这篇文章又是在一种惊掉下巴的气氛情绪中写下的,不会太长。
Grok-3开放给了所有人免费使用,所以我第一时间用了。
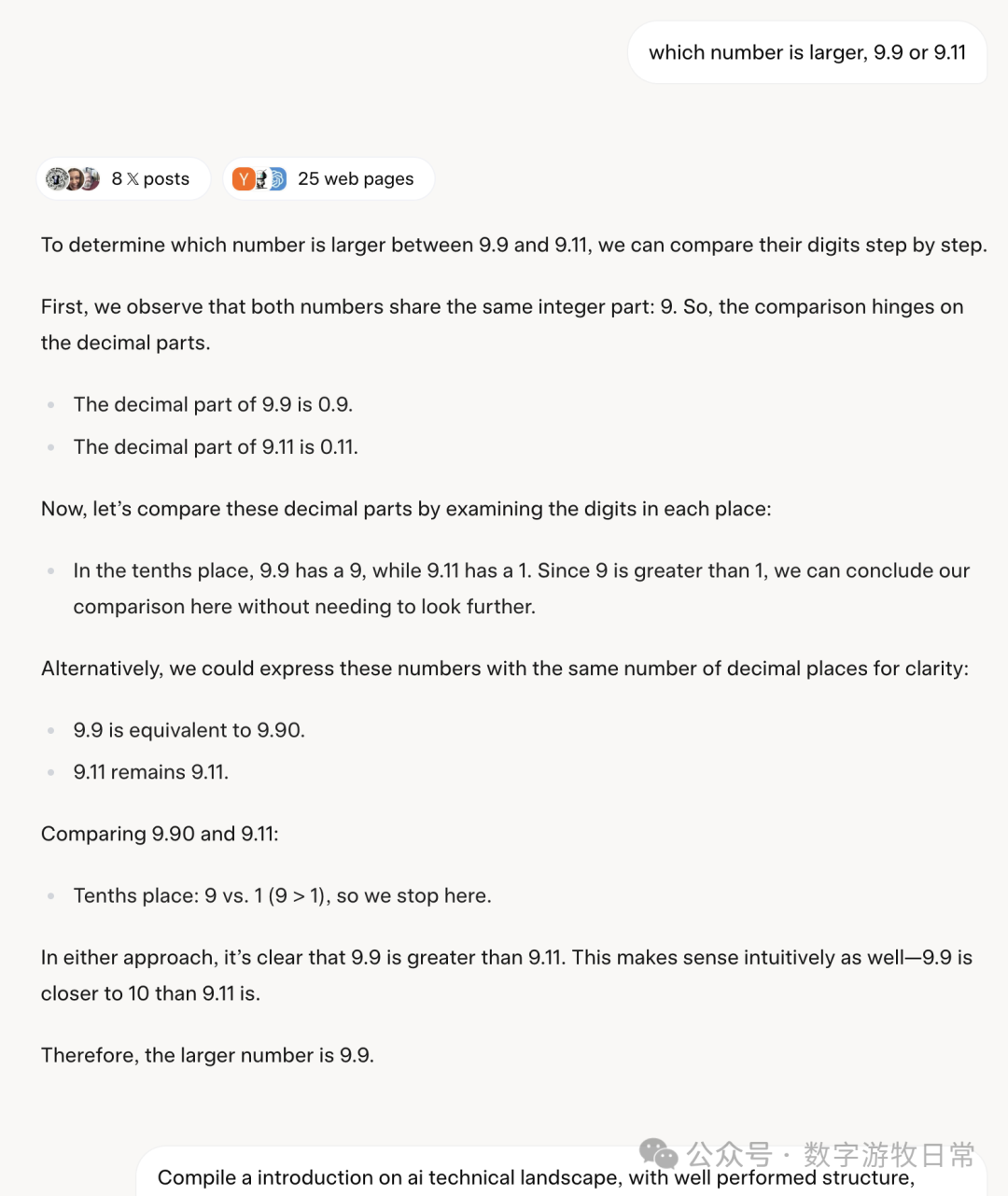
我在没有开启思考的模式下,去试了那个经典问题“9.9和9.11哪个大”。
它对了,对的“很正确”,但是坦白来讲,它对的过程很“Deepseek R1”。Deepseek是不是可以说这是通过他们的模型蒸馏得来的?
这个回答还是很满意,然后我就要第一时间尝试一下哪个传说中的名为“deep search”其实就是“deep research”的功能。
我用了跟GPT的“Deep Research”一样的提示词,GPT使用了6分9秒,生成的报告超过7000个词。
同样的提示词给到Grok-3,是的,它开始搜索了,开始思考了,速度很快,看起来过程也很正确,全程只用了54S。果然是干DOGE的。
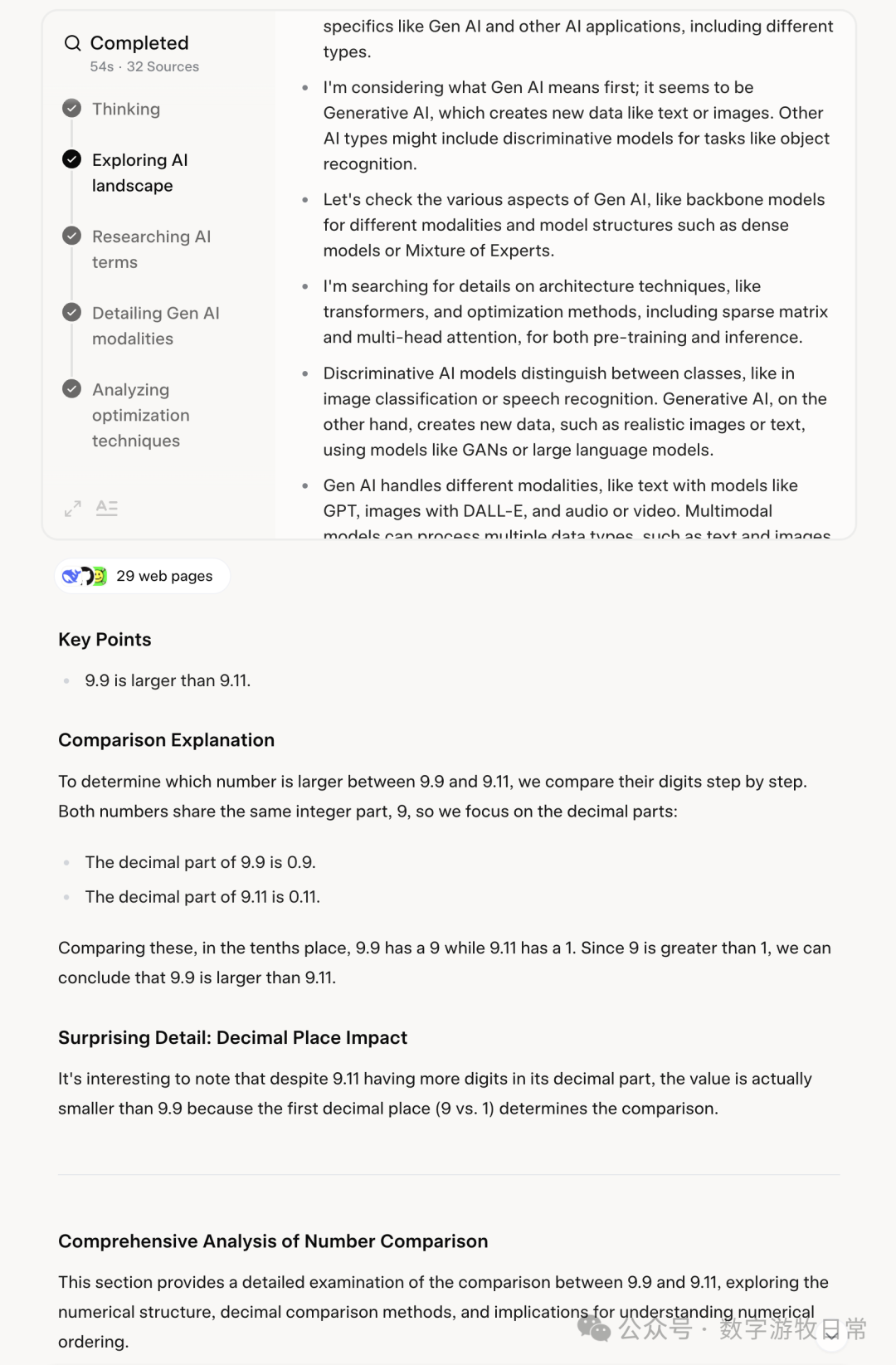
正当我准备欣赏Grok-3的大作时,奇迹发生了(我忘了新开对话):
它开始认认真真的回答我“9.9和9.11”谁大的问题了。难道你研究了这么一大通,就为了回答我这个问题吗?
坦白说,这是我在过去两年多里,使用任何公开发布的模型应用都没有碰到过的“奇迹”,果然“全宇宙最聪明”。
我相信Grok-3模型绝对不是这个水平,但是,这绝对是最差的“应用”。
差到我失去了兴趣去做任何的评测。
但是,我绝对相信,如此这样的品控能力,市场这两天反复讨论的“二十万张H100就提升了30%”的质疑,锅越来越不是“transformer”,而可能是xAI自己的了。
等下一个正规军Anthropic即将到来的Claude-4,再去评论吧。