This article is written in a jaw-dropping mood, and it won't be too long.
Grok-3 is now open to everyone for free, so I tried it immediately.
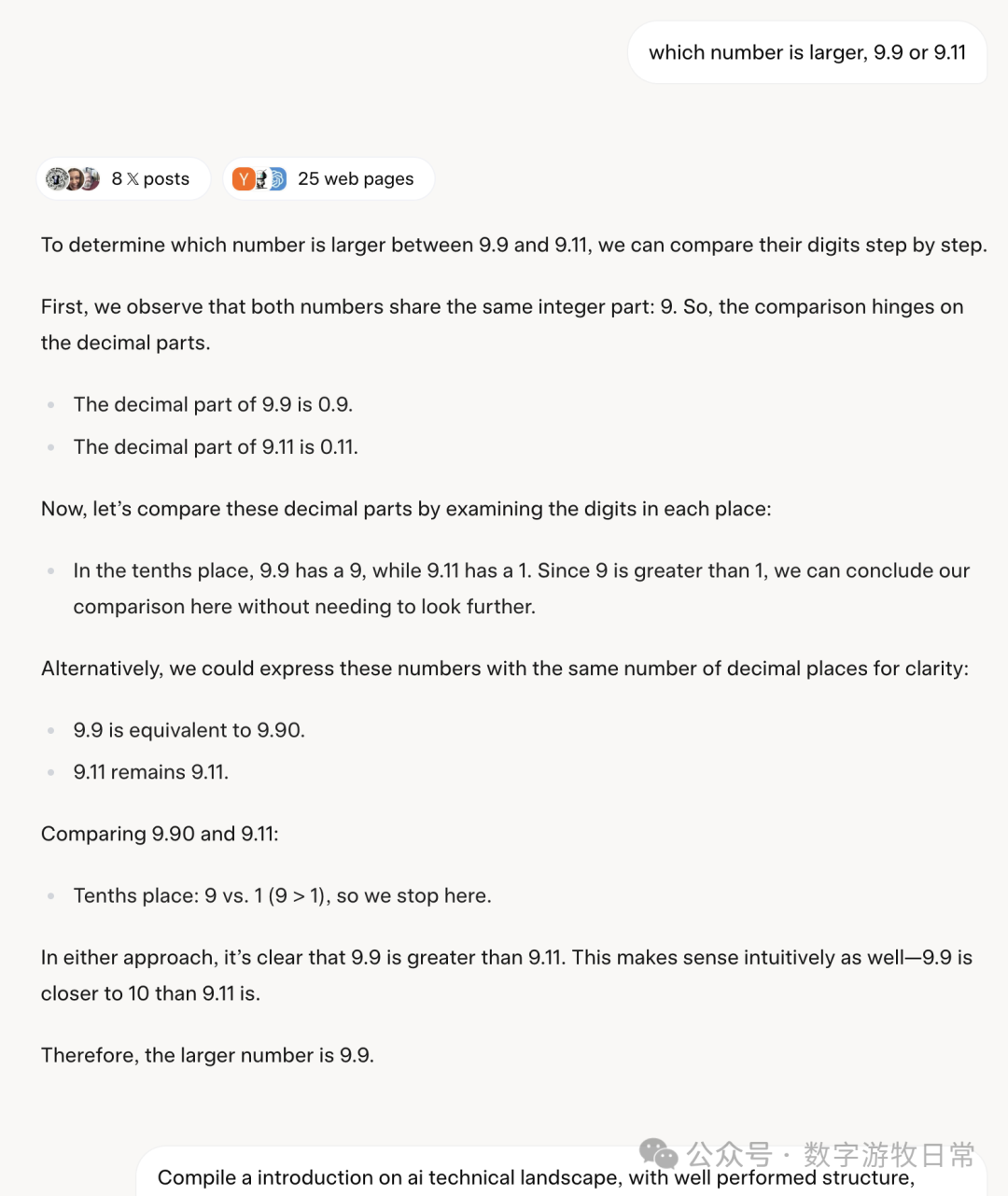
Without enabling thought mode, I tried that classic question: "Which is larger, 9.9 or 9.11?"
It got it right, "very correctly" so, but frankly, the process was very "Deepseek R1." Could Deepseek claim that this was distilled from their model?
I was quite satisfied with this answer, so I immediately wanted to try the legendary feature called "Deep Search," which is actually "Deep Research."
I used the same prompt as GPT's "Deep Research." GPT took 6 minutes and 9 seconds to generate a report of over 7,000 words.
The same prompt was given to Grok-3. Yes, it started searching and thinking. It was very fast, and the process seemed correct, taking only 54 seconds in total. It's definitely in the spirit of DOGE.
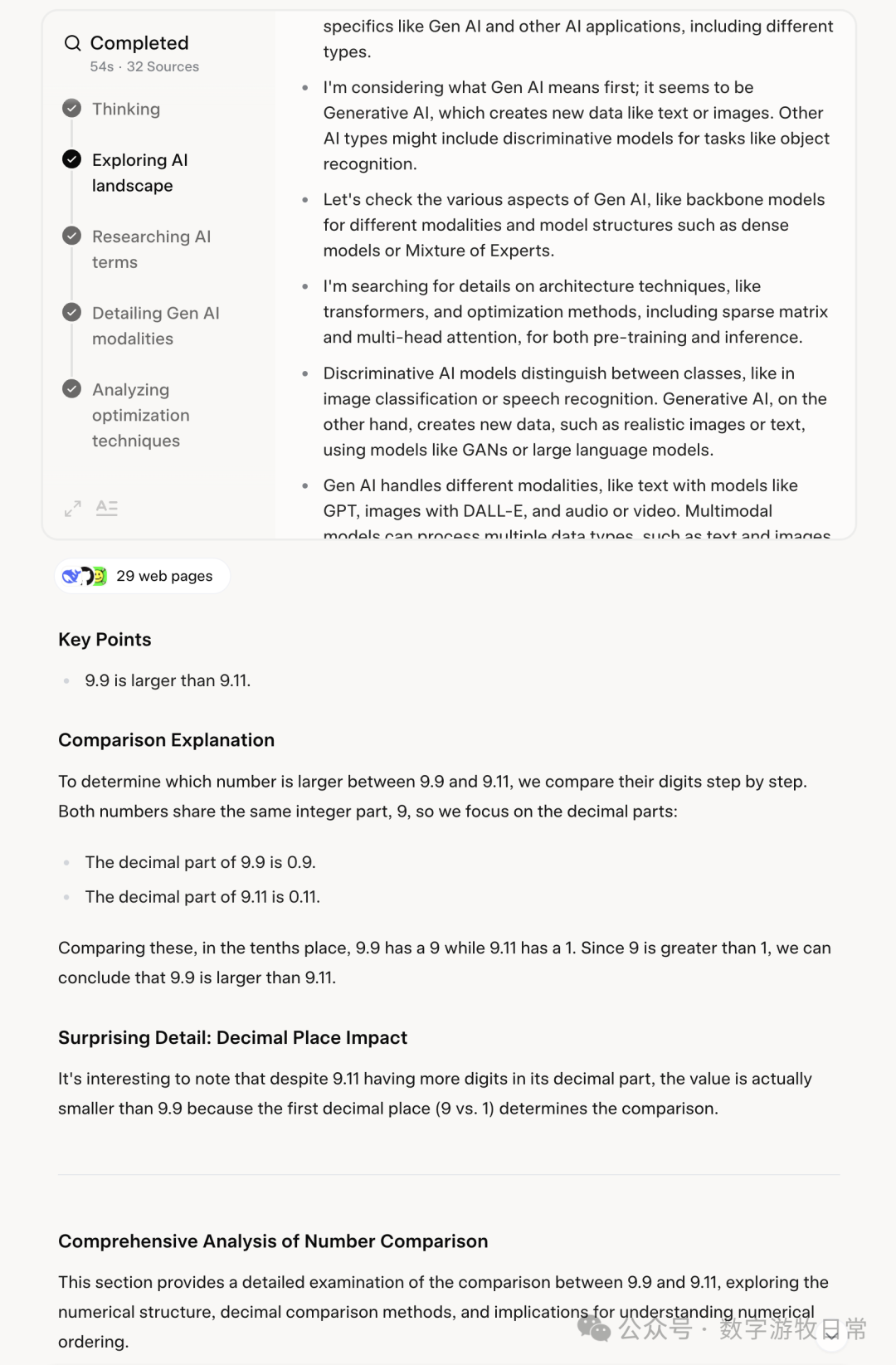
Just as I was about to appreciate Grok-3's masterpiece, a miracle happened (I forgot to start a new chat):
It began to earnestly answer my question about whether "9.9 or 9.11" is larger. Did you conduct all that extensive research just to answer this question?
Honestly, this is a "miracle" I haven't encountered in the past two-plus years of using any publicly released model application. Truly "the smartest in the universe."
I believe the Grok-3 model itself is not at this level, but this is definitely the worst "application."
It's so bad that I lost interest in doing any further evaluations.
However, I firmly believe that with such poor quality control, the market's recent skepticism regarding the claim that "200,000 H100s only yielded a 30% improvement" suggests the fault lies less with the "Transformer" architecture and more likely with xAI itself.
Let's wait for the next professional player, Anthropic's upcoming Claude-4, before making further comments.