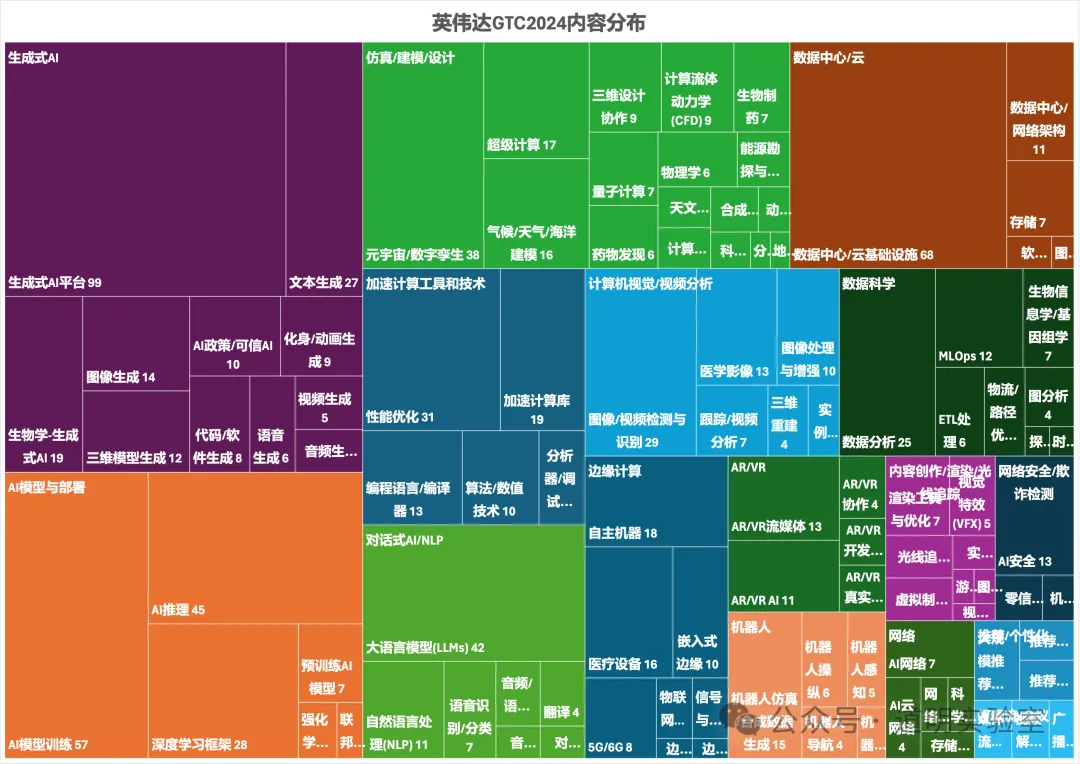
如果我们再仔细比较英伟达2024 GTF大会议程的内容分布图的话,可以很清楚的发现到处都有“三维生成”的身影:生成式AI、仿真、计算机视觉、AR/VR、内容创作、机器人……
LeCun关于AGI的讨论里有一点,其实几乎是大家的共识:我们要让模型理解人类物理世界。
这个“理解”的第一步,就是要看懂我们的三维世界。仅仅这一点,就已经足够具备吸引力。
更何况,“三维生成”对于科学研究、生产制造、影视游戏等内容创作更是具备“颠覆式”的重要性。
之前讨论“三维生成”的次数其实并不少,但是大家普遍会觉得繁琐,离的远。流程长,工具多,门槛高,确实是目前“三维生成”最大的问题。
所以,我又回到了自己当初建立第一个“三维模型”时采集照片的地方,Suntec新达城的标志性喷泉,一是环境可控,采集素材比较方便,二是也通过此来对比一下这一年多建模效果的变化。
首先,是我不同时期用不同设备在这个点拍摄的照片。尤其是最后一张,为了让喷泉和后面的办公楼都能完整,我在富士中画幅相机上使用了15mm的移轴镜头,竖构图,上下都移满,再拼接,等效135上已经是不到10mm的视角了。




进入建模流程介绍。
1、照片拍摄
竖构图,依然采用了富士中画幅相机,配合20-35mm镜头,使用20mm端,既有很广的角度,镜头的畸变又很小(畸变是三维重建的“克星”)。采集方法:喷泉周围是360度的栏杆,所以保持相机视角基本平衡,转一圈,等间隔拍摄,背景的建筑是很好的特征,用来帮助照片进行空间对齐的。
所以,这里,是我认为“三维生成”入门最佳地点。

2、照片整理
将照片导入电脑,存放到单独的文件夹,一共82张,因为是等间隔,差不多每两张照片之间的角度差距是4.5度,该镜头20mm端对角线视角是108度,短边视角就是不到70度,这种拍摄保证了每两张照片之间非常大的重叠部分,几乎在建模前就可以确定,金色的环是可以连续的。
3、照片空间对齐
这一步可以使用现成软件,我依然使用Epic Games(虚幻引擎出品公司)旗下的Reality Capture(目前只有Windows版本)。
打开软件,选择【WORKFLOW】页,第一步点击【Folder】按钮,导入照片后,点击【Start】按钮,程序就自动运行了。

经过一段时间的计算后,三维模型就生成了,如下动图展示的是稀疏模型的结果(也可以叫点云图)。界面上也可以同步显示没张照片的拍摄位置即角度(纯计算),在这个场景里,这些照片形成了完整的一个圆周。
4、调整重建区域,三维渲染
为了方便模型的后续处理,同时也为了大幅降低运算量。在上面的三维空间进行裁剪,只选取喷泉部分,再次重建,软件会重新计算,再选择【MESH MODEL】下的【Texture】,即可生成稠密模型,并可以实时渲染。
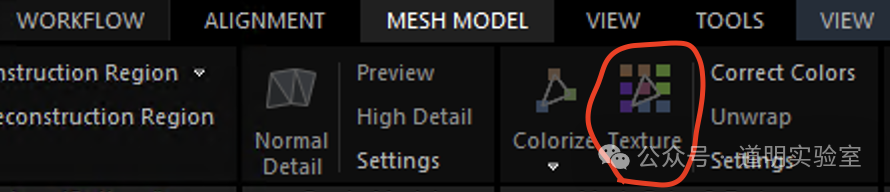
这个生成时间比照片对齐要长,画质也更好一点。
5、模型导出到Blender等三维或者游戏引擎里
可以将模型导出成.ply格式或者.obj格式,然后打开Blender(开源三维制作软件),导入。就可以进行各种编辑,如下:
6、导入苹果Vision Pro
不管经不经过Blender等软件进行编辑,导出后的.obj或者.ply都是可以通过应用程序在苹果Vision Pro里交互的。不过,目前的这种交互对于小规模的模型效果不错,但是对于大场景的就还是会力不从心,主要是因为大场景下,就更需要沉浸式体验了,对应用开发的难度也自然提高。不过,确实可以将刚刚生成的简单三维模型当作玩具一样导入到眼镜里,简单交互:

因为微信公众号对gif文件帧数限制, 我只能用每秒5帧的采样率上传这段gif,实际操作体验,会流畅很多。
至此,一个简单的三维建模就算完成了,为了更直观,我也把上面的全部步骤串联起来做成了短视频。
这才是三维建模里最入门的第一步,为了效果,需要付出的努力,是远大于照片的。但是那种宏大的多的信息量的感觉,真的很棒。