如果您是因为标题点进来的,请原谅我表现的有一些标题党。但这也是我的结论:在过去不到一个月里,我尝试通过四个版本的类“Deep Research”(OpenAI、Gemini、Perplexity、Grok-3)生成了不下100篇“深度研究”,当我确信优秀分析师的价值反而因为这类应用的普及而变得更大时,也生出了另一种担心,这类应用,其实是用来“摧毁”投研体系的。
其实这个结论,在我脑子里已经存在了一段时间了,但是没有一个好的切入点去更直观的讨论这个问题,直到今天。
事情是这样,我刷到了下面一篇文章,关于万维钢使用“Deep Research”的经验的。
这里用到了Deep Research
万维钢,公众号:罗辑思维
DeepSeek+华为,能不能超越英伟达和Open AI?
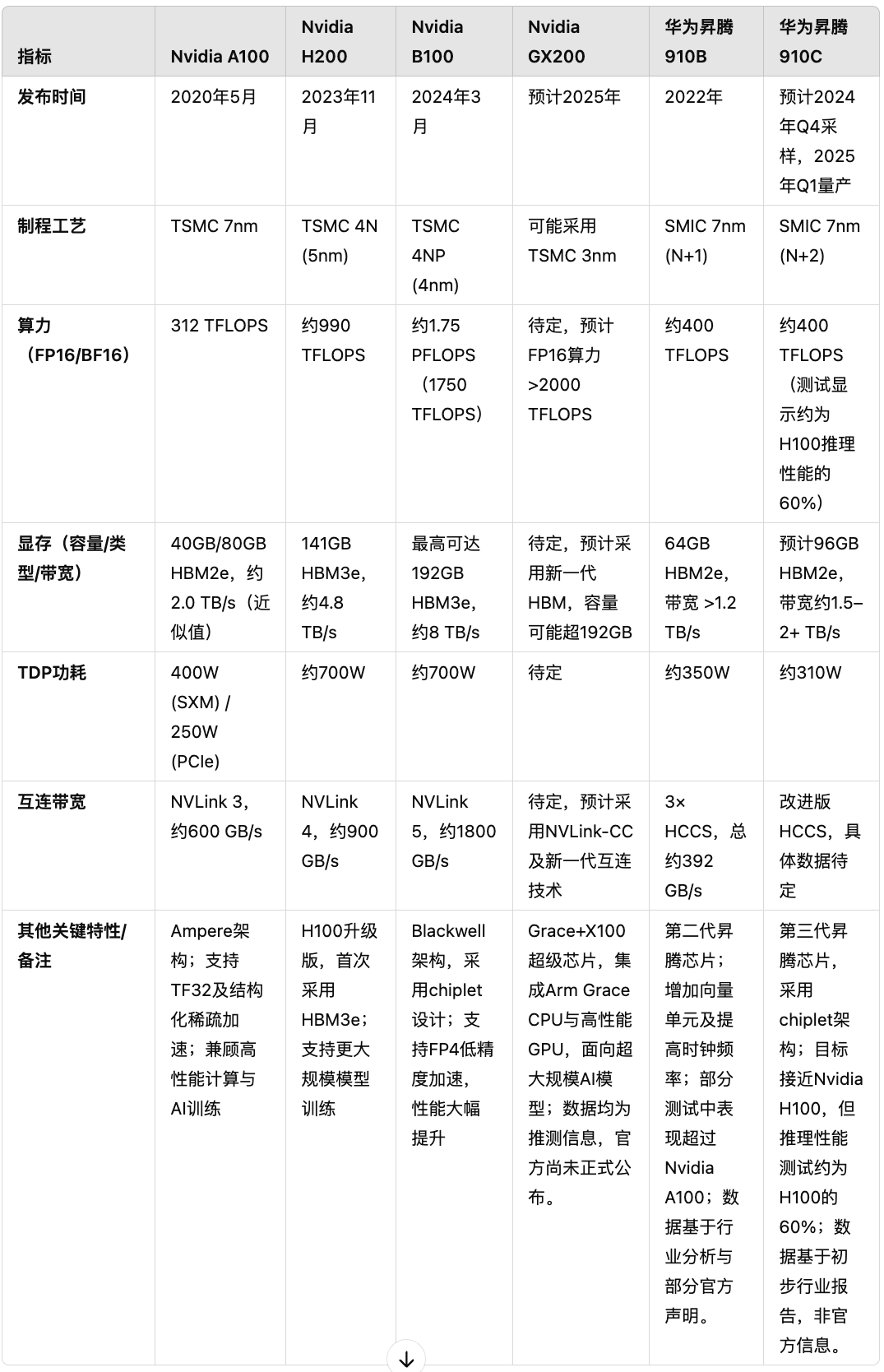
但是,当我看到文章里提到的下面这张由OpenAI的Deep Research生成的表格时,我一眼看去,就觉得有一些错误。
于是,我把这张图发给了小伙伴们,他们的反应速度让我很惊喜。
这个例子不是去批评“得到”或者万维钢,他毕竟不是在一线的分析师,行业里很细节的东西是不具备“一眼看上去不太对”的辨别能力的,但是不做事实核查就全盘接受,他接受一点点质疑也并不太冤。
恰恰就是这种快速辨别能力的差别,Deep Research这样的产品,很长时间里都取代不了优秀的分析师,因为这已经几乎成为他们的一种本能反应并通过“系统1”快速的输出出来。
但是,Deep Research可以成为优秀分析师非常高效的助手,如果使用得当的话。
这是第一个方面。
如果细看上面例子中潜在错误的话,如果对Deep Research的结果进行事实核查,我几乎可以肯定能够在它给出的信息来源里找到这些数字和表述。OpenAI刚发布了Deep Research的系统卡,我总结如下:
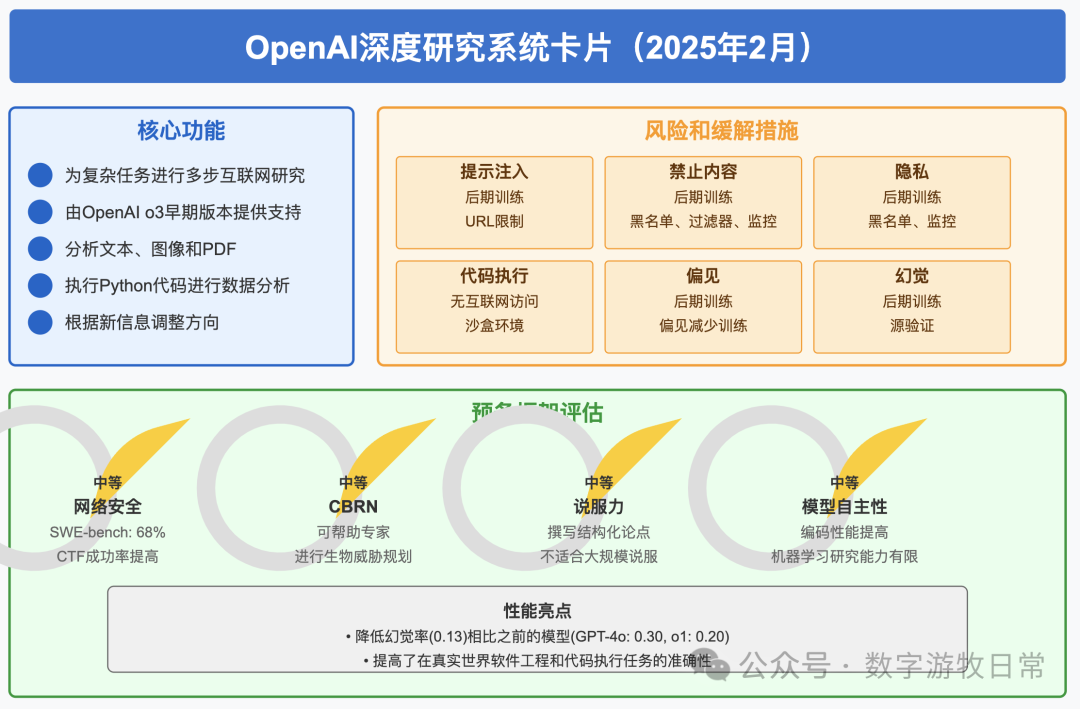
其中,一个非常重要的点,就是超低的幻觉率:0.13(一个插曲,模型在帮我生成这一页slide时,使用的是13%,因为我已经看过报告原文了,所以我知道这是一个错误的数字,也知道这并非模型的“幻觉”,所以我告诉模型不要看作是百分比,修改一下,它改成了0.13%,这跟我第一感觉是一样的,但是我又回去看了一下原文报告,OpenAI只说是一种指标,没有单位,所以,我又告诉模型,只输出数字就好,0.13)。
是的,在我过去事实核查的几十篇OpenAI Deep Research生成报告里的每一个数字时,我没有发现一例“幻觉”,与Perplexity和Grok-3有着明显的区别。
但是,没有幻觉不代表数字就是正确的:模型如实获取了信息来源里的数字,但信息来源里的数字可能本来就是错的。上面的例子就更可能是这种情况。
当然,行业里公开发“新发新能源车”的参数数据,十个数字里错三四个以上,也很普遍。
事实核查的意识和能力,因人而异。只是,Deep Research这类工具会快速普及,它们只会让本就没有意识和能力的“分析师”彻底地丧失这项最重要最基础的能力而已。
所以,回到标题,我还是“标题党”了,因为“分析师”的“错误和幻觉”甚至远高于模型,“垃圾信息”已经充斥着整个市场,只是现在污染了模型的信息源,再通过回旋镖打回来而已。
“粗制滥造”是一个原因。
另一个重要原因是,越来越方便的工具,等于极大的抹平了“信息差”,Deep Research的产出类似于某种“共识”,在有效市场里不再提供任何增量信息。
于是,真正有价值的信息,也许只会存在于少数人的大脑中,或者个人的“私有知识库”里,而越来越少的会流入到“系统”之中,因为,在未来可见的很长一段时间里,外部工具都将会比内部工具更好用。
投研体系,如果说的是某个具体的人,应该还会存在,如果说的是一个组织,那我就不太乐观了。不是越来越好的AI,而是我们自己的所作所为,早就把它的根基摧毁了。