capacity but relatively less memory bandwidth. In conversational AI scenarios, this difference is less pronounced. For instance, according to an article on R1 model optimization published by DeepSeek on Zhihu early this year: daily input tokens (prefill) totaled 680B, while output tokens (decode) were 168B, with 342B of inputs hitting the cache. Effectively, in conversational AI, the input-to-output ratio is roughly 3-4:1, leaving little room for hardware optimization.
However, with the introduction of search, code generation, and AI Agents, the situation changes drastically. First, the ratios shift significantly.
As shown in the chart from my previous article below, for search-heavy tasks, input tokens can be hundreds of times greater than output tokens.
In code generation tasks, the ratio of input tokens to output tokens can also reach 100:1.
Furthermore, because long contexts require longer prefill times (technically quadratic growth, though it becomes nearly linear when models process in segments), VRAM (HBM) is essentially idle or under low load during the prefill process. From a hardware depreciation perspective—since HBM is very expensive and idle time is wasted money—although the prefill speed (TPS) can be several times or dozens of times higher than decode (73.7k/s for prefill vs. 14.8k/s for decode, per DeepSeek data), the sheer volume of input in long-context scenarios means that high-bandwidth HBM is wasted for more than half the time, making it uneconomical.
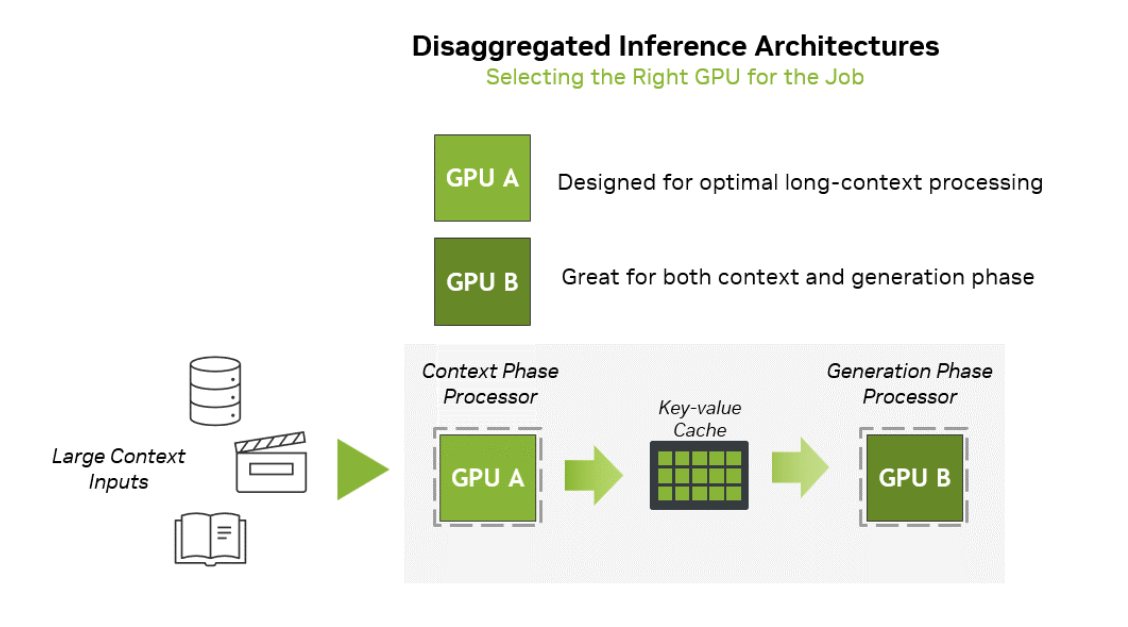
This demonstrates NVIDIA’s high sensitivity to the market (enabled by its industry dominance): they paired the system with a chip that has the same compute power but much cheaper memory, specifically dedicated to prefill.
This is the value proposition of this chip and hardware architecture, as illustrated in the image below from NVIDIA’s official website.